- The paper introduces LiveMCP-101, a benchmark with 101 complex tasks to rigorously assess the performance of MCP-enabled agents in dynamic settings.
- It employs a dual-agent execution framework and LLM-based scoring to diagnose planning, tool selection, and parameterization errors.
- Experimental results highlight significant performance gaps among models, emphasizing challenges in multi-step tool orchestration and adaptive reasoning.
LiveMCP-101: Stress Testing and Diagnosing MCP-enabled Agents on Challenging Queries
Introduction and Motivation
The LiveMCP-101 benchmark addresses a critical gap in the evaluation of agentic LLMs operating in dynamic, real-world environments via the Model Context Protocol (MCP). While MCP has standardized tool integration for LLM agents, prior benchmarks have been limited to synthetic, single-step, or static scenarios, failing to capture the complexity and temporal variability inherent in production deployments. LiveMCP-101 introduces 101 rigorously curated tasks spanning web search, file operations, mathematical reasoning, and data analysis, each requiring multi-step, cross-domain tool orchestration. The benchmark construction leverages iterative LLM rewriting and extensive manual review to ensure both complexity and practical solvability.
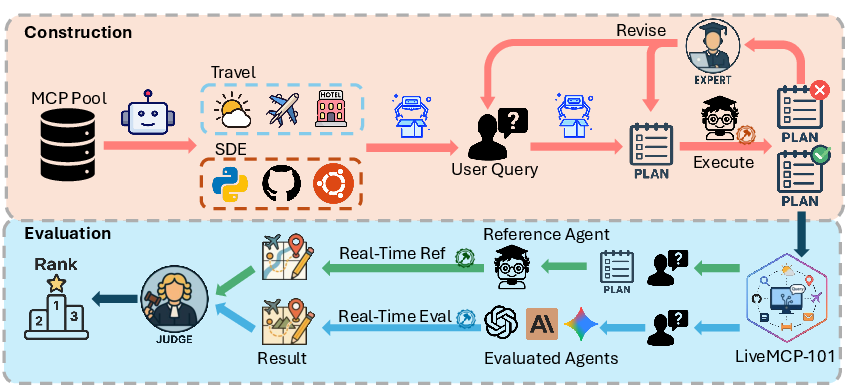
Figure 1: Construction and evaluation framework of LiveMCP-101, illustrating the dual-agent setup and real-time reference execution for robust benchmarking.
Benchmark Design and Evaluation Methodology
LiveMCP-101 is distinguished by its three-tiered difficulty structure (Easy, Medium, Hard), with tasks averaging 5.4 tool-calling steps and involving up to 41 MCP servers and 260 tools. Each query is paired with a validated ground-truth execution plan, generated via LLMs and refined through human verification, ensuring deterministic reference outputs despite the temporal drift of live MCP services.
The evaluation framework launches two parallel executions per task: a reference agent strictly follows the validated plan, while the test agent autonomously analyzes the query and interacts with a superset of MCP tools, including distractors. This setup enables fine-grained diagnosis of planning, tool selection, parameterization, and output handling errors. Scoring is performed by an LLM-as-a-judge using a 1-5 Likert scale for both final results and execution trajectories, mapped to discrete success rates and quality metrics.
Experimental Results and Model Analysis
Eighteen LLMs were evaluated, including proprietary (OpenAI, Anthropic, Google) and open-source (Qwen3, Llama-3) models. The strongest model, GPT-5, achieved a task success rate (TSR) of 58.42% overall, with only 39.02% TSR on Hard tasks, indicating substantial headroom for improvement in tool orchestration and long-horizon planning. Extended thinking (ET) variants of Anthropic models showed consistent gains, while open-source models lagged significantly, with Llama-3.3-70B-Instruct and Llama-3.1-8B-Instruct nearly failing on Hard tasks.
Performance degrades sharply with increasing task difficulty and tool pool size. Closed-source models exhibit a log-shaped curve in token efficiency: initial token increases yield rapid gains, but further increases plateau, suggesting diminishing returns from verbosity and redundant self-checks. Open-source models fail to convert additional tokens into reliable evidence, reflecting lower token efficiency and planning competence.
Ablation studies reveal that increasing the maximum iteration rounds from 15 to 25 improves TSR across all models, but further increases yield negligible gains, indicating that planning quality, not iteration capacity, is the primary bottleneck. Expanding the MCP server pool from 6 to 15 disproportionately degrades performance in weaker and mid-tier models due to increased distractor noise and long-context sensitivity, while top-tier models remain stable.
