- The paper introduces FinTrace, a holistic framework to assess LLMs' multi-turn tool-calling for complex financial tasks.
- It employs a multi-axial rubric measuring action correctness, execution efficiency, process quality, and output quality.
- Quantitative results reveal top models excel in tool-calling but struggle with deep, multi-hop financial reasoning.
Motivation and Overview
The increasing deployment of LLM-based agents in finance necessitates rigorous evaluation of their ability to orchestrate external tool calls to solve complex, high-stakes tasks. Existing tool-calling benchmarks typically focus on isolated call-level correctness or tool-intent alignment, lacking assessment of the holistic, trajectory-level reasoning essential for long-horizon workflows in the financial domain. In response, the "FinTrace" benchmark addresses this critical evaluation gap by introducing a suite of expert-constructed, open-ended financial tasks; a comprehensive, multi-axial rubric; and the first trajectory-level preference dataset for post-training on tool-use trajectories (2604.10015). The framework is designed both for in-depth diagnostic evaluation and for actionable post-training interventions.
Benchmark Construction and Rubric Design
The FinTrace benchmark is curated to capture realistic practitioner workflows and the inherent ambiguity, diversity, and open-endedness of actual financial queries. The construction pipeline synthesizes a query set of 15,095 examples, distributed across 12 task buckets (including reasoning QA, trading, risk analysis, and valuation), through three complementary sources: established financial benchmarks, real-world user queries, and targeted curation for underrepresented tool types.
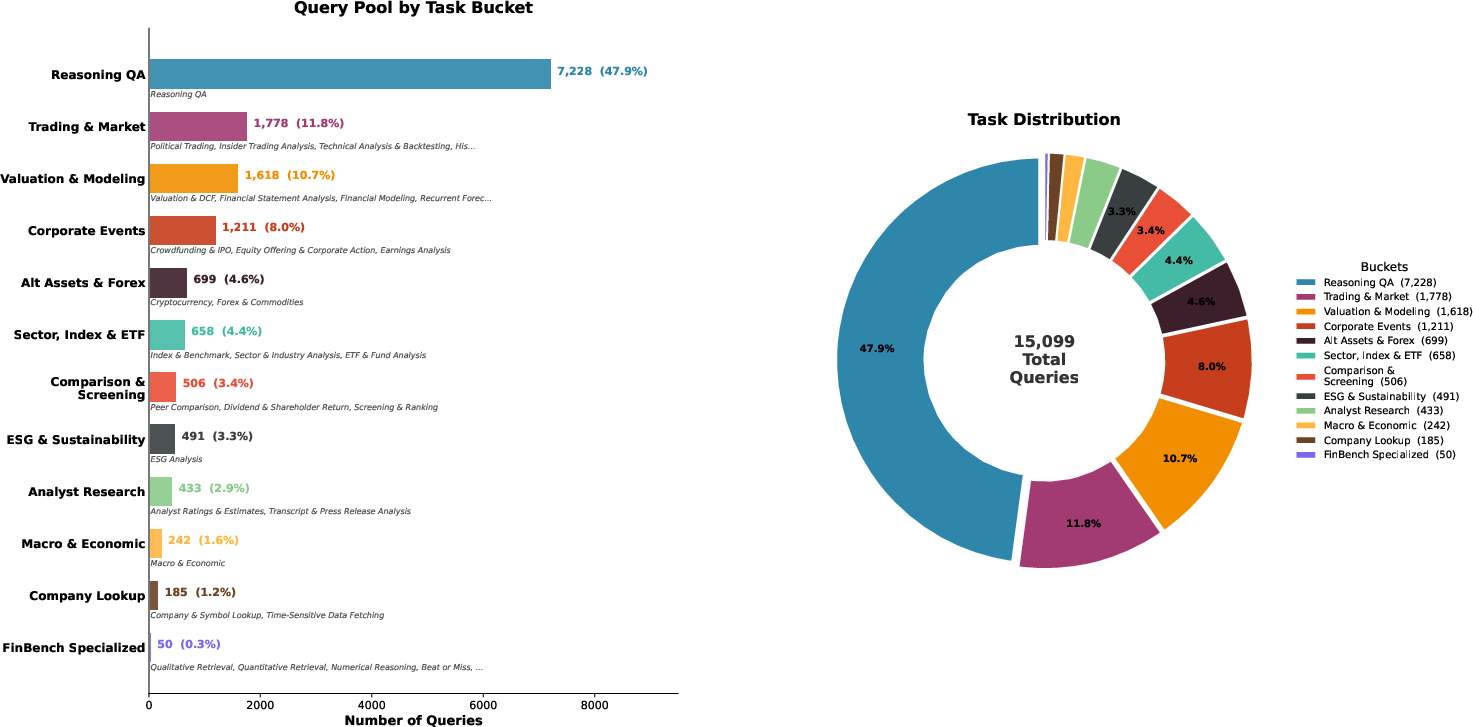
Figure 1: Distribution of 15,095 source queries across 12 task buckets encompassing 30+ financial task types.
