- The paper reveals that leading LLMs achieve a maximum of 37.2% finish-line accuracy, largely due to navigation bottlenecks.
- The paper introduces a novel DAG-structured benchmark with 1,400 legs and fork-merge tool chains to assess complex compositional reasoning.
- The paper demonstrates that while tool-use accuracy remains relatively stable, navigation errors dominate, pinpointing a critical area for future improvements.
Motivation and Benchmark Contributions
Recent advances in LLM-based agents have centered around compositional tool-use and web navigation. However, a systematic analysis of six leading benchmarks reveals that the majority (55–100%) of their instances are strictly linear, encompassing only shallow chains of two to five sequential steps. Such linearity under-represents the complexity encountered in realistic scenarios involving fork-merge dependencies and multi-branch tool workflows. "The Amazing Agent Race: Strong Tool Users, Weak Navigators" (2604.10261) addresses this compositionality deficit by introducing The Amazing Agent Race (AAR), a benchmark featuring exclusively DAG-structured puzzles—or “legs”—with fork-merge tool chains, generated from Wikipedia and coupled with live-API validation.
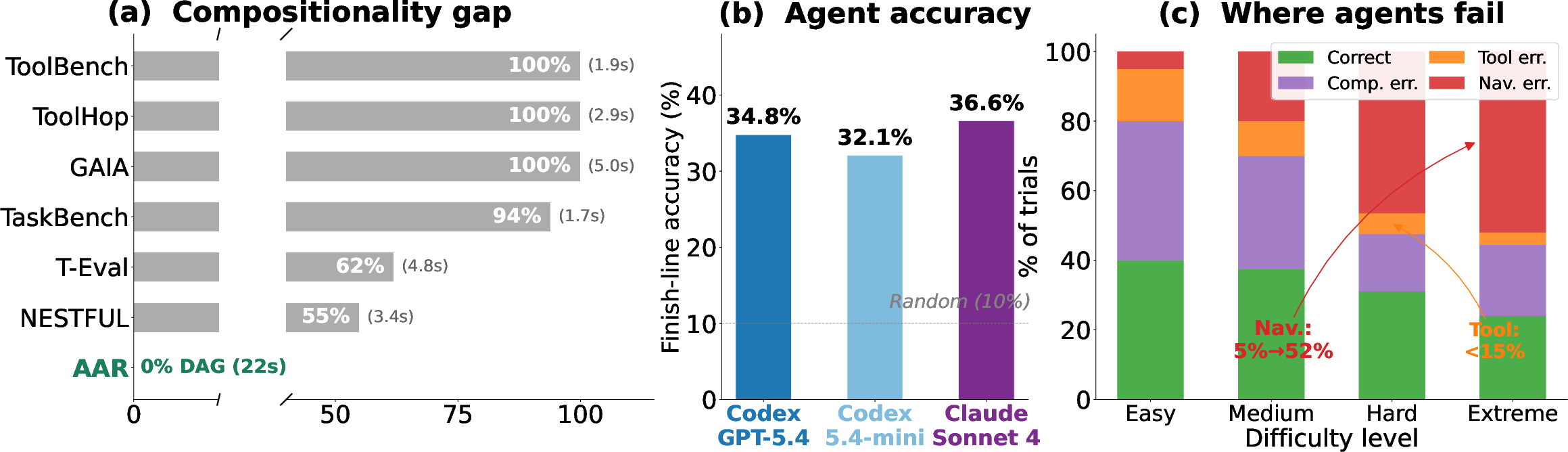
Figure 1: (a) Existing benchmarks exhibit 55--100% linearity; AAR uniquely provides 0% linearity, with all instances as true DAGs. (b) Best agent accuracy is 36.6% (aggregated across 1,400 legs).
AAR constructs 1,400 evaluation legs mapped into two variants: AAR-Linear (sequential chains, 800 legs) and AAR-DAG (compositional fork-merge DAGs, 600 legs). Every leg is procedurally generated from random Wikipedia seeds, spans four difficulty levels, and passes a stringent, automated quality pipeline to ensure solvability, contamination-resistance, and diverse tool composition. Notably, each puzzle in AAR is a true DAG with an average of 22 pit stops and up to five fork-merge diamonds—far surpassing the structural complexity of existing benchmarks.
