- The paper introduces OmniUMI, a unified multimodal interface that captures tactile, force, and visual inputs for robot learning.
- It details a human-aligned acquisition paradigm using compact hardware to ensure collection-deployment consistency and precise force regulation.
- Experimental results demonstrate 100% success in contact-rich tasks, highlighting the importance of integrating physically meaningful signals.
Physically Grounded Robot Learning via Human-Aligned Multimodal Interaction: A Technical Analysis of "OmniUMI" (2604.10647)
Introduction and Motivation
"OmniUMI: Towards Physically Grounded Robot Learning via Human-Aligned Multimodal Interaction" addresses a central barrier in scalable robot learning: the dominance of visuomotor data and the lack of physically grounded interaction signals such as tactile, internal grasp force, and environmental wrenches. While Universal Manipulation Interface (UMI) and its successors have enabled practical, robot-free demonstration acquisition at scale, these pipelines are primarily limited to geometric trajectories and vision-centric feedback. This constraint fundamentally limits generalization and robustness for contact-rich manipulation tasks, where reliance on visual modalities obscures critical, fine-grained force and contact dynamics.
This paper systematically bridges the sensing, interface, and deployment gaps by introducing a unified, reusable, and physically consistent multimodal interface (OmniUMI) for data acquisition and imitation learning, explicitly designed to maintain human-aligned data streams and controller-compatible downstream deployment. The paper's core claim is that to achieve robust contact-rich manipulation, physically meaningful interaction variables must be systematically sensed, perceptible during demonstration, embedded in the data, and interpretable by high-capacity multimodal policies that are compatible with practical impedance control deployments.
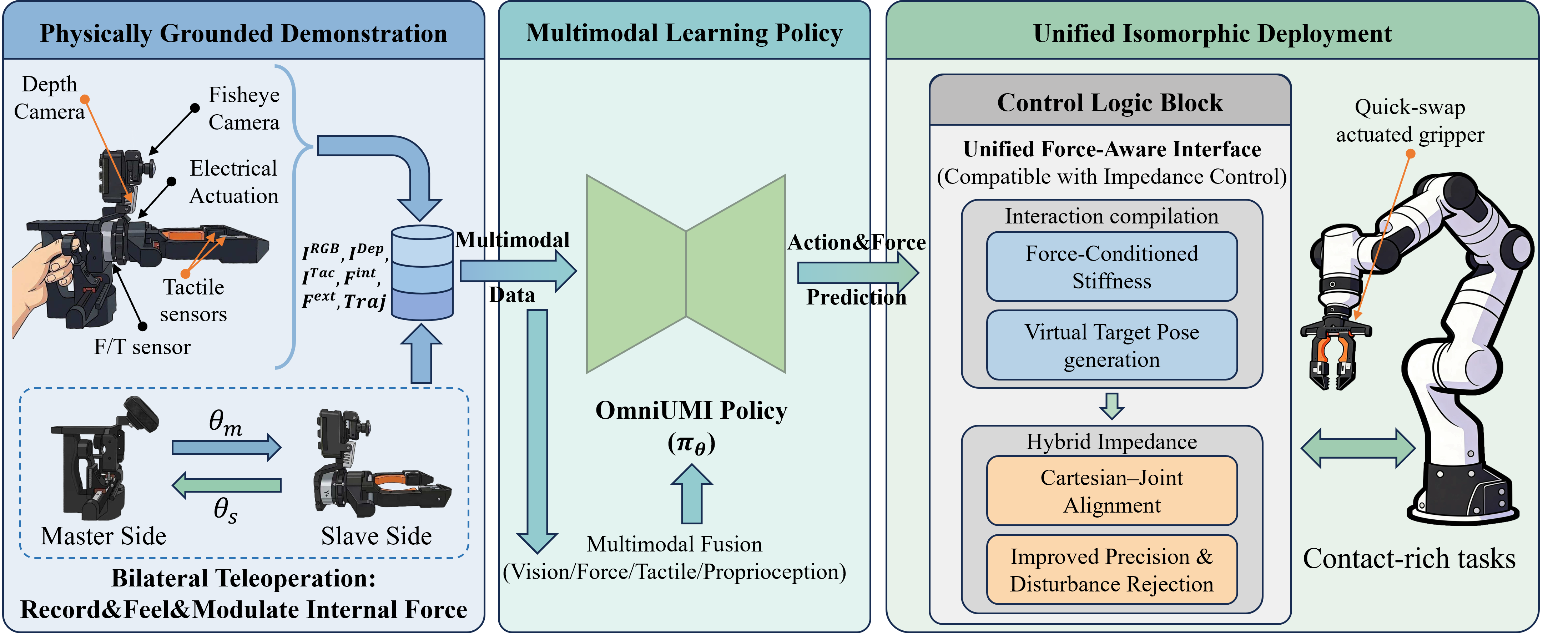
Figure 1: OmniUMI overview—integrated multimodal interface, policy learning, and impedance-compatible execution pipeline for contact-rich manipulation.
