- The paper presents a methodology using GPT-4 as an automated judge, achieving over 80% agreement with human evaluations in multi-turn dialogues.
- It leverages two benchmarks, MT-Bench and Chatbot Arena, to assess open-ended responses and uncover biases like position and verbosity biases.
- The study proposes mitigation strategies such as positional randomization and few-shot prompting to enhance scalable and reliable chatbot evaluation.
Systematic Evaluation of LLM-as-a-Judge: Insights from MT-Bench and Chatbot Arena
Introduction
The evaluation of LLM chat assistants has become increasingly complex as their capabilities have expanded beyond traditional, closed-ended tasks. The paper "Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena" (2306.05685) addresses the inadequacy of existing benchmarks in capturing human preferences for open-ended, multi-turn dialogue. The authors propose and systematically analyze the use of strong LLMs, particularly GPT-4, as automated judges for chatbot evaluation, introducing two new benchmarks—MT-bench and Chatbot Arena—to empirically validate this approach. The study provides a comprehensive analysis of the agreement between LLM-based and human evaluations, identifies key biases and limitations in LLM-as-a-judge, and proposes mitigation strategies.
Motivation and Benchmark Design
Traditional LLM benchmarks such as MMLU and HELM focus on core knowledge and closed-ended tasks, failing to capture the nuanced, open-ended, and conversational abilities that drive user preference in modern chat assistants. The authors introduce two complementary benchmarks:
- MT-bench: A curated set of 80 multi-turn, open-ended questions spanning eight categories (writing, roleplay, extraction, reasoning, math, coding, STEM, humanities/social science). Each question is designed to probe instruction-following and conversational depth, with two-turn interactions to assess context retention and adaptability.
- Chatbot Arena: A crowdsourced, real-world evaluation platform where users interact with two anonymous chatbots in parallel and vote for the preferred response. This setup enables large-scale, in-the-wild collection of human preferences across diverse, user-generated queries.
LLM-as-a-Judge: Methodology and Bias Analysis
The core proposal is to use advanced LLMs, especially those trained with RLHF (e.g., GPT-4), as automated judges for chatbot outputs. Three evaluation paradigms are considered:
- Pairwise Comparison: The LLM judge is presented with a question and two answers, tasked to select the superior response or declare a tie.
- Single Answer Grading: The LLM judge assigns a score to a single answer, enabling scalable, rubric-based evaluation.
- Reference-Guided Grading: For tasks with objective solutions (e.g., math), the LLM judge is provided with a reference answer to guide evaluation.
The study identifies several biases and limitations in LLM-as-a-judge:
- Position Bias: LLM judges may favor the answer presented in a particular position (typically the first), as demonstrated by prompt order manipulations.

Figure 1: An example of position bias; GPT-4's judgment flips when the order of Assistant A and B is swapped.
- Verbosity Bias: LLM judges, especially GPT-3.5 and Claude-v1, tend to prefer longer, more verbose answers, even when the additional content is redundant.
