Learning Versatile Humanoid Manipulation with Touch Dreaming
Abstract: Humanoid robots promise general-purpose assistance, yet real-world humanoid loco-manipulation remains challenging because it requires whole-body stability, dexterous hands, and contact-aware perception under frequent contact changes. In this work, we study dexterous, contact-rich humanoid loco-manipulation. We first develop an RL-based whole-body controller that provides stable lower-body and torso execution during complex manipulation. Built on this controller, we develop a whole-body humanoid data collection system that combines VR-based teleoperation with human-to-humanoid motion mapping, enabling efficient collection of real-world demonstrations. We then propose Humanoid Transformer with Touch Dreaming (HTD), a multimodal encoder--decoder Transformer that models touch as a core modality alongside multi-view vision and proprioception. HTD is trained in a single stage with behavioral cloning augmented by touch dreaming: in addition to predicting action chunks, the policy predicts future hand-joint forces and future tactile latents, encouraging the shared Transformer trunk to learn contact-aware representations for dexterous interaction. Across five contact-rich tasks, Insert-T, Book Organization, Towel Folding, Cat Litter Scooping, and Tea Serving, HTD achieves a 90.9% relative improvement in average success rate over the stronger baseline. Ablation results further show that latent-space tactile prediction is more effective than raw tactile prediction, yielding a 30% relative gain in success rate. These results demonstrate that combining robust whole-body execution, scalable humanoid data collection, and predictive touch-centered learning enables versatile, high-dexterity humanoid manipulation in the real world. Project webpage: humanoid-touch-dream.github.io.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What’s this paper about?
This paper shows how to teach a human-shaped robot (a “humanoid”) to use its whole body and hands to do tricky, real-world tasks—like folding a towel, organizing books, inserting a tight-fitting part, scooping cat litter, and carrying tea. The key idea is to make the robot not just see, but also “feel” through touch sensors, and even learn to predict how things will feel a moment later. The authors call this “Touch Dreaming.”
What questions were the researchers trying to answer?
- How can a humanoid robot stay balanced while using its hands in tight, slippery, or delicate situations?
- Can adding touch (not just vision) make the robot much better at real-world, contact-heavy tasks?
- Is there a simple, single training setup that learns from human demonstrations and becomes good at many different tasks?
How did they do it? (Simple explanation with real-world analogies)
Think of the robot like a person learning a new sport:
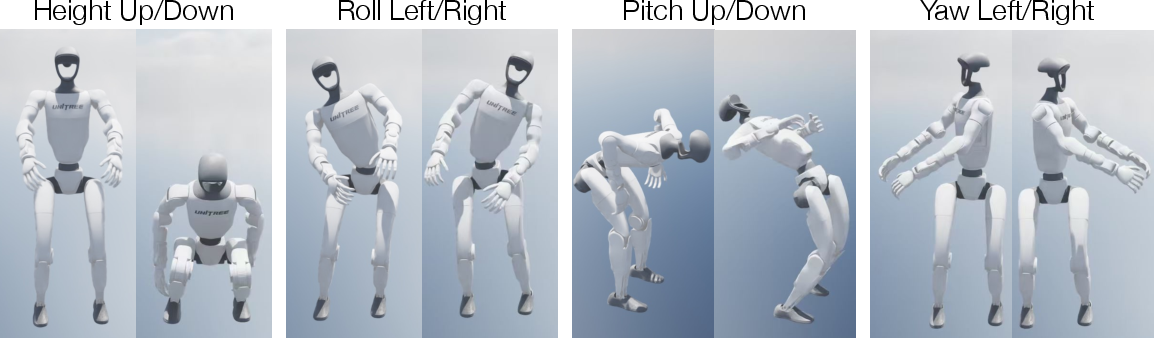
- A steady lower-body “autopilot”
- The team built a special controller (trained with reinforcement learning) that keeps the robot’s legs and torso steady—like a strong core that helps you balance while your hands do complicated moves.
- This “lower-body controller” listens to simple commands like “walk this way” or “lean this amount” and makes sure the robot doesn’t topple over.
