- The paper introduces a learned optical token compression technique that compresses UI screenshots to 256 tokens, achieving up to 7.5% CLIP score improvement over uncompressed outputs.
- It integrates a cascaded convolutional compressor with LoRA-adapted decoding, yielding a 9.1× speedup in time-to-first-token with only 0.26% extra parameters.
- Empirical evaluations and ablation studies demonstrate that UIPress outperforms standard and inference-time token reduction methods in both quality and efficiency.
UIPress: Learned Optical Token Compression for Efficient UI-to-Code Generation
Introduction and Motivation
Automated UI-to-Code generation—translating UI screenshots into functional HTML/CSS—poses substantial challenges to vision–LLMs (VLMs) due to the extremely long output sequences required (1K–4K tokens) and the dense visual tokenization induced by modern ViT-based encoders. For instance, Qwen3-VL-8B yields ∼6,700 visual tokens per typical high-resolution page, dominating both memory and latency during decoding. Existing token reduction approaches, including inference-time heuristics (e.g., feature-zeroing, token selection by L2 norm, resolution scaling), only partially mitigate runtime overhead and often fail to align with the highly non-uniform information distribution in UI screenshots. Moreover, encoder-side (optical) compression, successful in OCR, has not yet been adapted to UI-to-Code, largely due to representation mismatch and lack of task specificity.
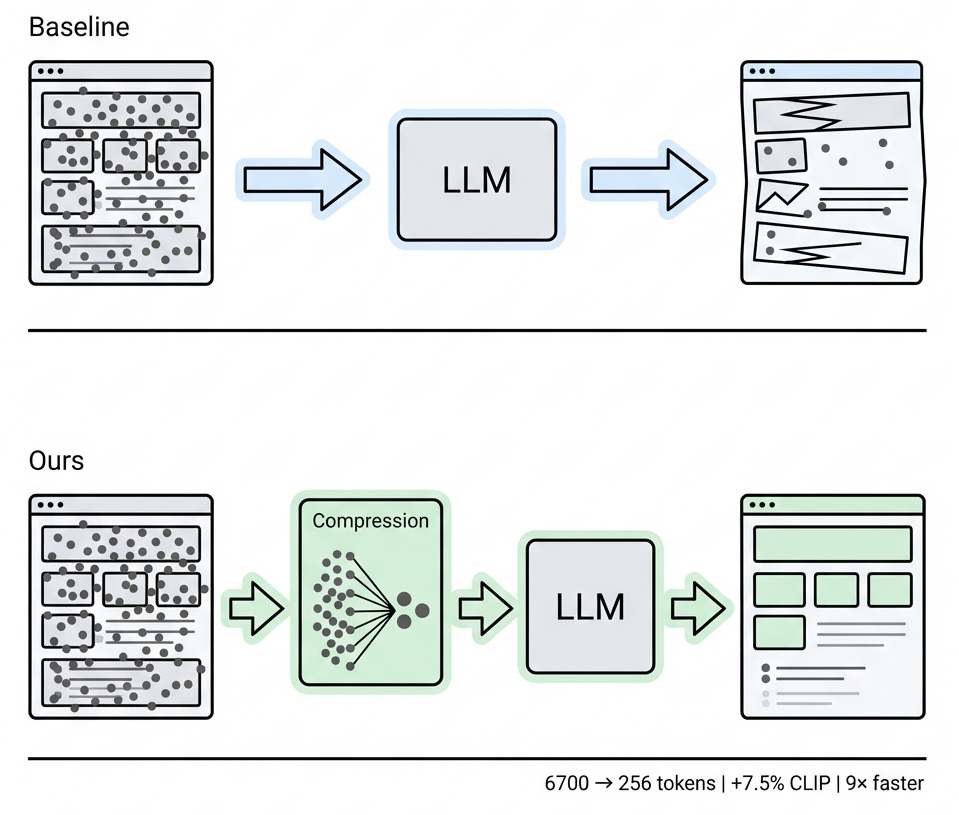
Figure 1: Comparison between conventional visual token processing and the learned compression framework introduced by UIPress for UI-to-Code generation.
Methodological Framework of UIPress
UIPress introduces a modular, learned optical compression pipeline between a frozen ViT encoder and the Qwen3-VL-8B LLM decoder. The framework encompasses three key components:
- Convolutional Optical Compressor: Utilizes cascaded depthwise-separable convolutions for spatial downsampling (4×), followed by adaptive pooling and element-guided token reweighting using OmniParser V2 detections. This yields a compressed, fixed-length sequence (typically K=256, down from ∼6,700).
- Decoder Adaptation via LoRA: Low-Rank Adaptation is jointly trained on all query and value projections of the frozen LLM decoder, bridging the representation gap without incurring the cost of full model fine-tuning.
- End-to-End Joint Training: The combination of compressor and LoRA adapters is optimized using a standard autoregressive objective on 50K WebSight screenshot–HTML pairs.
