FinTradeBench: A Financial Reasoning Benchmark for LLMs
Abstract: Real-world financial decision-making is a challenging problem that requires reasoning over heterogeneous signals, including company fundamentals derived from regulatory filings and trading signals computed from price dynamics. Recently, with the advancement of LLMs, financial analysts have begun to use them for financial decision-making tasks. However, existing financial question answering benchmarks for testing these models primarily focus on company balance sheet data and rarely evaluate reasoning over how company stocks trade in the market or their interactions with fundamentals. To take advantage of the strengths of both approaches, we introduce FinTradeBench, a benchmark for evaluating financial reasoning that integrates company fundamentals and trading signals. FinTradeBench contains 1,400 questions grounded in NASDAQ-100 companies over a ten-year historical window. The benchmark is organized into three reasoning categories: fundamentals-focused, trading-signal-focused, and hybrid questions requiring cross-signal reasoning. To ensure reliability at scale, we adopt a calibration-then-scaling framework that combines expert seed questions, multi-model response generation, intra-model self-filtering, numerical auditing, and human-LLM judge alignment. We evaluate 14 LLMs under zero-shot prompting and retrieval-augmented settings and witness a clear performance gap. Retrieval substantially improves reasoning over textual fundamentals, but provides limited benefit for trading-signal reasoning. These findings highlight fundamental challenges in the numerical and time-series reasoning for current LLMs and motivate future research in financial intelligence.
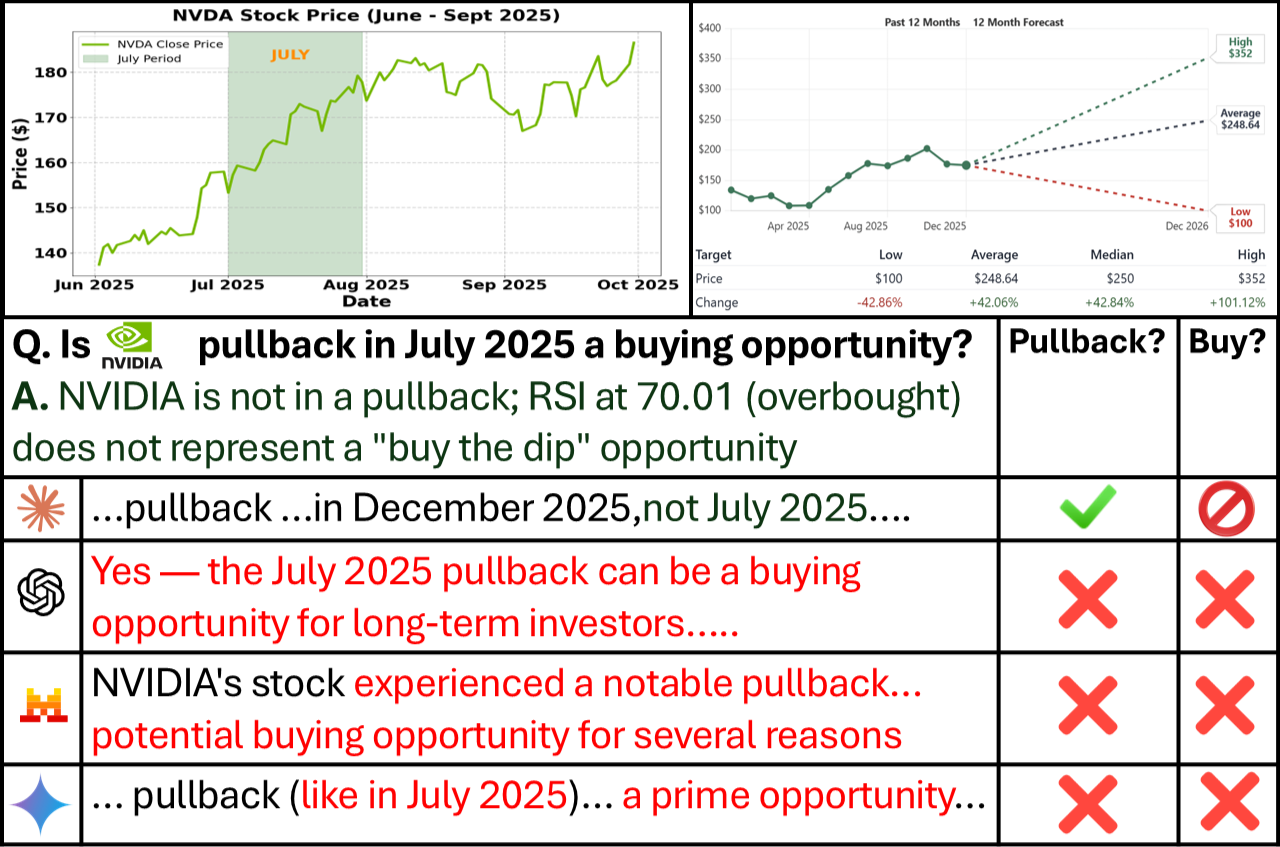

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
FinTradeBench: What this paper is about
This paper introduces FinTradeBench, a new “test” for AI LLMs that checks how well they can think about finance. It focuses on two kinds of information people use to judge a company’s stock:
- Company fundamentals: facts from official reports (like profits, debts, and sales)—think of these like a company’s health check-up.
