BERT-as-a-Judge: A Robust Alternative to Lexical Methods for Efficient Reference-Based LLM Evaluation
Abstract: Accurate evaluation is central to the LLM ecosystem, guiding model selection and downstream adoption across diverse use cases. In practice, however, evaluating generative outputs typically relies on rigid lexical methods to extract and assess answers, which can conflate a model's true problem-solving ability with its compliance with predefined formatting guidelines. While recent LLM-as-a-Judge approaches mitigate this issue by assessing semantic correctness rather than strict structural conformity, they also introduce substantial computational overhead, making evaluation costly. In this work, we first systematically investigate the limitations of lexical evaluation through a large-scale empirical study spanning 36 models and 15 downstream tasks, demonstrating that such methods correlate poorly with human judgments. To address this limitation, we introduce BERT-as-a-Judge, an encoder-driven approach for assessing answer correctness in reference-based generative settings, robust to variations in output phrasing, and requiring only lightweight training on synthetically annotated question-candidate-reference triplets. We show that it consistently outperforms the lexical baseline while matching the performance of much larger LLM judges, providing a compelling tradeoff between the two and enabling reliable, scalable evaluation. Finally, through extensive experimentation, we provide detailed insights into BERT-as-a-Judge's performance to offer practical guidance for practitioners, and release all project artifacts to foster downstream adoption.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
Imagine you’re grading a huge stack of tests from many different students. Some students follow the exact format you asked for (“Final answer: 42”), and some don’t (“I think the result is forty-two”). If you only accept the exact format, you might mark good answers wrong just because of how they’re written. This paper is about fixing that problem for AI models.
The authors introduce “BERT-as-a-Judge,” a fast, smaller AI that checks whether a model’s answer is actually correct—even if it’s phrased differently—by comparing it to the correct answer. It aims to be as accurate as bigger, slower “judge” AIs, but much cheaper and quicker to run.
What questions did the researchers ask?
- Can we evaluate AI answers based on their meaning, not just their exact wording or formatting?
- Are common “strict” methods (like regex rules) unfairly lowering scores by punishing formatting mistakes?
- Can a smaller, efficient model (based on BERT) judge answers as accurately as big, expensive judge AIs?
- Will this approach work across many tasks and many different AI models?
How did they study it? (Methods in simple terms)
Think of three pieces of text for each question:
- The question (what was asked),
- The candidate answer (what the AI wrote),
- The reference answer (the correct answer or solution).
The authors:
- Collected a large set of these triples from many tasks that have clear right/wrong answers:
- Multiple-choice (e.g., MMLU, ARC)
- Reading-with-evidence (context extraction, e.g., SQuAD, HotpotQA)
- Open-form math (e.g., GSM8K, MATH)
- Labeled correctness automatically:
- They used a strong AI (Nemotron-Super-v1.5) to label whether each candidate answer matches the reference.
- Then they checked a subset with 11 human annotators and found high agreement (about 97.5%), showing the automatic labels were reliable.
- Trained a fast “encoder” model to judge answers:
- An encoder (like BERT) is a “read-and-understand” model: it takes in text and decides something about it—in this case, “Is this answer correct?”
- They fine-tuned a BERT-like model (EuroBERT ~210M parameters) on about 1 million labeled examples to output True/False for correctness.
- This is much faster than asking a big generative model to “think” and write a judgment for every answer.
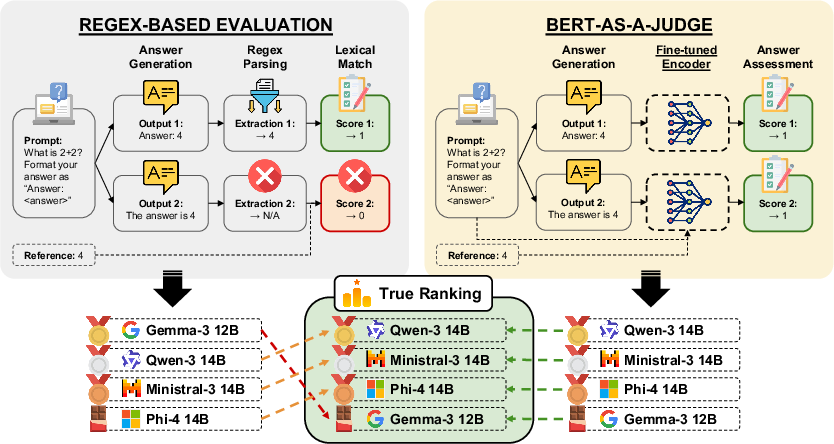
- Compared three evaluation styles:
- Regex-based (strict formatting + exact/lexical matching),
- LLM-as-a-Judge (a big AI writes a verdict),
- BERT-as-a-Judge (their smaller, fast classifier).