OmniUMI Hardware and Interface Architecture
OmniUMI is architected as a compact, handheld demonstration device that synchronously acquires:
- Visual (RGB-D fisheye)
- 6-DoF trajectory
- Tactile images (biomimetic finger integration)
- Internal grasp force (via motor-side current with closed-form modeling)
- External interaction wrench (environmental force/torque via F/T sensor with robust compensation)
- Bilateral gripper force feedback (human-aligned control loop)
This set of modalities is integrated through a custom hardware hub that manages cross-modal communication, power, and device management in a form factor viable for both in-hand demonstration and deployment, with a motorized, easily swappable gripper serving identically in each phase to ensure deployment-collection embodiment alignment.
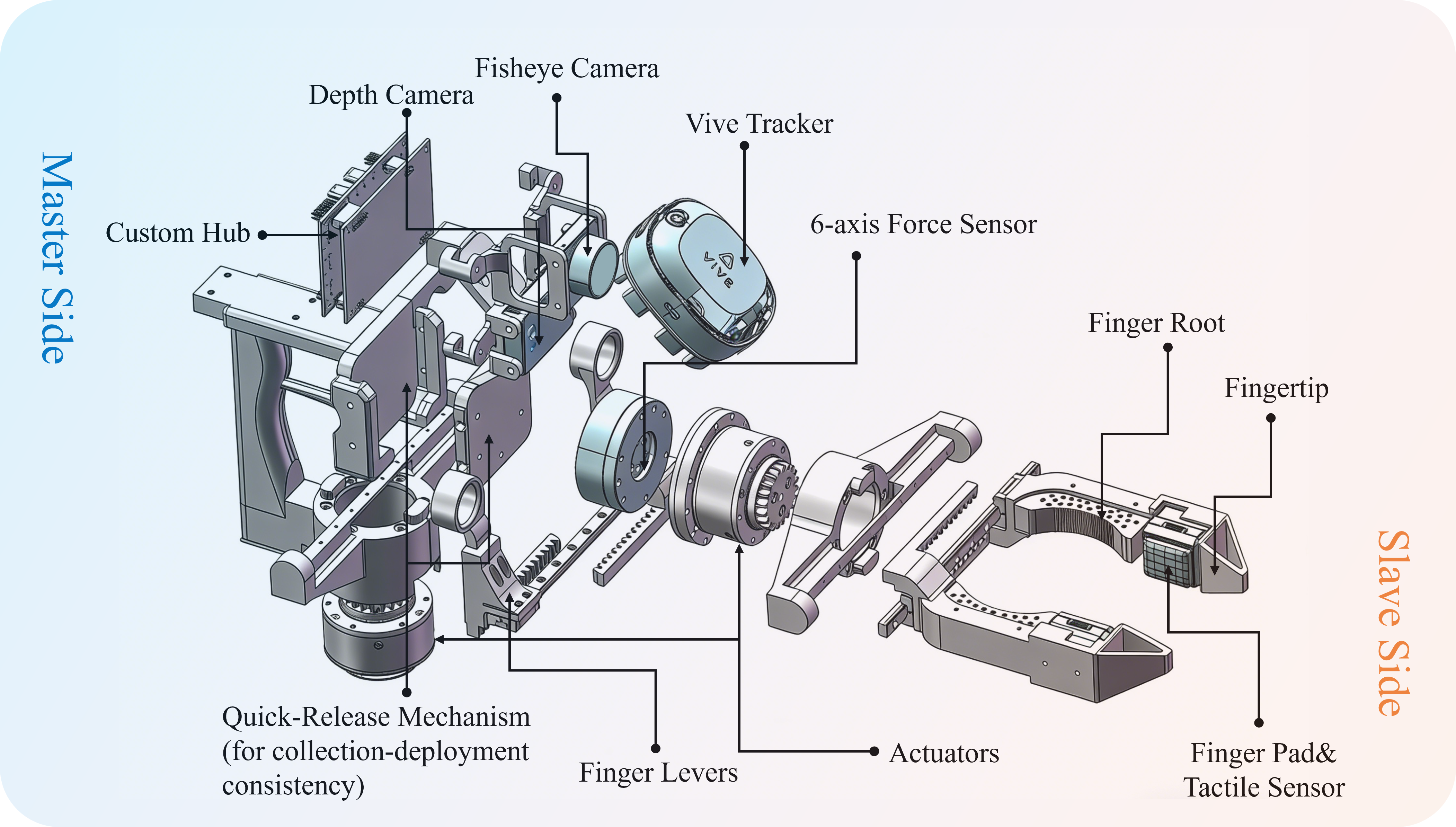
Figure 2: Compact interface design unifies motion tracking, tactile and force sensing, and deployment-consistent actuation within a reusable demonstration/robot platform.
Key novel aspects include:
- Collection–deployment consistency via hardware reuse and motor-driven actuation to eliminate actuation-contaminated force signals
- Physically shielded, biomimetic tactile sensors to preserve manipulation dexterity and sensor durability
- System-level focus on synchronized, calibrated, and compensated multimodal acquisition, not just modular sensor addition
Human-Aligned Multimodal Acquisition Paradigm
Fundamental to OmniUMI is the principle of "human-aligned acquisition"—interaction signals (especially force) are not only measured but actively perceived and regulated via the handheld interface and bilateral feedback during demonstrations.
