- The paper introduces a benchmark that challenges retrieval systems to locate a single webpage meeting multiple vague criteria from diverse domains.
- The paper details an LLM-driven automated pipeline for generating masked, ambiguous queries to simulate real-world exploratory search.
- The paper reveals considerable performance gaps between current automated agents and human experts, underscoring failures in multi-constraint semantic reasoning.
Needle in the Web: A Benchmark for Targeted Web Retrieval with Fuzzy Queries
Benchmark Motivation and Problem Definition
The "Needle in the Web" benchmark introduces a rigorous evaluation framework for search agents and LLM-based systems focused on retrieving specific webpages in open-domain, real-world conditions given vague, multi-faceted queries (2512.16553). Contemporary agent benchmarks such as BrowseComp and xBench-DeepSearch emphasize factoid-oriented, multi-hop reasoning, providing explicit and structured queries. These are insufficient for representing actual user behavior on the web, where queries are often semantically ambiguous, underspecified, or exploratory rather than direct.
"Needle in the Web" addresses Fuzzy Exploratory Search: tasks where queries encapsulate multiple implicit criteria, and the goal is to locate a single webpage satisfying the conjunction of these vague requirements. Unlike in complex reasoning QA, the agent cannot aggregate information from disparate sources—retrieval must yield one page meeting all criteria. This formalism aligns with real-world cognitive retrieval scenarios, challenging both the semantic parsing and web navigation capacities of autonomous agents.
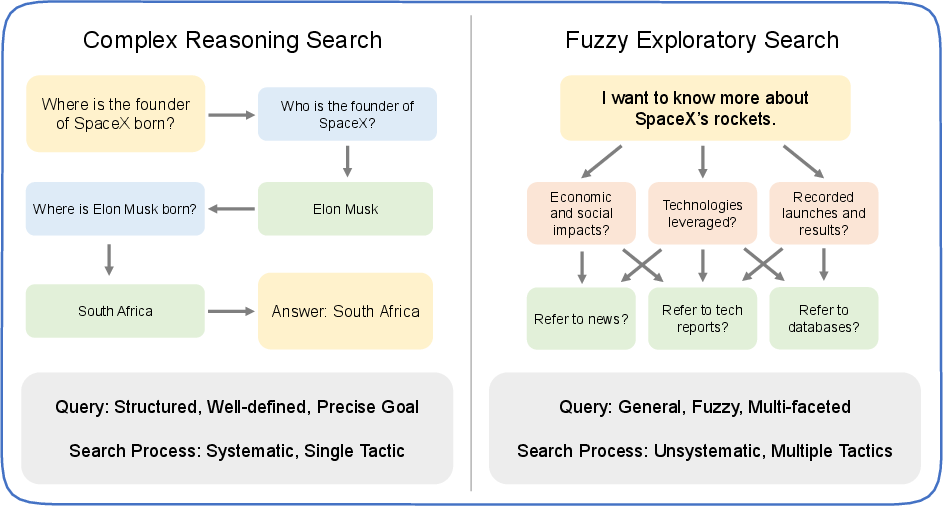
Figure 1: Contrasting paradigms—Complex Reasoning Search centers on explicit multi-hop factoid synthesis, while Fuzzy Exploratory Search requires identification and alignment with latent, multi-dimensional user intent.
Automated Query Generation and Dataset Design
The benchmark's construction leverages a systematic automated pipeline to synthesize candidate queries. Starting from real web pages sourced from seven diverse domains (ArXiv, OLH, Wikipedia, CNN, Pitchfork, Petapixel, Lonelyplanet), the process first extracts factual claims from each document via LLM prompting. These claims are ranked based on their embedding similarity to the source article, enabling fine-grained control over query difficulty. Hard queries select the most tangential claims, easy queries those closely related to the main topic.
To simulate fuzzy search, each claim is masked—central entities (names, locations, key terms) are obfuscated with generic placeholders (e.g. "someone" or "a certain species"), severing direct string matching and requiring semantic inference. Agents receive a set of three such masked statements per query and must retrieve the single matching webpage.
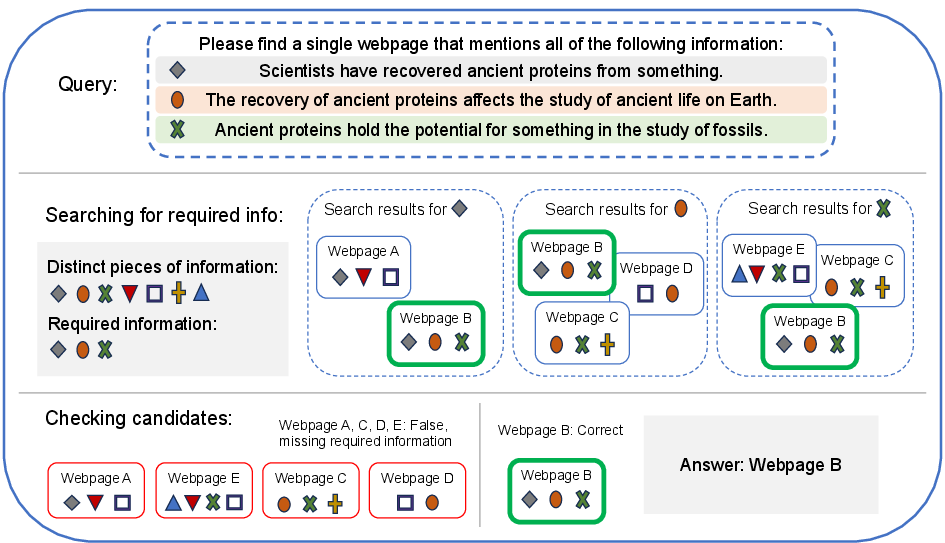
Figure 2: Illustration of a sample Needle in the Web query—target content must simultaneously satisfy all vague requirements, sharply increasing retrieval difficulty.
