Ego2Web: A Web Agent Benchmark Grounded in Egocentric Videos
Abstract: Multimodal AI agents are increasingly automating complex real-world workflows that involve online web execution. However, current web-agent benchmarks suffer from a critical limitation: they focus entirely on web-based interaction and perception, lacking grounding in the user's real-world physical surroundings. This limitation prevents evaluation in crucial scenarios, such as when an agent must use egocentric visual perception (e.g., via AR glasses) to recognize an object in the user's surroundings and then complete a related task online. To address this gap, we introduce Ego2Web, the first benchmark designed to bridge egocentric video perception and web agent execution. Ego2Web pairs real-world first-person video recordings with web tasks that require visual understanding, web task planning, and interaction in an online environment for successful completion. We utilize an automatic data-generation pipeline combined with human verification and refinement to curate well-constructed, high-quality video-task pairs across diverse web task types, including e-commerce, media retrieval, knowledge lookup, etc. To facilitate accurate and scalable evaluation for our benchmark, we also develop a novel LLM-as-a-Judge automatic evaluation method, Ego2WebJudge, which achieves approximately 84% agreement with human judgment, substantially higher than existing evaluation methods. Experiments with diverse SoTA agents on our Ego2Web show that their performance is weak, with substantial headroom across all task categories. We also conduct a comprehensive ablation study on task design, highlighting the necessity of accurate video understanding in the proposed task and the limitations of current agents. We hope Ego2Web can be a critical new resource for developing truly capable AI assistants that can seamlessly see, understand, and act across the physical and digital worlds.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A clear, simple guide to “Ego2Web: A Web Agent Benchmark Grounded in Egocentric Videos”
1. What is this paper about?
This paper introduces Ego2Web, a new test (called a benchmark) for AI assistants that need to do two things at once:
- see and understand the real world from a person’s point of view (like through AR glasses), and
- then use that information to complete tasks on the internet (like buying the exact snack you picked up in a video).
Most current web AIs only look at web pages or text. Ego2Web adds real-world, first-person video so the AI has to “look around,” understand what it sees, and then act online based on that.
2. What questions are the researchers asking?
The paper focuses on a few simple questions:
- Can we build a reliable test that checks whether AI can connect what it sees in the real world to actions on the web?
- How do today’s best AI agents perform on tasks that require both visual understanding (from first-person videos) and smart web actions?
- Can we automatically and fairly grade these agents without always needing humans to watch and judge?
3. How did they do it? (Methods explained simply)
Think of the process like making a school assignment and a fair grading system for an AI.
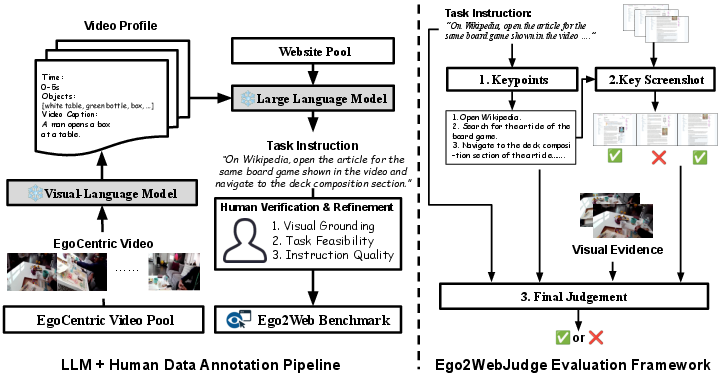
First, they built the assignment (the Ego2Web benchmark):
- They collected first-person videos (egocentric videos), like someone shopping or doing tasks at home.
- An AI “watched” each video and wrote short, time-stamped descriptions every few seconds. This makes a “video profile,” like a written summary of what’s in the video (e.g., “red soda can,” “blue backpack,” “brand logo on a toaster”).