- Internal grasp force is rendered directly to the operator via a master–slave gripper control loop, where estimated actuation-side torques are converted to forces with closed-form models, and bilateral impedance tuning aligns force perception with motor commands:
Ftint≈rgkτit
where it is motor current, kτ the torque constant, and rg the transmission radius.
- External interaction wrench is acquired through a dedicated F/T sensor with robust gravity and bias compensation, and uniquely, the handheld design allows operators to "feel" the external wrench proprioceptively, supplementing the measured data. Raw measurements are coordinate-transformed and bias-compensated:
wtee=Ts→ee(wtraw−wtgrav)
- Tactile and visual signals are acquired synchronously as complementary modalities, with tactile images routed directly to the policy.
This paradigm ensures that the demonstration process maintains alignment between human intent, perception, and the recorded multimodal signals, closing the human-in-the-loop gap that is critical in force-sensitive and contact-rich manipulation.
Multimodal Policy Learning and Diffusion Policy Extension
The paper extends the Diffusion Policy framework [chi_diffusion_2024] for multimodal policy learning, integrating visual, tactile, internal force, and external wrench signals as inputs to a conditional U-Net backbone. The architecture encodes low-dimensional sensor streams and image data into a unified observation for denoising diffusion trajectory prediction, yielding actions suitable for closed-loop deployment.