They measured how often each method agreed with the “ground-truth” labels and checked results across 36 different AI models and 15 tasks.
Key terms in everyday language:
- Regex: Think of it like a very picky form-checker—it only “sees” the answer if it matches a strict pattern (e.g., “Final answer: [text]”). If the student writes anything extra, it might fail.
- LLM-as-a-Judge: Like asking a professor to read and grade each answer—usually accurate, but slow and expensive.
- Encoder/BERT: Like a skilled, fast scanner that reads both the student’s answer and the answer key and quickly says “correct” or “incorrect” without writing an essay.
What did they find?
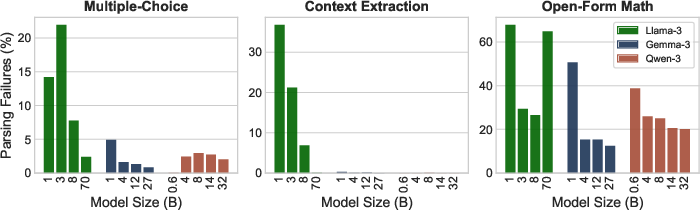
- Strict, format-based grading (regex) often misjudges answers:
- Many models don’t always follow exact formatting, especially on harder, open-form math tasks. When that happens, regex can’t even find the answer to grade.
- Even when answers are parsed, lexical checks can miss meaning (e.g., “two dollars” vs “$2.00” or small wording differences).
- This leads to unfairly lower scores and can shuffle leaderboards in surprising ways (some models drop many ranking spots for formatting—not ability).
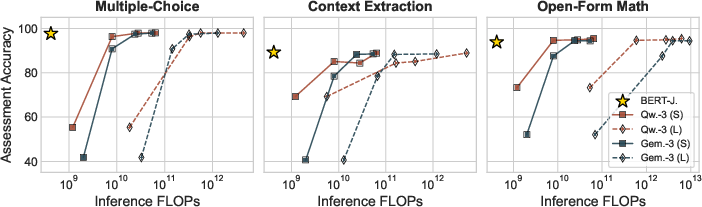
- BERT-as-a-Judge matches human-like judgments and beats regex by a lot:
- On multiple-choice datasets, it was near perfect (often 98–99% accuracy against the ground-truth labels).
- On open-form math and reading-with-evidence tasks, it remained very strong (often around 90–99%, depending on the task).
- It runs fast (about 200 ms per example on a CPU) and is far cheaper than using large “judge” AIs.
- It generalizes well:
- It worked on tasks it wasn’t trained on.
- It worked on answers from models it hadn’t seen during training.
- It stayed accurate even when the answer format changed (e.g., free-form vs. strictly formatted).
- It doesn’t need tons of training data:
- Even with 100,000 examples (much less than 1 million), results were already very good—especially for multiple-choice and math.
- Flexible and practical extras:
- Hybrid option: Use regex first and only fall back to BERT-as-a-Judge when parsing fails—this improves accuracy versus regex alone while saving compute.
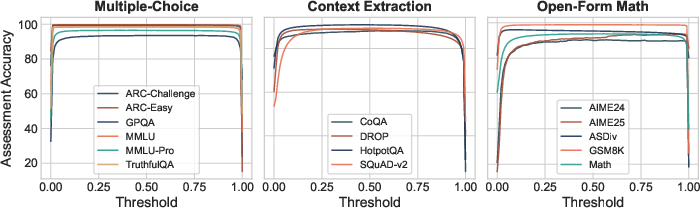
- Robust thresholds: Its “True/False” score doesn’t need careful fine-tuning. The default threshold works well.
- Including the question helps most on reading tasks, but the method still works decently without it (useful for shorter inputs or different modalities).
- Small LLM judges underperform:
- Using a small generative AI as a judge (under ~1B parameters) did worse than both regex and BERT-as-a-Judge. Bigger LLM judges can do better, but they cost much more to run. BERT-as-a-Judge gets close to the best judges at a fraction of the cost.