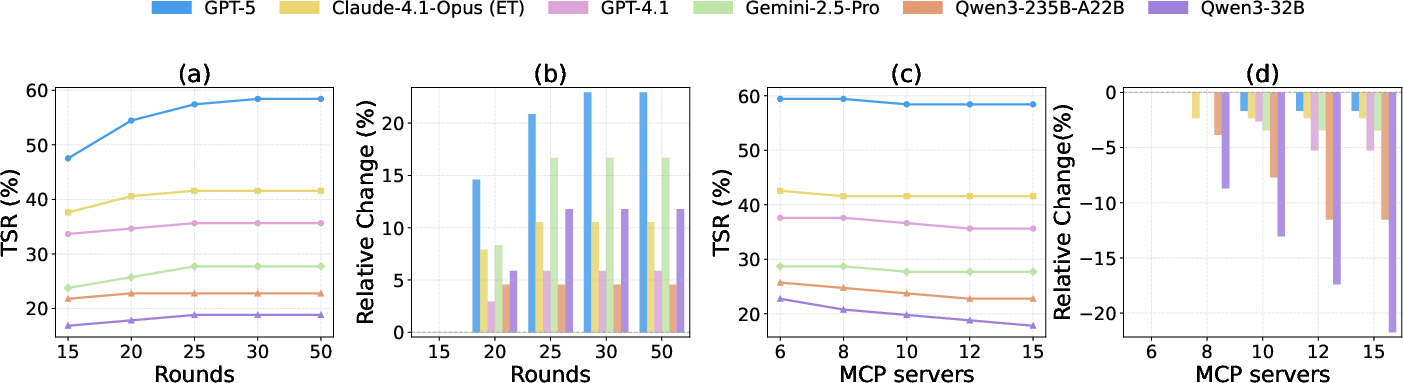
Figure 2: Ablation study results showing the impact of iteration rounds and MCP server pool size on TSR and relative performance changes across model tiers.
Error Analysis and Failure Modes
A comprehensive error classification identifies seven failure subtypes across three categories: tool planning/orchestration, parameter errors, and output handling. Semantic errors dominate, even in strong models (16–25%), while syntactic errors are catastrophic for models lacking MCP-specific fine-tuning (e.g., Llama-3.3-70B-Instruct at ~48%). Overconfident self-solving and unproductive thinking are prevalent in mid-tier models, often leading to premature termination or excessive reliance on internal knowledge.
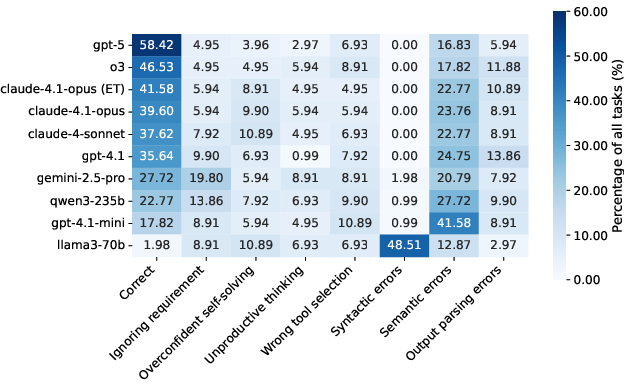
Figure 3: Error classification heatmap across models, decomposing failures into seven fine-grained subtypes and highlighting dominant error patterns.
Evaluation Reliability
Human–LLM agreement studies using Cohen's κ demonstrate high reliability of the LLM-as-a-judge framework, with >85% agreement on result evaluations and >78% on trajectory evaluations, supporting the scalability and consistency of automated scoring in agentic benchmarks.
Implications and Future Directions
LiveMCP-101 establishes a rigorous standard for evaluating autonomous agentic capabilities in realistic, temporally evolving environments. The benchmark exposes persistent challenges in multi-step tool orchestration, adaptive reasoning, and token efficiency, even for frontier LLMs. The detailed error taxonomy and ablation insights suggest that future advances will require targeted improvements in planning, tool selection, and MCP-specific schema grounding, as well as more efficient utilization of token budgets.
Practically, the benchmark provides a scalable framework for diagnosing agentic failures and guiding model development. Theoretically, it motivates research into compositional reasoning, robust tool use under distractors, and dynamic adaptation to evolving external services. Future work may explore curriculum learning for tool orchestration, hierarchical agent architectures, and more sophisticated evaluation protocols that account for real-world variability and long-horizon dependencies.
Conclusion
LiveMCP-101 delivers a comprehensive and challenging benchmark for MCP-enabled agents, revealing substantial gaps in current LLM capabilities and providing actionable insights for advancing autonomous tool-augmented AI systems. The benchmark's design, evaluation methodology, and diagnostic framework set a new bar for agentic evaluation, with implications for both practical deployment and foundational research in agentic AI.

