- The paper introduces BizFinBench, a business-driven benchmark designed to evaluate LLM performance on real-world financial queries.
- It uses 6,781 annotated queries across diverse tasks, employing IteraJudge to minimize bias and ensure reliable multi-step reasoning assessment.
- Experimental results reveal performance gaps among various LLMs, highlighting the need for further refinement and optimization in handling complex financial tasks.
BizFinBench: A Business-Driven Real-World Financial Benchmark for Evaluating LLMs
Introduction
The paper presents BizFinBench, a comprehensive, business-centric benchmark specifically tailored for evaluating the performance of LLMs in financial domains. This work addresses the challenge of assessing LLM robustness in complex, precision-critical tasks typical in finance, law, and healthcare. Unlike traditional benchmarks which often simplify these scenarios, BizFinBench aims to rigorously test LLMs using real-world financial inquiries. The benchmark encompasses diverse tasks spanning numerical calculations, reasoning, information extraction, prediction, and question answering, thereby offering a holistic evaluation framework for LLM capabilities in financial applications.
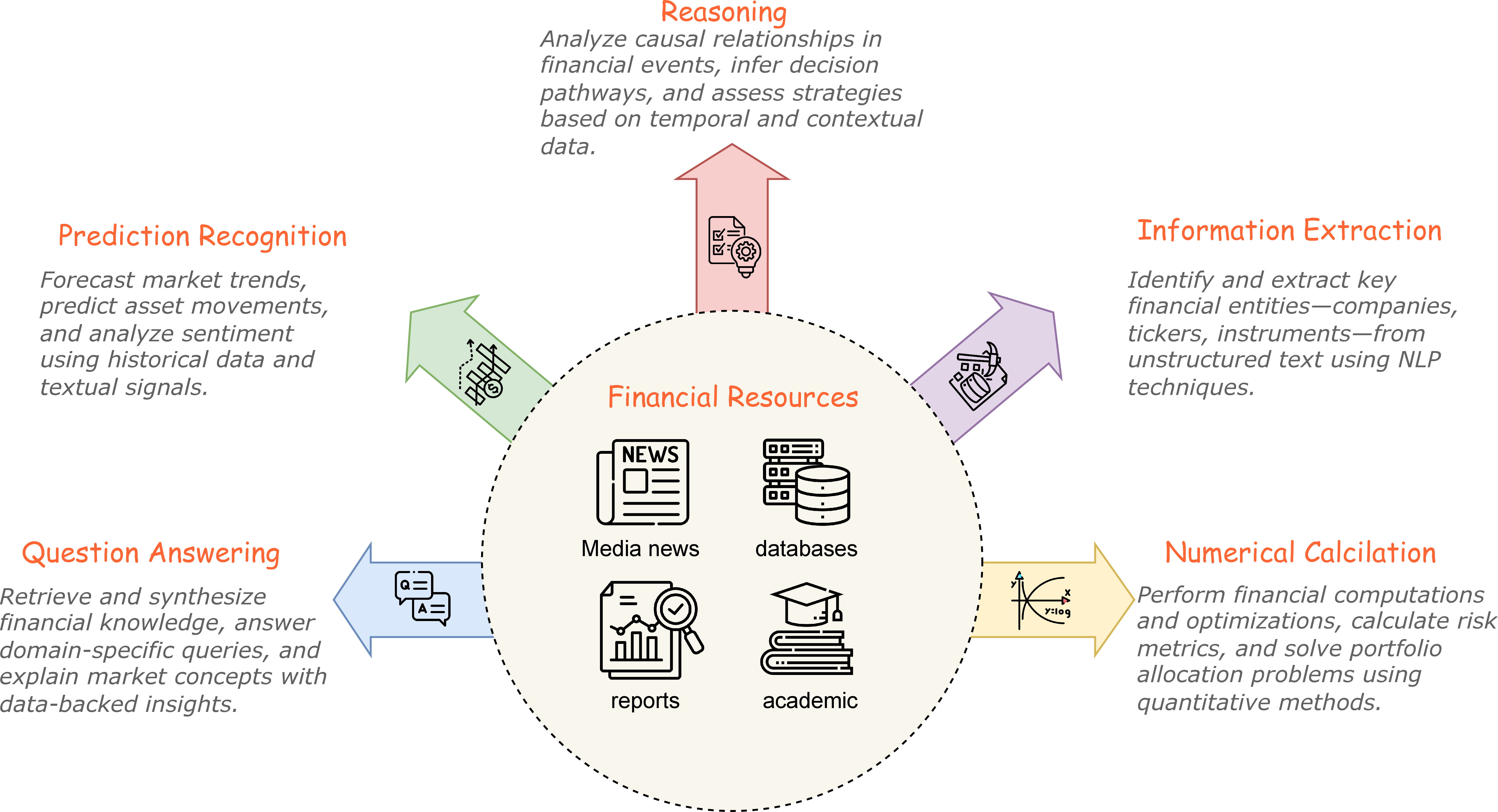
Figure 1: Distribution of tasks in BizFinBench across five key dimensions.
Data Construction and Structure
BizFinBench consists of 6,781 well-annotated queries, organized across five key dimensions and nine fine-grained categories, such as numerical computation and anomalous event attribution. The dataset derives from real-world financial user queries, reflecting actual complexities encountered by financial professionals. Each task requires multi-step reasoning, where model outputs must incorporate contextual analysis, temporal reasoning, and cross-conceptual understanding. The dataset's design ensures a realistic representation of financial task challenges, empowering LLMs to effectively engage with ambiguous, dynamic, and noise-rich contexts typical of financial data.

Figure 2: Workflow of BizFinBench dataset construction.
Evaluation Methodology
Central to BizFinBench is IteraJudge, a novel LLM evaluation method designed to minimize evaluator bias, especially when models serve as evaluators. This method involves iterative assessment and refinement of model outputs based on predefined criteria, ensuring high accuracy and reliability. Additionally, BizFinBench evaluates models using both objective metrics, such as accuracy, and subjective metrics captured through LLM-assisted judging of more nuanced tasks. This dual approach provides a comprehensive evaluation of model performance across diverse financial scenarios.
Figure 3: IteraJudge Pipeline.
Results and Analysis
In experimental evaluations involving 25 LLMs, BizFinBench reveals distinct strength patterns. Certain proprietary models, such as Claude-3.5-Sonnet, excelled in numerical calculation, while others like ChatGPT-o3 demonstrated superior reasoning capabilities. The results underline that existing LLMs often lack consistent performance across different financial tasks. Specifically, smaller open-source models underperform, highlighting their limitations in handling complex financial queries. Moreover, even state-of-the-art models grapple with tasks requiring intricate multi-step logical reasoning, indicating potential areas for further refinement and optimization.
Implications and Future Work
The introduction of BizFinBench marks a significant step towards aligning LLM evaluation with real-world financial applications. By focusing on business-aligned benchmarks, the research aims to bridge the gap between theoretical LLM performance and practical applicability. Future developments may involve expanding the dataset to include emerging financial trends, incorporating more sophisticated adversarial scenarios, and refining the evaluation framework to include more interactive, multi-turn financial analyses. Such enhancements can further fortify LLMs against the complex demands of financial intelligence tasks.
Conclusion
BizFinBench offers a pioneering framework for rigorously assessing LLMs within the context of real-world financial challenges. By integrating complex, business-oriented tasks and employing sophisticated evaluation techniques like IteraJudge, the benchmark sets a new standard for evaluating LLM performance in specialized, high-stakes sectors. This approach not only enhances our understanding of current model limitations but also guides future innovations towards more adept, contextually sensitive financial AI systems.