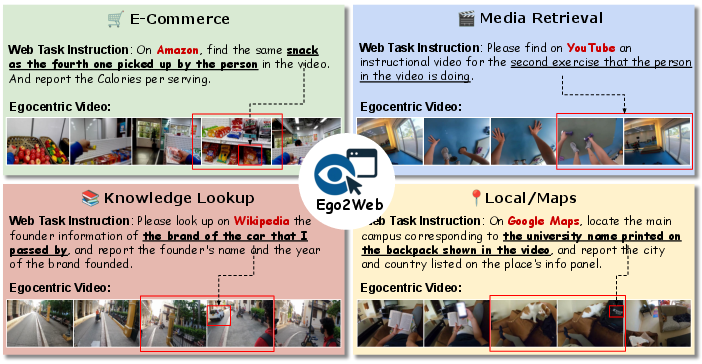
- Another AI used these summaries, plus a list of popular websites (Amazon, YouTube, Wikipedia, maps, etc.), to write realistic tasks that require using what’s in the video. Example: “Find and buy the exact headphones shown in the video,” or “Look up information about the museum in the video.”
- Humans checked each task to make sure it:
- really depends on something visible in the video,
- can be done on the chosen website,
- is clearly written.
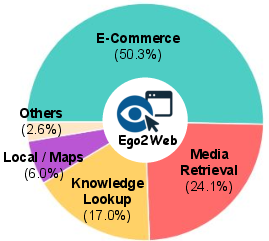
- Result: 500 high-quality video + web-task pairs across e-commerce, media search, knowledge lookup, maps/navigation, and more.
Second, they built a fair automated grader (Ego2WebJudge):
- Imagine a teacher’s checklist. The system turns each task into key points (like “correct brand,” “correct color,” “correct product page”).
- It picks the most important screenshots from the AI agent’s web-browsing steps (to avoid reviewing dozens of unimportant pages).
- It compares the AI’s final answer and web steps to the key points and the actual video evidence (the relevant video clip or frames).
- Using a large AI model as a judge (LLM-as-a-judge), it decides success or failure, much like a referee who can watch the play and read the rules.
Simple analogies:
- “Egocentric video” = first-person view, like what you see through your own eyes.
- “Video profile” = a written summary of important moments in the video.
- “LLM-as-a-judge” = a smart AI acting like a fair grader that checks the AI’s work against the video and the instructions.
4. What did they find, and why does it matter?
Main findings:
- Current AI agents struggle with these real-world + web tasks. Even the best one succeeded in a bit over half the tasks (around 59%), showing lots of room to improve.
- Tasks that only need looking up knowledge (like Wikipedia) are easier; tasks involving maps or shopping—where details like brand, color, and exact matching matter—are harder.
- Agents that can truly “watch” the video (not just read a text summary of it) do much better. When an agent has no visual input, performance drops dramatically.
- Their automatic grader, Ego2WebJudge, matches human judgments about 84% of the time—better than older grading methods. This means we can scale up testing without needing humans to hand-check every result.
Why it matters:
- Real assistants (on phones, AR glasses, home robots) need to connect what they see with what they do online. Ego2Web shows that this is still hard, and it gives a solid way to measure progress.
- A reliable automatic grader saves time and makes it easier for researchers to improve their systems quickly.
5. What’s the bigger impact?
This work pushes AI toward being more helpful in everyday life—connecting the physical and digital worlds. Here’s what it could lead to:
- Smarter shopping helpers that find the exact item you saw in real life.
- Better personal assistants that understand your surroundings and then book, buy, or research things online for you.
- Stronger, more trustworthy evaluation tools so companies and researchers can test and improve these assistants faster and more fairly.
In short, Ego2Web is a new “bridge” between seeing the real world and taking action on the web. It shows where today’s AI falls short and provides the tools to help it get better.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes concrete gaps and open issues left unresolved by the paper that future work could address:
- Benchmark scale and coverage:
- Only 500 video–instruction pairs are provided; it’s unclear if this size sufficiently captures the diversity of egocentric scenes, tasks, and websites to support robust benchmarking.
