- The paper presents JudgeBoard, which reframes reasoning evaluation by directly assessing answer correctness using an Elo-based model-as-judge protocol.
- It introduces Multi-Agent Judging (MAJ), where SLMs with diverse reasoning profiles collaborate and debate, boosting evaluative accuracy by up to 2%.
- Empirical findings indicate that profiled, collaborative SLM ensembles can rival larger LLMs, challenging the dominance of scale in model selection.
JudgeBoard: Direct Evaluation and Enhancement of SLM Judging in Reasoning Tasks
Introduction and Motivation
The evaluation of reasoning outputs produced by LLMs traditionally relies on comparison-based judging: models assess candidate answers through entailment metrics or direct reference to ground-truth labels. While effective for broad performance analysis, this approach limits direct assessment of a model's intrinsic ability to judge correctness, particularly for Small LLMs (SLMs) where label efficiency and automation are critical requirements. "JudgeBoard: Benchmarking and Enhancing Small LLMs for Reasoning Evaluation" (2511.15958) proposes a new framework—JudgeBoard—which formulates the judging task as direct answer correctness evaluation. This pipeline facilitates both the comparison and enhancement of SLMs in terms of evaluative reliability, granularity, and scalability.
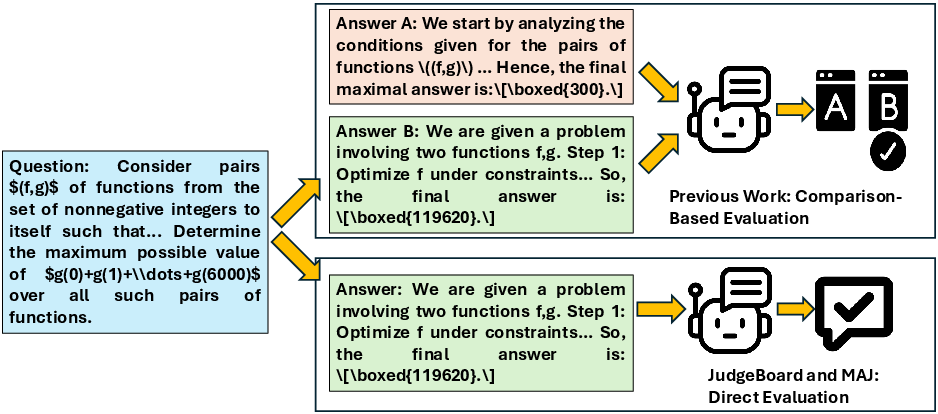
Figure 1: Comparison of JudgeBoard and MAJ with previous works; JudgeBoard/MAJ advance beyond comparison-based evaluation by focusing on explicit correctness assessment of reasoning questions.
JudgeBoard Pipeline: Direct Judging and Elo-Based Evaluation
JudgeBoard’s central innovation is its model-as-judge protocol, which queries models—particularly SLMs—directly on the factual correctness of candidate answers to reasoning questions across two high-value domains: mathematical and science/commonsense reasoning. Unlike indirect comparison-based frameworks, JudgeBoard orchestrates a pipeline consisting of candidate answer collection, independent judgment by models, pairwise competition, and leaderboard construction based on both accuracy and Elo-style relative rating instead of pure absolute metrics.
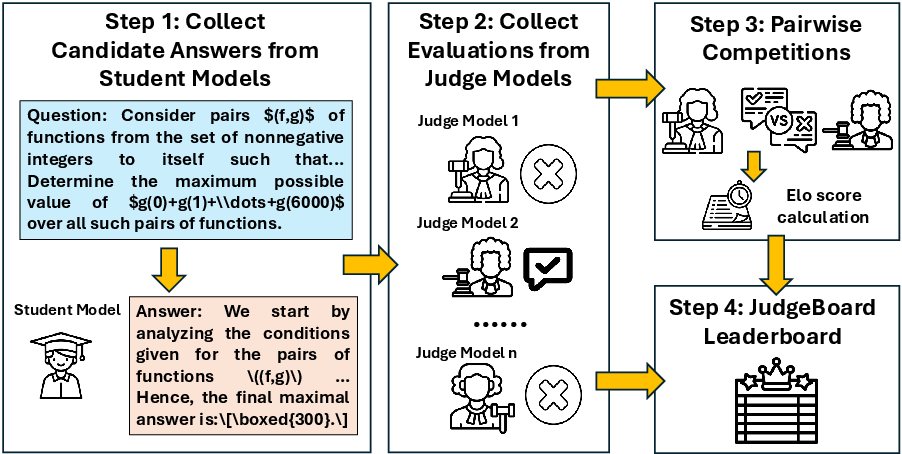
Figure 2: Overview of the JudgeBoard pipeline, demonstrating the staged evaluation architecture with direct model querying and systematic leaderboard construction.