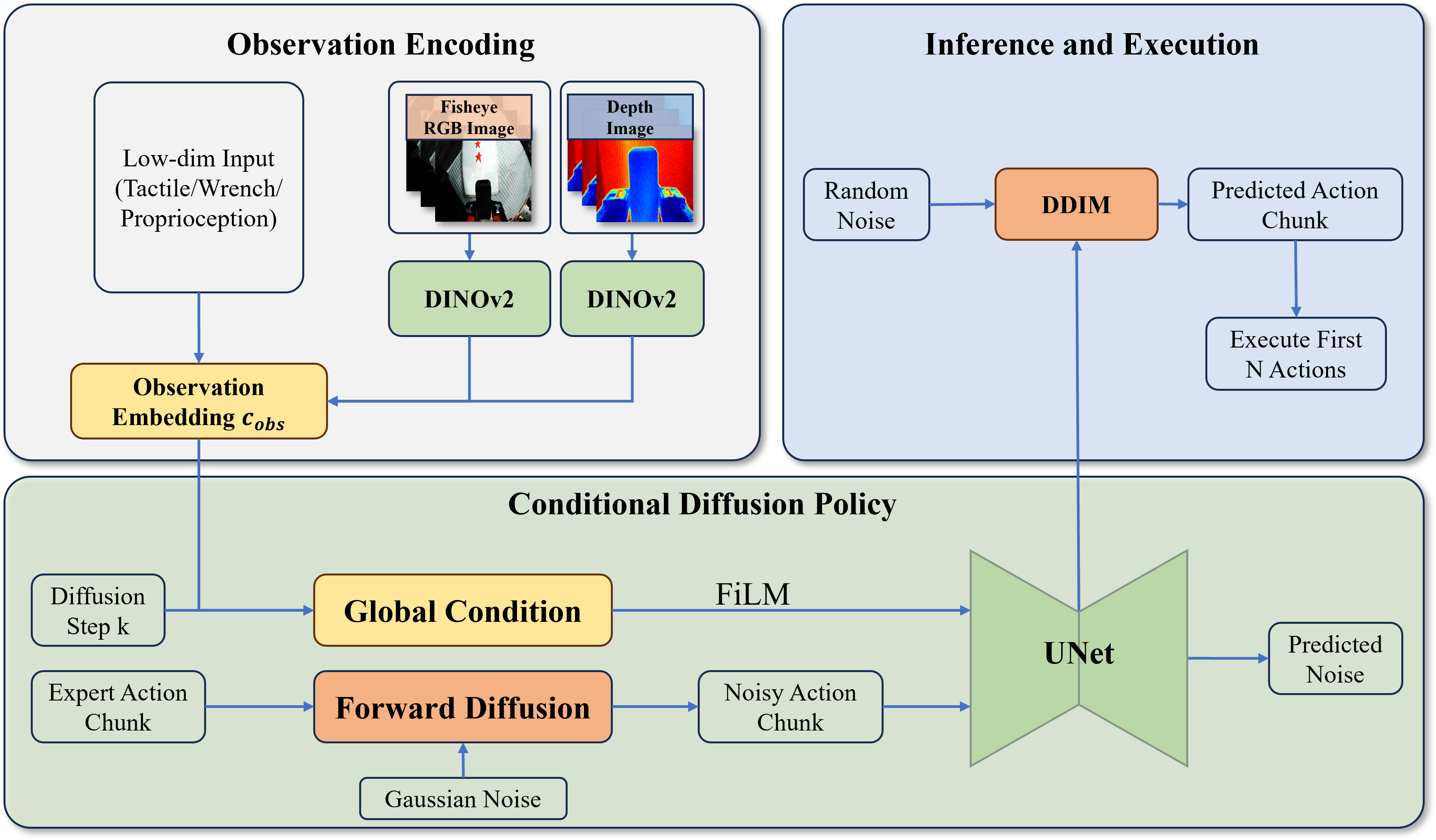
Figure 3: Multimodal diffusion-policy framework: visual/tactile/force observations are encoded, denoised via diffusion modeling, and decoded to receding-horizon action chunks for real-world deployment.
Action outputs are compact, consisting of end-effector displacements (translation, rotation), and gripper width, intentionally designed for compatibility with high-level impedance or virtual-target controllers.
A critical technical advance is the translation of multimodal policy outputs into an impedance-compatible controller interface. Policy-predicted forces and poses are jointly reparameterized as virtual targets with adaptive stiffness scheduling, enabling unified, continuous modulation of robot compliance and interaction force/precision without explicit mode switching:
Kp,t=diag(kx,t,ky,t,kz,t);Δpt=Kp,t−1ft;ptvt=ptref−Δpt
This architecture supports stable execution across robots with practical impedance controllers—a key system-level constraint in real-world deployment, especially for contact-intensive tasks.