- Learning from a human teacher in VR
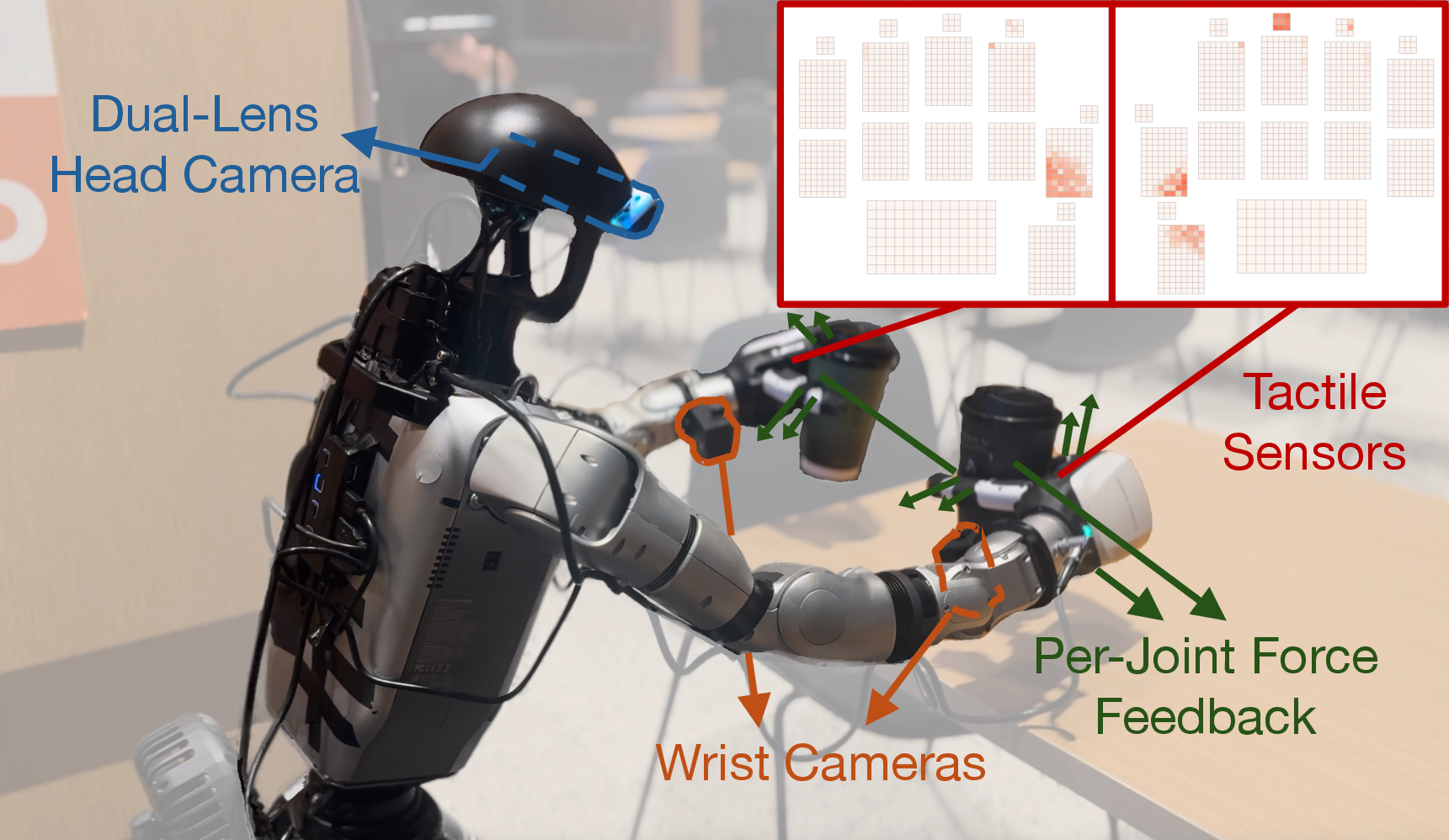
- A person wears a VR headset and “drives” the robot, showing it how to do tasks. Cameras on the robot’s head and wrists record what it sees; sensors record the robot’s body positions; and the robot’s hands have touch sensors that record what it feels.
- This creates a rich “how-to” dataset: what the human did (actions), what the robot saw (cameras), how it moved (body signals), and what it felt (touch and forces).
- A brain that uses eyes, body sense, and touch together
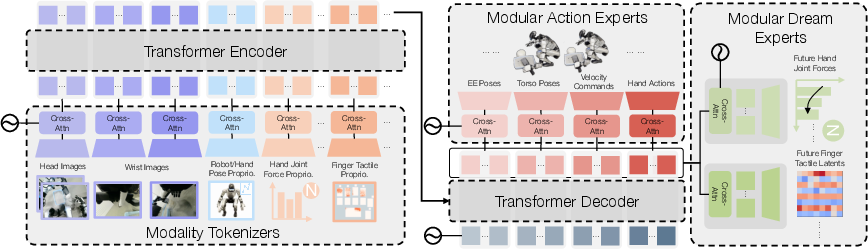
- The robot’s “brain” is a Transformer model called HTD (Humanoid Transformer with Touch Dreaming).