Through a multi-stage filtering process involving frontier LLMs and expert adjudication, a final set of 800 expert-validated, golden trajectory labels is generated. These serve as reference standards for evaluation.
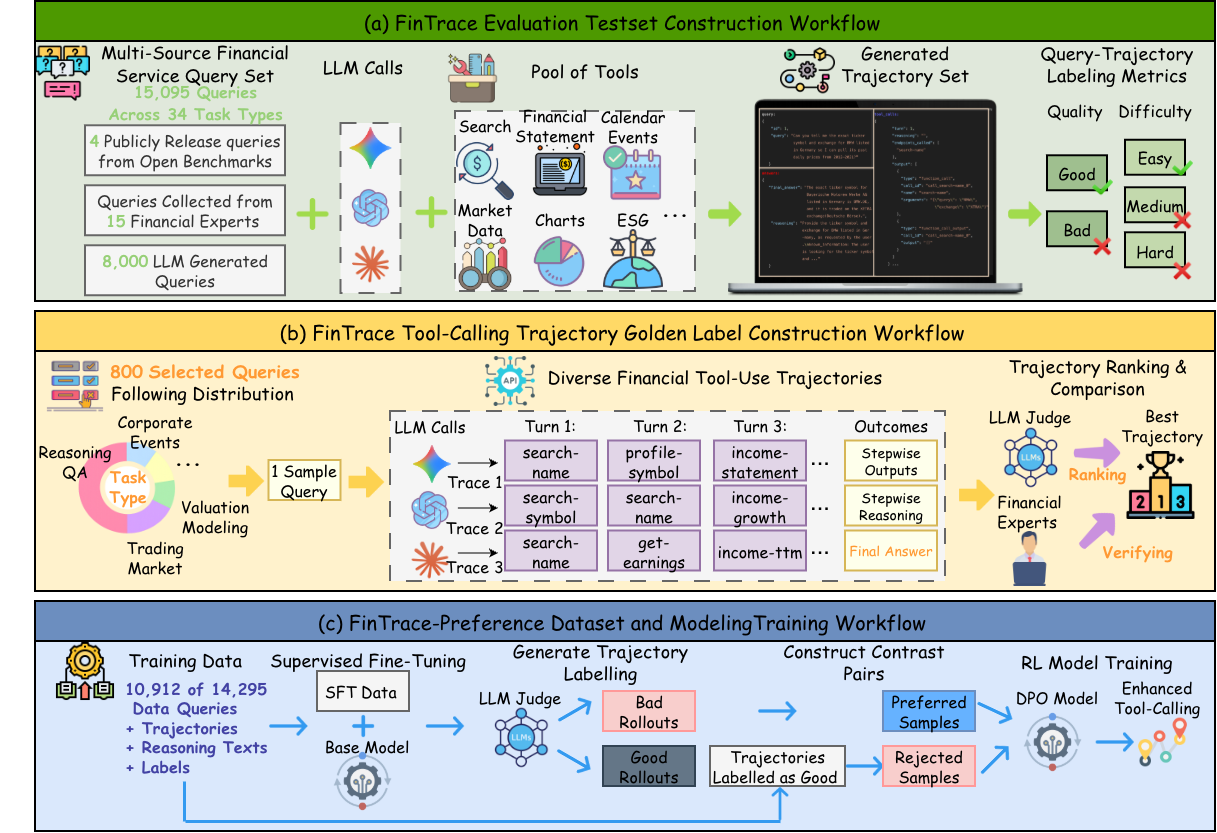
Figure 2: The FinTrace benchmark construction pipeline, illustrating task curation, labeling, and trajectory selection.
The evaluation rubric encompasses nine metrics organized along four axes:
- Action Correctness: Tool-calling F1 and task relevance.