The total added parameter count is remarkably low—∼21.7M (0.26% of base parameters)—positioning UIPress as both practical and efficient.
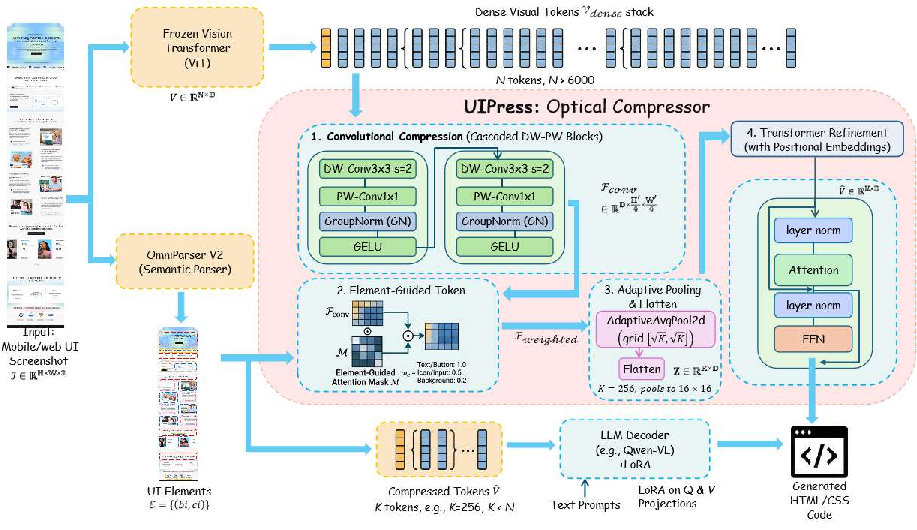
Figure 2: Schematic overview of UIPress, detailing ViT encoding, convolutional compression, element-guided pooling, Transformer refinement, and LoRA-augmented decoding.
Empirical Results and Comparative Analysis
UIPress is evaluated on Design2Code, pitted against Qwen3-VL-8B with no compression and four inference-time compression baselines (resolution scaling, VisionZip, EfficientUICoder, FastV). Key highlights and strong claims include:
Training curves (Figure 4) show clear monotonic ascent on validation CLIP with no discernible overfitting, attesting to stable convergence properties.
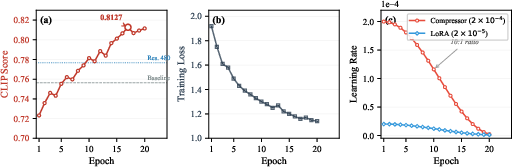
Figure 4: UIPress training dynamics: validation CLIP increases from 0.7232 (random init) to a peak of 0.8127 (epoch 17), surpassing all baselines.
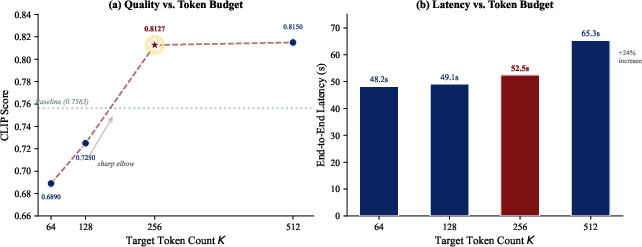
Pareto plots of compression-quality trade-offs (Figure 5) position UIPress-256 as strictly dominant among all tested configurations.
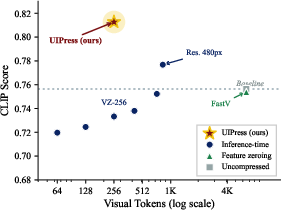
Figure 5: Comparative plot of method–budget configurations demonstrates UIPress-256’s Pareto optimality for compression vs. CLIP.
Qualitative comparisons (Figure 6) confirm that even at extreme compression, UIPress-generated HTML repros maintain sidebar layouts, preserve fine structure, and avoid content collapse that afflicts non-learned baselines.