Sensor Reliability and Force Signal Integrity
Gravity compensation and system-level bias removal for wrench sensing yield force readouts with negligible pose-dependent error across static orientations, ensuring that external force measurements are not confounded by sensor placement or embodiment (Figure 4).
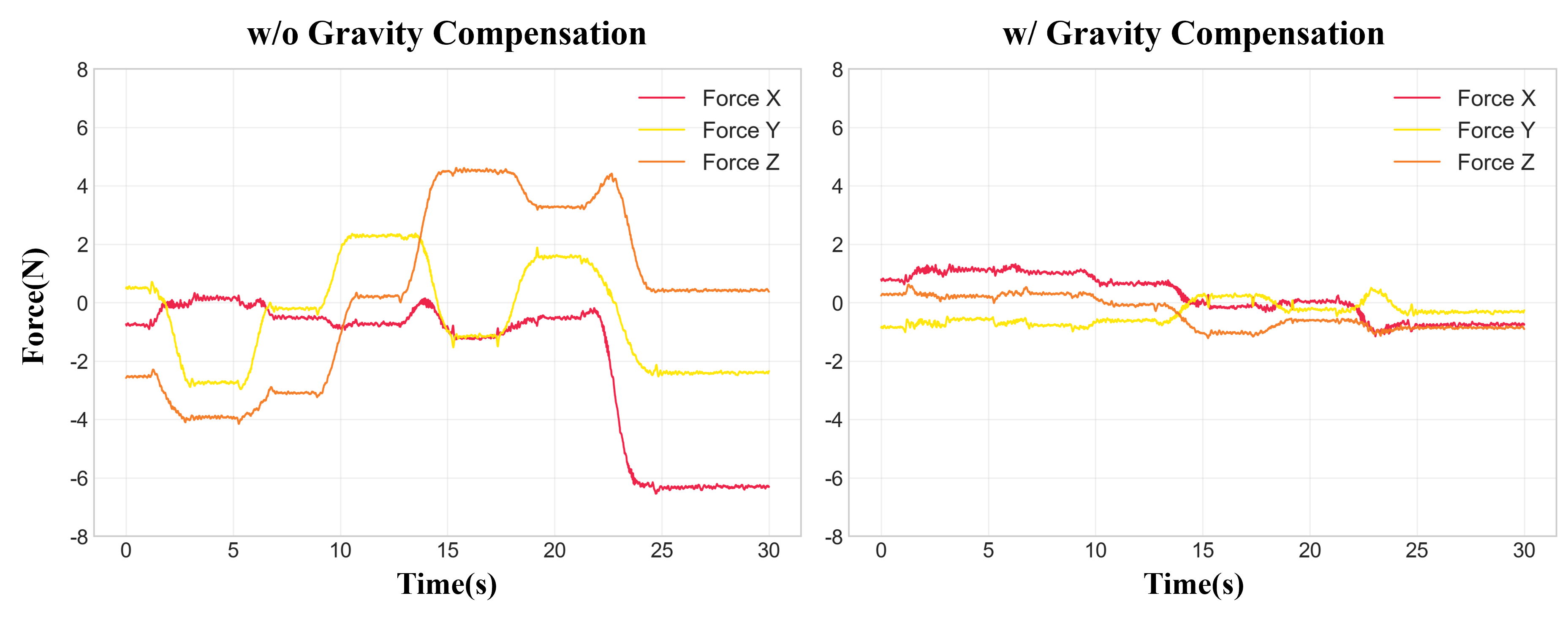
Figure 4: External force sensor readings before (left) and after (right) gravity compensation—post-compensated values cluster tightly around zero, validating sensor integrity.
Human-Aligned Demonstration Efficacy
OmniUMI's interface achieves:
- Temporal and magnitude alignment in contact forces between human and robot demonstrations (whiteboard wiping), with force trajectories and task durations closely matching those of direct human demonstrations as opposed to noisy, oscillatory teleoperated baselines (Figure 5).
- Substantial improvements in grasp force modulation and stability when bilateral feedback is enabled, aligning robot-collected grasp-force trajectories with those of direct human interaction (Figure 6).