- Trading signals: patterns in stock prices and volume over time—think of these like a heart-rate graph showing how the stock is behaving day to day.
The goal is to see whether AI can understand each of these on their own and, more importantly, combine both to make better decisions—just like a real analyst would.
What questions did the researchers ask?
In simple terms, the paper asks:
- Can today’s AIs answer finance questions that require reading company reports (fundamentals)?
- Can they handle questions that require looking at price patterns over time (trading signals)?
- Can they combine both types of information to make a sensible judgment?
- Does “looking things up” during answering (called retrieval) help them do better?
How did they do it?
To test this, the team built a 1,400-question benchmark covering NASDAQ-100 companies across 10 years (2015–2025). The questions fit into three groups:
- Fundamentals-focused: based on company reports (like profitability or debt ratios).
- Trading-focused: based on price and volume patterns (like momentum or volatility).
- Hybrid: questions that require using both at once.
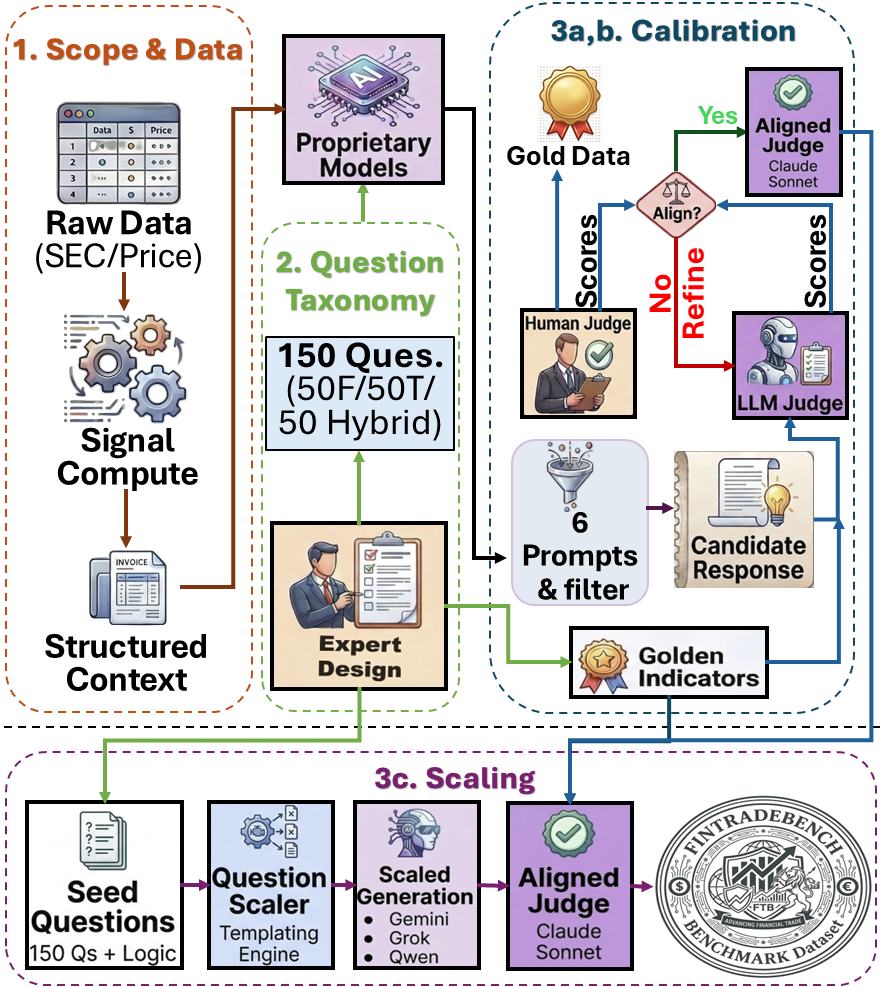
They used a careful three-step process to make the benchmark reliable and fair:
- Start small with experts:
- Finance experts wrote a seed set of questions and “golden indicators” (the key facts needed for a correct answer).
