- The paper introduces an automated LLM-driven pipeline that constructs realistic, reproducible, and scalable benchmarks for browser agents.
- It employs a four-stage agent framework—plan, generation, refinement, and validation—to generate interactive web tasks with controlled multi-dimensional difficulty.
- Empirical evaluations reveal that the benchmarks effectively differentiate agent performance, exposing modality impacts and domain-specific challenges.
WebForge: Automated Multi-Dimensional Benchmark Generation for Browser Agents
Motivation and Positioning
WebForge introduces a fully automated pipeline for constructing browser agent benchmarks that robustly address the entrenched realism–reproducibility–scalability trilemma present in prior art. Previous benchmarks using real websites achieve ecological validity but rapidly decay due to content drift, while controlled environments ensure reproducibility at the expense of stimulus realism and require unsustainable manual curation. Existing automated generation strategies are limited to non-interactive or static tasks, lacking support for multi-dimensional, interactive, and noise-robust web environments. WebForge provides a comprehensive solution by leveraging multi-agent LLM pipelines and principled difficulty control, demonstrated to produce challenging, realistically noisy, scalable, and human-annotation-free testbeds for browser-based autonomous agents.
Automated Pipeline Architecture
The WebForge pipeline consists of four sequentially orchestrated LLM-driven agents: Plan Agent, Generation Agent, Refinement Agent, and Validation Agent. Each agent has a well-defined interface and operational semantics, enabling fully reproducible and interpretable benchmark construction.
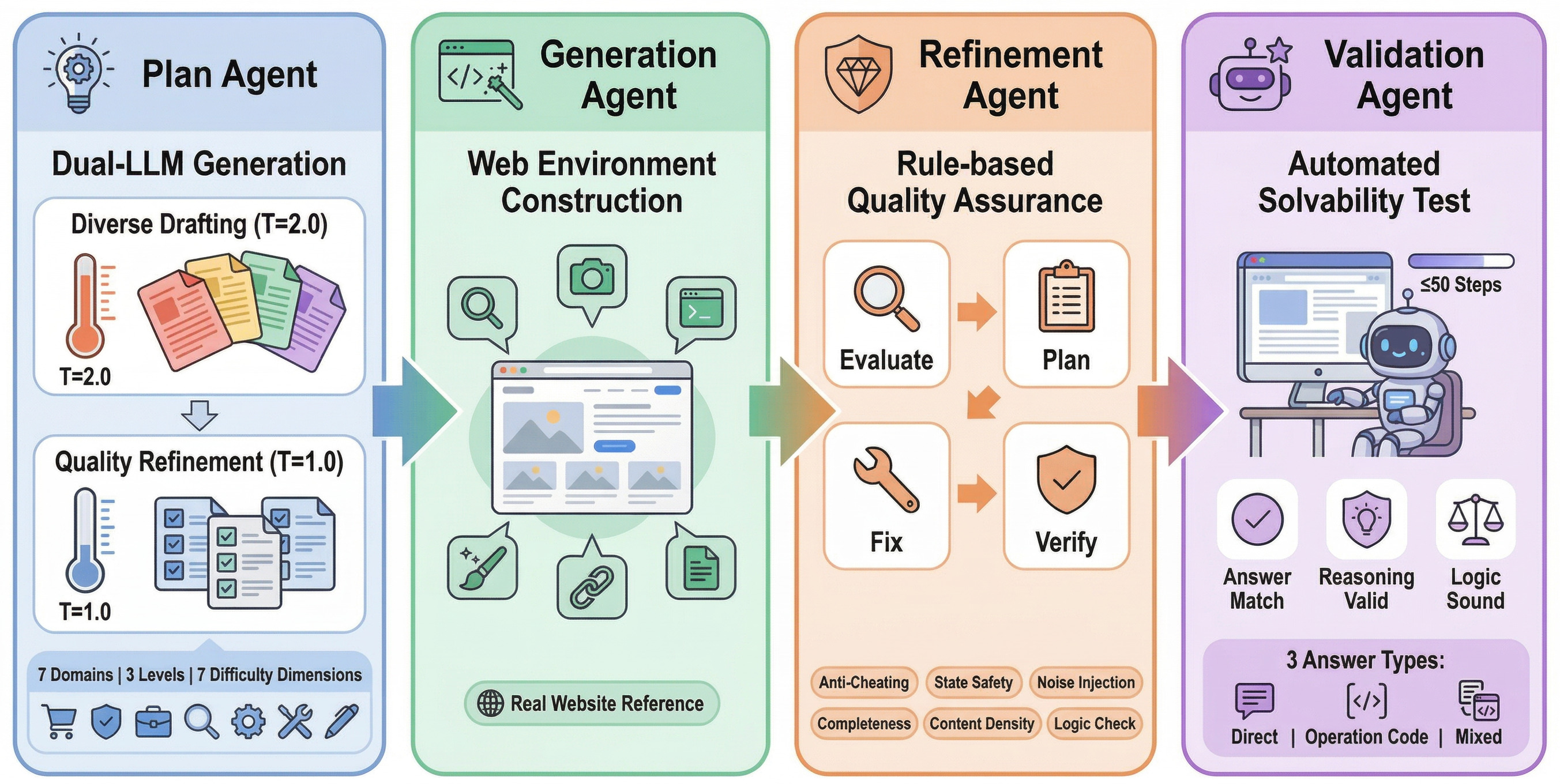
Figure 1: The four-stage pipeline for automated web environment and task generation, encapsulating plan design, website synthesis, environment refinement, and browser-level validation.