- Task/domain coverage is limited to a curated set of “popular” sites; long-tail domains, enterprise tools, and mobile apps are not included.
- Tasks are predominantly English and appear US/Global-North centric; cross-lingual, locale-specific, and region-locked sites are not addressed.
- Data source and generation biases:
- All videos are sourced from Ego4D; the extent to which this single-source sampling biases content (e.g., activities, environments, demographics) is not quantified.
- The pipeline relies on Qwen3-VL for dense captions and GPT-5 for task generation; error propagation and stylistic biases from these models are not analyzed.
- No inter-annotator agreement or quantitative QA metrics are reported for human verification/refinement of tasks and visual evidence clips.
- Visual evidence annotation and scalability:
- The process for selecting/annotating “egocentric visual evidence clips” used by the judge (v) is not fully specified (who annotates, guidelines, time cost, consistency checks).
- It is unclear how scalable and maintainable this annotation is as the benchmark grows or websites evolve.
- Reproducibility of online evaluation:
- Live web evaluation introduces nondeterminism (A/B tests, dynamic content, ads, pop-ups, CAPTCHAs, rate limits, geofencing, time-dependent changes) not controlled or logged.
- Browser/OS settings (user agent, viewport size, extensions, cookie policies, locale, time zone, network) are not standardized or reported, limiting reproducibility.
- No versioning or “frozen snapshot” strategy is described to handle task drift/website changes over time.
- Evaluation fairness across agents:
- Some agents cannot ingest raw video and are forced to use textual captions, confounding comparisons of “agent capability” with “input modality availability.”
- No standardized perception interface (e.g., canonical video frames/features) is provided to level the playing field across agents with different media I/O capabilities.
- Metric design and reliability:
- Ego2WebJudge achieves ~84% agreement with humans, but the remaining ~16% disagreement is not characterized (error types, categories, or causes).
- The judge’s key steps (keypoint extraction, screenshot selection threshold δ, screenshot summarization) are not ablated for sensitivity or failure modes.
- Binary Success/Failure scoring lacks partial credit for completing subsets of keypoints; no measures of efficiency, safety, or side effects are reported.
- Potential for Goodharting remains: agents might optimize surface features in final responses to satisfy the judge; guardrails against evaluation gaming are not discussed.
- Dependence on LLM-as-a-judge:
- The evaluator depends on specific MLLMs (e.g., GPT-4o, Gemini-2.5 Pro); stability across model updates and cross-model consistency over time are not analyzed.
- No calibration across task types/domains or per-category reliability of the judge is reported.
- Circularity risks exist: the same model family (or closely related models) is used for dataset construction and evaluation (task generation vs. judging), which may bias outcomes.
- Task design limitations:
- The benchmark focuses on bridging recognition/grounding to single-website actions; multi-website, cross-session, or very long-horizon workflows are underrepresented.
- Audio, speech, OCR-from-video nuances, gaze, depth, or other egocentric modalities are not included, limiting ecological validity for real wearables/AR use cases.
- Temporal reasoning difficulty is not quantified (e.g., tasks requiring long-range spatiotemporal grounding vs. single-frame cues).
- Safety and ethics:
- Executing real actions (e.g., purchases) on live sites raises safety/cost/ethical concerns; mechanisms to simulate or safely sandbox transactional steps are not detailed.
- Privacy considerations for egocentric content (e.g., incidental PII, sensitive scenes) are not discussed beyond sourcing from a public dataset.
- Robustness and generalization:
- Robustness to common egocentric video artifacts (motion blur, occlusion, low light), and to adversarial or ambiguous visual cues, is not evaluated.
- Sensitivity to different video inputs (keyframe rate, resolution, compression) and captioning quality is only partially explored; no systematic ablation on video sampling policies.
- No analysis of agent robustness to substantial website UI changes or content distribution shifts.
- Experimental design details:
- The reported “~40% gap from oracle performance” is not rigorously defined (what is the oracle, how it’s estimated), limiting interpretability of headroom.
