Judging the Judges: Evaluating Alignment and Vulnerabilities in LLMs-as-Judges
Abstract: Offering a promising solution to the scalability challenges associated with human evaluation, the LLM-as-a-judge paradigm is rapidly gaining traction as an approach to evaluating LLMs. However, there are still many open questions about the strengths and weaknesses of this paradigm, and what potential biases it may hold. In this paper, we present a comprehensive study of the performance of various LLMs acting as judges, focusing on a clean scenario in which inter-human agreement is high. Investigating thirteen judge models of different model sizes and families, judging answers of nine different 'examtaker models' - both base and instruction-tuned - we find that only the best (and largest) models achieve reasonable alignment with humans. However, they are still quite far behind inter-human agreement and their assigned scores may still differ with up to 5 points from human-assigned scores. In terms of their ranking of the nine exam-taker models, instead, also smaller models and even the lexical metric contains may provide a reasonable signal. Through error analysis and other studies, we identify vulnerabilities in judge models, such as their sensitivity to prompt complexity and length, and a tendency toward leniency. The fact that even the best judges differ from humans in this comparatively simple setup suggest that caution may be wise when using judges in more complex setups. Lastly, our research rediscovers the importance of using alignment metrics beyond simple percent alignment, showing that judges with high percent agreement can still assign vastly different scores.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of gaps the paper leaves unresolved. Each item is phrased to be directly actionable for future research.
- Generalization beyond a single dataset: Results are derived exclusively from TriviaQA (English, short-form factual QA). It remains unclear whether findings hold for long-form generation, math/code, reasoning-heavy, safety-critical tasks, or multilingual and multimodal settings.
- Limited sample size and coverage: Only 400 questions (per exam-taker) from the validation set were used, with bootstrapping to check variance. A stratified, larger-scale study across difficulty levels and categories is needed to ensure stable, domain-wide conclusions.
- Binary grading only: The study uses a “correct/incorrect” label; it does not assess partial credit, degree of correctness, or multi-dimensional rubrics (e.g., factuality, completeness, reasoning quality). The transferability of results to richer evaluation schemes remains unknown.
- Missing comparison to semantic automatic metrics: Baselines are solely lexical (Exact Match, Contains). The paper does not evaluate or compare against modern semantic metrics (e.g., NLI-based scoring, BERTScore, BLEURT, LLM-as-NLI/entailment), leaving unclear whether these could rival or complement judge models.
- No evaluation of committee/jury strategies: The study uses single-judge decisions. It does not test whether aggregations (e.g., majority vote across diverse LLM judges, self-consistency, debate, or confidence-weighting) improve reliability or mitigate bias.
- Judge stochasticity and decoding controls: The paper does not report temperature/decoding settings or test run-to-run variability. Stability of judge decisions across seeds and decoding parameters remains unquantified.
- Prompt sensitivity underexplored: Only four prompt variants (and a reference-order test) are evaluated. A systematic exploration of template phrasing, rubric specificity, chain-of-thought/cot suppression vs. encouragement, and instruction conflicts is missing.
- Unclear pathways to mitigate leniency bias: The paper estimates a positive “leniency” bias () but does not investigate its causes or test corrective strategies (e.g., calibrated thresholds, cost-sensitive training, adversarial negative examples, bias-aware fine-tuning).
- Handling under-specified/partial answers: Judges struggle with under-specified answers. The paper does not test structured normalization (e.g., entity extraction/comparison), rubric redesigns, or training interventions to reduce over-crediting partial responses.
