- The paper proposes the Sage framework to measure both local (IPI) and global (TOV) logical consistency in LLM-based evaluations.
- It employs a symmetrized, round-robin pairwise comparison method validated with strong empirical and theoretical results across diverse benchmarks.
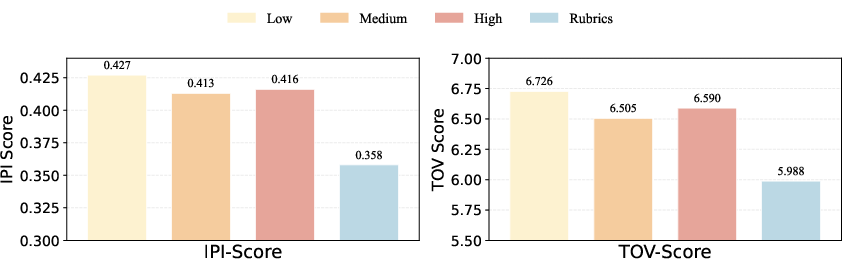
- The findings reveal that explicit evaluation rubrics and increased reasoning depth can mitigate situational preference and improve judge reliability.
Authoritative Summary and Evaluation of "Are We on the Right Way to Assessing LLM-as-a-Judge?" (2512.16041)
The LLM-as-a-Judge paradigm leverages highly capable LLMs to provide scalable, automated evaluation of AI-generated outputs, progressing beyond human-centric ground-truth annotation. This paradigm has rapidly gained adoption in model evaluation and reward modeling, offering methodological efficiency and cost-effectiveness. However, the paradigm inherits vulnerabilities from human annotation, including annotator disagreement, cognitive bias, and an inability to handle fine-grained assessment of high-quality outputs, resulting in instability and unreliability. The paper targets these foundational deficiencies, questioning the assumed reliability of human-annotated gold standards in LLM evaluation and proposing the Sage evaluation framework to systematically quantify judge model robustness in a manner agnostic to human annotation.
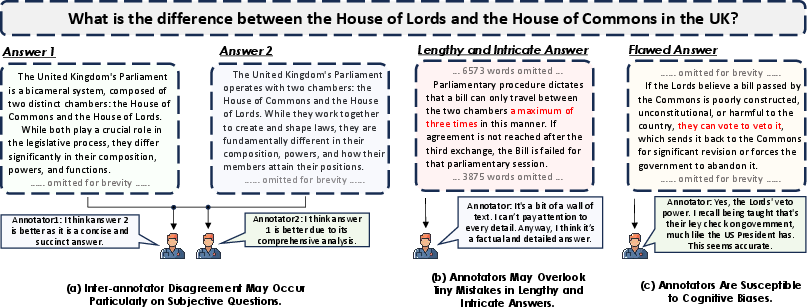
Figure 1: Human preference annotation exhibits inter-annotator disagreement, missed subtleties, and cognitive biases, undermining the reliability of ground-truth data.
The Sage Evaluation Suite: Methodology and Metrics
Sage is introduced as a self-contained, human-free protocol for quantifying LLM judges’ local and global logical consistency in pairwise evaluation scenarios. The methodological core consists of a symmetrized round-robin scheme for pairwise answer comparison, designed to neutralize positional bias and ensure reproducibility. Each judge model M performs bidirectional judgments on all answer pairs for each question, mapping output to {−1,0,1} for preference/indifference.
Two consistency metrics are defined:
- Intra-Pair Instability (IPI): Measures bidirectional disagreement (i.e., the judge’s response for (Ai,Aj) vs (Aj,Ai)) as a proxy for local, atomic inconsistency and positional bias.
- Weak Total Order Violation (TOV): Quantifies the minimum number of preference reversals necessary to embed all judgments into a valid weak total order, thus tracking a judge’s global logical coherence and violation of transitivity.
Sage’s protocol is validated both empirically (variance <10−5 for aggregate metrics across 650 questions) and theoretically (conformal prediction-derived bounds and i.i.d. error propagation) to guarantee stability and robustness under model stochasticity.