- Calibrate quality:
- Multiple AI models generated answers. Each model picked its best answer.
- A separate AI and human experts checked the answers for correctness and clear reasoning.
- The team aligned how the AI judge scored answers with how humans scored them, so automatic grading stayed trustworthy.
- Scale up safely:
- Using the aligned judge, they expanded the questions across many companies and time periods to reach 1,400 questions.
They also tested 14 different AI models in two modes:
- No lookup (like a closed-book test).
- With retrieval (RAG, short for “retrieval-augmented generation”)—like an open-book test where the model can pull in relevant documents (company filings and price data) while answering.
Key terms explained in everyday language:
- Company fundamentals: Details from official filings (e.g., SEC 10-K/10-Q) about how healthy a business is—profits, debts, valuations, and more.
- Trading signals: Numbers computed from stock prices and trading volumes over time (e.g., moving averages, momentum, RSI). Think of them as patterns in how the stock has been moving.
- RAG (retrieval-augmented generation): Letting the AI “look things up” from a library of documents and data while answering, instead of relying only on memory.
- Time series: Data that changes with time (like a daily stock price list).
What did they find?
Here are the big takeaways:
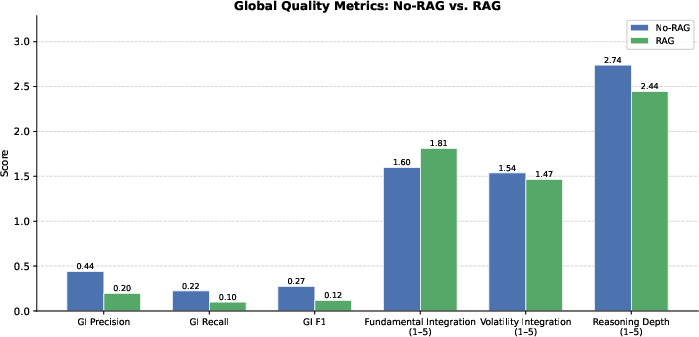
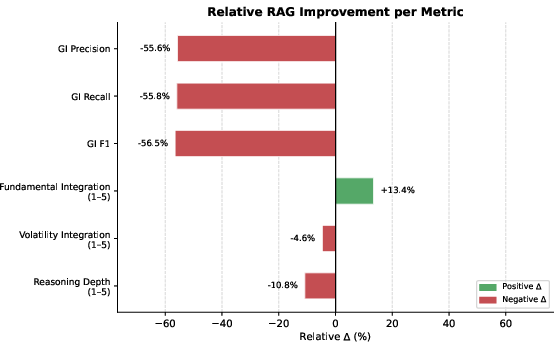
- Looking things up helps with reading reports, but not with price patterns.
- When models were allowed to retrieve company filings, they got much better at fundamentals questions and improved on mixed (hybrid) questions.
- But retrieval didn’t help on trading-signal questions (based on price data). In many cases, it actually made things worse. Why? Because the AI struggled to compute and interpret numerical patterns from raw price tables.
- Models that “think step by step” did better at mixing both types of information.
- Models designed for deeper reasoning did best on hybrid questions (those that need both fundamentals and trading signals). This suggests careful, step-by-step thinking helps when signals conflict or need to be combined.
- More information can distract the AI.
- With retrieval, models often produced answers full of facts and quotes but missed the key indicators that actually matter for the question. In other words, they sounded informed but didn’t always focus on the right numbers.
- Model design matters more than size.
- Some model families improved a lot with retrieval; others got worse, even when they were large. This shows that what a model was trained on and how it reasons can be more important than how big it is.
Why this is important:
- In real finance, both a company’s health (fundamentals) and its stock’s behavior (trading signals) matter. This benchmark shows that current AIs are decent at reading reports (especially with retrieval) but struggle with interpreting and computing time-based price patterns. That’s a major gap if we want AI to help with investment analysis responsibly.
Why it matters and what could come next
- Better tools for numbers and time series are needed:
- The results suggest that AI models should be paired with calculators or small programs that can compute trading indicators (like RSI or momentum) instead of trying to reason from raw numbers alone.