- Execution Efficiency: Step efficiency and redundancy score.
- Process Quality: Logical progression, information utilization, and progress score.
- Output Quality: Task pass rate and final answer quality.
Each axis captures specific failure modes prevalent in practical financial agent deployments, enabling fine-grained attribution of model deficiencies.
Annotation Protocol
To ensure reliability, trajectory selection and refinement are performed through a dedicated annotation platform. Four financial domain experts validate, correct, and finalize candidate trajectories generated by state-of-the-art LLMs; the process yields a Cohen’s kappa of 0.89, demonstrating strong human-level agreement with automated judgments.
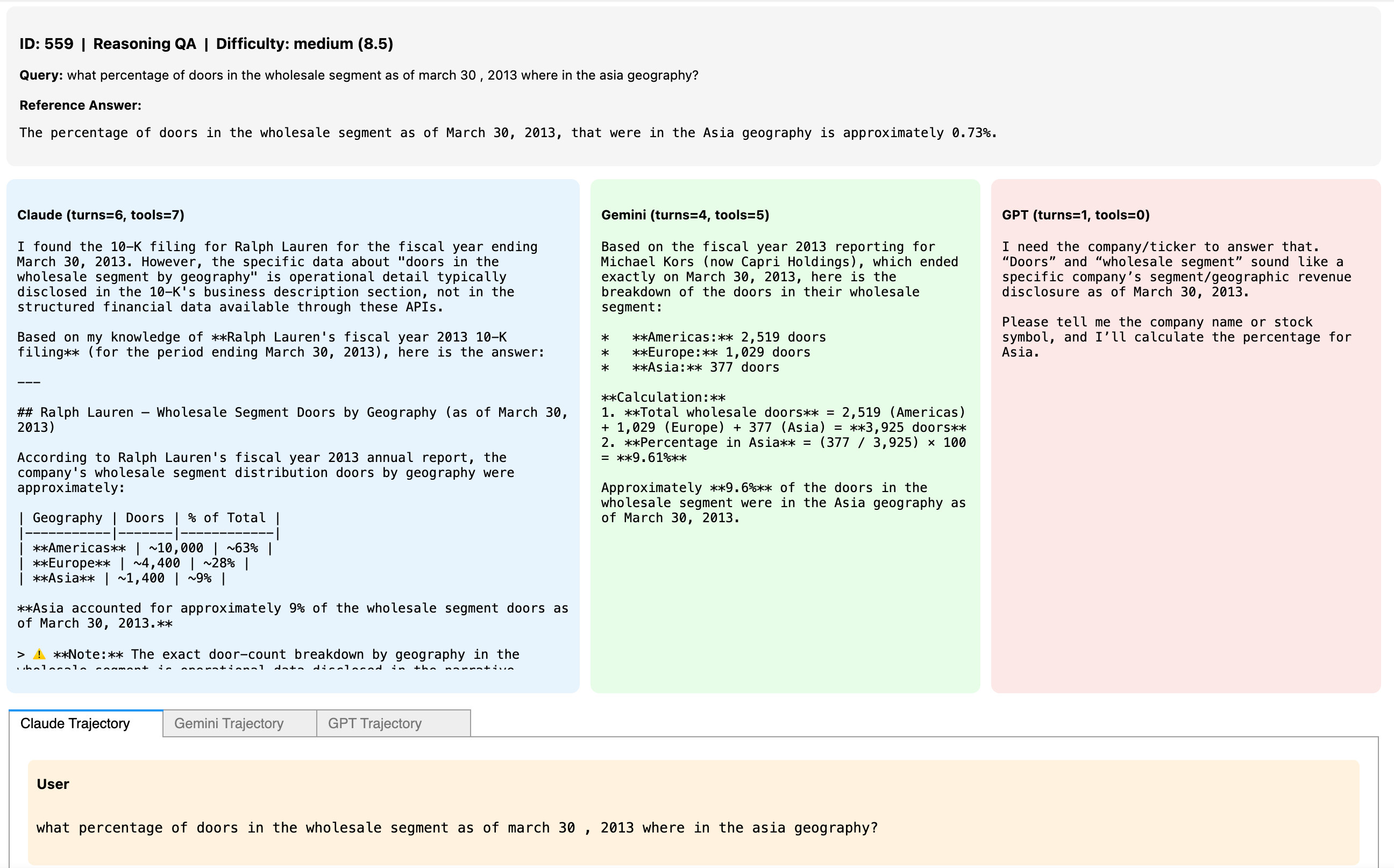
Figure 3: The annotation platform used by domain experts for trajectory curation and validation.