Why is this important?
When we compare AI models, we want to know which ones actually understand and solve problems—not just which ones follow formatting instructions. If the grading method punishes good answers for minor wording quirks, we get the wrong picture. This research shows a better way to evaluate:
- Fairer: Scores reflect true correctness, not formatting trivia.
- Faster and cheaper: Makes large-scale evaluation more accessible and less wasteful.
- More reliable leaderboards: Developers and users can trust comparisons across many tasks and models.
Limitations and what’s next
- Current focus: English tasks with clear right/wrong answers.
- Not yet aimed at open-ended writing like summaries or stories, or at multilingual or multimodal tasks (like images or audio).
Future directions:
- Adapting the approach to open-ended tasks (e.g., summarization, translation, code).
- Extending to more languages and to multimodal settings (e.g., visual question answering).
- Moving toward a unified, efficient evaluation for many kinds of AI outputs.
In short
BERT-as-a-Judge is like a fair, fast referee that checks whether an AI’s answer is truly correct—even if it’s written differently. It avoids the strictness of format-based grading and the cost of big judge AIs, giving a reliable, scalable way to measure what really matters: problem-solving ability.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable follow-up research.
- Dependence on a single synthetic labeler: Training and evaluation rely primarily on Nemotron‑Super‑v1.5 labels, with only a small human audit. How do labeler biases and errors propagate into the encoder, and how robust is performance to alternative labelers or mixtures of human and synthetic labels?
- Limited human validation: The human study (3,212 annotations) is small relative to the 1M training samples and not clearly stratified by task. What are per-task, per-model, and per-category human agreement rates, and how do model rankings correlate with human judgments at scale (e.g., Spearman/Kendall on leaderboards)?
- Binary correctness only: The method outputs True/False judgments. How to extend to graded or rubric-based scoring (e.g., partial credit, semantic similarity scales) and measure calibration to human rubrics?
- Single-reference assumptions: The approach assumes a single reference answer. How to handle multiple valid references, paraphrase clusters, or equivalence classes, and what aggregation strategy (max/any-of/learned) best aligns with human judgments?
- Missing source context for grounded tasks: For context extraction benchmarks, the judge uses question–candidate–reference only, not the passage. Can the method verify grounding (evidence use, citation correctness) when the source context is included, and how much does that change decisions?
- Long-context constraints: The encoder (EuroBERT 210M) likely has a short input limit. How does truncation or sliding-window handling affect accuracy on long candidate answers or contexts, and would long-context encoders (e.g., Longformer, ModernBERT-Long) improve robustness?
- Generalization beyond English/objective tasks: Experiments are confined to English and tasks with objectively verifiable answers. How well does the approach transfer to multilingual settings, domain-specific jargon (e.g., biomedical, legal), and code/text in other scripts?
- Open-ended generation not assessed: The method is untested on summarization, MT, dialog quality, instruction following, and other non-reference or multi-dimensional quality settings. What adaptations (e.g., entailment-based judging, pairwise preferences) are needed?
- Adversarial robustness: No evaluation against adversarially crafted candidates designed to fool the encoder (e.g., misleading negations, prompt-injection-like content, distractors). What are failure modes and defenses (adversarial training, consistency checks)?
- Sensitivity to training mixture: The composition is “balanced” but not ablated. How do task weights, model-family diversity, and data heterogeneity affect generalization? Is there a data-efficient curriculum or active sampling strategy that improves robustness?
- Missing comparisons to learned metrics: The paper does not compare against established neural evaluators (BLEURT, COMET, MetricX, InfoLM, BERTScore variants). How does BERT‑as‑a‑Judge fare against these baselines in both accuracy and compute cost?
- LLM‑as‑a‑Judge baseline scope: Comparisons focus on small-to-mid open LLMs and limited prompting. How does the encoder compare to strong, best-practice LLM judges (e.g., larger models with self-consistency, debate, or tool use) under equalized cost-quality trade-offs?
- Handling chain-of-thought (CoT): The impact of verbose, step-by-step candidate reasoning on the judge is not analyzed. Does training with CoT-rich candidates improve robustness, and how does CoT length interact with encoder context limits?
