- The paper demonstrates that LLM-synthesized tools yield consistent performance gains only when the user is weaker than the tool’s creator.
- The study employs a large-scale, controlled evaluation across multiple frameworks and backbone models to assess tool complexity, utility, and compositionality.
- Key findings challenge the assumption that more complex tools are superior, advocating for simple, composable APIs and semantic skill abstraction for robust agent design.
Introduction
The adoption of tool-based paradigms in web agents operating with LLMs marks a significant departure from granular, low-level browser actions. While numerous studies have highlighted the benefits of LLM-synthesized tools, prevailing experimental evidence is frequently limited by scale and comparability, resulting in ambiguous or even contradictory conclusions regarding the utility, design, and costs of tools for web agents. This paper, "The Tool Illusion: Rethinking Tool Use in Web Agents" (2604.03465), presents a large-scale, controlled empirical study covering diverse tool sources, state-of-the-art agent frameworks, backbone models, and evaluation benchmarks. It systematically unmasks foundational phenomena, design trade-offs, and actionable principles, ultimately challenging several established claims and refocusing research toward reliable grounding.
Empirical Foundations and Revised Claims
The study rigorously evaluates tool use within three prominent frameworks: WALT, SkillWeaver, and Hybrid-Agent. The backbone models range from strong generative models such as GPT-5 to smaller variants (GPT-5-mini, GPT-5-nano), Grok-4.1-Fast-Reasoning, and Mistral-Large-3.1. The evaluation covers both standard and vision-augmented web-task benchmarks (WebArena, VisualWebArena).
A principal finding is that LLM-synthesized tools predominantly act as a vector for one-way capability distillation: tools yield consistent performance gains only if the agent utilizing the tool is strictly weaker than the agent (LLM) that synthesized it. When the tool user matches or exceeds the developer in baseline capability, tool use produces limited, inconsistent, or negative outcomes. For instance, WALT’s tools (derived from GPT-5-mini) afford benefits only to weaker backbones; stronger models may even degrade upon relying on them.
This relationship is further reinforced by explicitly varying the tool-constructor across strengths. Tools created with GPT-5 consistently benefit all weaker models; tools created by weaker LLMs, conversely, fail to consistently uplift even modest agents.
The Cost of Complexity
An intuitive but empirically invalidated hypothesis is that more comprehensive, complex, or end-to-end tools necessarily generate superior performance. The study’s multi-level analysis of tool complexity confirms that frameworks heavily populated with high-complexity, task-specific tools—such as SkillWeaver—suffer from inferior generalization and utility. Many complex tools are rarely, if ever, invoked, imposing practical redundancy and selection ambiguity.
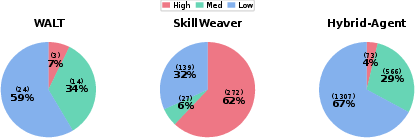
Figure 1: Distribution of tool complexity levels across the three frameworks.
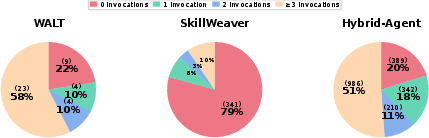
Figure 2: Distribution of tool invocations. Many synthesized tools are never invoked during real task execution.
The findings motivate a strong decoupling principle: deterministic, reusable UI operations should be encapsulated as tools, while context-sensitive, grounding-dependent reasoning and multi-step planning must remain with the agent. Encapsulating agentic reasoning as tools reduces flexibility, induces brittleness, and exacerbates maintenance and interpretability issues.
Functional Coverage and Compositionality
Frameworks equipped with atomic or medium-complexity tools supporting broad website functionalities and robust multi-tool composition (e.g., Hybrid-Agent with many low/medium-level RESTful APIs) outperform those with monolithic or overly specific tool sets. The empirical evidence establishes that functional coverage and reliable composition are key—not tool complexity or library size. Agents must be able to combine simple, composable tools to cover a wide distribution of user intentions rather than relying on single-shot procedures.
The Hidden Tax: Efficiency, Token Cost, and Step Overhead
Contrary to the common presumption, tools do not inherently yield efficiency gains. The presence of extensive or low-quality synthesized tool sets increases both the average token cost (due to retrieval and inspection prompt inflation) and agentic action steps (from tool selection, error recovery, or parameter rectification). Only frameworks with well-curated, highly composable, and small tool sets realize step-efficient execution.
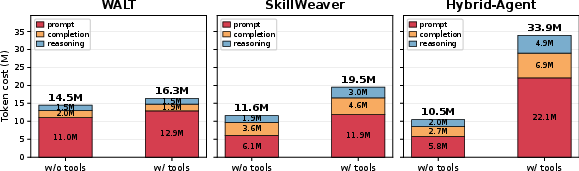
Figure 3: Average token cost per website on WebArena. Toolized agents pay a higher prompt/completion token cost.