- It takes in:
- Multi-view vision (what the robot sees from head and wrist cameras),
- Proprioception (its own body and joint positions),
- Touch/force signals from the hands.
- “Touch Dreaming”: imagining future feel
- While learning from demonstrations, the model isn’t just told “copy these actions.”
- It is also trained to predict how the hands will feel a short time into the future—like imagining whether a book will slip, or if a plug will catch when it’s slightly misaligned.
- Instead of predicting every tiny bump in raw sensor data (which is noisy), the model predicts a cleaner “summary” of touch called a latent. A slowly updated “teacher” version of the touch encoder provides stable targets—like a coach who gives consistent feedback over time. This makes learning smoother and more reliable.
- At test time, the robot doesn’t need to keep predicting future touch; it uses what it learned to act more wisely in the moment.
- Planning a few steps ahead
- The policy outputs small chunks of upcoming actions each time (like planning the next few moves instead of just the very next move). This helps it stay smooth and stable.
What did they find, and why does it matter?
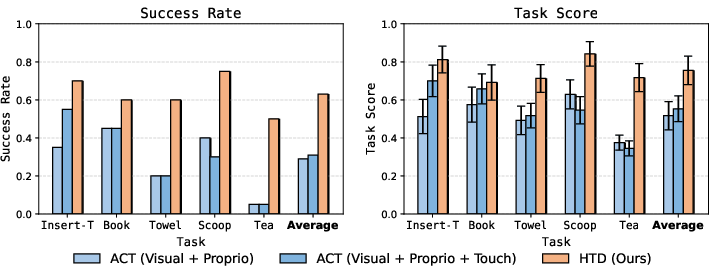
- Big performance gains across five tough, contact-heavy tasks:
- Insert-T: Putting a T-shaped block into a tight slot (only 3.5 mm of wiggle room) requires precise alignment and sensitivity to sticking or jamming.
- Book Organization: Sliding, grasping, and shelving a thin book that’s hard to pick up directly.
- Towel Folding: Handling soft, floppy fabric without losing track or getting tangled.
- Cat Litter Scooping: Using a tool in tight spaces and keeping contact controlled.
- Tea Serving: Carrying objects with both hands while walking—keeping them balanced and steady.
- Adding “Touch Dreaming” made a big difference:
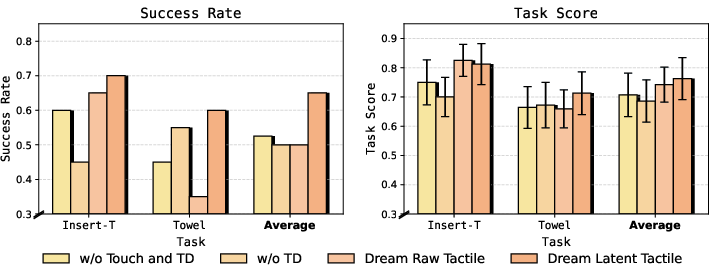
- The new method (HTD) improved average success rates by 90.9% compared to a strong existing baseline. In simple terms, it nearly doubled how often the robot succeeded.
- Predicting touch in a clean, compact “latent” form worked better than predicting raw touch signals, giving a further 30% boost. That’s because latents focus on meaningful patterns (like slip or pressure changes) instead of noise.
- Stronger balance and body control:
- Their lower-body controller kept the robot steadier and better aligned than other leading approaches in tests. That stability is essential for hands-on tasks where a small wobble can cause a failure.
Why this matters:
- Many real-life tasks involve continuous contact—pushing, sliding, scooping, inserting—where feeling is as important as seeing. Teaching the robot to “expect” how touch will change helps it act more safely and precisely.
What’s the big picture impact?
- More capable home and workplace robots: Combining vision with touch—and teaching robots to “imagine” how things will feel—can make them much more reliable at everyday chores that involve contact, friction, and precision.
- Simpler training pipeline: The system learns everything in one stage from human demonstrations, without bolting on complicated extra models at test time. That means it could scale to more tasks more easily.
- Safer, more adaptable manipulation: When a robot anticipates slip or jamming, it can react before things go wrong, reducing drops, damage, or spills.
- A path toward general-purpose helpers: Stable whole-body control plus touch-centered learning brings humanoids closer to being helpful in cluttered, changing, real-world environments.
In short: This paper shows that giving humanoid robots a strong sense of touch—and training them to predict how that touch will change—helps them handle tricky, contact-heavy tasks far better, all while staying balanced and coordinated.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
The paper introduces a promising single-stage, touch-aware humanoid manipulation system, but several aspects remain under-specified or unexplored. The points below identify concrete gaps and questions to guide future work.