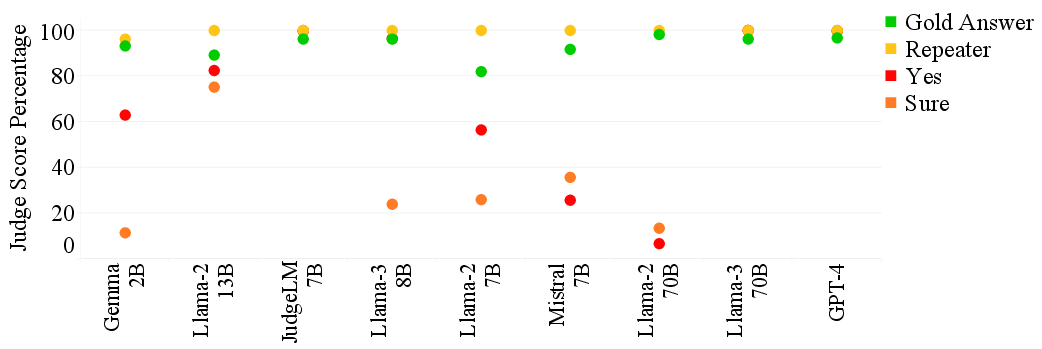
- Vulnerability to simple dummy answers: The study shows failures on inputs like “Yes”/“Sure” but does not examine richer adversarial attacks (e.g., persuasive language, prompt injections, stylistic obfuscation, hedging). Robustness against realistic adversarial exam-taker strategies is uncharacterized.
- Failures on verbatim gold answers: Some judges fail even when the candidate matches a reference exactly. The causes (instruction-following issues, tokenization, formatting) and mitigations (e.g., structured input formats, tool-assisted matching) are not analyzed.
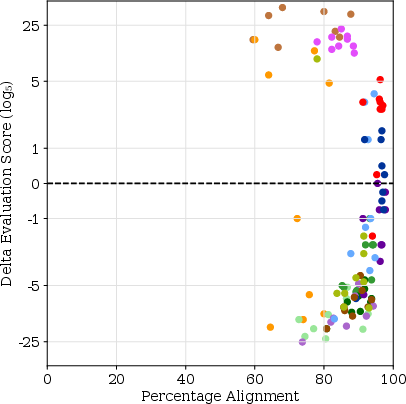
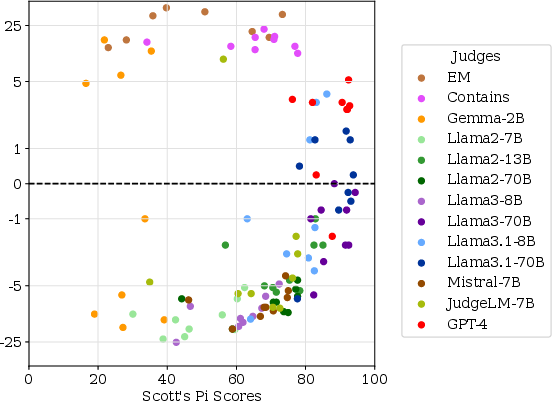
- Alignment metrics remain incomplete: Although Scott’s is more discriminating than percent agreement, it still does not capture score deltas, directionality of bias, or calibration. The paper does not test alternatives (e.g., MCC, balanced accuracy, AUROC) or propose task-specific metrics linking alignment to absolute score deviation.
- Ranking reliability nuances: High Spearman’s is reported, but the stability of rankings under small score shifts, different subsets of items, or across tasks is not examined (e.g., Kendall’s , top-k stability, swap sensitivity, significance across broader domains).
- Human annotation pipeline risks: After establishing high inter-annotator agreement on a subset, the study uses a single annotator for the remainder. The impact of residual label noise or annotator drift on conclusions is not quantified.
- Closed-source judge dependence and version drift: GPT-4 is used without versioning sensitivity analyses. How judge updates or API changes affect reproducibility and alignment is not assessed.
- Limited breadth of model families: Judge and exam-taker pools omit several strong contemporary families (e.g., Claude, Gemini, Qwen, Mixtral, Phi). The portability of findings across broader ecosystems remains unknown.
- Exam-taker prompting effects: Exam-takers are prompted with five few-shot examples, but the impact of few-shot selection, answer-style normalization, and verbosity constraints on judge performance is not explored.
- Reference set coverage and aliasing: TriviaQA has multiple short answers, yet the paper does not quantify how alias expansion, paraphrase augmentation, or entity-linking normalization affect judge alignment versus lexical baselines.
- Pairwise vs. absolute grading: The work intentionally avoids pairwise judgments. Whether the observed judge behaviors (e.g., leniency, prompt sensitivity) persist or improve in pairwise or listwise setups (and how to calibrate between them) remains untested.