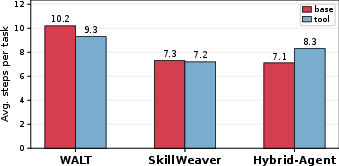
Figure 4: Average number of agent steps required to complete a task on WebArena. Tool use sometimes increases, rather than decreases, step count.
Semantic Skills as a Transparent Alternative
The opaque (“black-box”) execution of programmatic tools constrains agent transparency, inspectability, and fault tolerance. Translating tool knowledge into “skills”—explicit, natural language, procedural descriptions—enables strong agents (e.g., GPT-5) to outperform tool use by flexibly reasoning over, adapting, or ignoring skill guidance. However, this method proves effective only when the agent’s own capabilities are sufficient; for weaker models, direct executable tools remain preferable.
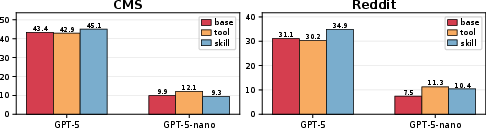
Figure 5: Comparison of tool and skill in SkillWeaver. Skills outperform tools for strong models but not for weaker ones.

Figure 6: Example of the Python tool function of SkillWeaver and the converted skill.
The ablation study further demonstrates that visual webpage input (screenshots) remains beneficial even in tool-use paradigms, although tool-equipped agents are more robust to missing visual information. Thus, vision and tool-use offer complementary rather than interchangeable advantages.
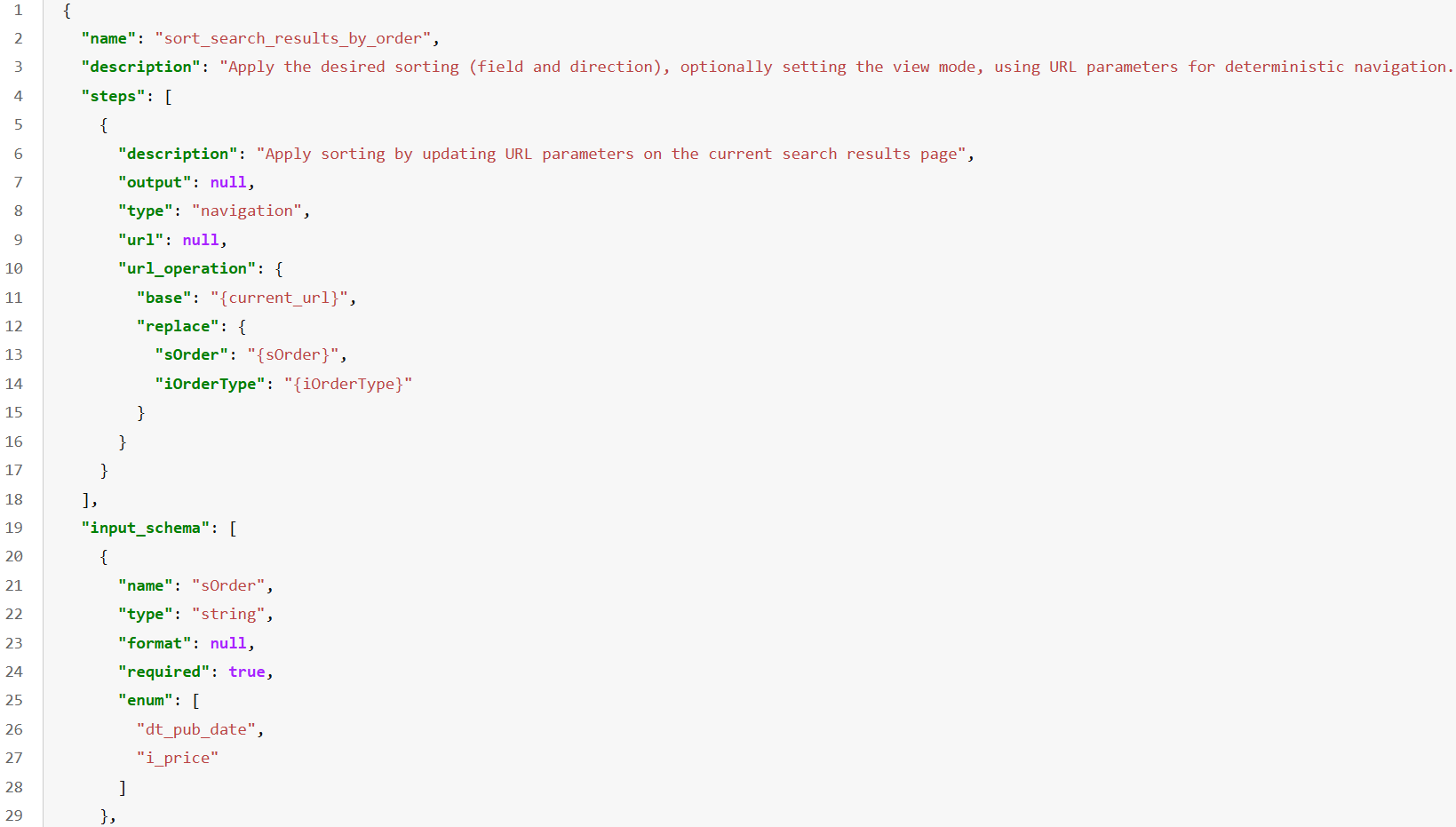
Figure 7: Tool example of WALT: a JSON-based, focused UI action flow.