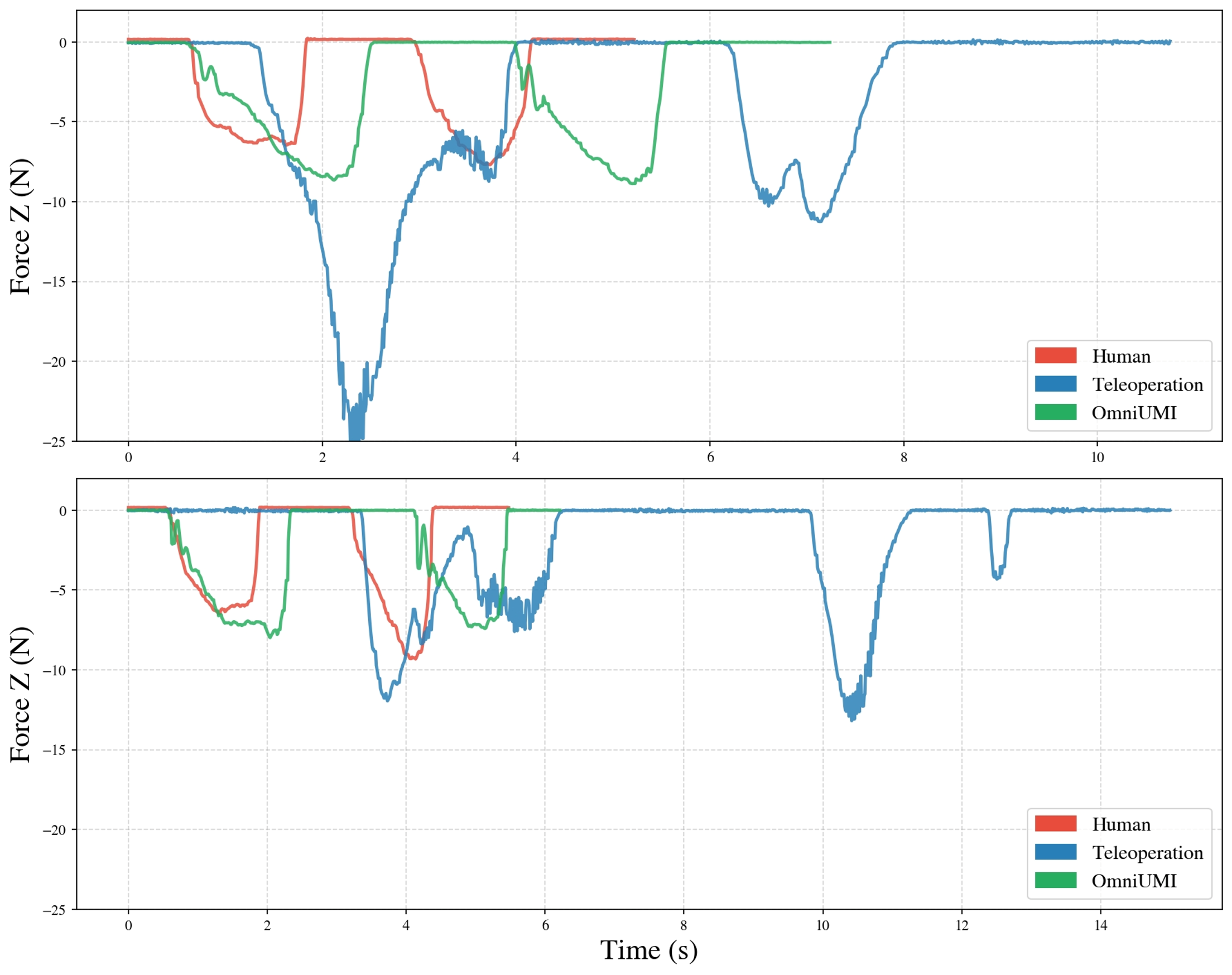
Figure 5: Comparison of Fz force profiles—OmniUMI data closely tracks direct human demonstrations; teleoperation is misaligned and oscillatory.