The Elo formulation, inspired by Chatbot Arena, quantifies not only aggregate accuracy but also the distribution of “difficult” judgments via score updates in pairwise model matchups. This method exposes subtle performance contrasts opaque to summary statistics, offering more actionable insights for fine-grained system comparison.
Multi-Agent Judging (MAJ): Profiling and Debate for SLM Enhancement
Recognizing that isolated SLMs substantially underperform state-of-the-art LLMs when serving as single evaluators, the authors propose Multi-Agent Judging (MAJ)—a framework in which a set of SLMs with distinct, hand-engineered reasoning profiles (deductive, logical, robust) collaborate in judgment via structured deliberation and majority voting. Each agent is presented with the original question and a candidate answer, tasked with individual assessment and post-debate revision, followed by a consensus process. The use of profiles is crucial: it generates diverse analysis strategies while constraining the agents within actively useful reasoning paradigms.
Empirical Evaluation: Quantifying Model and System-Level Judging Ability
The JudgeBoard benchmark is instantiated across a spectrum of datasets, including MATH, GSM-8K, GSM-PLUS, ARC-Challenge, OmniMATH, and GPQA, allowing a multidimensional view of model judging capabilities in both math and science/commonsense reasoning.
Performance disparities are marked: LLMs (>14B parameters) consistently outperform SLMs across most metrics. However, contemporary SLMs (notably Qwen3 and Gemma3) can outperform older, larger models like Llama3 and Qwen2.5. Notably, Mixtral’s mixture-of-experts LLM configuration does not yield proportional judgment gains over baseline transformers.
MAJ delivers a significant boost to SLMs: With the MAJ architecture, Qwen3-14B surpasses larger LLMs—achieving an average +2% judging accuracy improvement over Qwen3-30B-A3B in the MATH dataset. This counters the prevailing assumption that SLMs are intrinsically ill-suited for judgment: collaborative, profiled SLM juries can match or even exceed LLM judgment reliability in competitive regimes.
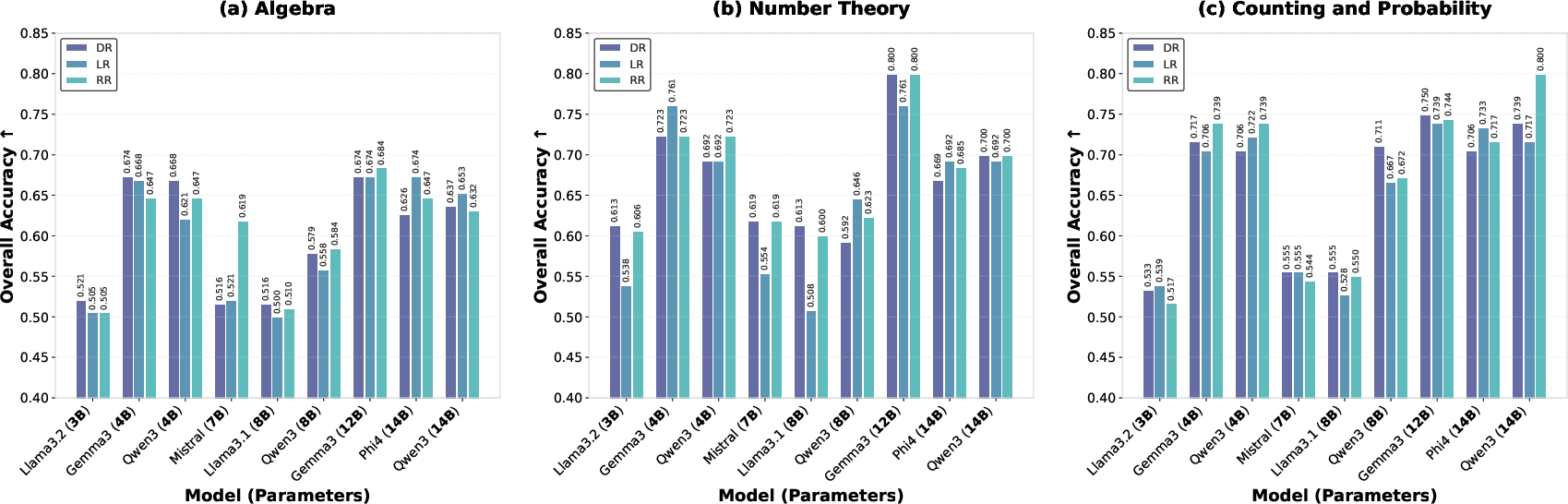
Figure 3: Accuracy for Deductive, Logical, and Robust Reasoner SLM profiles on Algebra, Number Theory, and Counting/Probability tasks, illustrating the versatility and impact of profiling.