Figure 8: Tool example of SkillWeaver: A procedural, Python-Playwright function with complex trajectory encapsulation.
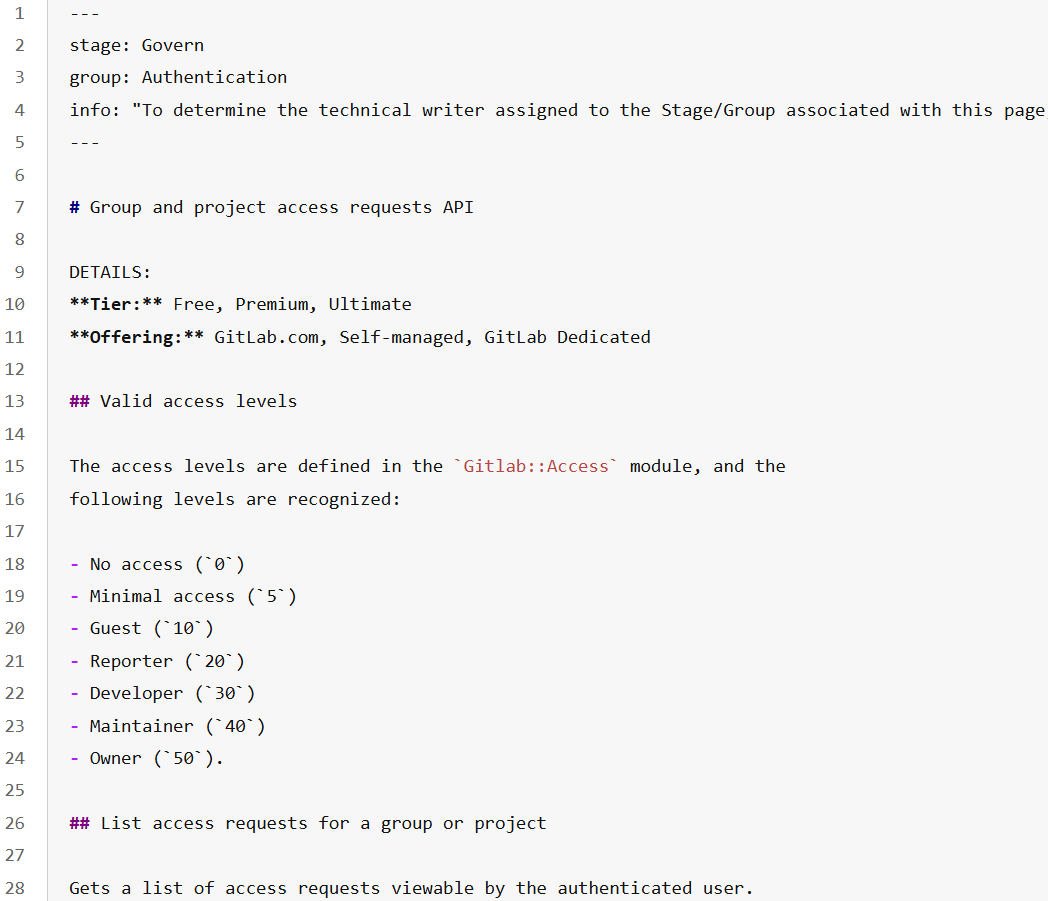
Figure 9: Tool example of Hybrid-Agent: A website-native REST API, linking UI operation to backend functionality.
Practical and Theoretical Implications
These findings enforce a substantial shift in research focus and agent design:
- Stronger, generalist backbone models should not uncritically rely on LLM-synthesized tools. Instead, human-crafted or high-quality composable APIs remain the empirically validated choice for consistent gain.
- Tool design must target coverage and compositional reliability rather than comprehensiveness or complexity. Overly large tool libraries—especially those inflated by weak or redundant tools—impose both performance and resource penalties.
- Semantic skill abstraction, properly surfaced to the agent, offers a powerful avenue for future research, particularly for transparent and interpretable agentic planning.
- Vision remains a critical augment even as text-based tool interfaces proliferate.
Future AI systems for web automation should evolve toward principled mixtures of atomic tool composition, transparent skill distillation, robust fallback to browser actions, and strong grounding in both DOM/state and visual modalities.
Conclusion
This work provides a methodologically rigorous and empirically grounded reassessment of tool use in web agents. It dispels simplistic assumptions regarding tool superiority and underscores the context-dependent, one-way distillation effect of LLM-synthesized tools. The insights regarding tool complexity, compositionality, cost, and semantic skill alternatives establish new baselines for both practice and research in scalable web-agent development. The study’s implications extend to automated RL-based agent design, interpretable skill transfer, and robust multimodal grounding in future interactive AI systems.