- Lack of targeted judge training interventions: The paper audits judges but does not test fine-tuning or instruction-tuning specifically for evaluation reliability, nor characterize data requirements, overfitting risks, or cross-task generalization of “judge-tuned” models.
- Minimal analysis of style/verbosity effects in this setting: Although verbosity bias is noted in prior work, the paper does not quantify whether verbosity or stylistic cues influence judge decisions even in TriviaQA, where answers can be short but exam-takers may be verbose.
- Real-world, multi-turn contexts are out of scope: The study evaluates single-turn QA with references. It does not assess judge reliability in conversational contexts, multi-hop dialogues, or when prior turns may bias judgments.
- Cost/latency–quality frontier: While compute costs are provided in an appendix, the paper does not analyze the Pareto frontier (alignment vs. cost/latency) or propose guidelines for when cheaper judges (e.g., “Contains”) suffice for ranking vs. when expensive judges are necessary.
- Tool-augmented judges: The study does not test whether equipping judges with tools (e.g., regex/entity matchers, retrieval for alias verification) improves precision on partially correct or noisy outputs without inflating leniency.
- Reproducibility artifacts: It is unclear whether full prompts, annotations, and code are released. Without open artifacts, replicating nuanced findings (e.g., prompt sensitivity, dummy-answer failures) may be difficult.
Practical Applications
Immediate Applications
Below are concrete ways organizations and practitioners can use the paper’s findings right now, along with sector tags, potential tools/workflows, and feasibility notes.
- Replace percent agreement with more discriminative alignment metrics in evaluation dashboards (software/ML platforms)
- What: Report Scott’s π alongside percent agreement to distinguish judge quality and anticipate score deltas.
- Tools/workflows: “Eval Dashboard” modules that compute π, precision/recall, FP/FN stratified by error type; CI hooks in model release pipelines.
- Assumptions/dependencies: Access to a small human-labeled slice for calibration; clear binary criteria for correctness.
- Cost-efficient model ranking with simple baselines (software, education)
- What: Use a contains-based lexical metric or small LLMs (e.g., Mistral 7B) to produce reliable model rankings when exact scoring isn’t critical.
- Tools/workflows: “Cheap Ranker” stage for preliminary screening, followed by targeted human or strong-judge audits.
- Assumptions/dependencies: High-agreement tasks and short-reference answers (e.g., factoid QA); not for high-stakes scoring.
- Calibration of judge leniency and thresholds (software, education, enterprise QA)
- What: Estimate and monitor leniency bias (probability of over-marking “correct”), then adjust decision thresholds or require second opinions near decision boundaries.
- Tools/workflows: “Judge Auditor” that estimates leniency, plots calibration curves, and triggers human review for borderline/under-specified answers.
- Assumptions/dependencies: A small ground-truth set; willingness to tune thresholds per task/domain.
- Prompt policy for judges based on model strength (software, education)
- What: Keep judge prompts short/simple for weaker/smaller models; use richer guidelines for top models (GPT-4, Llama 3/3.1 70B) to gain small improvements without overloading.
- Tools/workflows: “Prompt Budgeter” that selects minimal instruction sets per judge and task.
- Assumptions/dependencies: Access to multiple judge options; prompt templates aligned with human guidelines.
- Defense checks in evaluation pipelines (software, RAG systems, education)
- What: Systematically test judges using dummy answers (e.g., “Yes”, “Sure”, question repeaters) and verbatim gold answers to detect false positives/negatives.
- Tools/workflows: “DummyProbe” tests in CI to fail builds if judges over-accept irrelevant answers or miss verbatim gold matches.
- Assumptions/dependencies: Automated test harness with representative prompts and references.
- Reference-order randomization to reduce bias (software/ML evaluation)
- What: Randomize and/or balance reference answer ordering to avoid small-model bias to early-listed references.
- Tools/workflows: “RefShuffle” pre-processor; A/B variants to confirm invariance in strong judges.
- Assumptions/dependencies: Multiple reference answers; stable tokenization/pre-processing.