- Numerical equivalence nuances: Beyond high-level accuracy, there is no fine-grained analysis of numeric equivalence (units, rounding, scientific notation, intervals). Where does the encoder fail on mathematically equivalent forms, and can numeric canonicalization help?
- Probability calibration and abstention: Although threshold robustness is shown, calibration quality (e.g., ECE, Brier) and selective abstention strategies are untested. Can calibrated uncertainty drive triage (e.g., defer low-confidence cases to stronger judges or humans)?
- Multi-reference aggregation at scale: Practical strategies for integrating many references (e.g., MT multiple references, QA variants) are not explored. What batching or learned aggregation is most effective and compute-efficient?
- Vulnerability to gaming: If generators are optimized against this judge, can they exploit learned heuristics? Study red-teaming and adversarial co-training to harden against exploitation.
- Architectural and compression ablations: Only EuroBERT 210M is used. What is the performance/latency frontier across encoder families (DeBERTa-v3, ModernBERT, MiniLM), sizes, quantization, and distillation for edge deployment?
- Benchmark leakage and overfitting: Training uses the training splits of the same benchmarks evaluated on their test splits. Does the judge learn dataset-specific heuristics? Evaluate on entirely novel datasets outside the three task families.
- Real-world throughput and systems aspects: Beyond per-sample latency, end-to-end throughput, memory footprint, and batching on CPUs/GPUs are not reported. What are engineering best practices for large-scale leaderboard evaluation?
- Fairness and bias: No analysis of whether the judge’s decisions vary across demographic content, dialects, or sensitive topics. Design targeted audits and mitigation strategies.
- Prompt/format sensitivity: Triplet formatting details are limited. How sensitive is performance to prompt templates, tokenization schemes, and instruction wording used to present question, candidate, and reference?
- Evidence and citation compliance: For tasks requiring cited evidence, how to evaluate both correctness and the quality/faithfulness of citations (e.g., hallucinated or irrelevant spans), potentially with context-aware NLI?
- Multimodal extension: The path to judging answers grounded in images, audio, or video is outlined but not instantiated. What architectures and datasets enable reliable multimodal judging with similar efficiency?
Practical Applications
Immediate Applications
Below are actionable, deployable-now uses of BERT-as-a-Judge and the paper’s hybrid workflows, grounded in the paper’s findings on accuracy, robustness to formatting, training efficiency (≥100k samples), and low inference cost (~200 ms/sample on CPU).
- Sector: Software (LLM evaluation/MLOps)
- Use case: Replace regex-based metrics in LLM evaluation pipelines for reference-based tasks (e.g., QA, multiple choice, math answers) to reduce misranking and underestimation caused by parsing/matching errors.
- Tools/products/workflows:
- Integrate the released checkpoints into evaluation harnesses (e.g., lm-eval-harness, HELM) as a “semantic correctness” metric.
- Deploy as a lightweight “Judge API” microservice for CI/CD to gate model/prompt changes with pass/fail thresholds.
- Adopt the hybrid strategy: use regex first and fall back to BERT-as-a-Judge on parsing failures to cut compute while recovering accuracy.
- Assumptions/dependencies: Requires reference answers and English task framing; best suited to tasks with objectively verifiable correctness; threshold set to default 0.5 (paper shows robustness).
- Sector: Software/Agentic systems
- Use case: Step verification in agent workflows where intermediate subgoals have canonical or checkable answers (e.g., data extraction steps, math sub-results).
- Tools/products/workflows:
- Insert BERT-as-a-Judge checkpoints between agent steps to auto-accept/retry steps based on correctness probability.
- Assumptions/dependencies: Subgoals must be specifiable as question–candidate–reference triplets.
- Sector: Education (EdTech, LMS)
- Use case: Automated grading of short-answer and math questions with tolerance to phrasing/formatting differences.
- Tools/products/workflows:
- LMS plugin that consumes question, student answer, and answer key; emits binary correctness with confidence.
- Local/offline grading for exams and practice sets on low-cost CPUs.
- Assumptions/dependencies: Requires clear answer keys; best for English content and objective questions; human spot checks recommended in high-stakes contexts.
- Sector: Customer support/Knowledge management
- Use case: QA bot validation against a knowledge base for FAQs where a canonical answer exists.
- Tools/products/workflows:
- Deploy BERT-as-a-Judge to continuously evaluate bot responses against reference answer snippets and flag deviations for retraining/prompts.