- Smarter “open-book” systems:
- Retrieval should give models the right precomputed signals—not just long documents and raw data—to avoid overwhelming them and to focus their reasoning.
- Fair, realistic testing:
- FinTradeBench gives researchers and companies a way to measure real financial reasoning, not just reading comprehension. It can help track progress and avoid overclaiming what AI can do in finance.
In short: This paper builds a practical, carefully designed test that shows where AI is strong (reading financial reports with help) and where it still struggles (making sense of time-based price patterns and combining both kinds of signals). It points the way toward better AI systems that can calculate, compare, and reason with numbers more like a skilled analyst.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased to inform concrete next steps for researchers:
- External validity and coverage: The dataset is limited to NASDAQ-100 firms (large-cap, U.S.) from 2015–2025; it is unknown whether findings generalize to small/mid-caps, international markets, other asset classes (fixed income, FX, commodities), earlier regimes (e.g., 2008 crisis), or longer horizons.
- Market-regime robustness: The benchmark does not stratify performance by market regimes (bull/bear, high/low volatility, crisis periods); it is unclear how model performance varies across distinct macro/volatility environments.
- Limited signal breadth: Trading signals are derived from daily OHLCV and a compact set of indicators; the benchmark omits higher-frequency signals, order-book/microstructure features, options/implied volatility, cross-asset factors, and macroeconomic variables that strongly influence real-world decisions.
- Fundamentals extraction fidelity: The reliability of parsing and normalizing fundamentals from SEC filings (tables vs. narrative, restatements, fiscal calendar misalignments) is not audited in detail; error rates and their impact on evaluation are unreported.
- Temporal alignment risks: Aligning daily time-series with quarterly fundamentals can introduce leakage or mis-timing; the paper does not quantify alignment errors or define guardrails for event-timing (e.g., earnings release vs. filing dates).
- Ground-truth objectivity for trading questions: Many trading-signal tasks can admit multiple reasonable interpretations; the paper relies on “golden indicators” and LLM-judge scoring rather than outcome-based or rule-based ground truths, leaving ambiguity about what constitutes correctness under conflicting signals.
- Reliance on LLM-as-judge at scale: Only 150 seed questions have expert evaluation; the remaining ~1,250 rely on a single LLM judge calibrated to humans (MAE < 10%). Inter-judge robustness, failure modes, and propagation of subtle judge biases across categories are not assessed.
- Judge generalization and drift: The stability of the judge’s scoring across time, model families, prompt styles, and future model updates is not evaluated; no cross-judge or cross-rubric consistency checks beyond the seed set are provided.
- Data contamination risk: Some evaluated periods (e.g., 2025) may overlap with LLM pretraining or public post-training knowledge; contamination safeguards and diagnostics for memorization vs. reasoning are not described.
- Small benchmark size: 1,400 questions may be insufficient to robustly stratify by sector, regime, difficulty, and question templates while maintaining statistical power for multiple comparisons and ablations.
- Question diversity and difficulty calibration: Beyond the F/T/FT taxonomy, difficulty levels, concept coverage, and distributional balance (firms, sectors, periods, indicator types) are not reported, limiting interpretability of accuracy gaps.
- Limited model diversity and finance-specific baselines: The evaluation omits specialized finance LLMs/agents and tool-augmented systems (e.g., code execution, TA-Lib, spreadsheets), making it unclear whether deficits on trading tasks are model-inherent or pipeline-related.
- Tool-use integration for time-series reasoning: The paper hypothesizes that quantitative tasks require intermediate computation but does not implement or benchmark code/tool-augmented pipelines (e.g., Python, calculators, program-of-thought) against RAG-only approaches.
- “Ideal RAG” not systemically evaluated: The case study shows large gains with precomputed indicators but lacks a systematic benchmark variant or ablation to quantify how precomputation (vs. raw time-series) affects performance across many questions and models.
- RAG design ablations are missing: The dual-track retrieval is fixed; there is no systematic comparison of alternative chunking, encoder choices, numeric-aware reranking for time-series, query rewriting, or source-specific compression to mitigate distraction.
- Context distraction vs. compression strategies: The paper observes RAG-induced distraction and reduced reasoning depth but does not test structured outputs, checklists, stepwise extraction of golden indicators, or architecture-aware context compression.