- Scope of generality vs. per-task specialization
- Clarify whether HTD is a single multi-task policy or separately trained per task; if single, detail the task-conditioning mechanism and how it scales with additional tasks and skills.
- Evaluate how well a single policy transfers to truly novel tasks without retraining or with minimal adaptation.
- Dataset scale, diversity, and collection efficiency
- Report the number of demonstrations, task durations, object instances, and environmental variations per task; analyze data-efficiency by success vs. number of demos.
- Quantify collection efficiency and operator burden in VR teleoperation (time per demo, learning curve), and assess how operator skill affects policy quality.
- Generalization across objects, materials, and environments
- Test robustness to unseen objects (shapes, sizes, masses), materials (friction/compliance), and environmental changes (lighting, background clutter, surfaces, table heights).
- Assess transfer to new scenes and furniture layouts, and to new grasp/tool-use affordances beyond those seen in training.
- Robustness of tactile and force sensing
- Provide calibration details for per-joint hand-force signals (origin, units, correlation with external contact forces) and quantify sensor noise, drift, and latency.
- Evaluate sensitivity to tactile sensor failures, saturation, non-uniform wear, and missing channels; test fault tolerance and redundancy strategies.
- Examine how dependent HTD is on the specific tactile layout (17 regions, 1062-D) and whether the method transfers to different tactile hardware and spatial layouts without redesign.
- Touch dreaming design and alternatives
- Ablate the impact of touch-dreaming horizon τ, action-chunk horizon h, and EMA decay α on manipulation performance and stability.
- Compare latent tactile supervision to alternative objectives (contrastive/InfoNCE, BYOL/SimSiam-style predictors, variational latent targets, masked modeling) and to predicting other contact quantities (contact state, slip probability, friction coefficients).
- Investigate using the dreamed touch at inference (e.g., as a contact-state estimator, for anomaly detection, or to drive model-predictive adjustments) versus keeping it purely auxiliary.
- Temporal modeling and memory
- Specify and ablate the temporal context used by HTD (history window, causal vs. non-causal encoding); assess whether limited temporal context impedes long-horizon sequencing and recovery after contact disruptions.
- Compare chunk-based decoding to recurrent or explicit sequence models for fine-grained contact timing.
- Multimodal architecture choices
- Ablate the number of tokens per modality, tokenizer architecture (cross-attention “slot” design), and image backbone choice on performance and compute.
- Quantify the contribution of each modality (vision-only, proprio-only, force-only, tactile-only, and combinations), beyond the raw vs. latent tactile comparison.
- Whole-body controller (WBC) sim-to-real and stability limits
- Provide real-world tracking metrics for the LBC (not only simulation) under representative manipulation disturbances and terrain variations.
- Examine how the WBC’s narrower roll range affects manipulation requiring lateral leaning, and evaluate stability under load transfer (carrying heavy or sloshing objects).
- Explore adaptation to uneven ground, foot slippage, or external pushes during loco-manipulation.
- Locomotion–manipulation coupling at policy level
- Clarify how base-velocity commands are produced during autonomous execution (predicted by HTD vs. scripted), and evaluate obstacle avoidance and footstep placement under visual occlusions caused by manipulation.
- Test policies on tasks requiring longer-distance locomotion, tight turns, and narrow passages, not only stationary or short-base motions.
- Real-time performance and latency
- Report end-to-end inference latency (sensing → policy → LBC/IK/hand) and its variability; quantify how delays affect contact transitions and tight-tolerance insertion success.
- Profile on-robot compute requirements (GPU/CPU) and assess scalability to higher camera/tactile frame rates or additional sensors.
- Failure modes and safety
- Provide a systematic failure analysis across tasks (misalignment, slip, jam, loss of balance, over/under-grasping) and the corresponding sensory signatures.
- Incorporate and evaluate safety constraints (force/torque limits, collision thresholds) and recovery behaviors after partial failures (e.g., stuck insertion, dropped object).
- Comparative baselines and broader benchmarks
- Compare HTD to additional touch-centric policy baselines (diffusion-based VTAs, explicit visuo-tactile world models) and to policies without LBC (end-to-end learned whole-body control).
- Evaluate on standardized contact-rich benchmarks or release task definitions to enable direct comparisons.
- Ablations on training recipe and regularization
- Study the sensitivity to loss weights λF and λZ, magnitude term weight β, optimizer settings, and EMA hyperparameters; analyze stability (e.g., risk of latent collapse without EMA).
