- The paper introduces a unified framework that couples video and action diffusion using independent diffusion timesteps for enhanced robot learning.
- It leverages both action-annotated trajectories and action-free videos to support policy, forward and inverse dynamics, and video prediction tasks.
- Experimental results show over 80% average success rates across real-world and simulated tasks, demonstrating robust generalization even in OOD scenarios.
Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets
Introduction
The paper introduces Unified World Models (UWM), a framework that unifies policy learning and world modeling for robotic control by integrating action and video diffusion processes within a single transformer architecture. UWM leverages both action-annotated robot trajectories and action-free video data, enabling flexible inference for policy, forward dynamics, inverse dynamics, and video prediction tasks. The approach is motivated by the limitations of conventional imitation learning, which relies heavily on high-quality expert demonstrations and often fails to generalize beyond the training distribution. By coupling video and action diffusion with independent modality-specific timesteps, UWM facilitates feature sharing and causal understanding between actions and observations, improving robustness and generalization.
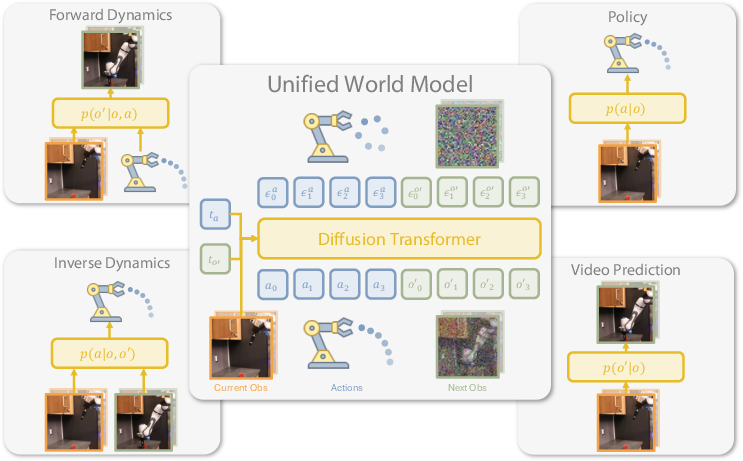
Figure 1: Unified World Models integrates action and video diffusion in a unified transformer architecture controlled by modality-specific diffusion timesteps, enabling flexible training and inference for diverse robotic tasks.
Methodology
Diffusion-Based Unified Modeling
UWM builds upon denoising diffusion probabilistic models (DDPMs), extending them to jointly model actions and future observations conditioned on current observations. The key innovation is the decoupling of diffusion timesteps for actions and next observations, allowing independent control over each modality during both training and inference. This enables the model to flexibly marginalize or condition on either modality, supporting inference for:
- Policy: p(a∣o)
- Forward dynamics: p(o′∣o,a)
- Inverse dynamics: p(a∣o,o′)
- Video prediction: p(o′∣o)
During training, the model is exposed to all combinations of noise levels for actions and observations, instilling a causal understanding of their relationships. The denoising objective is optimized over both modalities, with weights to balance action and observation prediction losses.
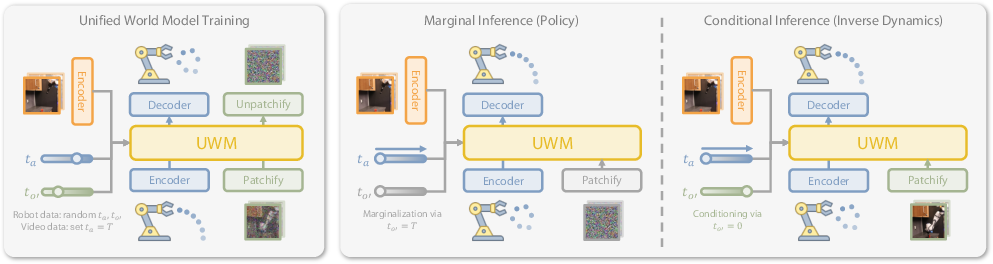
Figure 2: UWM training and inference pipeline, illustrating pretraining on robot trajectories and co-training on action-free videos via diffusion timestep masking, and flexible inference modes for policy and inverse dynamics.
Architecture
UWM employs a diffusion transformer backbone with AdaLN conditioning. Observations are encoded using ResNet-18, and diffusion timesteps are embedded via sinusoidal encodings. Actions are embedded with a shallow MLP, while images are processed in the latent space using a frozen SDXL VAE and patchified for transformer input. Register tokens are introduced to facilitate multi-modal feature sharing, empirically improving performance.
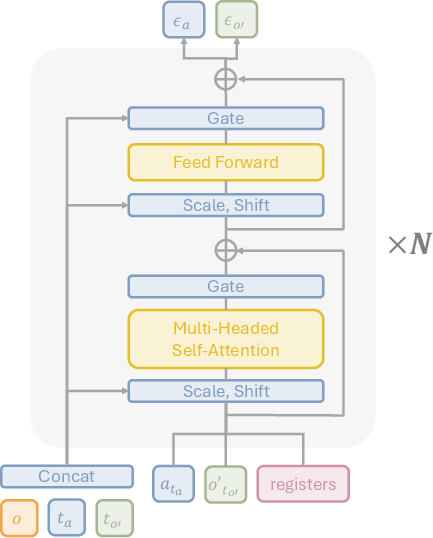
Figure 3: A single UWM block consists of a transformer with adaptive layer norm conditioning and register tokens for enhanced multi-modal feature sharing.
Training Paradigms
UWM supports pretraining on large-scale multitask robotic datasets and co-training on action-free videos. For video data, actions are masked by setting the action diffusion timestep to T and imputing random noise, allowing the model to learn from broader data modalities. The model is trained using distributed data parallelism and optimized with AdamW.
Experimental Evaluation
Real-World Robotic Manipulation
UWM is evaluated on five real-world manipulation tasks using the DROID dataset, with both in-distribution and out-of-distribution (OOD) scenarios. Tasks include Stack-Bowls, Block-Cabinet, Paper-Towel, Hang-Towel, and Rice-Cooker, each requiring visual and positional generalization.