In AAR, each instance presents the agent with a seed Wikipedia URL, a natural-language clue envelope that obfuscates explicit titles and tool names, the full set of 19 tools, and a constrained step budget. The agent must sequentially process clues, navigate across Wikipedia, orchestrate multi-step tool chains (composing up to three calls), and ultimately aggregate all necessary facts and computed values into a single-digit answer. Clues are paraphrased to minimize contamination risk and are coupled with live API calls (including temporal data such as weather or financial values), ensuring the required reasoning surpasses recall of static knowledge.
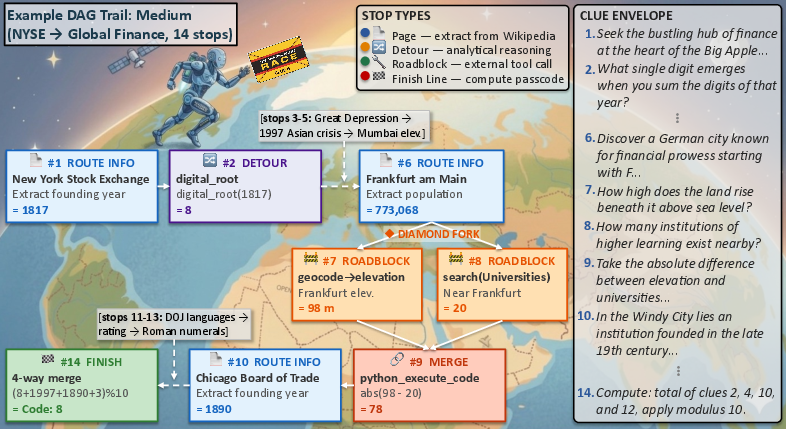
Figure 2: An AAR clue envelope (leg) as presented to the agent, utilizing paraphrased multi-step riddles instead of explicit Wikipedia titles or tool names.
The legs are constructed as DAGs via diamond patterns: a source pit-stop (usually a Wikipedia-derived fact) fans out into two or more parallel tool chains, each invoking different API workflows, which then merge at a downstream aggregation node. This structure creates explicit compositional dependencies absent from standard linear tool-use tasks.
Evaluation Metrics and Pipeline Overview
AAR introduces metrics decomposed along the agent pipeline to allow fine-grained diagnosis:
- Finish-line Accuracy (FA): Exact match on the final single-digit answer.
- Pit-stop Visit Rate (PVR): Fraction of golden Wikipedia page visits matched—an explicit measure of navigation quality.
- Roadblock Completion Rate (RCR): Fraction of expected toolchain invocations performed on the correct arguments.
This decomposition isolates navigation failures from tool-use deficiencies and final computation errors, enabling robust attribution of agent weaknesses.
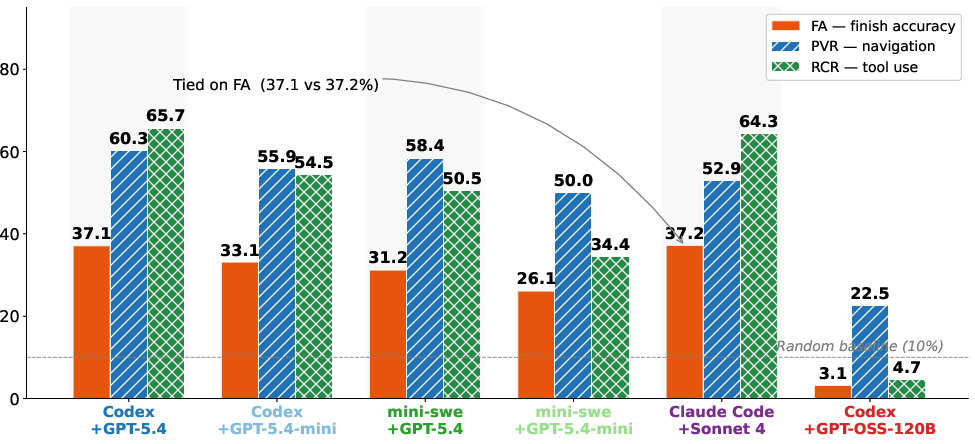
Figure 4: Main results on both benchmark variants. (a) FA, PVR, and RCR for AAR-Linear. (b) Metrics for AAR-DAG reveal sharp PVR drop (navigation difficulties) but relatively stable RCR (tool-use competence).