- Assumptions/dependencies: Availability of reference answers or canonical KB snippets; domain drift requires periodic re-validation.
- Sector: Finance (Compliance and contact centers)
- Use case: Check whether responses include required disclosures or match policy-mandated answers to standardized questions.
- Tools/products/workflows:
- Call/chat QA: transform compliance checkpoints into question–reference pairs and score agent or bot outputs in batch.
- Dashboard with pass/fail and confidence for supervisors.
- Assumptions/dependencies: Policy text must be converted into concrete reference answers; binary correctness framing must be defensible for audits.
- Sector: Healthcare (Clinical QA and data labeling)
- Use case: Evaluate extraction tasks (e.g., diagnosis codes, medication names) against annotated references; validate clinical FAQ bots against canonical guidance.
- Tools/products/workflows:
- Local evaluation for privacy-sensitive settings using CPU-only inference.
- Data pipeline filter: auto-flag mismatches for curator review.
- Assumptions/dependencies: Must operate only on de-identified or authorized data; reference labels must be available; remains English-focused.
- Sector: Research/Academia
- Use case: Fairer benchmarking of instruction-tuned models without conflating capability with formatting compliance; robust cross-model comparisons.
- Tools/products/workflows:
- Swap regex metrics for the released encoder in leaderboards; report both hybrid and encoder-only scores.
- Data curation: auto-label model generations as correct/incorrect for error analysis and training set construction.
- Assumptions/dependencies: Benchmarks should have unambiguous references; avoid leakage between training/eval splits for fairness.
- Sector: Product management/A-B testing
- Use case: Rapid, low-cost A/B testing of prompts or models on reference-based tasks without spinning up expensive LLM judges.
- Tools/products/workflows:
- Batch-score logs with the encoder; trigger promotion thresholds based on accuracy deltas and confidence distributions.
- Assumptions/dependencies: Reference answers defined per test set; monitoring for domain/topic drift.
- Sector: Public sector/Policy
- Use case: Compute-efficient audits of AI systems on standardized, reference-based evaluations for procurement or compliance checks.
- Tools/products/workflows:
- Distribute an offline evaluation kit with the released checkpoint and fixed datasets to enable reproducible third-party audits.
- Assumptions/dependencies: Audits restricted to English and objective tasks; agencies must agree on reference sets and pass criteria.
- Sector: Daily life/Personal learning
- Use case: Local study assistant that checks practice answers against keys (math, factual QA) without an internet connection.
- Tools/products/workflows:
- Desktop/mobile app embedding the encoder for on-device grading with immediate feedback.
- Assumptions/dependencies: Requires curated answer keys; best for concise, objective questions.
Long-Term Applications
The following opportunities build on extensions discussed in the paper (multilingual, multimodal, open-ended generation) and require further research, domain data, or engineering.
- Sector: Multilingual education, global support, international governance
- Use case: Multilingual “BERT-as-a-Judge” variants to evaluate correctness across languages for grading, QA bots, and regulatory audits.
- Tools/products/workflows:
- Train/jointly fine-tune multilingual encoders on synthetic labels across languages; release language-specific checkpoints.
- Assumptions/dependencies: High-quality multilingual references and labels; careful evaluation of cultural/linguistic nuances.
- Sector: Multimodal AI (Healthcare imaging, Retail, Autonomous systems)
- Use case: Encoder-based judges for VQA, image captioning, and speech QA where outputs are compared to references.
- Tools/products/workflows:
- Extend to vision/text and speech/text encoders; integrate with multimodal benchmarks (e.g., VQA with canonical answers).
- Assumptions/dependencies: Multimodal encoders and datasets; coherent reference formulations for multimodal tasks.
- Sector: Content generation (Media, Enterprise documentation)
- Use case: Learned evaluators for open-ended tasks (summarization, translation, policy drafting) as faster, cheaper alternatives to LLM-as-a-Judge.
- Tools/products/workflows:
- Train task-specific encoder judges (e.g., Summarize-as-a-Judge, Translate-as-a-Judge) using human or high-quality synthetic labels.
- Use as part of editorial QA pipelines for style/coverage criteria aligned to references.
- Assumptions/dependencies: Requires reliable gold/reference signals or high-quality human ratings; evaluation criteria are less binary and need rubric design.