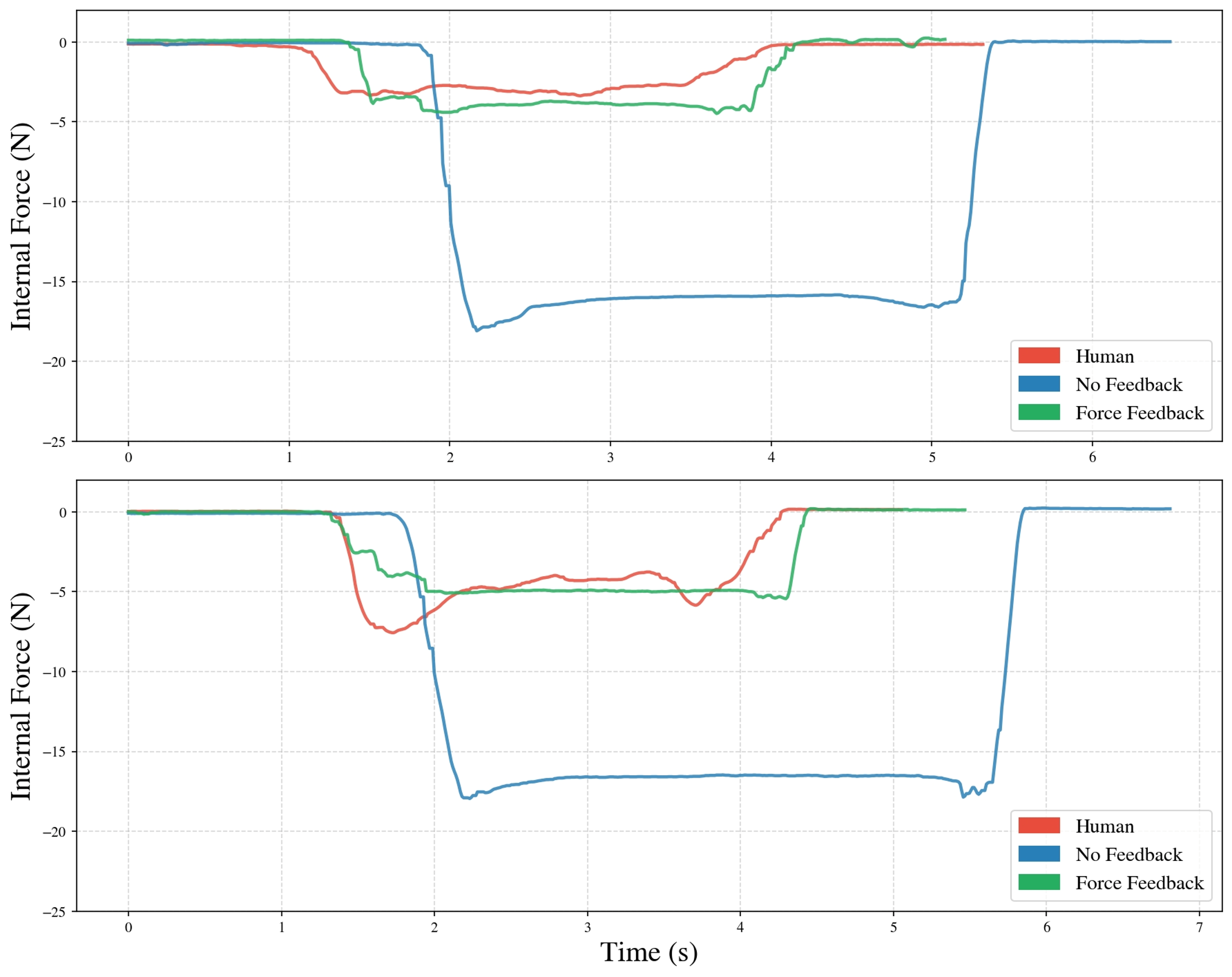
Figure 6: Internal grasp-force trajectories: only bilateral feedback produces stable, human-like regulation.
Three canonical tasks demonstrate the advantage of physically grounded, human-aligned multimodal learning:
- Force-Sensitive Pick-and-Place: Grasp-force-aware policies achieve 100% success lifting heavy objects, while baselines without force input fail entirely due to slippage and insufficient grasp stability. This demonstrates the necessity of real force awareness for nontrivial manipulation.
- Wrench-Informed Surface Erasing: Policies with external force input erase markings completely and achieve task durations/forces comparable to humans; vision-only baselines leave significant residue and exhibit unstable contact regulation (Figure 7).