The benchmark generation proceeds through an automated eight-step pipeline, including web crawling, thematic route planning, leg construction, tool-chain validation, diamond-structured augmentation, golden-trace execution, and NL clue verbalization. All legs are subject to alignment and contamination-resistant checks before inclusion in the evaluation set.
Evaluation across 1,400 legs and three agent frameworks (OpenAI Codex CLI, Anthropic Claude Code, and a lightweight mini-swe-agent ReAct-style agent) yields critical findings:
- Low Maximum Achievement: No agent configuration exceeds 37.2% FA on any variant, with navigation (PVR) consistently underperforming tool-use competence (RCR).
- Navigation as Bottleneck: Navigation errors are the dominant failure (27–52% of cases), while tool-use breakdowns remain below 17%, even as tool chains grow longer and more compositional.
- Architectural Sensitivity: Agent framework choice impacts performance as much as model scale; e.g., Claude Code matches Codex CLI performance despite using 6× fewer tokens.
- Compositionality Amplifies Navigation Failure: Transitioning from AAR-Linear to AAR-DAG induces a 13–18pp decline in navigation performance, while tool-use remains relatively unaffected.
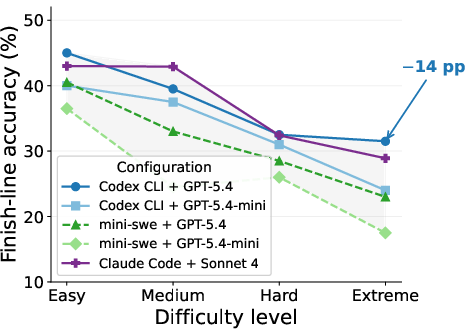
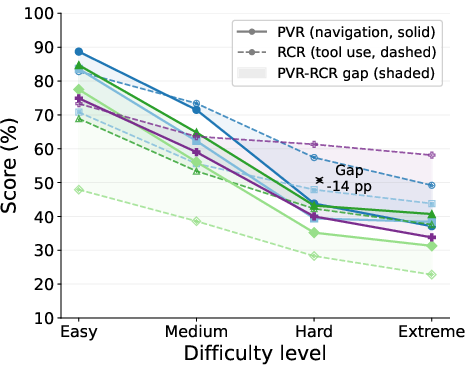
Figure 6: FA (finish-line accuracy) degrades monotonically with difficulty increases, with worst-case drops of 19pp, substantiating the growing impact of navigation complexity.
Detailed failure taxonomy demonstrates that agents often succeed at correct tool invocation, yet select or extract facts from incorrect navigation targets. Furthermore, agent strategies to recover from partial progress show that high navigation and tool-use rates do not always guarantee a correct answer—compositional aggregation remains an additional challenge.
Implications, Limitations, and Future Opportunities
AAR exposes limitations in current LLM agent architectures—specifically, their inability to robustly solve complex, compositional, real-world tasks requiring nontrivial navigation and fact discovery. Purely increasing model size or internal “reasoning” (as in the case of GPT-OSS-120B) does not overcome the navigation bottleneck and merely increases resource use without accuracy gains.
Shortcut solution strategies, where an agent bypasses navigation and reasons directly from tool argument inference, are detected by low PVR and remain a nontrivial success that AAR’s decomposed metrics can explicitly measure. However, even with these “shortcuts,” overall accuracy remains low, confirming the structural hardness of the benchmark.
Future research should address:
- Targeted retrieval and verification over more exhaustive (and error-prone) searching.
- Deeper integration of navigation and tool-use policies for complex DAGs with richer branching and more ambiguous clues.
- Richer, domain-general compositionality (multi-season legs, cross-episode state, and more diverse sources than Wikipedia).
Conclusion
The AAR benchmark sets a new standard for evaluating tool-augmented LLM agents, demonstrating that strong tool-use alone does not translate into holistic problem-solving: navigation and compositional reasoning constitute the principal limitations. As LLM-based agents are increasingly deployed in open-ended and compositional real-world tasks, research must prioritize robust navigation, targeted multimodal fact-finding, and the fusion of navigation and tool utilization strategies. AAR provides the framework and diagnostics for such progress.