- Examine curriculum learning or data-augmentation effects for contact diversity (e.g., tactile jittering, force/torque perturbations, synthetic slip events).
- Teleoperation retargeting and action supervision
- Quantify retargeting error for hands and wrists during teleoperation, and how it propagates to action labels; study methods to denoise or correct teleoperated trajectories.
- Evaluate whether hand-IK/retargeting artifacts bias learned action distributions, especially for fine dexterity.
- Towel folding and deformable-object generality
- Test across towels of different sizes, stiffness, and textures; assess the policy’s ability to adapt to cloth dynamics under varying friction and wrinkling.
- Explore extension to other deformables (bags, cables) and quantify where contact-aware representations remain effective or require new supervision.
- Tool-use breadth and constraints
- Extend evaluation beyond low-profile scooping to tools with different contact geometries (tongs, spatulas, screwdrivers) and quantify adaptation to tool inertia and compliance.
- Analyze how tactile signals through tools (tool–object contact distal to the hand) are represented when hand tactile readings encode only handle contact.
- Bimanual coordination and object transport
- Assess robustness of bimanual stability during locomotion with perturbations (sudden stops, turns) and different payload distributions; measure oscillations and spill rates in “Tea Serving.”
- Investigate coordination strategies for asymmetric tasks (one hand stabilizes, the other manipulates) and how tactile feedback is fused across both hands.
- Long-horizon task structure and sequencing
- Measure performance on multi-stage tasks with explicit subgoal changes (e.g., pre-shaping, regrasping, placement) and test whether HTD needs task-phase signals or can infer them from multimodal cues.
- Explore integration with high-level planners or language goals to scale beyond fixed task templates.
- Reproducibility and transferability
- Provide detailed hardware specs (robot model, hand model, tactile hardware, sensor placements) and release calibration, dataset, and code to enable replication.
- Study transfer across different humanoid platforms and hand designs without retraining the tactile/force encoders from scratch.
- Ethical, safety, and deployment contexts
- Establish safety evaluations for human-proximal operation during contact-rich tasks, including force-limiting and fail-safe behaviors.
- Explore how to certify manipulation behaviors in home/industrial settings where contact unpredictability is high.
Practical Applications
Immediate Applications
Below are concrete, near-term use cases that can be piloted with today’s hardware and software stacks, assuming access to a dexterous humanoid (or arm-hand system), multi-view cameras, tactile sensing, and sufficient compute for transformer training.
- Tight-tolerance insertion in manufacturing cells
- Sectors: robotics, manufacturing, electronics assembly
- What to do: Deploy HTD-style visuo-tactile policies for connector insertion, peg-in-hole, battery/board seating, and cable routing where millimeter-level clearance and compliant contact are critical.
- Tools/workflows: Add “touch dreaming” auxiliary heads to existing imitation-learning or diffusion policies; collect teleoperated demos via the VR mapping pipeline; use the RL-trained lower-body controller (or a stationary base + arm) to ensure precise end-effector poses.
- Dependencies/assumptions: Availability and calibration of distributed tactile sensors and joint-force readouts; repeatable fixturing; reliable multi-view vision; safety interlocks for contact forces.
- Retail and library shelf organization for thin-profile objects
- Sectors: retail, logistics, service robotics
- What to do: Use mixed pushing–grasping strategies to create overhangs and pick/place books, magazines, folders, or blister packs on shelves—directly mirroring the “Book Organization” task.
- Tools/workflows: VR demo collection in target aisles; HTD training with action chunking; deployment with bimanual control and wrist cameras for low-profile perception.
- Dependencies/assumptions: Stable flooring and lighting; sufficient shelf standardization; dexterous hands with tactile coverage to reason about slip and edge contact.
- Laundry folding in controlled environments
- Sectors: hospitality, home robotics pilot programs, facilities management
- What to do: Execute multi-stage, long-horizon deformable-object manipulation (towels, small linens) on dedicated folding tables.
- Tools/workflows: Teleop collection of fold templates; HTD fine-tuning on local linens; integrate tactile-latent prediction to handle fabric contact/drag.
- Dependencies/assumptions: Clean, flat work surfaces; high-friction fingertips or gloves; moderate fabric variability; time windows that tolerate multi-step policies.
- Tool-mediated surface cleaning and scooping
- Sectors: janitorial services, hospitality, pet-care robotics
- What to do: Perform low-profile tool use (e.g., scoops, scrapers) to collect debris from trays and shallow bins—similar to “Cat Litter Scooping” but adaptable to crumbs and dustpan tasks.
- Tools/workflows: Wrist-camera alignment; tactile-based slip/force feedback; HTD trained with future force prediction for compliant tool–surface contact.