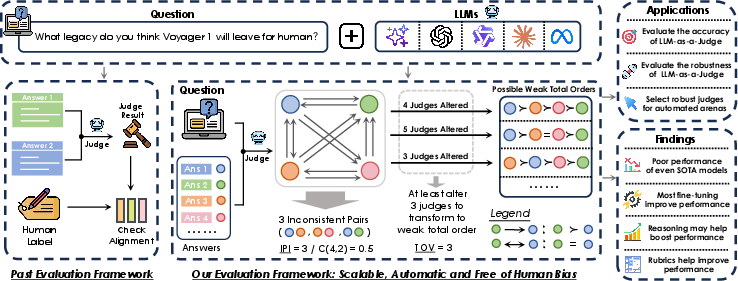
Figure 2: Sage employs a symmetrized protocol for pairwise comparisons, computing IPI (preference flip rate) and TOV (minimum violations for a transitive ranking).
Benchmark Design and Experimental Setup
The 650-question Sage benchmark is constructed from five RewardBench2 categories and real-world WildChat-1M queries, yielding broad semantic coverage. For each question, two difficulty tiers are instantiated:
- Sage-Easy: Six answers provided by models with clear capability gaps, facilitating robust comparisons.
- Sage-Hard: All answers generated by a single strong model, enforcing minimal quality variance and challenging fine discrimination.
Quality dispersion is empirically validated using coefficient of variation (CV), with Sage-Hard exhibiting markedly lower CV and higher cognitive load (42% longer adjudication time for annotators), confirming benchmark difficulty.
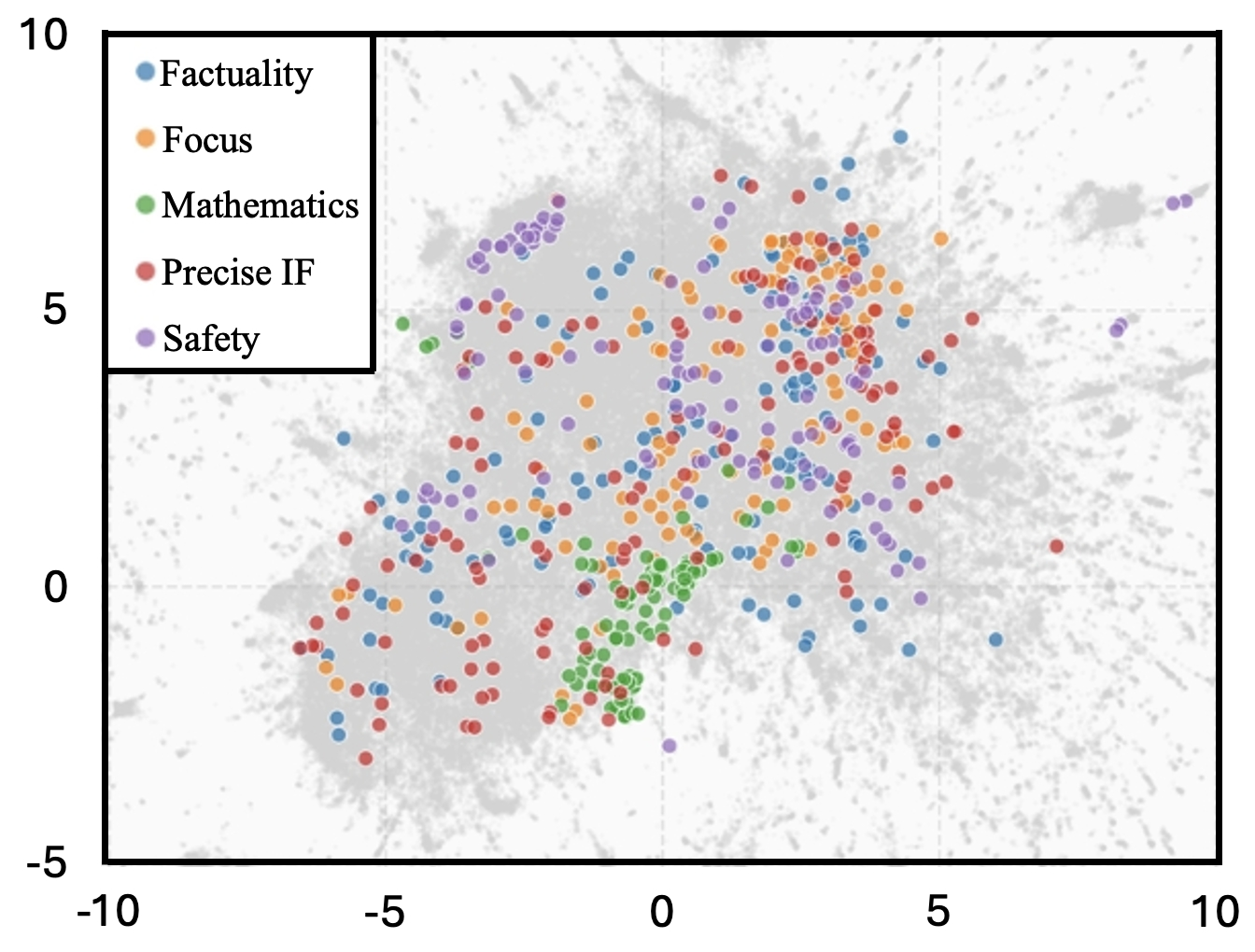
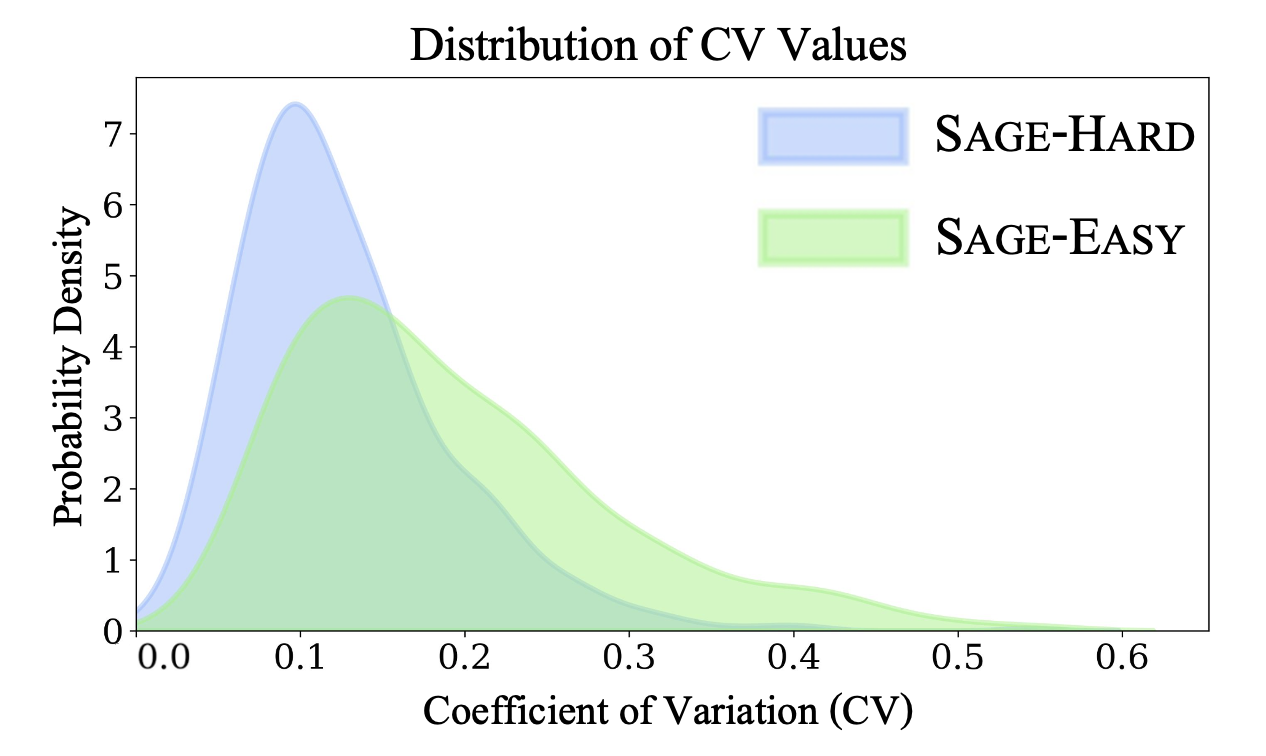
Figure 3: Sage dataset is derived from multiple categories and sources, ensuring extensive topical and semantic coverage.