- Sector: Reinforcement learning/fine-tuning (RLHF/DPO/RLAIF)
- Use case: Encoder-based reward proxies for tasks with referenceable outcomes, reducing reliance on large judge models during training.
- Tools/products/workflows:
- Plug encoder scores into reward models or as acceptance filters for preference datasets; use in bandit/offline RL loops.
- Assumptions/dependencies: Only applicable where correctness is referenceable; avoid reward hacking by diversifying references and periodic human audits.
- Sector: Domain-specialized evaluation (Legal, Medical, Finance)
- Use case: Fine-tune “Legal-/Med-/Fin-BERT-as-a-Judge” on domain corpora to evaluate adherence to domain standards and canonical answers.
- Tools/products/workflows:
- Construct domain triplets (question, candidate, reference) with expert curation or careful synthetic labeling; deploy in regulated pipelines.
- Assumptions/dependencies: Expert-approved references; rigorous validation against human judgments; monitoring for liability in high-stakes scenarios.
- Sector: Code and software engineering
- Use case: Textual evaluators for code tasks without executable tests (e.g., short algorithm answers, docstring-to-solution equivalence).
- Tools/products/workflows:
- Train a code-aware encoder (e.g., CodeBERT-as-a-Judge) to assess equivalence against reference snippets or expected outputs.
- Assumptions/dependencies: Ground-truth references of sufficient quality; for safety-critical code, execution-based tests remain preferred.
- Sector: Benchmarking standards and governance
- Use case: Standardized, compute-efficient evaluation suites adopted by consortia and regulators to reduce environmental impact and increase reproducibility.
- Tools/products/workflows:
- Publish certified judge checkpoints, frozen datasets, and protocols; define pass/fail thresholds per task and sector.
- Assumptions/dependencies: Community buy-in; periodic updates to prevent overfitting; clear separation of training/evaluation artifacts.
- Sector: Privacy-preserving/edge evaluation
- Use case: On-device evaluators for sensitive sectors (health, finance, defense) to validate AI outputs without sending data to cloud services.
- Tools/products/workflows:
- Optimize encoders for mobile/edge (quantization, distillation); bundle in SDKs for OEMs and enterprise devices.
- Assumptions/dependencies: Availability of device-class accelerators; careful latency/accuracy trade-offs; secure model distribution.
- Sector: Data creation and curation at scale
- Use case: Semi-automatic construction of large verified datasets by filtering/generated outputs against references at web scale.
- Tools/products/workflows:
- Use judge scores to accept/reject synthetic items during data augmentation and self-instruct pipelines.
- Assumptions/dependencies: Reference quality; safeguards against propagating synthetic label biases; scheduled human audits.
Notes on Feasibility and Dependencies (cross-cutting)
- Core dependencies:
- Reference-based, objectively correct tasks; English language coverage in current checkpoints.
- Access to the released code/models (GitHub/Hugging Face) and ability to run CPU/GPU inference.
- Key assumptions:
- Synthetic labels used for training correlate strongly with human judgments (paper reports ~97.5% agreement on a subset).
- Distribution shifts (domain, format, language) may require light domain adaptation; paper shows training efficiency even at 100k samples.
- Risks/mitigations:
- Not a substitute for human evaluation in subjective or high-stakes open-ended tasks; use hybrid workflows with human-in-the-loop.
- Avoid training/eval leakage when reporting benchmarks; maintain held-out splits and audit training data sources.
Glossary
- alignment strategies: Techniques used to align model behavior with desired objectives or instructions via data or training procedures. "Such deviations may stem from differences in model scale, instruction-tuning data mixtures, or alignment strategies, and can artificially deflate measured downstream performance."
- BERT-as-a-Judge: An encoder-based evaluation approach that judges correctness of model outputs against references. "To address this limitation, we introduce BERT-as-a-Judge, an encoder-driven approach for assessing answer correctness in reference-based generative settings"
- BERTScore: A neural similarity metric that uses contextual embeddings to compare texts. "and then rely on metrics beyond exact match, such as ROUGE, BERTScore, or Math-Verify"
- bidirectional attention: Attention mechanism that processes context in both left-to-right and right-to-left directions for improved understanding. "leveraging its bidirectional attention mechanism well suited for structured text classification"
- binary cross-entropy: A loss function for binary classification measuring divergence between predicted probabilities and true labels. "fine-tune it for one epoch using binary cross-entropy."