- Step limit (40) sensitivity is not studied; trade-offs between action budget and success rates remain unknown.
- Failure analysis for agents is high-level; a structured taxonomy of failure modes (perception, grounding, navigation, form-filling, decision errors) is not provided.
- Dataset maintenance and versioning:
- There is no plan for continuous validation, deprecation of broken tasks, or benchmark versioning as websites evolve.
- Full lists of target sites and prompts are referenced but not fully specified in the main text; precise reproducibility depends on appendices/external assets.
- Extending the task space:
- Cross-lingual and locale-aware evaluation (localized sites, non-Latin scripts) remains unexplored.
- Integration with OS-level actions, mobile app environments, and mixed-ecosystem workflows (web + OS/app switching) is out of scope but critical for real assistants.
- Real-time, streaming, and on-device AR settings (latency constraints, incremental perception) are not evaluated.
- Training vs. evaluation:
- The benchmark is evaluation-only; guidance on standardized training splits, or protocols for fine-tuning without leaking test content, is not provided.
- Human evaluation process:
- Human evaluation uses 3 annotators with majority vote, but inter-annotator agreement and guidelines are not reported, leaving ambiguity about human ground-truth reliability.
- Release stability:
- Long-term reproducibility of both the judge and the benchmark is sensitive to third-party model/API changes; mitigation strategies (e.g., frozen judge checkpoints, offline artifacts) are not specified.
Practical Applications
Practical Applications of Ego2Web and Ego2WebJudge
Ego2Web introduces a new benchmark that connects egocentric video understanding with live web-task execution and a scalable, visually grounded evaluation framework (Ego2WebJudge). Below are concrete real-world applications derived from the benchmark, its semi-automatic data generation pipeline, and the LLM-as-a-Judge method, grouped by deployment horizon.
Immediate Applications
- Benchmark-driven QA and regression testing for web agents and AR assistants
- Sectors: software, e-commerce, AR/wearables
- Potential tools/products/workflows: integrate Ego2Web tasks and Ego2WebJudge into CI/CD to detect regressions in “see-and-act” capabilities across live websites; vendor scorecards for model/agent selection
- Assumptions/dependencies: access to the benchmark; ability to feed video or high-quality captions to agents; live-site variability handled via robust test harnesses
- Rapid prototyping of “see-and-buy” experiences
- Sectors: retail/e-commerce, marketing
- Potential tools/products/workflows: mobile/AR feature that captures short egocentric clips of products, grounds brand/color/shape, searches retailer sites, and adds matches to cart
- Assumptions/dependencies: reliable visual grounding (brand/logos/colors), product search APIs, user consent/privacy, fallback to human review
- Medication label verification before online ordering (pilot workflows)
- Sectors: healthcare, pharmacy
- Potential tools/products/workflows: capture label via phone/glasses; extract NDC/drug name/dosage; cross-check formulary; place refill/transfer on pharmacy sites
- Assumptions/dependencies: HIPAA/FDA compliance, pharmacist oversight, high-accuracy OCR and visual grounding, robust error handling
- Contextual knowledge lookup from real-world objects or scenes
- Sectors: education, consumer apps, travel
- Potential tools/products/workflows: identify museum artifacts, plants, monuments, or tools from egocentric video; retrieve authoritative resources (Wikipedia, university sites)
- Assumptions/dependencies: disambiguation for look-alike objects; sufficient video quality; site access
- Local/maps workflows triggered by real-world cues
- Sectors: mobility, travel, local services
- Potential tools/products/workflows: detect storefront/signage from video; open maps; fetch hours/reviews; plan route
- Assumptions/dependencies: accurate sign parsing; location permissions; changing site UIs
- Internal training/evaluation data creation using the semi-automatic pipeline
- Sectors: academia, AI labs, enterprise R&D
- Potential tools/products/workflows: generate task instructions from internal egocentric footage; human-in-the-loop validation to create domain-specific benchmarks (e.g., warehouses, kitchens)
- Assumptions/dependencies: annotator capacity and guidelines; data licensing/consent; domain diversity beyond the initial 500 samples
- “Judge-as-a-Service” for agent teams
