- The paper proposes a novel benchmark that leverages the distributional hypothesis to assess LLM outputs without human judgment.
- It employs character-level n-gram statistics focusing on fluency, truthfulness, and helpfulness, achieving a 0.9896 correlation with GPT-4o evaluations.
- The approach offers a scalable and resource-efficient alternative validated against existing LLM benchmarks, particularly for Japanese language models.
A Judge-free LLM Open-ended Generation Benchmark Based on the Distributional Hypothesis
Introduction
The paper presents a novel approach to evaluating LLMs for open-ended text generation using a benchmark grounded in the distributional hypothesis. The motivation stems from the high cost and variability associated with human or LLM-as-a-judge evaluations, which the proposed benchmark aims to alleviate by employing deterministic n-gram statistics. This benchmark is designed to assess LLMs across three metrics: Fluency, Truthfulness, and Helpfulness. Importantly, the benchmark strongly correlates with GPT-4o-based evaluations while being significantly more resource-efficient.
Methodology
Benchmark Design
The benchmark is built around 50 carefully curated questions spanning multiple disciplines, such as language, social studies, and sciences. Each question is paired with reference answer sets constructed using state-of-the-art Japanese-specific LLMs. The evaluation framework is structured to yield scalable and reliable performance metrics based on the n-gram distribution, without relying on subjective judgment.
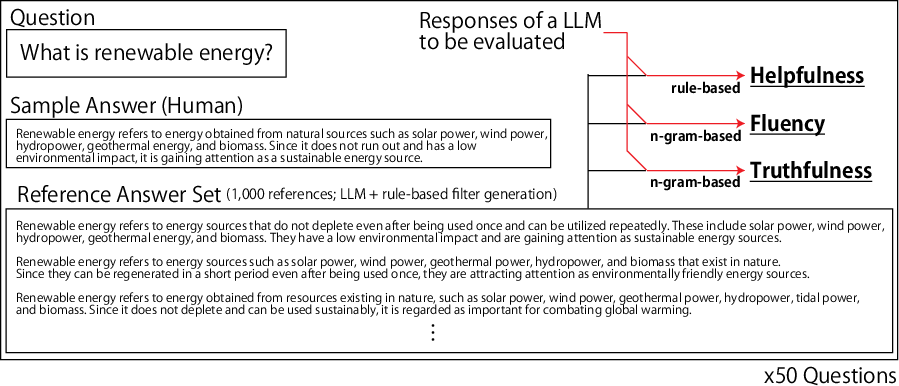
Figure 1: Evaluation outline illustrating the workflow of generating and evaluating responses using the benchmark framework.
Evaluation Metrics
- Fluency is measured through the inner product of 10-gram occurrence ratios against a reference set, ensuring that generated text aligns closely with expected language patterns.
- Truthfulness assesses the prevalence of reliable factual information in responses, ensuring that low-frequency hallucinations are minimized.
- Helpfulness evaluates the informational completeness of responses based on predefined key phrases for each question.
Results
The study confirms the benchmark's robustness by comparing its scores against an LLM-as-a-judge system (GPT-4o), where it achieves a high correlation coefficient of 0.9896, demonstrating comparable reliability with significantly reduced computational overhead.
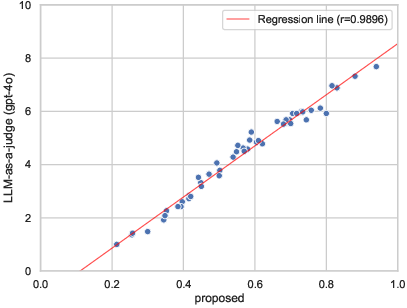
Figure 2: Comparison between our benchmark and GPT-4o's LLM-as-a-judge evaluation method.
Further analyses against existing benchmarks such as Nejumi LLM Leaderboard 3 and Japanese MT-Bench reveal correlations above 0.7, underscoring the method's comprehensive assessment across various LLM features.
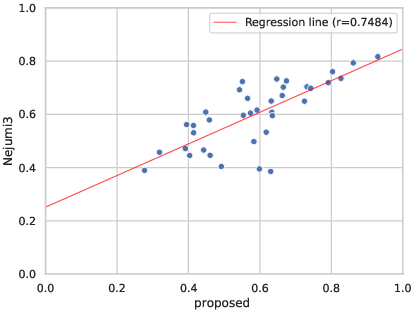
Figure 3: Comparison between our benchmark and Nejumi LLM Leaderboard 3 shows strong alignment in performance evaluations.
Discussion
The paper posits that the adoption of character-level n-grams, tailored to the Japanese language's unique attributes, provides a stable and scalable evaluation mechanism for open-ended text generation tasks. This approach is a significant shift from LLM-as-a-judge models, offering a cost-effective alternative that maintains high fidelity to established performance metrics.
Conclusion
By leveraging the distributional hypothesis, this judge-free benchmark offers a viable, resource-efficient method to assess LLM capabilities for open-ended tasks. Its strong correlations with existing high-cost evaluation methods affirm its validity and potential as a new standard in the field of LLM evaluation, particularly for applications with resource constraints or when trained on specific LLMs.
The full implementation details and materials are accessible on GitHub, allowing for community engagement and further development of this approach.