- Prompting and decoding sensitivity: While TELeR prompts (N=6) are used, there is no analysis of prompt-template sensitivity, best-of-N size, temperature/top-k effects, or explicit chain-of-thought vs. no-CoT ablations across categories.
- Statistical testing assumptions: Paired t-tests assume independence and normality across question-level scores; no checks for violation of assumptions or alternative nonparametric tests are reported.
- Reproducibility and versioning: Some model labels (e.g., “GPT-5-mini”) and proprietary endpoints lack exact versions, hyperparameters, or seeds; full reproducibility and run-to-run variance are unreported.
- Retrieval for time-series lacks numeric-aware reranking: Track B bypasses cross-encoder reranking; the paper does not explore specialized numeric/temporal similarity functions or learned retrievers tuned for sequence patterns.
- Golden indicator extraction evaluation gap: The paper reports F1 drops with RAG but does not release or analyze per-indicator confusion (e.g., which indicators are frequently missed) or test structured-answer formats to enforce indicator coverage.
- Sector/event-specific performance: No breakdown of performance by sector (e.g., financials vs. tech) or by event types (earnings, guidance revisions, splits) is provided, limiting actionable insights for domain practitioners.
- Handling contradictory signals: The benchmark highlights conflicts between fundamentals and market narratives but does not formalize evaluation protocols for acceptable alternative analyses or tie-break rules, risking penalization of nuanced, defensible answers.
- Cost/latency and practicality: Computational costs (RAG indexing, retrieval, generation, judging), latency, and throughput tradeoffs are not reported, limiting guidance for deployment in real-world analyst workflows.
- Multilingual and cross-jurisdiction applicability: The benchmark is English/US-centric; applicability to non-English filings, differing accounting standards (IFRS), and local market conventions is untested.
- Release readiness and licensing: The dataset is not fully released (subset only); details about data sources/licensing for price data and filings, regeneration scripts, and long-term maintenance plans are not specified.
- Ethical and misuse safeguards: While ethical considerations are referenced, concrete safeguards for preventing the benchmark from being used to imply trading performance or financial advice are not articulated.
Practical Applications
Immediate Applications
The following applications can be deployed with current methods, data availability, and infrastructure described in the paper.
- Benchmark-driven model selection for financial QA and analysis assistants — Sectors: finance, software
- What: Use FinTradeBench to pick the right LLM (e.g., latent-reasoning models for hybrid questions, RAG-enabled models for fundamentals) for specific analyst workflows (earnings-call Q&A, filing summarization, valuation checks).
- Tools/workflows: Vendor bake-offs against FinTradeBench; per-task scorecards (F vs. T vs. FT); procurement checklists with category-specific thresholds.
- Assumptions/dependencies: Access to the benchmark subset and evaluation scripts; acceptance that NASDAQ‑100, 2015–2025 scope approximates target use; organizational tolerance for benchmark-to-production domain shift.
- Compliance-aware RAG copilots for fundamentals-focused tasks — Sectors: finance, enterprise software
- What: Deploy the dual-track RAG with parent–child chunking, BM25+dense retrieval+re-ranking, and metadata injection to power assistants that answer filing-related questions and reduce hallucinations.
- Tools/products: SEC filings copilot for IR/sell-side teams; auditors’ assistant that links answers to retrieved 10‑K/10‑Q sections; explainability UI showing “golden indicators” used.
- Assumptions/dependencies: Reliable EDGAR access; document chunking/indexing pipeline; human review for regulated contexts; legal disclaimers.
- “Ideal RAG” via precomputed technical indicators for trading-signal queries — Sectors: finance, fintech
- What: Precompute momentum/volatility/RSI/MACD and supply signals (not raw OHLCV tables) to the model, as the paper shows this mitigates numerical parsing failures and distraction.
- Tools/workflows: Nightly feature pipeline; feature store keyed by ticker/period; prompt templates that reference signals explicitly; caching for popular tickers.
- Assumptions/dependencies: Licensed price data; reproducible signal definitions; versioning and data lineage; clear data-lag policies.
- Analyst “hybrid reasoning” playbooks that combine fundamentals and trading signals — Sectors: asset management, research
- What: Embed hybrid prompts and reasoning scaffolds (TELeR-based) for tasks like “valuation plus momentum check,” with chain-of-thought suppressed in output but used internally.
- Tools/workflows: Prompt libraries aligned to F/T/FT taxonomy; pre- and post-answer checklists that verify golden indicators were referenced.