Another key empirical observation is the sycophancy phenomena in low-performing models: poor SLMs often default to agreement with candidate answers regardless of correctness, resulting in high accuracy when the upstream student model is right, but drastically poor “Student Wrong Accuracy”—the ability to detect erroneous answers. The best models maintain balanced performance between validation and rejection.
Model profiling analysis uncovers that, for most SLMs, the “Robust Reasoner” profile yields the most consistent accuracy gains, while “Logical Reasoner” is less predictable. Profiling not only improves mean accuracy but also increases Elo separation among competitive models.
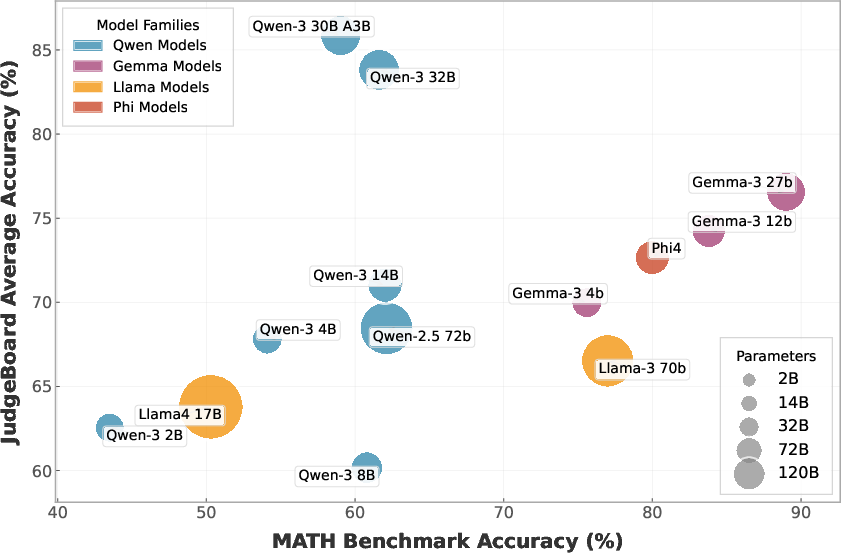
Figure 4: Performance comparison of LLMs on mathematical reasoning benchmarks, highlighting model parameter-dependent trends and outlier effects.
Theoretical and Practical Implications
JudgeBoard reframes evaluation in the LLM domain: by establishing direct judging as a tractable and scalable benchmark, it permits a more faithful measurement of judgment capabilities, vital for applications requiring reliable auto-evaluation or model-driven oversight. The demonstration that MAJ-like multi-agent SLM systems can nearly close the accuracy gap with LLMs challenges the dominance of scale in model selection for evaluation pipelines—collaborative, diversified SLM ensembles are a plausible, efficient substitute for monolithic judges.
Practically, this shift enables the deployment of competitive evaluators in resource-constrained settings, democratizing robust evaluation practices. The incorporation of structured agent profiling and debate draws a connection between architectural diversity and group reasoning in models, foreshadowing further gains via automatic agent configuration and adaptive self-critique.
Future Directions and Potential Advancements
Several unresolved axes invite further study. Dynamic agent profiling, where interaction protocols and reasoning styles evolve per-task or per-instance, may yield further gains over static profiling. Integrating MAJ with supervised or RL-based fine-tuning could result in SLM-based “expert judges” specialized for critical domains. Finally, extending JudgeBoard and MAJ to tasks beyond math/science—including long-form, creative, or safety-sensitive evaluation—and automating inter-agent debate rules, are promising areas for future systems and rigorous research.
Conclusion
JudgeBoard presents a comprehensive framework for direct, scalable, and fine-grained evaluation of LLM judgment in reasoning tasks. The incorporation of MAJ demonstrates that collaborative SLM systems, when properly orchestrated, can approximate or surpass traditional LLM-based judges. The work prompts a broader reconsideration of evaluation model design, championing collective and profiled SLM architectures as viable alternatives for automated reasoning assessment.