- BLEURT: A learned evaluation metric for text generation quality, trained to correlate with human judgments. "as well as task-specific evaluators like COMET \citep{comet,cometkiwi,xcomet}, MetricX \citep{metricx23,metricx25}, and BLEURT \citep{bleurt}."
- Borda count: A rank aggregation method that assigns points based on positions to produce a combined ranking. "Bottom: model rankings for four similarly sized models from different families, computed via task-wise Borda count."
- chain-of-thought: Intermediate reasoning tokens generated before a final answer or judgment to improve reasoning quality. "
L'' (long'') allows the generation of intermediate chain-of-thought tokens before the final judgment." - Code-Eval: An automated metric for program synthesis tasks that runs code to evaluate correctness. "or Code-Eval \citep{codeval}, making evaluation highly sensitive to surface-level formatting."
- COMET: A neural metric for machine translation quality that estimates adequacy relative to references. "task-specific evaluators like COMET \citep{comet,cometkiwi,xcomet}, MetricX \citep{metricx23,metricx25}, and BLEURT \citep{bleurt}."
- decision threshold: The probability cutoff used to convert a continuous score into a binary decision. "Encoder classifiers output continuous sigmoid probabilities, requiring a decision threshold for discrete evaluation."
- greedy decoding: A generation strategy that selects the most probable token at each step without exploration. "Inference is conducted using greedy decoding in non-reasoning mode."
- InfoLM: A family of information-theoretic metrics for measuring semantic similarity between texts. "motivating neural metrics such as BERTScore \citep{bertscore} and InfoLM \citep{infolm} for general text generation"
- inference FLOPs: A measure of computational cost for model inference, roughly proportional to parameters times tokens. "Inference FLOPs are estimated using the formula from \citet{kaplan2020scaling}: FLOPs = 2 model size (in parameters) number of generated tokens."
- instruction-tuned models: Models fine-tuned to follow natural language instructions and interact with users. "For instruction-tuned models (optimized for human interaction and question answering), evaluation is typically conducted in zero-shot generative settings"
- LLM-as-a-Judge: An evaluation paradigm where a LLM judges the correctness or quality of another model’s output. "Recently, LLM-as-a-Judge frameworks have emerged as a compelling alternative"
- linear decay schedule: A learning rate schedule that decreases linearly over training steps. "along with a 5\% warmup ratio and a linear decay schedule."
- log-likelihood: The probability of observed data under a model, often used to evaluate LLMs. "Pretrained LLMs have traditionally been evaluated using log-likelihood"
- MetricX: A neural metric for machine translation evaluation providing reference-based quality estimates. "task-specific evaluators like COMET \citep{comet,cometkiwi,xcomet}, MetricX \citep{metricx23,metricx25}, and BLEURT \citep{bleurt}."
- out-of-domain (OOD): Data or models not seen during training, used to test generalization. "Assessment accuracy on out-of-domain models."
- reference-based generative settings: Evaluation setups where generated outputs are compared against given reference answers. "an encoder-driven approach for assessing answer correctness in reference-based generative settings"
- regex-based evaluation: Assessing outputs using regular expressions to parse and compare answers in fixed formats. "This section analyzes the impact of regex-based evaluation on measured downstream performance"
- ROUGE-L: An automatic evaluation metric based on longest common subsequence overlap between texts. "and evaluates multiple-choice tasks with exact match, context extraction with ROUGE-L, and open-form math with Math-Verify."
- semantic correctness: Whether an output is meaningfully equivalent to a reference, regardless of surface form. "assessing semantic correctness rather than strict structural conformity"
- sigmoid probabilities: Output scores from a sigmoid activation representing probabilities for binary classification. "Encoder classifiers output continuous sigmoid probabilities"
- synthetic labeling: Creating labels automatically using a model or rules instead of human annotators. "To validate the reliability of the synthetic labeling approach, we perform human annotation on a subset of the data."
- warmup ratio: The fraction of initial training steps during which the learning rate increases from zero to its peak. "along with a 5\% warmup ratio and a linear decay schedule."
- zero-shot: Performing a task without task-specific examples or fine-tuning, relying only on general capabilities. "evaluation is typically conducted in zero-shot generative settings"
Collections
Sign up for free to add this paper to one or more collections.