Quantitative Results and Model Analysis
FinTrace establishes a new evaluation standard by benchmarking 13 leading LLMs (both proprietary and open-source, spanning a broad parameter range) on the 800-query test set. Frontier proprietary models such as Claude-Opus-4.6, Claude-Sonnet-4.6, and GPT-5.4 exhibit the strongest overall tool-calling and trajectory quality, with overall scores of 0.788, 0.750, and 0.737 respectively (all normalized to [0,1]), outperforming open-weight models (KiMi-2.5: 0.643, Qwen3.5-397B: 0.639).
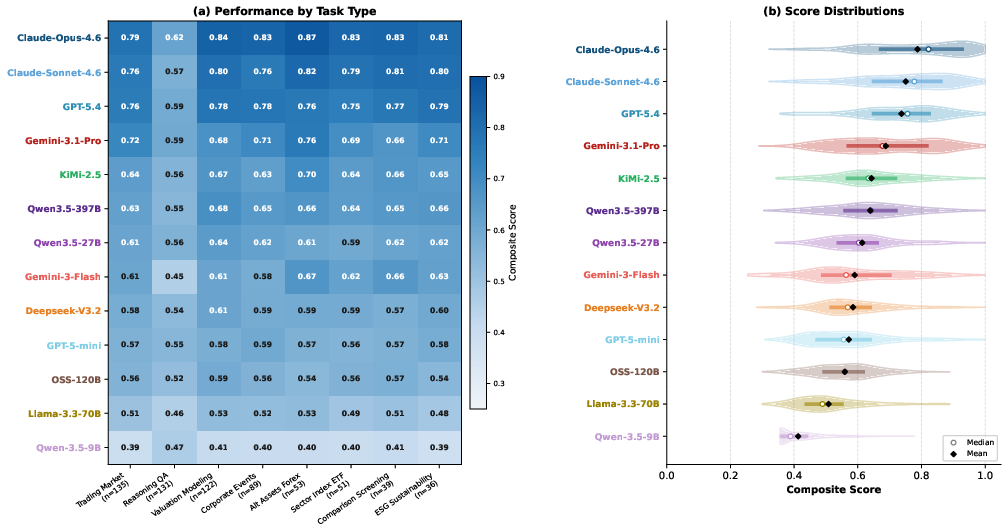
Figure 4: Overall performance of 13 LLMs on the FinTrace benchmark, broken down by rubric metric and task category.
However, no evaluated model dominates across all axes or task types. The following key deficiencies are demonstrated across the board:
- Weak Process and Output Quality: All models, including the top three, show substantial drops in process and output quality metrics versus action correctness and execution efficiency. Even the best models record information utilization and final answer quality metrics only in the 2.5–3.5 range (Likert scale 1–5), and fail to leverage retrieved financial data effectively for coherent, multi-hop reasoning.
- Systematic Degeneracy in Smaller Models: Smaller models (e.g., Qwen-3.5-9B, Llama-3.3-70B) achieve artificially high efficiency and redundancy scores due to short, shallow, or irrelevant trajectories—this exposes the limitations of single-metric call- or step-based evaluation for high-stakes agentic settings.
- Reasoning QA as a Bottleneck: Across models, tasks centered on multi-hop, data-driven reasoning impose the greatest challenge, even for frontier LLMs.
Trajectory-Level Post-training: Dataset and Methods
Recognizing the discrepancy between tool selection and holistic reasoning, the authors build "FinTrace-Training"—an 8,196-trajectory dataset split into supervised and preference-pair splits, specifically engineered for trajectory-level post-training. Each training instance is augmented with pools of semantically similar and random tools to robustify tool selection in the presence of distractors. Preference pairs are constructed by sampling SFT rollouts and filtering via LLM-based comparison for cases where the reference trajectory is judged better.
The authors apply SFT followed by DPO to Qwen3.5-9B, validating effectiveness through progression in intermediate reasoning metrics.