A secondary LLM-driven validation ensures that for each query, only one or at most a negligible number of real webpages fulfill all requirements, which is empirically supported by ablation during evaluation.
Evaluation Protocol and Judging Mechanism
Unlike prior tasks, exact-match string comparison is unsuitable for candidate evaluation due to URL multiplicity and content replication across the web. Thus, answer pages are scored using an LLM-as-a-judge protocol that verifies, at the semantic entailment level, whether all input criteria are satisfied by the document. This model—citing the strengths of LLMs in NLI and long-context comprehension—enables robust and reliable correctness adjudication, well-aligned with the natural error modal in this retrieval setting.
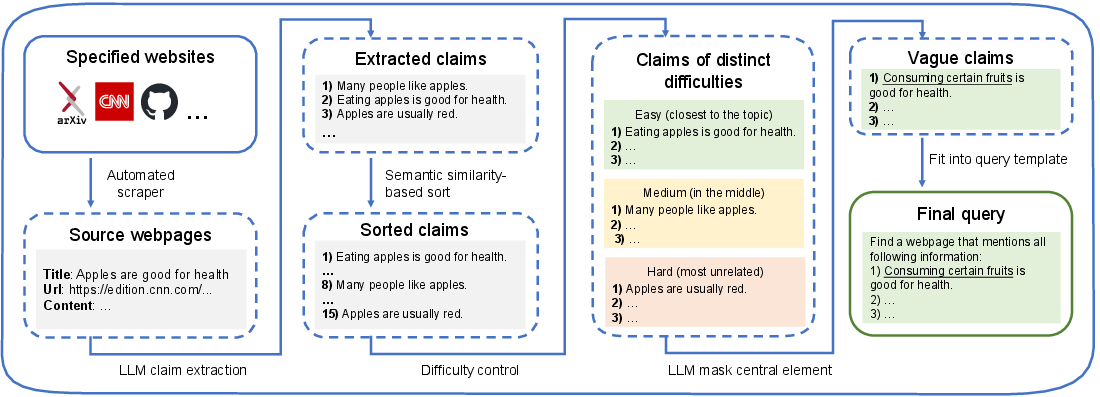
Figure 3: The automated pipeline for query creation integrates claim extraction, masking, difficulty calibration, and LLM validation to achieve high-quality, scalable benchmark construction.
Six state-of-the-art systems (GPT-4o, Gemini-2.5-flash, Perplexity Sonar; Search-R1, DeepResearcher, CognitiveKernel-Pro) are evaluated. None surpasses 35% accuracy on the overall dataset; wide variance is seen across domains and difficulty levels. Even with the most powerful proprietary LLMs, performance deteriorates sharply as query ambiguity increases, with success rates below 15% at the hard setting.
(Figure 4)
Figure 4: Accuracy of major agent frameworks by source domain reveals strong performance stratification and failure to generalize robustly outside academic, well-formed text collections.
Human expert baseline provides critical calibration: average completion rates are considerably higher (85.7% on easy and 78.6% on hard), with modest effort (sub-7 minutes/query), empirically demonstrating that the benchmark difficulty is not artificially inflated but traces real-world user capability boundaries.
Figure 5: Illustration of agent error patterns—including misunderstanding of search APIs, improper tool invocation, and semantic entailment failure.
Key empirical observations:
- Semantic intersectionality is highly challenging: Most agents locate partial matches or pages satisfying some, but not all, criteria, revealing deficiencies in multi-constraint reasoning.
- Major toolchain inefficiencies and breakdowns: Open-source agents suffer significant failure rates from shallow content extraction, brittle HTML parsing, and improper document chunking which disconnects criteria co-appearance.
- Closed-source agents are more query-efficient, typically succeeding or failing with fewer search API invocations; open frameworks often enter unproductive cycles or repeat global queries without context-sensitive refinement.
- No evidence for “winner-take-all” agents: There is high volatility and no system reliably leads across both domain and difficulty axes.
Practical and Theoretical Implications
"Needle in the Web" reveals critical weaknesses in current LLMs and agentic architectures for modeling implicit information needs, transforming fuzzy linguistic constraints into actionable search strategies, and robustly disambiguating and verifying semantically-aligned web content. The findings invalidate the assumption that scaling LLMs or basic fine-tuning suffices for real-world web agency—improvements in multi-constraint reasoning, search tool understanding, and context-aware interaction are imperative.
Practically, the benchmark is immediately relevant for agents intended for tasks such as personal research assistantship, discovery in poorly structured information landscapes, or exploratory Q&A where incomplete or vague input is the norm. Theoretically, it provides a well-grounded minimal testbed for progress on human-like retrieval, multi-criteria inference, and iterative interactive search. Its modular design facilitates future extension to datasets with richer modalities, time-evolving corpora, and non-English content, enabling longitudinal assessment of system improvement.
Conclusion
This benchmark provides a novel diagnostic for retrieval-centric agent development in scenarios where semantic ambiguity and constraint intersection are fundamental. Current models, despite sophistication in multi-hop and RAG paradigms, exhibit substantial limitations—rarely surpassing one-third accuracy and consistently failing to generalize across varied site structures and content themes. Improvements in search tool utilization, semantic notion of relevance, and robust context integration are essential to bridge the gap to human-level exploratory search proficiency.
"Needle in the Web" thus stands as an indispensable evaluation suite for advancing the robustness, flexibility, and real-world applicability of agentic AI.
References
See (2512.16553) for detailed methodology, data/code, and comprehensive results.