- Dependencies/assumptions: Tool standardization and easy mounting; reliable force thresholds; sealed environments to avoid airborne dust issues.
- Tray carrying and gentle transport in facilities
- Sectors: hospitality, healthcare logistics, corporate services
- What to do: Bimanual carrying and “loco-manipulation” (e.g., tea tray or medication tray transport) using whole-body stabilization while keeping payload balanced.
- Tools/workflows: RL-based lower-body controller for torso/height tracking; HTD for bimanual actions and reactive stabilization; waypoint navigation integration.
- Dependencies/assumptions: Smooth floors; payload mass/CoM within trained ranges; fall-safe design and speed limits around people.
- Safer teleoperation with whole-body stabilization
- Sectors: defense, inspection, utilities, R&D labs
- What to do: Use the RL-trained lower-body controller + IK + hand retargeting to reduce operator burden and improve stability during remote tasks (e.g., turning valves, panel interactions).
- Tools/workflows: Off-the-shelf VR interfaces; the paper’s motion-mapping stack; logging for post-hoc imitation learning.
- Dependencies/assumptions: Reliable comms; operator training; scene cameras for situational awareness.
- Drop-in policy upgrade for arm-hand systems on contact-rich tasks
- Sectors: industrial robotics, lab automation
- What to do: Apply “touch dreaming” (future tactile latent + force prediction) as auxiliary objectives to existing arm-hand policies to improve robustness under partial observability.
- Tools/workflows: Integrate EMA latent supervision into your transformer/v-diffusion policy; plug tactile encoders into your data pipeline; finetune with existing demos.
- Dependencies/assumptions: Tactile sensors or joint-torque signals available; minimal code changes to accommodate new loss heads.
- Data collection pipeline for visuo-tactile humanoid learning
- Sectors: academia, corporate research
- What to do: Stand up the full VR teleop-to-dataset pipeline to quickly gather synchronized multi-view, proprioceptive, force, and tactile trajectories for new tasks.
- Tools/workflows: Adopt the unified frame mapping, IK, and DexPilot-style retargeting; store EMA teacher weights and tactile latents for reuse.
- Dependencies/assumptions: Access to a compatible humanoid or bimanual platform; robust time-sync and storage; IRB/data governance where humans are recorded.
- Benchmarking and ablation of tactile representations
- Sectors: academia, sensor vendors
- What to do: Use the paper’s latent-vs-raw tactile prediction finding to evaluate new tactile skins or layouts and identify optimal encoders.
- Tools/workflows: Plug-in per-finger/region tactile encoders; measure task success under ablations; share latent spaces for cross-sensor comparisons.
- Dependencies/assumptions: Comparable sensor coverage and sampling rates; standardized evaluation tasks.
- Training-as-a-service for contact-rich skills
- Sectors: robotics software, systems integrators
- What to do: Offer HTD-style training packages where clients bring task layouts and objects; provider supplies teleop rig, data collection, and tuned policies.
- Tools/workflows: Containerized training pipeline (ROS 2 + GPU); pre-validated lower-body controllers; auto-calibrators for tactile sensors.
- Dependencies/assumptions: Onsite data collection access; service-level agreements on safety and downtime; IP agreements for datasets.
Long-Term Applications
The following opportunities require further scaling, generalization research, or engineering for reliability, safety, and cost before broad deployment.
- General-purpose household humanoid assistant
- Sectors: consumer robotics
- Vision: Perform routine chores (laundry folding, dish handling, tidying, light cleaning) in unstructured homes using touch-aware manipulation.
- Tools/products: “Home HTD” with continual learning on user-specific environments; robust tactile skins; energy-efficient whole-body controllers.
- Dependencies/assumptions: Affordable hardware, long battery life, safety certification, privacy-preserving in-home data collection, high reliability in clutter.
- Bedside and eldercare assistance
- Sectors: healthcare
- Vision: Gentle handling of linens, meal trays, medication organizers, and mobility aids near patients, using tactile-aware compliance for safety.
- Tools/products: Hospital-grade tactile skins with sterilizable covers; validated force thresholds; supervisory autonomy with nurse oversight.
- Dependencies/assumptions: Regulatory approval (FDA/IEC standards), strict infection control, fall-risk mitigation, robust human–robot interaction policies.
- Flexible micro-assembly and rework cells
- Sectors: advanced manufacturing, electronics
- Vision: Tactile-guided assembly/disassembly of small components, connectors, and fasteners without custom jigs; on-the-fly changeovers.
- Tools/products: Cross-sensor tactile latent standards enabling rapid retooling; policy libraries tuned to common assembly motifs.