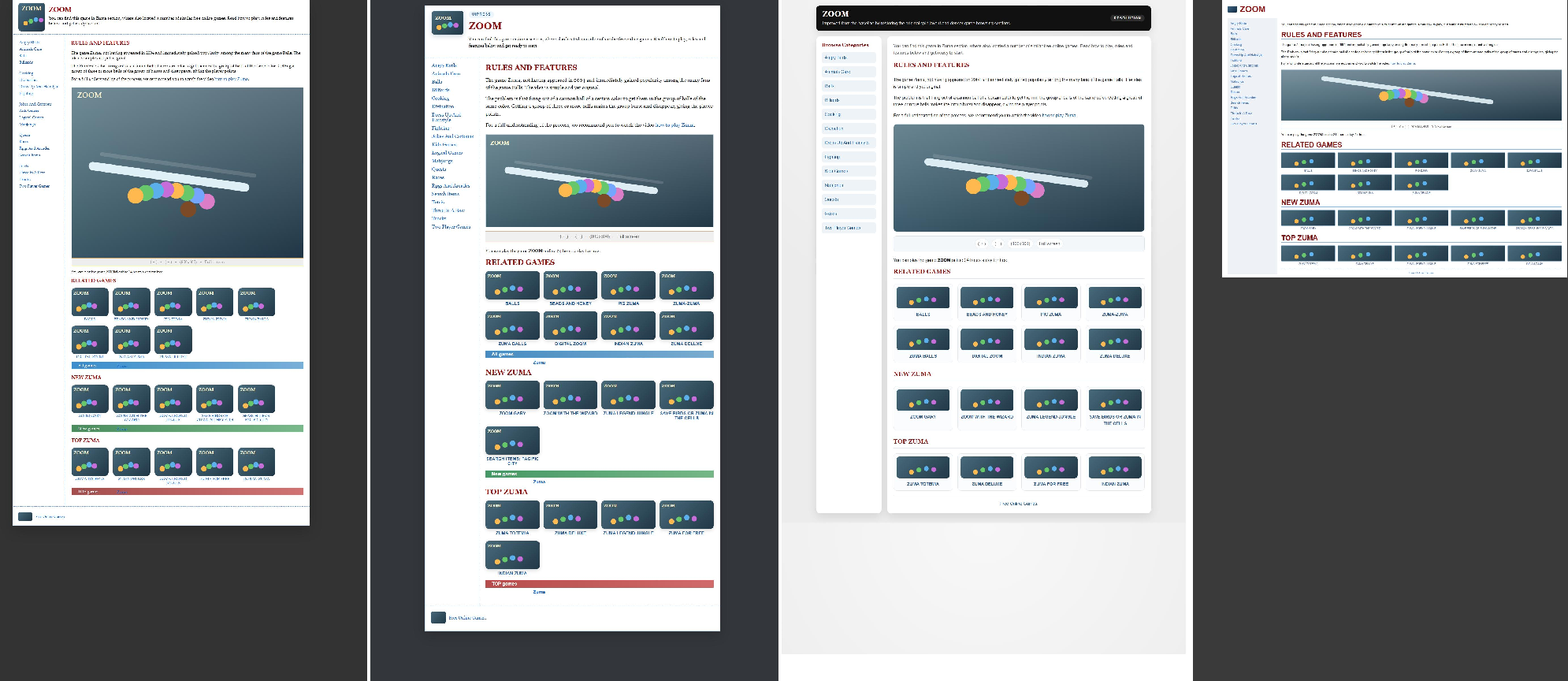
Figure 6: Qualitative case: UIPress best preserves sidebar structure and section-level styling at 256 tokens, with superior CLIP versus all baselines.
Theoretical Perspective and Broader Implications
UIPress is, to date, the first encoder-side learned compression adapted to UI-to-Code. Its efficacy is underpinned by:
- Task-aligned bottlenecking: The framework harnesses spatial redundancy and non-uniform semantic density in page screenshots via learned, element-prioritized pooling. The information bottleneck interpretation clarifies why high compression rates are plausible—UI pages are heavily over-tokenized by ViT encoders.
- Joint representational adaptation: Introduction of LoRA to the decoder is essential for mitigating distribution mismatch, demonstrating that lightweight adaptation is necessary for effective utilization of novel compressed representations.
- “Beyond-lossless” compression: Contrary to naive information-theoretic bounds, learned bottlenecks can improve performance by denoising or focusing model capacity, a result directly observed in both empirical metrics and qualitative fidelity.
Practically, UIDPress enables the deployment of high-fidelity UI code generation with order-of-magnitude latency and memory reductions—a substantial advance toward real-world multimodal agents capable of synthesis or automated frontend engineering.
Limitations and Future Prospects
Notable limitations include:
- Reliance on large (50K) task-specific training sets for optimal performance.
- Fixed-token budgets per instance; adaptive allocation according to page complexity is an open problem.
- CLIP is the principal metric—evaluation on fine-grained structural or semantic correctness remains an area for follow-up.
- Reimplementation for mobile, Figma, or native apps would require domain adaptation.
The theoretical angle suggests further exploration along the lines of dynamic, instance-adaptive compression strategies, extending to other multimodal tasks (e.g., complex document synthesis, GUI automation), and possible co-design of visual encoder and bottleneck modules.
Conclusion
UIPress establishes encoder-side optical compression as a viable, high-yield approach to visual token reduction in UI-to-Code tasks. By combining convolutional downsampling, task-specific reweighting, transformer refinement, and lightweight decoder adaptation, it achieves significant gains in both output quality and computational efficiency—realizing truly practical, latency-aware UI-to-Code systems with minimal parameter overhead. This paradigm is likely extensible to broader classes of vision-language tasks exhibiting similar long-range, non-uniform, and semantically structured input domains.
Reference: "UIPress: Bringing Optical Token Compression to UI-to-Code Generation" (2604.09442)