- Sectors: software tooling, platform vendors
- Potential tools/products/workflows: hosted Ego2WebJudge to grade agent runs on live sites (keypoint extraction + key screenshot selection + outcome verdicts); regression dashboards
- Assumptions/dependencies: evaluation LLM availability/cost; log capture (actions, screenshots); acceptable 80–84% agreement with human judgments
- Accessibility prototypes for low-vision users
- Sectors: assistive technology, healthcare
- Potential tools/products/workflows: read labels/receipts and place online orders or fetch accessible resources
- Assumptions/dependencies: user consent, safety and confirmation loops, robust error handling
- Compliance/audit of autonomous agent actions
- Sectors: finance, healthcare, enterprise IT
- Potential tools/products/workflows: use Ego2WebJudge to audit web-agent action logs and screenshots for correctness and policy compliance
- Assumptions/dependencies: secure log storage and PII redaction; acceptance of LLM-judge as an internal audit aid (with human spot checks)
- Vendor/model comparison and procurement decisions
- Sectors: enterprise IT, operations
- Potential tools/products/workflows: standardized trials on Ego2Web across domains (e-commerce, media, knowledge, maps) to select agents/MLLMs
- Assumptions/dependencies: benchmark representativeness for target use cases; periodic updates to handle web drift
Long-Term Applications
- Real-time AR assistants that perceive and transact across the web
- Sectors: consumer electronics, AR/wearables, e-commerce
- Potential tools/products/workflows: always-on smart glasses that identify items, compare prices, apply coupons, and complete purchases securely
- Assumptions/dependencies: on-device/video-capable MLLMs, privacy-preserving pipelines, frictionless UX/payments, robust safety guardrails
- In-home inventory management with automatic replenishment
- Sectors: retail, smart home, logistics
- Potential tools/products/workflows: periodic kitchen/pantry scans to detect low stock and submit orders; user confirmation via app
- Assumptions/dependencies: retailer integrations, high-precision detection to prevent erroneous orders, fail-safes and approvals
- Clinical/home health agents for safe medication management
- Sectors: healthcare, home care
- Potential tools/products/workflows: verify medication identity/dose; check interactions; coordinate refills/insurance authorizations via web portals
- Assumptions/dependencies: regulation (FDA/HIPAA), clinician oversight for high-risk actions, near-perfect visual/OCR accuracy
- Field service copilots for technicians
- Sectors: manufacturing, energy/utilities, telco
- Potential tools/products/workflows: recognize equipment/part numbers from helmet cams; retrieve manuals; order replacements
- Assumptions/dependencies: enterprise system integrations (ERP/CMMS), domain-specific visual models, controlled network environments
- Embodied robots coordinated with web services
- Sectors: robotics, warehousing, hospitality
- Potential tools/products/workflows: robots perceive shelves via onboard cameras and place online procurement orders or schedule deliveries
- Assumptions/dependencies: reliable robot perception/control, safety certifications, end-to-end error recovery
- Classroom and lab assistants that “see and fetch”
- Sectors: education, research labs
- Potential tools/products/workflows: watch experiments; fetch protocols, safety sheets, or order missing reagents/equipment
- Assumptions/dependencies: institutional policies, role-based approvals, domain ontologies
- Autonomous transactions with embedded compliance layers
- Sectors: finance, insurance, procurement
- Potential tools/products/workflows: Ego2WebJudge-like modules as policy gates that evaluate visual context + web actions before committing payments or contracts
- Assumptions/dependencies: auditable action trails, standardized risk thresholds, alignment with legal/compliance teams
- Standardized certification frameworks for multimodal agents
- Sectors: policy/regulators, industry consortia
- Potential tools/products/workflows: publicly maintained, physically grounded benchmarks for certification of AR/web agents (safety, privacy, performance)
- Assumptions/dependencies: multi-stakeholder consensus, dataset governance and periodic updates
- Large-scale training curricula and RL environments combining egocentric video and web interaction
- Sectors: AI research, platform providers
- Potential tools/products/workflows: curriculum learning from captions → video → live web tasks; self-play/simulation with human-in-the-loop corrections