- Dependencies/assumptions: Extremely precise kinematics, stable ESD-safe workspaces, automated calibration for each batch of parts.
- Service robots in public venues (restaurants, hotels, retail)
- Sectors: hospitality, food service, retail
- Vision: Loco-manipulation in dynamic crowds—serving, clearing, and restocking—with touch-aware compliance for safe incidental contact.
- Tools/products: Multi-robot coordination; crowd-aware navigation tied to whole-body controllers; incident reporting and risk monitors tied to tactile events.
- Dependencies/assumptions: Public-space safety certification, liability frameworks, robust perception in variable lighting and noise.
- Standardized tactile-latent middleware across hardware vendors
- Sectors: robotics platforms, sensor manufacturing
- Vision: A “tactile latent API” that decouples policies from specific sensor layouts, enabling model portability across hands and skins.
- Tools/products: Open-source EMA teacher encoders; calibration pipelines to map raw sensor IDs into shared latent spaces.
- Dependencies/assumptions: Industry cooperation on formats, long-term sensor stability, versioning and drift detection.
- Continual, on-robot self-improvement via imagined touch
- Sectors: robotics software, autonomy
- Vision: Use touch dreaming for online representation maintenance and uncertainty estimation; periodic relabeling or self-training during downtime.
- Tools/products: Onboard model distillation; safe exploration policies gated by force/tactile thresholds; MLOps for field-deployed models.
- Dependencies/assumptions: Reliable fail-safes, compute budgets on-board, robust data governance and rollback strategies.
- Cross-embodiment transfer (humanoids ↔ mobile manipulators)
- Sectors: logistics, field robotics
- Vision: Reuse contact-aware policies across different embodiments using shared tactile latents and modular action experts.
- Tools/products: Retargeters that map action chunks to different kinematics; embodiment-agnostic encoders.
- Dependencies/assumptions: Strong sim-to-real transfer; standardized action interfaces; morphology-aware training.
- Regulatory guidance and testing protocols for contact-rich humanoids
- Sectors: policy, standards bodies
- Vision: Codify tactile- and force-aware safety tests, runtime monitoring, and audit trails for humanoids operating near people.
- Tools/products: Open test suites for contact-rich tasks; logging standards for tactile/force events; certification rubrics.
- Dependencies/assumptions: Multi-stakeholder engagement (manufacturers, insurers, regulators), alignment with existing robotic safety standards.
- Low-cost tactile skins and self-calibration at scale
- Sectors: hardware, manufacturing
- Vision: Produce robust, affordable tactile arrays with auto-calibration and drift compensation that feed high-quality latents to policies.
- Tools/products: Printed flexible sensors, modular finger/palm tiles, embedded preprocessing to output latent-ready features.
- Dependencies/assumptions: Manufacturing yield and durability; environmental robustness (temperature, humidity); maintainability in the field.
- End-to-end kit for small enterprises
- Sectors: SMEs in logistics, light manufacturing, services
- Vision: A turnkey “Loco-Manipulation Kit” bundling teleop data capture, HTD training, and deployment playbooks tailored to customer tasks.
- Tools/products: Pretrained lower-body controllers; templated demos for common tasks; hosted training with monitoring dashboards.
- Dependencies/assumptions: Service models that fit SME budgets, remote support, clear ROI versus manual labor.
Each application’s feasibility hinges on assumptions such as hardware availability (dexterous hands with tactile arrays), reliable multimodal sensing and calibration, adequate compute for transformer training, high-quality demonstration data, and adherence to safety and regulatory requirements. Where these prerequisites are met, the paper’s methods—especially the integrated whole-body controller, VR teleoperation pipeline, and touch-dreaming policy training—can be transitioned from lab demonstrations to production pilots and, over time, scaled to broader deployments.
Glossary
- Ablation: An experimental analysis where components of a system are removed or altered to assess their impact. "Ablation results further show that latent-space tactile prediction is more effective than raw tactile prediction"
- Action chunking: Predicting a short sequence of future actions at once rather than a single step to improve control stability and efficiency. "We adopt action chunking"
- AMASS: A large motion capture dataset used for human motion retargeting and simulation. "retargeted arm joint references sampled from AMASS"
- Behavioral cloning: Imitation learning that trains a policy to mimic demonstrated actions from observations. "trained in a single stage with behavioral cloning augmented by touch dreaming"
- Bimanual: Involving the use of both hands for coordinated manipulation. "bimanual object fetch and loco-manipulation"
- Clearance: The small intentional gap between parts, crucial for insertion tasks to avoid jamming. "with a clearance of 3.5\,mm"
- Compliance modulation: Adjusting a robot’s mechanical or control stiffness to safely and adaptively interact with contact. "compliance modulation"
- Cosine similarity: A measure of alignment between two vectors, used to supervise latent predictions. "cosine similarity"
- Cross-attention aggregation layer: A module where learnable queries attend to input features to produce compact tokens. "using a cross-attention aggregation layer"
- DAgger: A dataset aggregation algorithm that iteratively collects expert corrections to improve imitation policies. "via DAgger"
- Detokenizer: A network component that maps tokens back into predicted signals (e.g., tactile latents). "the touch detokenizer will mode collapse"
- Domain randomization: Randomly varying simulation parameters to improve robustness when transferring to the real world. "We also apply domain randomization to improve sim-to-real transferability."