- Assumptions/dependencies: Use of latent reasoning–capable models (e.g., DeepSeek‑R1 class or distills); prompt governance; red-teaming for leakage of chain-of-thought.
- Data engineering patterns for doc+time-series retrieval — Sectors: data platforms, enterprise AI
- What: Adopt parent–child chunking for long filings, temporal filters for time-series retrieval, and source-specific quotas to prevent text overwhelming numerical evidence.
- Tools/workflows: Retrieval orchestration layer separating Track A (text) and Track B (time series); duplicate parent-context suppression; temporal metadata injection.
- Assumptions/dependencies: Vector DB with custom reranking support; time alignment between filings and market data; monitoring for context budget overruns.
- LLM-as-judge pipelines calibrated to human raters for numeric tasks — Sectors: software, academia, QA
- What: Reuse the calibration-then-scaling framework (multi-model sampling, self-filtering, numerical auditing, human–LLM judge alignment) to evaluate generative systems in finance and other numeric domains.
- Tools/workflows: Independent judge model + rubric mirroring human criteria; numerical claim auditor; MAE tracking for human–LLM alignment.
- Assumptions/dependencies: Availability of domain experts for initial calibration; stability of judge prompts over time; acceptance of LLM-judge limitations.
- Teaching modules and coursework for FinNLP and quant finance — Sectors: education, academia
- What: Use the benchmark and observed failure modes (time-series reasoning, distraction) in classes and labs; student projects on retrieval design and indicator computation.
- Tools/workflows: Assignments benchmarking models on F/T/FT tasks; labs implementing “ideal RAG.”
- Assumptions/dependencies: Access to code/data subset; institutional data-use policies; compute for classroom-scale experiments.
- Investor education features in retail apps (with disclaimers) — Sectors: consumer fintech
- What: Add explainers that compute and interpret a few precomputed indicators alongside simple fundamentals for a given ticker and date range; teach when signals can conflict.
- Tools/products: “Signals 101” panel; side-by-side fundamentals vs. momentum visualization; answer rationales grounded in retrieved filings.
- Assumptions/dependencies: Strict “not investment advice” posture; supervisory review; clear UI indicating data time window and lag.
- Vendor evaluation dashboards for banks and funds — Sectors: finance, procurement/risk
- What: Operationalize category-level accuracy, delta-from-RAG, and golden-indicator F1 into dashboards for model governance and vendor selection.
- Tools/workflows: Automated test harness; significance testing on per-task distributions; model-change alerts when performance drifts.
- Assumptions/dependencies: Internal governance acceptance; reproducible test conditions; segregation between evaluation and production data.
Long-Term Applications
These applications need further research, broader data, more robust tooling, or regulatory/scaling work before deployment.
- Full-stack AI research analyst with tool-use for code-based time-series computation — Sectors: finance, software
- What: An agent that retrieves filings, computes technical indicators via code execution or external notebooks, reconciles conflicting signals, and drafts decisions with auditable logs.
- Tools/products: Toolformer- or function-calling LLM integrated with a quantitative library; provenance tracking; scenario analysis; compliance-grade report generation.
- Assumptions/dependencies: Reliable tool-use safety; latency budgeting; model robustness on multi-step math; organizational approval for semi-autonomous analysis.
- Regulatory benchmarks and disclosures for AI advice quality — Sectors: policy/regulation
- What: Use FinTradeBench-style tasks to set minimum performance standards for AI financial advice, require category-wise disclosure (F vs. T vs. FT) and RAG effects in consumer-facing tools.
- Tools/workflows: Supervisory testing sandboxes; public scorecards; certification programs.
- Assumptions/dependencies: Regulator buy-in (e.g., SEC/FINRA); standardized datasets; procedures for periodic revalidation and version control.
- Cross-domain dual-track RAG for text + time-series decision support — Sectors: healthcare, energy, supply chain, manufacturing
- What: Adapt the retrieval architecture to EHR notes + vitals (healthcare), grid reports + telemetry (energy), or logistics docs + sensor data (supply chain).
- Tools/products: Domain-specific “ideal RAG” with precomputed features (e.g., risk scores, anomaly flags); temporal retrieval controllers.
- Assumptions/dependencies: Data access and privacy compliance (HIPAA, etc.); validated domain signals; domain-expert calibration.
- Training and pretraining strategies for time-series reasoning — Sectors: AI research, finance
- What: Curate pretraining/finetuning corpora with structured time-series and indicator computation traces; augment with synthetic tasks for numerical fidelity.