Empirical Analysis: Consistency, Robustness, and Proxy Validity
Extensive experiments across thirteen prominent LLM judges reveal:
- Metric Stability: Sage’s IPI and TOV metrics display high stability across temperature sweeps and replicate runs, aligning with theoretical variance bounds.
- External Correlation: Spearman rank correlations between Sage metrics and supervised benchmarks (LLMBar, RewardBench2) are >0.79, substantiating Sage’s capability as an effective proxy for both robustness and error rate.
All models degrade sharply from Sage-Easy to Sage-Hard (approximate 200% increase in inconsistency), indicating fundamental brittleness in local and global preference formation for difficult, subtle discriminative cases. Gemini-2.5-Pro and analogous models achieve the lowest IPI/TOV, but still fail to maintain strict consistency in over 25% of Sage-Hard trials.
Situational Preference and Evaluation Instabilities
Upon further analysis, the primary instability mode is identified as "situational preference," wherein LLM judges vary their gauging principles or rubrics across answer pairs under the same question, absent a stable internal standard. This phenomenon accounts for widespread logical incoherence even in top-tier models.
Effects of Fine-Tuning, Multi-Agent Aggregation, and Reasoning
Fine-tuned judges (Prometheus, Skywork-Critic, M-Prometheus) consistently outperform base models, evidencing generalizable improvements in logical consistency, while some models (JudgeLRM-3B) regress due to inherited biases in preference data. Multi-agent panels further enhance performance (up to 15%), whereas debate-based systems degrade stability due to persuasive hallucinations, anchoring, and information redundancy. Increased model reasoning depth yields monotonic improvements in evaluation robustness, especially in Sage-Hard settings.
Robustness to Prompting and Benchmark Difficulty
Prompt style has negligible effect on metric stability or model ranking, indicating prompt-agnostic reliability. Changing the answer generator in Sage-Hard produces minimal performance shifts (<0.5%), confirming benchmark difficulty as intrinsic and model-agnostic.
Figure 5: Minimal metric spread across prompt styles validates the reliability and prompt-invariance of Sage’s evaluation framework.
Human Annotation Baseline and Cost Analysis
Human annotators exhibit substantial inconsistency (IPI up to 0.332, TOV up to 6.523 in Sage-Hard), definitively demonstrating that human annotation is a noisy, unreliable gold standard for fine-grained evaluation. Sage achieves full-scale evaluation at negligible computational cost (%%%%9↓10%%%%\sim\$\{-1,0,1\}$1 and 100 days).
Theoretical and Practical Implications
Sage exposes foundational limitations in the LLM-as-a-Judge paradigm—large-scale LLMs do not consistently maintain internal evaluative standards, particularly on tasks requiring fine discrimination among high-quality or subtly differing outputs. The identification and quantification of situational preference, and the demonstration that explicit rubrics and deep reasoning can partially remediate inconsistency, pave the way for future developments:
- Automated evaluation frameworks must incorporate intrinsic consistency validation and rubric standardization.
- Reward modeling and RL-based training using LLM-as-a-Judge should factor in robustness diagnostics to avoid reward hacking through preference instabilities.
- Human annotation should be abandoned as an unquestioned gold standard for model evaluation, and consistency-driven, model-agnostic frameworks such as Sage adopted for both textual and multimodal assessment.
Conclusion
"Are We on the Right Way to Assessing LLM-as-a-Judge?" (2512.16041) provides a rigorous, systematic reconsideration of automated model evaluation pipelines, identifying deep-seated weaknesses in both human and LLM-based judgment. The Sage methodology offers stable, cost-efficient, and theoretically grounded metrics for diagnosing logical consistency in LLM judges. Empirical evidence establishes the unreliability of human annotation and the prevalence of situational preference in current models, with explicit rubric regularization and fine-tuning serving as partial countermeasures. Future research should focus on robustness-first design for judge models and the expansion of model-agnostic consistency frameworks for high-quality evaluation and alignment.