Figure 4: Visualization of diverse pretraining and finetuning datasets, covering a wide range of tasks and environments for robust generalization.

Figure 5: Real-world task setups, initial configurations, successful completions, and OOD scenarios for robustness evaluation.
UWM consistently outperforms baselines (Diffusion Policy, PAD, GR1) in both ID and OOD settings, with average success rates exceeding 80% in most tasks. Co-training with action-free videos further improves performance, especially under distribution shifts. PAD and GR1 show weaker positive transfer from video data, with PAD's performance limited by its conditioning strategy.
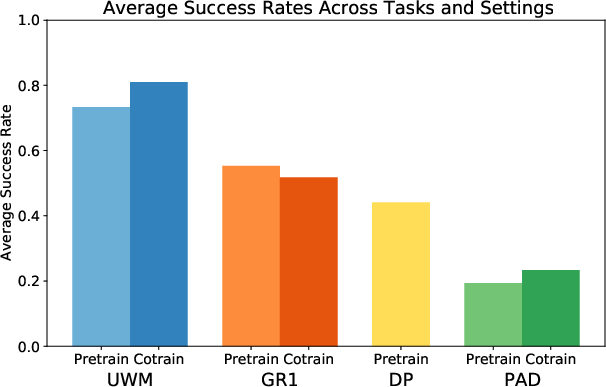
Figure 6: Average success rates across all real robot tasks and settings, demonstrating UWM's strong performance and gains from video co-training.
Simulated Benchmarks
On the LIBERO benchmark, UWM achieves the highest success rates in OOD evaluation tasks, outperforming DP, PAD, and GR1. The improvement is attributed to pixel reconstruction as an auxiliary signal and the causal understanding imparted by independent diffusion timesteps.

Figure 7: Visualization of LIBERO datasets for pretraining and evaluation under distribution shifts.
Analysis and Ablations
Forward and Inverse Dynamics
UWM accurately predicts future observations conditioned on actions, validating its world modeling capabilities.

Figure 8: Forward dynamics predictions, showing accurate robot and object pose estimation conditioned on initial observation and actions.
Inverse dynamics inference enables trajectory tracking with higher success rates than policy inference under time constraints.
Robustness to OOD Conditions
UWM demonstrates superior robustness in categorized OOD settings (lighting, background, clutter), with video co-training providing significant gains over baselines.

Figure 9: Categorized OOD settings for generalization analysis, including varied lighting, backgrounds, and clutter.
Scaling and Ablations
UWM scales more effectively from pretraining than DP, and ablations show that reconstructing future observations is more beneficial than reconstructing current observations.
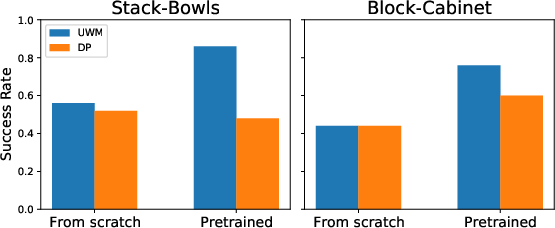
Figure 10: Comparison of training from scratch versus finetuning pretrained models, highlighting UWM's scalability.
Implementation Considerations
- Computational Requirements: Training UWM on 100K steps with DROID data requires 4 NVIDIA A100 GPUs for 24 hours.
- Architecture Choices: AdaLN conditioning and register tokens are critical for multi-modal feature sharing and performance.
- Data Modalities: UWM can leverage both action-annotated and action-free video data, with independent diffusion timesteps enabling flexible masking and conditioning.
- Deployment: At inference, UWM supports flexible rollout strategies by selecting appropriate diffusion timesteps for the desired inference mode.
Implications and Future Directions
UWM provides a unified framework for robot policy learning and world modeling, bridging the gap between imitation learning and generative modeling. The ability to leverage heterogeneous datasets, including action-free videos, is a significant step toward scalable robot learning. The approach suggests that independent control over modality-specific diffusion processes is essential for causal understanding and robust generalization.
Future work should address learning from large-scale human videos to bridge the embodiment gap, improve forward dynamics reconstruction fidelity, and explore denser video prediction. Integration with recent advances in generative modeling and multi-modal transformers may further enhance scalability and generalization.
Conclusion
Unified World Models present a principled approach to coupling video and action diffusion for scalable robot learning. By decoupling diffusion timesteps and enabling flexible inference, UWM achieves superior performance and robustness across diverse tasks and settings. The framework's ability to leverage both action-annotated and action-free data positions it as a promising foundation for future generalist robot models.