- Dream experts: Auxiliary heads that predict future sensory outcomes (e.g., forces, tactile latents) to regularize representation learning. "dream experts that predict future forces and tactile latents"
- Encoder--decoder Transformer: A Transformer architecture that encodes inputs and decodes outputs via attention mechanisms. "a multimodal encoder--decoder Transformer"
- End-effector: The robot’s terminal tool or hand that directly interacts with objects. "end-effector pose targets"
- Exponential Moving Average (EMA) target encoder: A slowly updated teacher network providing stable latent supervision. "an Exponential Moving Average (EMA) target encoder"
- I-JEPA: A specific Joint-Embedding Predictive Architecture for predictive representation learning. "I-JEPA"
- Inverse Kinematics (IK): Computing joint configurations that realize desired end-effector poses. "an IK solver"
- IsaacLab: A massively parallel robotics simulation framework. "with IsaacLab"
- Joint-Embedding Predictive Architectures: Models that learn representations by predicting future embeddings rather than reconstructing raw inputs. "Joint-Embedding Predictive Architectures"
- Latent space: A compact learned representation space capturing semantic structure of sensory inputs. "latent-space tactile prediction"
- Learnable query embeddings: Trainable vectors that query the Transformer to structure inputs/outputs into tokens. "We use learnable query embeddings"
- Loco-manipulation: Joint locomotion and manipulation, coordinating whole-body movement with object interaction. "humanoid loco-manipulation"
- Lower-body controller (LBC): A control module focusing on stable locomotion and torso posture for the humanoid. "lower-body controller (LBC)"
- Mode collapse: A failure mode where outputs ignore input variability and collapse to similar predictions. "mode collapse where all tactile inputs map to near-identical latents"
- Modality tokenizers: Encoders that convert each input stream (e.g., images, forces, tactile) into a fixed set of tokens. "modality tokenizers"
- Non-prehensile manipulation: Manipulating objects without grasping, e.g., pushing or sliding. "non-prehensile manipulation"
- PPO (Proximal Policy Optimization): A reinforcement learning algorithm used to train the teacher policy. "using PPO"
- Prehensile manipulation: Manipulating objects by grasping them with hands or grippers. "prehensile and non-prehensile manipulation"
- Privileged information: Additional state information available during training (e.g., in simulation) but not at deployment. "with access to privileged information"
- Proprioception: Internal sensing of the robot’s body state (e.g., joint positions/velocities, forces). "proprioception"
- Retargeting: Mapping human motions or references onto a robot’s kinematics for execution. "hand retargeting"
- Self-distillation: A training scheme where a model learns from targets generated by its own EMA teacher. "self-distillation mechanism"
- Sim-to-real transferability: The ability of a policy trained in simulation to perform well on real hardware. "to improve sim-to-real transferability."
- Smooth L1 loss: A robust regression loss that is less sensitive to outliers than L2. "smooth L1 loss"
- Stop-gradient: A training operation that prevents gradients from flowing through certain computations. "with stop-gradient, providing stable latent targets."
- Tactile latents: Compact learned embeddings of tactile sensor readings used as prediction targets. "future tactile latents"
- Teleoperation: Human control of a robot from a distance, often via VR, to collect demonstrations or operate in real time. "VR-based teleoperation"
- Touch dreaming: Predicting near-future touch signals (forces and tactile latents) as an auxiliary training objective. "touch dreaming"
- Trajectory optimization: Planning method that computes optimal trajectories by optimizing over control and state sequences. "trajectory optimization"
- VR teleoperation: Using virtual reality interfaces for immersive remote control of robots. "VR teleoperation"
- Whole-body controller (WBC): A controller coordinating multiple body segments to achieve stable, integrated locomotion and manipulation. "whole-body controller (WBC)"
Collections
Sign up for free to add this paper to one or more collections.