- Tools/workflows: Instruction datasets mixing OHLCV + fundamentals; curricula that interleave retrieval, computation, and explanation; evaluation on hybrid tasks.
- Assumptions/dependencies: Licensing of market data; scalable data pipelines; evidence that pretraining shifts improve generalization without catastrophic forgetting.
- Context management and anti-distraction methods for RAG — Sectors: software, enterprise AI
- What: Develop context planners that extract only golden-indicator-relevant content, compress unrelated sections, and pre-check context for numerical density before generation.
- Tools/products: Golden-indicator extractors; signal-aware rerankers; learnable context budgets by question type; verifier loops that penalize off-indicator content.
- Assumptions/dependencies: Reliable indicator detection; integration with retrieval stack; effectiveness across diverse document styles.
- Benchmark-driven procurement and governance standards for enterprise AI — Sectors: finance, enterprise IT
- What: Institutionalize FinTradeBench-like evaluation as part of model procurement, change management, and model risk management (MRM) standards.
- Tools/workflows: Template controls for category-wise performance; challenge datasets; periodic attestations by vendors.
- Assumptions/dependencies: Internal policy alignment; third-party audit frameworks; continuous monitoring capabilities.
- Community leaderboards and shared tasks on hybrid financial reasoning — Sectors: academia, open-source
- What: Host competitions emphasizing hybrid reasoning, numerical audits, and judge calibration; spur innovations on tool-use, precomputation, and context planning.
- Tools/workflows: Public leaderboards; standardized judge prompts and MAE targets; prize challenges on trading-signal reasoning.
- Assumptions/dependencies: Dataset release at scale; reproducibility guidelines; legal clearance for broader data distribution.
- Human–LLM judge ecosystems for high-stakes numeric domains — Sectors: healthcare, public policy, engineering
- What: Extend the calibration-then-scaling evaluation pattern to clinical decision support, infrastructure risk, or macro-policy analysis where numeric fidelity is critical.
- Tools/workflows: Domain-specific auditors; human-aligned rubrics; MAE thresholds for deployment gating.
- Assumptions/dependencies: Availability of expert raters; standardized, auditable data sources; governance for judge model updates.
- Retail co-pilots that teach signal conflicts and market narratives — Sectors: consumer fintech, education
- What: Interactive tutors that simulate cases where fundamentals and prices diverge (e.g., sentiment-driven rallies), teaching users how to weigh signals.
- Tools/products: Scenario walkthroughs; narrative vs. fundamentals dashboards; “what changed?” modules across quarters.
- Assumptions/dependencies: Clear consumer protections; interpretability-first design; curated historical cases.
Notes on feasibility and dependencies (cross-cutting):
- Data availability: SEC filings are public; high-quality historical price data may require licenses; ensure strict time alignment to avoid hindsight leakage.
- Model choice: Latent-reasoning models perform better on hybrid tasks; instruction-tuned models may degrade with RAG unless context is curated.
- Risk and compliance: Financial outputs should be treated as decision support, not advice; maintain audit trails and human oversight.
- Evaluation integrity: LLM-as-judge requires periodic recalibration to human raters; track MAE and drift over time.
- Generalization: Benchmark focuses on NASDAQ‑100 (2015–2025); performance may differ for small caps, other markets, or different regimes.
Glossary
- Automated numerical audit: An automated process to verify numerical claims in generated answers against a structured financial knowledge base. "Automated numerical audit."
- Best-of- sampling: A generation strategy that samples multiple candidates and selects the best according to a criterion. "paralleling best-of- sampling"
- BM25 lexical matching: A classic information retrieval algorithm that ranks documents based on term frequency and document length. "BM25 lexical matching"
- Book / Price (Quarterly): A valuation ratio comparing book value of equity to market capitalization. "Book / Price (Quarterly)"
- Calibration-then-scaling framework: A benchmark construction approach that calibrates with expert supervision and then scales using automated methods. "calibration-then-scaling framework"
- Cross-encoder re-ranking: A re-ranking method where a cross-encoder scores retrieved candidates for improved relevance. "cross-encoder re-ranking (ms-marco-MiniLM-L-6-v2)"
- Cross-signal reasoning: Reasoning that integrates multiple types of signals (e.g., fundamentals and trading signals) within a single question. "hybrid questions requiring cross-signal reasoning"
- Debt / Assets (Quarterly): A leverage ratio measuring total debt relative to total assets. "Debt / Assets (Quarterly)"
- Dense embeddings: Vector representations used for semantic retrieval in dense information retrieval systems. "dense embeddings (BAAI/bge-large-en-v1.5)"
- Drawdowns: Measures of peak-to-trough declines used to assess downside risk. "including moving averages, momentum, realized volatility, drawdowns, and volume measures"
- Dual-Track Retrieval Engine: A retrieval design that separately handles unstructured financial text and structured time-series data. "Dual-Track Retrieval Engine."