- Human-in-the-loop adjudication for partial/under-specified responses (education, enterprise knowledge QA, customer support)
- What: Automatically flag answers that are plausible but incomplete (under-specified) for human review, given judges’ difficulty with such cases.
- Tools/workflows: “Partiality Detector” heuristics (e.g., entity counts vs reference) + routing rules to reviewers.
- Assumptions/dependencies: Clear rubric on “partial correctness”; available reviewers for triage.
- Ranking-focused leaderboards with bias reporting (academia, industry consortia)
- What: Use cheap judges/contains for ranking across many systems, but publish judge bias/π metrics and expected score deltas to avoid over-interpretation.
- Tools/workflows: Leaderboard metadata panel: Scott’s π, leniency estimates, FP/FN breakdown, prompt spec disclosure.
- Assumptions/dependencies: Community buy-in; standardized reporting format.
- Procurement and vendor evaluation guardrails (policy, enterprise IT)
- What: Require vendors to report judge alignment (π), leniency bias, and dummy-answer robustness when they claim “LLM-as-judge” evaluations.
- Tools/workflows: RFP/RFQ templates with evaluation disclosures; audit checklists.
- Assumptions/dependencies: Contractual requirements; acceptance that percent agreement alone is insufficient.
- Low-cost regression testing for RAG/QA features (software, search)
- What: Use contains plus a calibrated small judge to detect regressions and maintain ranking consistency; reserve strong judges/humans for contentious cases.
- Tools/workflows: “Two-Tier QA CI”: Tier-1 cheap ranker; Tier-2 strong judge/human spot checks on drift.
- Assumptions/dependencies: Stable task distribution; reference answers with high agreement.
- Education short-answer grading with safeguards (education)
- What: Deploy calibrated judges to grade short factoid items, with explicit thresholds for under-specified or ambiguous answers and mandated human overrides.
- Tools/workflows: “Hybrid Grader” integrating π-based selection of judges; rule-based partial-credit flags; human adjudication queue.
- Assumptions/dependencies: Narrow, factual prompts; institutional policy allowing hybrid grading; student privacy compliance.
- Risk triage in high-stakes domains (healthcare, finance, legal)
- What: Use LLM judges only for pre-screening/triage; final decisions by domain experts. Publish judge metrics and error profiles.
- Tools/workflows: “Triage Gate” that filters obvious errors and prioritizes expert time; audit logs including judge prompt length and versioning.
- Assumptions/dependencies: Strong governance; domain-specific references; privacy/security controls.
Long-Term Applications
The following require further research, domain adaptation, safety work, or standardization before broad deployment.
- Domain-specific, calibrated judge models with reduced leniency and higher recall on partial errors (healthcare, finance, legal, education)
- What: Fine-tuned judges that detect under-specification, partial matches, and domain nuances; controllable precision/recall trade-offs per risk level.
- Tools/products: “Domain Judge” families with reliability profiles; calibration kits; domain error taxonomies.
- Assumptions/dependencies: High-quality, domain-labeled data; expert-validated rubrics; ongoing calibration.
- Multi-judge ensembles with probabilistic aggregation (software, academia, policy)
- What: Ensembles of heterogeneous judges (LLMs + lexical + heuristics) combined via probabilistic models (e.g., Dawid–Skene-like variants) to reduce bias/variance.
- Tools/products: “Judge Ensemble SDK” with per-item uncertainty and disagreement signals; active-learning hooks for human labeling.
- Assumptions/dependencies: Sufficiently diverse judges; careful calibration on representative human labels.
- Adaptive, per-item judge selection and prompt optimization (software)
- What: Systems that pick the best judge and prompt for each instance based on predicted difficulty and risk—balancing cost, accuracy, and latency.
- Tools/products: “Adaptive Evaluator” with meta-models that predict when to escalate to stronger judges or humans.
- Assumptions/dependencies: Meta-data on item difficulty; historical error analytics; orchestration infrastructure.
- Robustness hardening against adversarial or off-distribution answers (software, policy)
- What: Training/evaluation procedures that make judges resistant to irrelevant yet “plausible” answers (“Yes”, “Sure”), prompt overload, or stylistic hacks.