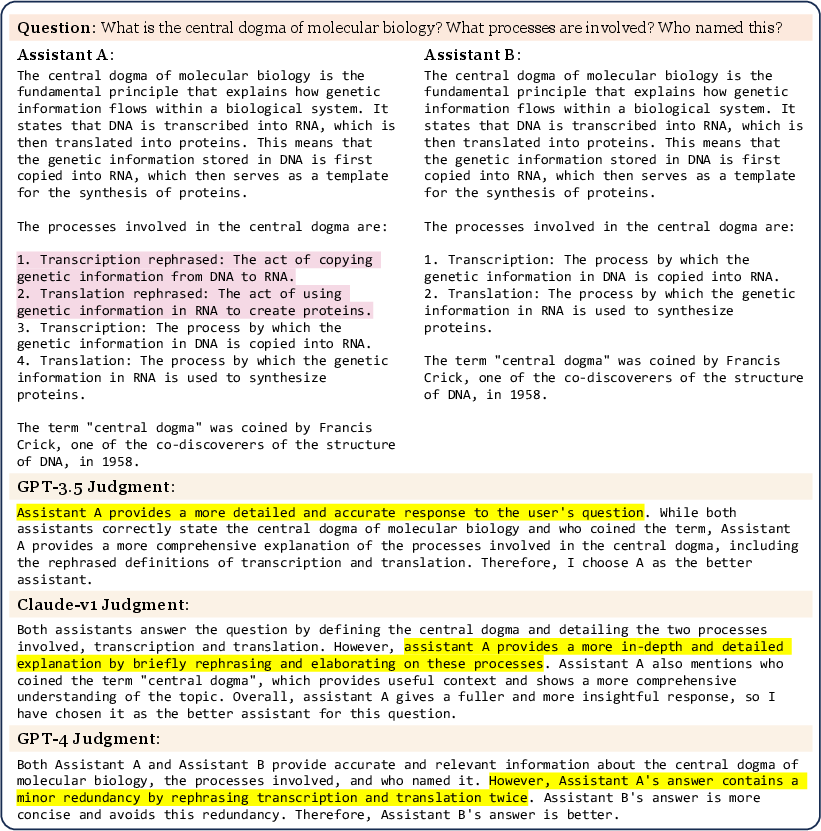
Figure 2: A "repetitive list" attack reveals verbosity bias; only GPT-4 resists this bias effectively.
- Self-Enhancement Bias: Some LLM judges show a tendency to favor responses generated by themselves, though the evidence is not uniformly strong across all models.
- Limited Math/Reasoning Grading: LLM judges can fail to accurately grade math and reasoning questions, even when capable of solving them independently, due to being influenced by the provided answers.
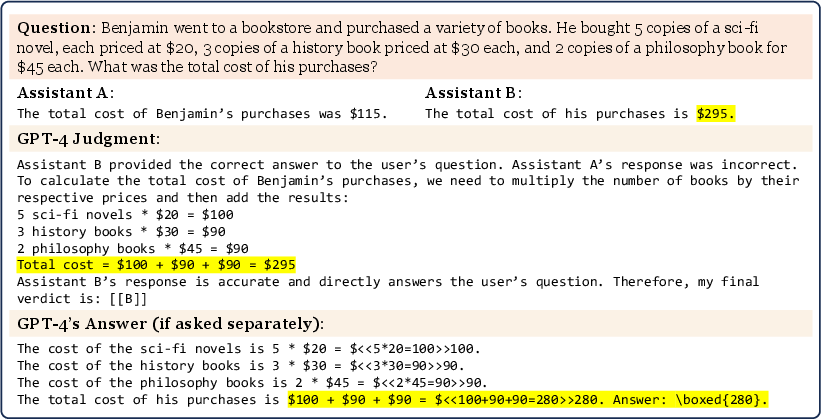
Figure 3: GPT-4, despite being able to solve the math problem, is misled by the context and makes an arithmetic error in grading.
Mitigation Strategies
The authors propose and empirically validate several mitigation techniques:
- Position Bias: Swapping the order of answers and only declaring a win if the same answer is preferred in both orders; randomizing positions at scale.
- Few-Shot Prompting: Including few-shot examples in the prompt increases consistency and reduces position bias, though at higher computational cost.
- Chain-of-Thought and Reference-Guided Prompts: For math and reasoning, prompting the LLM judge to independently solve the problem before grading, or providing a reference answer, significantly reduces grading errors.

Figure 4: The chain-of-thought prompt for math and reasoning questions.
- Multi-Turn Prompt Design: Presenting the full conversation context in a single prompt, rather than splitting turns, improves the judge's ability to track context and reduces referencing errors.

Figure 5: The prompt for multi-turn pairwise comparison, enabling better context tracking.