- EDGAR: The SEC’s public database for corporate filings. "indexed by EDGAR"
- Earnings / Price (Quarterly): The inverse of the P/E ratio, using quarterly earnings per share over price per share. "Earnings / Price (Quarterly)"
- Earnings per share (EPS): A company’s profit allocated to each outstanding share of common stock. "Earnings per share~(EPS)"
- EMA (Exp. Moving Average): An average that applies exponentially decreasing weights to past prices, emphasizing recent data. "EMA (Exp. Moving Average)"
- Golden Indicator F1: An F1 metric measuring precision and recall over expert-defined key indicators in responses. "Golden Indicator F1"
- Golden indicators: The specific, expert-defined financial metrics required for a correct answer. "a set of golden indicators"
- Hierarchical Indexing: A document indexing strategy that preserves parent-child structure for coherent retrieval. "Hierarchical Indexing"
- Human-LLM-judge-alignment: The degree of agreement between human evaluators and an LLM judge on evaluation criteria. "Human-LLM-judge-alignment"
- Integration Score: A metric assessing how well models synthesize textual and tabular signals. "Integration Score"
- Intra-model self-filtering: A process where a model evaluates and selects its own best response among its candidates. "Intra-model self-filtering."
- Likert scale: A psychometric scale commonly used for evaluations, here with five levels. "5-point Likert scale"
- MA (Moving Average): The average stock price over a fixed lookback window to smooth fluctuations. "MA (Moving Average)"
- MACD: A momentum indicator based on the difference between short- and long-term EMAs. "MACD"
- Mean absolute error (MAE): An error metric averaging absolute differences between predicted and true values. "mean absolute error (MAE)"
- Medium-Term Momentum: A measure of price persistence over several weeks or months. "Medium-Term Momentum"
- Metadata Injection: Adding structured fields (e.g., ticker, fiscal year) to embeddings or chunks to improve retrieval. "Metadata Injection"
- OBV (On-Balance Volume): A cumulative volume-based indicator linking price direction with trading volume. "OBV (On-Balance Volume)"
- OHLCV (Open, High, Low, Close, and Volume): Standard fields in market data used to compute trading signals. "OHLCV (Open, High, Low, Close, and Volume)"
- One-Day Reversal: The daily return from previous close to current close indicating short-term reversals. "One-Day Reversal"
- Paired t-test: A statistical test used here to assess the significance of performance differences across conditions. "paired -test"
- Parent--child chunking: A chunking approach that retrieves smaller child chunks but returns larger parent contexts for coherence. "parent--child chunking"
- Realized volatility: A volatility measure computed from historical price movements. "realized volatility"
- Relative Retrieval Delta (): The relative performance change when using RAG compared to No-RAG. "Relative Retrieval Delta ()"
- RAG architecture: A Retrieval-Augmented Generation setup that integrates retrieved evidence into LLM prompting. "Overview of the RAG architecture."
- Regime changes: Shifts in underlying market behavior or risk states captured by volatility models. "regime changes"
- RSI (Relative Strength Index): A bounded momentum oscillator indicating overbought or oversold conditions. "RSI (Relative Strength Index)"
- Self-preference biases: The tendency of models to favor their own outputs during evaluation. "self-preference biases"
- Self-selection module: A component that chooses the best response among multiple candidates for evaluation. "A self-selection module"
- TELeR taxonomy: A structured hierarchy of prompt types used to elicit different levels of reasoning. "TELeR taxonomy"
- Temporal query mechanism: A retrieval method that aligns queries and evidence by time to handle time-series data. "auxiliary temporal query mechanism"
- Tick-level trading data: High-frequency data capturing every transaction (“tick”) in the market. "tick-level trading data"
- Time-series market data: Sequential numerical data (e.g., prices, volumes) used to compute trading signals. "time-series market data"
- Volatility measures: Metrics that quantify the variability of asset returns and perceived market risk. "Volatility measures are also used to capture perceived market risk and regime changes"
Collections
Sign up for free to add this paper to one or more collections.