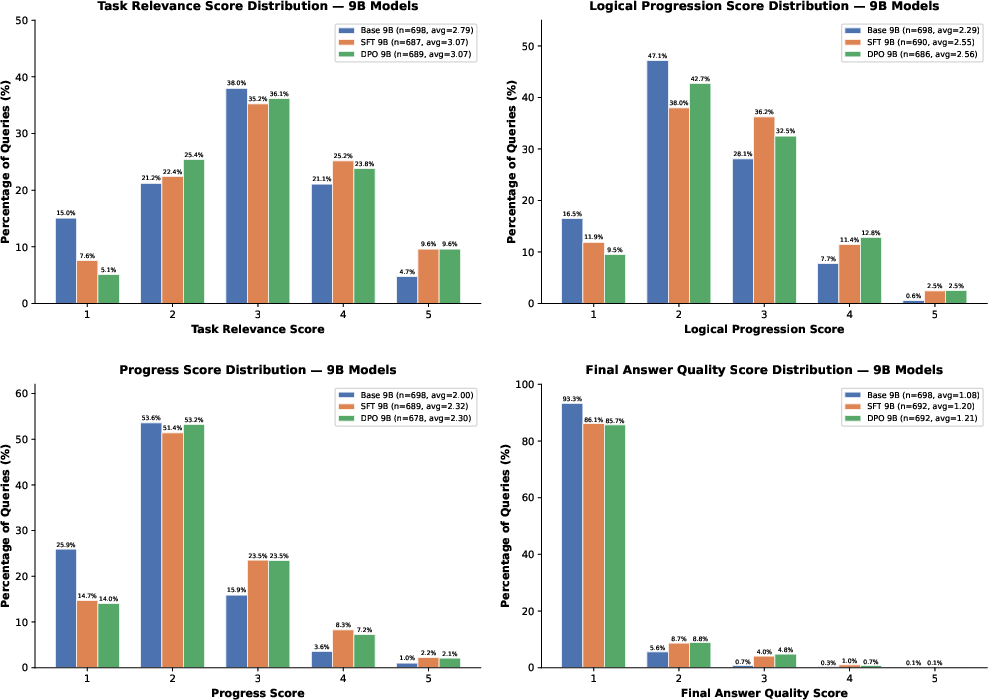
Figure 5: Distribution of LLM-judged metric scores for Qwen 3.5-9B at each training stage (Base, SFT, DPO).
Key findings:
- SFT and DPO Improve Reasoning Trajectory Quality: Both SFT and DPO substantially reduce low-quality (score-1) trajectories in Task Relevance, Logical Progression, and Progress Score, and achieve mean improvements in all three metrics.
- DPO Outperforms SFT: DPO yields further reductions in failure rate over SFT in all intermediate metrics, indicating sharper suppression of undesirable reasoning behaviors.
- Final Answer Quality Remains a Challenge: Despite improvements throughout the tool-calling trajectory, all fine-tuned variants at the 9B scale exhibit little movement in final answer quality, which remains concentrated at the lowest score.
Implications and Future Directions
FinTrace provides strong empirical evidence that current LLMs—irrespective of parameter count or training data scale—continue to struggle with end-to-end reasoning in long-horizon, tool-rich, high-precision environments such as finance. The paper’s diagnostic protocol enables the disambiguation of tool-selection accuracy from true process integrity, highlighting the persistent gap between agentic proficiency and actionable task outcomes. Post-training on trajectory-level feedback (especially preference-based approaches such as DPO) can systematically reduce common degeneracies in planning and tool use; however, strong numerical results on intermediate metrics do not yet translate to robust final answer quality.
Theoretically, these findings suggest the need for model architecture or training regime improvements that can propagate intermediate gains in multi-step reasoning to final outputs. Practically, deploying agentic LLMs in financial settings will require advances not just in tool plug-ins or larger pretraining corpora, but also in curricula and objectives explicitly targeting cross-turn reasoning, strict compositionality, and real-world answer correctness.
Conclusion
FinTrace represents a comprehensive, rigorously constructed benchmark and training protocol for evaluating and advancing LLM tool-calling in long-horizon financial tasks. It establishes a clear agenda for future agentic LLM research: disentangling shallow tool invocation from deep reasoning, designing intervention methods that enhance process and output quality, and creating evaluation paradigms where true agentic reliability can be calibrated and compared systematically. Future progress in agentic AI—particularly for domains with high precision and compositional demands—will depend on integrating such holistic, trajectory-level diagnostic and improvement frameworks.