- Tactile-Informed Selective Release: Tactile-enhanced policies achieve 100% success on the delicate task of releasing only the inner of two nested cups—vision-only policies fail catastrophically (Figure 8).

Figure 7: Qualitative results—top, grasp-force-aware policy lifts and transports heavy bottle; bottom, wrench-aware control erases whiteboard cleanly.

Figure 8: Tactile-informed selective release—successful fine-grained control is feasible only with real tactile input.
Each scenario robustly demonstrates that the combination of physically meaningful signal acquisition, human-aligned feedback, and controller-compatible deployments is required for high success in real-world contact-rich manipulation.
Discussion and Theoretical Implications
OmniUMI establishes that contact-rich robot learning cannot be adequately addressed by vision and geometry alone, regardless of dataset or model scale. Instead, the acquisition and downstream use of grounded interaction variables—explicitly accessible and modulated during human demonstration—are essential. By unifying tactile, force, and visual signals in a portable, collection–deployment-consistent interface and coupling this with high-capacity diffusion models and impedance-compatible deployment, the pipeline moves towards practical, scalable contact-rich robot learning.
The interface design directly implicates the phenomenon of "embodiment mismatch," showing that even minor divergences in sensing or actuation can severely degrade data and learned policy performance. In a broader AI context, this work emphasizes the systems-level integration and feedback alignment required to transition foundation models and large-scale data regimes from descriptive to interactive, physically effective embodied intelligence [liu_aligning_2024], [gao_physically_2023].
Recent related efforts in force-centric demonstration systems ("ForceMimic" [liu_forcemimic_2024]), tactile-informed learning pipelines ("TacDiffusion" [wu_tacdiffusion_2024]), and curriculum approaches for force attending ("FACTR" [liu_factr_2025]) reinforce the paper's findings: only with multimodal, physically grounded, and human-aligned signals can learning reliably transcend the limitations of visual or proprioceptive data, especially for generalization in contact-dense settings.
Future Directions
System limitations cited include the need for broader benchmarking across tasks and operator populations, further isolation of causal pathways from feedback-aligned data to policy performance, and the extension to more dexterous, long-horizon, and high-dimensional manipulation regimes. Integrating these physically grounded multimodal pipelines with vision-language-action (VLA) foundation models [dexvla_2025], [kim_openvla_2024], and benchmarking across the latest multi-embodiment datasets [roboMIND_2024], [all_robots_in_one_2024] will be crucial for scaling the paradigm to generalist embodied intelligence.
Conclusion
OmniUMI addresses the critical systems challenges in moving from scalable vision-based robot learning to scalable, physically grounded, multimodal learning that aligns with human intent and perception. Through a combination of tightly integrated hardware, human-aligned dual-force feedback, robust sensor compensation, and controller-compatible policy architectures, the paper demonstrates strong empirical gains—achieving perfect (100%) manipulation success in contact-rich tasks only when physically meaningful force and tactile signals are explicitly acquired and exploited.
The work establishes a technical and methodological foundation for large-scale, real-world, multimodal robot learning, with implications extending to foundation model integration, scalable imitation, and reinforcement learning grounded in physical, interactive embodiment.
References
- [chi_diffusion_2024] Diffusion Policy
- [liu_forcemimic_2024] ForceMimic: Force-Centric Imitation Learning
- [wu_tacdiffusion_2024] TacDiffusion: Force-domain Diffusion Policy
- [liu_factr_2025] FACTR: Force-Attending Curriculum Training
- [kim_openvla_2024] OpenVLA: An Open-Source Vision-Language-Action Model
- [dexvla_2025] DexVLA: Vision-LLM with Plug-In Diffusion Expert
- [liu_aligning_2024] Aligning Cyber Space with Physical World: A Comprehensive Survey on Embodied AI
- [gao_physically_2023] Physically Grounded Vision-LLMs for Robotic Manipulation
- [roboMIND_2024] RoboMIND Benchmark on Multi-embodiment Intelligence
- [all_robots_in_one_2024] All Robots in One: Unified Dataset for General-Purpose Embodied Agents