Seven-Dimensional Difficulty Control and Benchmark Structure
WebForge imposes a seven-dimensional task difficulty schema: Jump Depth, Jump Breadth, Page Interaction complexity, Visual Complexity, Information Complexity, Reasoning/Calculation, and Risk Factor (irreversibility). Each axis is discretized into three levels, yielding combinatorially diverse scenario configurations. Aggregate difficulty is regulated by compositional constraints (e.g., Level-3 tasks require multiple axes at their hardest settings), producing benchmarks with strong stratification properties both within and across domains.
The pipeline constructs WebForge-Bench, a corpus of 934 tasks over 7 web domains and 3 global difficulty tiers, with final composition reflecting realistic distributions of risk, visual, and navigation complexity.
Empirical Evaluation and Capability Profiling
Comprehensive experiments on WebForge-Bench include an array of SOTA closed and open-source agents, text-only and multimodal. Multiple findings stand out:
- Difficulty Stratification: All models, including frontier multimodal LLMs (e.g., Gemini-3-Pro, Claude-4.5-Sonnet), show steep accuracy decay as difficulty increases. Level-1 tasks yield >73% accuracy for top models; Level-3 produces strong separation (e.g., Gemini-3-Pro 58.0% vs. Qwen3-Omni-30B 2.4%). This validates the discriminative efficacy of the multi-dimensional framework.
- Domain Sensitivity: Cross-domain analysis reveals substantial and consistent performance shifts: info retrieval tasks are universally easier, while consumer transaction and content moderation domains manifest distinct failure modes, especially in irreversible or nuanced policy judgment scenarios. These distinctions are not visible under conventional aggregate scoring, highlighting the necessity of structured multi-axis benchmarks.
- Modality Impact: Removal of visual input consistently decreases accuracy by 14–16 points for multimodal models, and the effect amplifies with increasing task difficulty.
Ablation studies confirm the each pipeline component’s critical role: omission of plan refinement or post-generation refinement leads to substantial declines in validation pass rates (from 74.1% to 51.4%).
Robust Anti-Cheating Mechanisms
WebForge enforces a final-state evaluation paradigm: agents’ outputs are judged only on end-state correctness, not trajectory, and sensitive solution data is encrypted or gated by operational code. The presence of adversarial answer codes ensures that partial mistake patterns are mapped to plausible, but strictly incorrect, outputs—eliminating source-level answer leakage and facilitating precise diagnostic error analysis. This obviates the need for ad hoc, potentially subjective semantic reward functions that plague prior work.
Practical and Theoretical Implications
WebForge conclusively demonstrates that highly realistic, reproducible, and scalable browser agent benchmarks can be fully automated. By escaping the realism–reproducibility–scalability trilemma, the methodology enables:
- Creation of continuously updating testbeds immune to the decay and maintenance costs associated with manual curation and content drift.
- Systematic, interpretable diagnosis of agent weaknesses along multiple cognitive-action axes, spurring targeted algorithmic improvements.
- Generation of arbitrary quantities of labeled, browser-executable training data as a future extension, addressing the paucity of high-quality RL trajectories for web agents.
- A robust platform for research into open questions on multi-modal grounding (text/image), sim-to-real transfer, and agentic error recovery under realistically noisy and diverse web scenarios.
The pipeline’s compositional, modular nature also makes it adaptable for future inclusion of simulated backends, collaborative workflows, and additional forms of visual or interaction noise, which are necessary as agent benchmarks are pushed toward more challenging operational frontiers.
Conclusion
WebForge provides a robust methodology and implementation for multi-dimensional, strictly automated, browser agent benchmarking. Unlike previous methods, it supplies task generation, interactive web environment synthesis, real-web disturbance injection, and machine-verified solvability checks, all without human annotation. The dataset and empirical results validate the effectiveness and necessity of multi-axis difficulty control for comprehensive agent evaluation. This pipeline will underpin the next generation of RL/LLM research on practical and diverse browser automation agents, and its extension to automated training corpora is an obvious and promising avenue.