- Tools/products: “Adversarial Eval Kit” generating stress tests for judges; certification badges for robustness profiles.
- Assumptions/dependencies: Curated adversarial corpora; consensus on robustness criteria.
- Standards and certifications for LLM-as-judge evaluation (policy, industry consortia, academia)
- What: Guidelines that specify metrics (Scott’s π, precision/recall, FP/FN by error type), prompt disclosure, dummy-answer robustness, and reference-order checks.
- Tools/products: “Evaluation Standard v1.x”; compliance audits; public registries of certified judge configurations.
- Assumptions/dependencies: Multi-stakeholder consensus; alignment with emerging AI governance frameworks.
- Comparative (pairwise) judging for open-ended tasks with fairness controls (education, creative industries)
- What: Prefer comparative assessments over absolute scoring to reduce instability; include verbosity/style debiasing.
- Tools/products: “Pairwise Grader” with length/style normalization; rank aggregation; fairness dashboards.
- Assumptions/dependencies: Task designs supporting comparisons; fairness definitions per context.
- Self-evaluating agent stacks with trustworthy internal judges (software, robotics)
- What: Agents that use calibrated judges to assess intermediate outputs (plans, tool calls) with controlled leniency and robust prompts.
- Tools/products: “Trusted Critic” module integrated in agent frameworks; fail-safe triggers on judge uncertainty.
- Assumptions/dependencies: Reliable uncertainty estimates; domain-specific safety constraints; real-time compute budgets.
- Large-scale assessment for standardized testing with equity safeguards (education, public sector)
- What: Gradual adoption of LLM judges for short answers with strict bias controls, transparent metrics, and human oversight for edge cases.
- Tools/products: “Public Exam Evaluator” compliant with reporting standards; audit trails; appeals workflows.
- Assumptions/dependencies: Regulatory approval; bias/impact studies; robust item banks with high inter-human agreement.
- Continuous monitoring of judge drift and governance (enterprise, policy)
- What: Lifecycle governance that tracks judge updates, prompt changes, and alignment drift over time; enforces re-validation when metrics degrade.
- Tools/products: “Judge Monitor” linking model cards, versioning, and live telemetry; automatic re-certification triggers.
- Assumptions/dependencies: Organizational maturity in MLOps; telemetry and data management policies.
- Human–AI collaboration protocols for nuanced partial credit (education, professional training)
- What: Structured workflows where judges propose partial-credit candidates and humans finalize grades to improve consistency and efficiency.
- Tools/products: “Partial-Credit Assistant” with fine-grained error codes (e.g., under-specified, wrong entity, too many/few entities).
- Assumptions/dependencies: Detailed rubrics; educator acceptance; UI for efficient adjudication.
- Sector-specific evaluation frameworks for RAG and knowledge systems (healthcare, finance, legal)
- What: Reference-rich, evidence-linked benchmarks and judge criteria tuned to RAG outputs and factuality, with strict handling of partial/ambiguous answers.
- Tools/products: “RAGEval Pro” with evidence verification and source-weighted scoring; judge robustness suites.
- Assumptions/dependencies: High-quality, up-to-date knowledge bases; privacy/compliance tooling.
- Public transparency in model leaderboards and reports (policy, academia)
- What: Require publication of judge prompts, alignment metrics, error analyses, and sensitivity tests to inform responsible interpretation.
- Tools/products: Leaderboard “Eval Factsheets”; repositories of judge prompts and reference sets.
- Assumptions/dependencies: Community norms favoring reproducibility; support from organizers/sponsors.
Cross-cutting assumptions and caveats
- Findings were derived from a high-agreement, factoid QA setting (TriviaQA); generalization to open-ended or subjective tasks requires validation.
- Strong judges (e.g., GPT-4, Llama 3/3.1 70B) still deviate up to ~5 points from humans; avoid single-judge reliance in high-stakes decisions.
- Availability, licensing, and compute for large models may constrain adoption; privacy and compliance requirements can limit API-based judging.
- Judge performance is sensitive to prompt complexity, reference ordering (especially for smaller models), and answer style/verbosity; pipeline guardrails are necessary.
Collections
Sign up for free to add this paper to one or more collections.