- Assumptions/dependencies: scalable data generation beyond 500 examples; compute; realistic simulators/live-site sandboxes
- Privacy-aware ad/rec systems that bridge real-world attention to online content
- Sectors: advertising, media
- Potential tools/products/workflows: opt-in systems that map viewed products/scenes to relevant content/deals online
- Assumptions/dependencies: strict consent and on-device processing, compliance with privacy laws (GDPR/CCPA), transparent controls
Cross-cutting assumptions and dependencies
- Video-capable MLLMs are still evolving; performance depends on high-fidelity video inputs (raw video > sparse keyframes > captions)
- Live websites change frequently; robust evaluation/automation requires resilient selectors, fallbacks, and regular benchmark updates
- Privacy, security, and regulatory compliance (especially for healthcare/finance) mandate human oversight, auditability, and explicit consent
- Ego2WebJudge shows ~84% agreement with humans—sufficient for triage and QA but not a substitute for human sign-off in high-stakes settings
- Dataset coverage (500 video–task pairs) should be expanded and diversified for domain-specific deployments
Glossary
- Ablation study: A controlled analysis where components or conditions are systematically varied or removed to assess their impact on performance. "We also conduct a comprehensive ablation study on task design, highlighting the necessity of accurate video understanding in the proposed task and the limitations of current agents."
- Agreement Rate (AR): A metric that measures how often an automatic evaluator’s judgments match human judgments. "Agreement Rate (AR) between human evaluation and automatic evaluation methods across agents."
- Binary judgment: An evaluation decision with two possible outcomes (e.g., Success or Failure). "It then prompts an MLLM to make a binary judgment on whether the agent successfully completed the visually grounded web task (more details in~\cref{eval})."
- Clip-level dense captions: Detailed textual descriptions generated for short video segments, capturing rich scene and object information. "we employ an MLLM (e.g., Qwen3-VL~\citep{qwen3technicalreport}) to produce clip-level dense captions describing both global scene context and local object details with a timestamp."
- DOM trees: The hierarchical Document Object Model structure representing elements of a web page used for programmatic interaction and analysis. "on-screen content (e.g., DOM trees, rendered pages, or video recordings) without grounding in the userâs physical visual context."
- Ego2WebJudge: The paper’s proposed automatic evaluation framework that uses an LLM to judge task success grounded in video evidence. "we also develop a novel LLM-as-a-Judge automatic evaluation method, Ego2WebJudge, which achieves approximately 84\% agreement with human judgment, substantially higher than existing evaluation methods."
- Egocentric video perception: Visual understanding from a first-person point of view, capturing what a user sees and does. "To address this gap, we introduce Ego2Web, the first benchmark designed to bridge egocentric video perception and web agent execution."
- Egocentric visual evidence: Video frames or clips from the user’s viewpoint that contain crucial information needed to solve a task. "and an annotated egocentric visual evidence clip that contains necessary information for task solving (e.g. object brand, shape, color and other visual attributes)"
- Key Screenshot Selection: A process that identifies the most relevant screenshots from an interaction history for focused evaluation. "(2) Key Screenshot Selection:"
- Key-Point Identification: Extracting the critical requirements or goals from instructions to assess task success. "(1) Key-Point Identification: Given the task instruction , we first ask the LLM to extract critical key points from , defining what must be achieved for success (e.g., specifying an item, location, or attribute)."
- LLM-as-a-Judge: An evaluation paradigm where a LLM is tasked with judging whether an agent has successfully completed a task. "we also develop a novel LLM-as-a-Judge automatic evaluation method, Ego2WebJudge, which achieves approximately 84\% agreement with human judgment"
- Model–human collaborative pipeline: A data creation workflow combining automated model generation with human verification and refinement. "To construct Ego2Web, we design a modelâhuman collaborative pipeline that automatically synthesizes visually grounded web tasks."