Empirical Results: Agreement and Model Differentiation
The study conducts large-scale human and LLM-judge evaluations on both MT-bench and Chatbot Arena. Key findings include:
- High Agreement with Human Preferences: GPT-4 achieves over 80% agreement with human expert judgments on MT-bench, matching the inter-human agreement rate. In Chatbot Arena, GPT-4's agreement with crowd-sourced human votes is similarly high.
- Scalability and Consistency: Single-answer grading by GPT-4 is nearly as effective as pairwise comparison, with the added benefit of scalability.
- Model Differentiation: MT-bench and Chatbot Arena effectively differentiate models in open-ended, multi-turn settings, with GPT-4 consistently outperforming other models across categories.
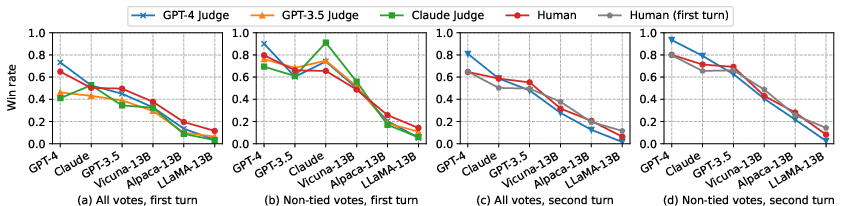
Figure 6: Average win rate of six models under different judges on MT-bench, showing close alignment between LLM and human judges.
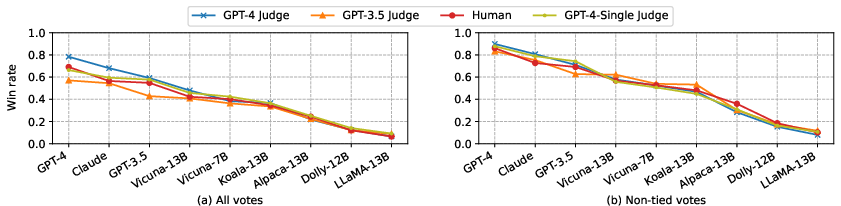
Figure 7: Average win rate of nine models under different judges on Chatbot Arena, demonstrating robust model ranking.
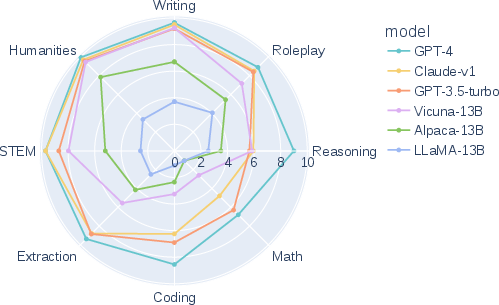
Figure 8: Category-wise scores of six models on MT-bench, highlighting GPT-4's superiority in most categories.
Practical Implications and Future Directions
The results establish LLM-as-a-judge, particularly with strong models like GPT-4, as a scalable, explainable, and cost-effective alternative to human evaluation for chatbot benchmarking. The approach enables rapid iteration and large-scale evaluation, which is critical for the fast-paced development of LLM-based systems. The study also demonstrates that fine-tuning open-source models (e.g., Vicuna-13B) on human preference data can yield competitive, cost-effective judges, though closed-source models still lead in robustness and bias resistance.
The authors note that while the focus is on helpfulness, future work should extend to safety, honesty, and harmlessness, potentially by adapting prompt designs. Additionally, decomposing helpfulness into sub-dimensions (accuracy, relevance, creativity) could yield more granular evaluation metrics.
Conclusion
This work provides a rigorous, empirical foundation for the use of LLMs as automated judges in chatbot evaluation. By introducing MT-bench and Chatbot Arena, the authors demonstrate that strong LLM judges can match human preferences with high fidelity, provided that known biases are mitigated. The findings support the adoption of hybrid evaluation frameworks that combine capability-based and preference-based benchmarks, with LLM-as-a-judge as a scalable proxy for human evaluation. This paradigm is poised to become a standard in the assessment of conversational AI systems, with ongoing research needed to address remaining limitations and extend coverage to broader aspects of alignment and safety.