- Multimodal LLMs (MLLMs): LLMs that can process and reason over multiple data modalities, such as text, images, and video. "The rapid advancement of Multimodal LLMs (MLLMs)~\citep{hurst2024gpt,bai2025qwen3,li2024llava,seed2} and web-based agents~\citep{tongyidr,openai2025operator,bai2025qwen25vltechnicalreport,anthropic2025computeruse} has enabled impressive progress"
- Online evaluation setting: Assessing agents on live websites rather than in controlled or simulated environments. "our Ego2Web follows the online evaluation setting~\citep{xue2025illusion, he2024webvoyager, yoran-etal-2024-assistantbench, pan2024webcanvas-m2wlive} that evaluate web agents on live, real-world websites rather than in a static, pre-defined sandbox"
- Oracle performance: An estimated upper-bound or idealized performance level used for comparison. "about 40\% gap) from the oracle performance according to human evaluation for improvement across all agents."
- Perception–action alignment: The consistency and coordination between what an agent perceives and the actions it takes. "revealing their significant limitations in visual grounding, reasoning ability, and perceptionâaction alignment on Ego2Web."
- Sandboxed browser environment: A controlled, isolated browser setup used to enable reproducible experiments. "introduced a sandboxed browser environment for controlled, reproducible evaluation."
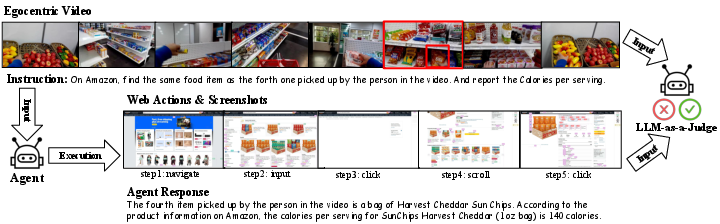
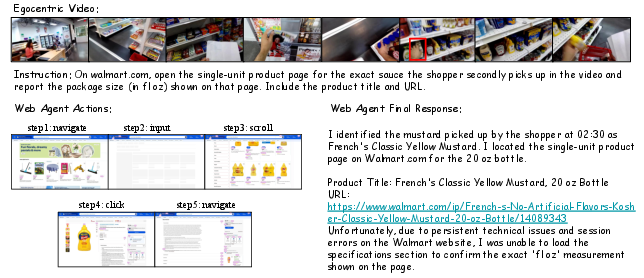
- Spatio-temporal grounding: Locating and linking relevant visual elements across both space and time within a video. "the agent must first perform spatio-temporal grounding to identify the relevant visual cue (e.g., the fourth snack picked up in the video), and then execute corresponding web actions"
- Temporal segmentation: Dividing a video into time-based segments, often for analysis or labeling. "and temporal segmentation from real-world wearable cameras."
- Unconstrained online evaluation setting: Testing agents in live environments without restrictive controls, reflecting real-world variability. "under an unconstrained online evaluation setting, forming a new testbed for multimodal agents grounded in the real-world visual perception."
- Video-language reasoning: Inferring and answering questions by jointly understanding video content and language. "advance the field toward higher-level video-language reasoning and commonsense understanding"
- Visual grounding: Linking linguistic or task references to specific visual content in an image or video. "revealing their significant limitations in visual grounding, reasoning ability, and perceptionâaction alignment on Ego2Web."
- Web execution reasoning: Planning and performing stepwise actions on the web to achieve task goals based on perceived information. "Web Execution Reasoning: according to the video perception, planning and executing step-by-step web actions to complete the task (e.g., navigating to a website, searching, scrolling on the page, clicking on the button)."
- Web trajectories: Sequences of web navigation steps and interactions taken by an agent during task completion. "As web trajectories can contain 5 to 20 steps, many of which are irrelevant (loading pages, backtracking, UI errors)."
Collections
Sign up for free to add this paper to one or more collections.