- The paper introduces a bidirectional token compression framework that reduces both visual and code token redundancies in MLLM-based UI code generation.
- It combines element detection, attention-guided token refinement, and adaptive duplicate suppression to achieve significant improvements in FLOPs, token count, and inference speed.
- Experimental results demonstrate up to 60% compression and enhanced output quality, validated by both automatic metrics and human evaluations.
EfficientUICoder: Bidirectional Token Compression for Efficient MLLM-Based UI Code Generation
Introduction and Motivation
EfficientUICoder addresses the computational inefficiencies inherent in Multimodal LLM (MLLM)-based UI-to-code (UI2Code) tasks. These inefficiencies stem from the excessive number of input image tokens and output code tokens required to represent complex webpage designs and their corresponding HTML/CSS implementations. Empirical analysis reveals that over 90% of token consumption in UI2Code benchmarks is attributed to image and code tokens (Figure 1).
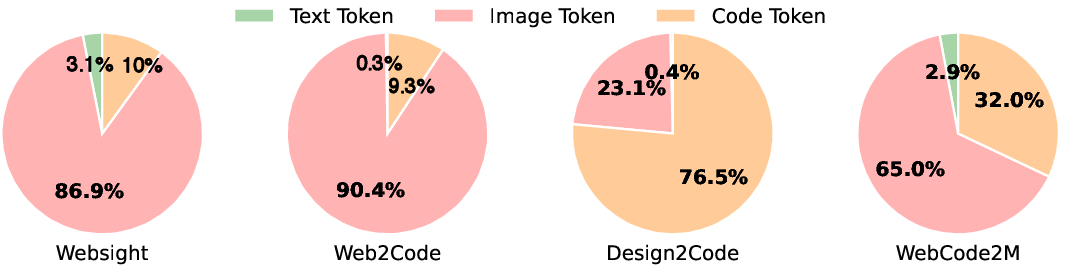
Figure 1: The token ratios of different datasets.
The paper identifies two primary sources of redundancy: (1) visual token redundancy, where background and non-informative regions inflate input sequence length and distract model attention, and (2) code token redundancy, where MLLMs frequently generate duplicate HTML/CSS structures and textual content, leading to invalid or excessively lengthy outputs. These redundancies result in quadratic growth in computational complexity due to the self-attention mechanism's dependence on sequence length.
Redundancy Analysis in UI2Code Tasks
Visual Token Redundancy
Attention score visualizations using CLIP-based encoders demonstrate that only a minority of tokens correspond to semantically meaningful UI elements, while the majority are allocated to background regions (Figure 2). This misallocation not only increases computational cost but also degrades model focus on critical interface components.
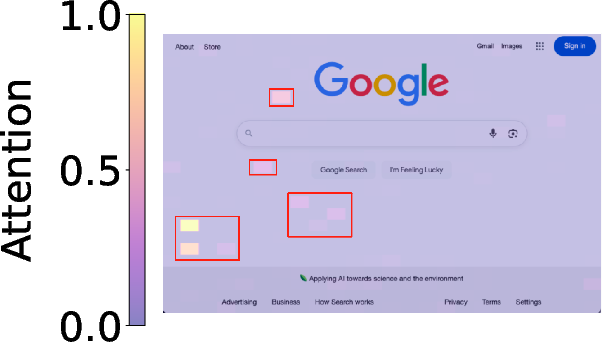
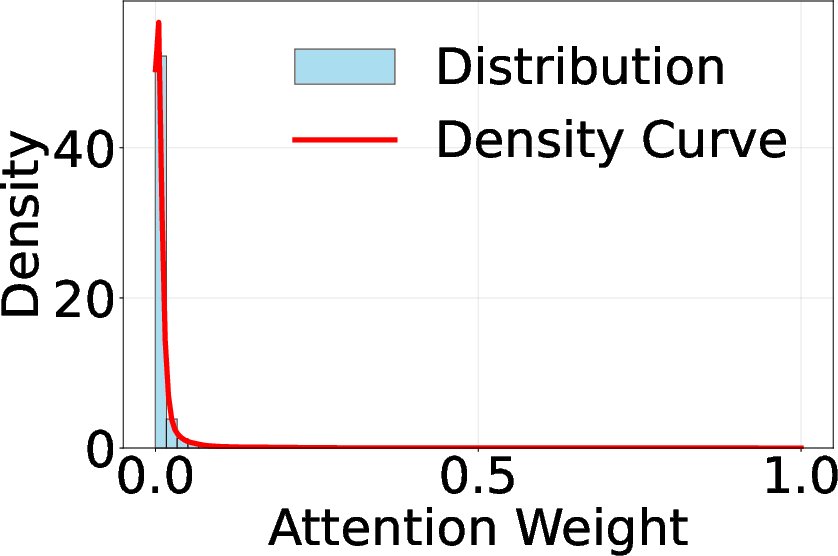

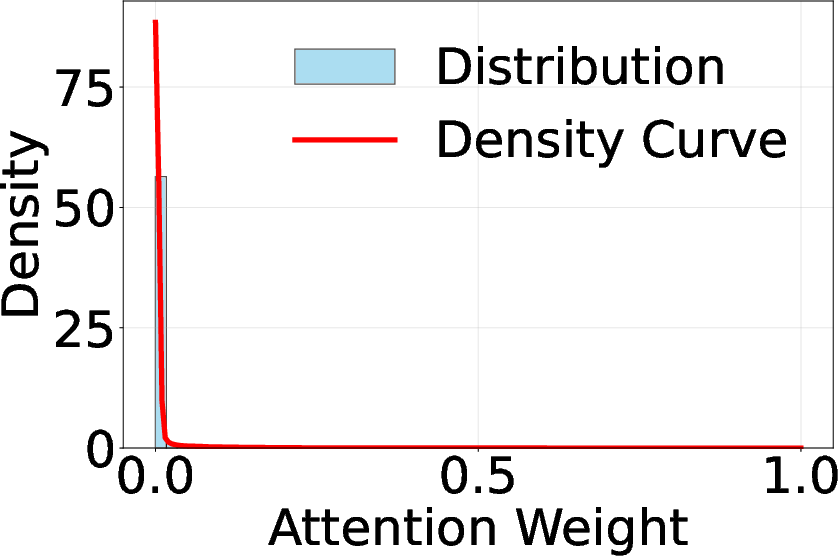
Figure 2: Visual encoders' attention score visualization and distribution on two webpages.
Code Token Redundancy
Manual and automated analysis of MLLM outputs on Design2Code and WebCode2M datasets reveals three categories of code redundancy: repeated CSS selectors/properties, redundant HTML structural patterns, and duplicate textual content (Figure 3). These patterns can persist until the model's token limit is reached, resulting in invalid HTML and wasted computation.
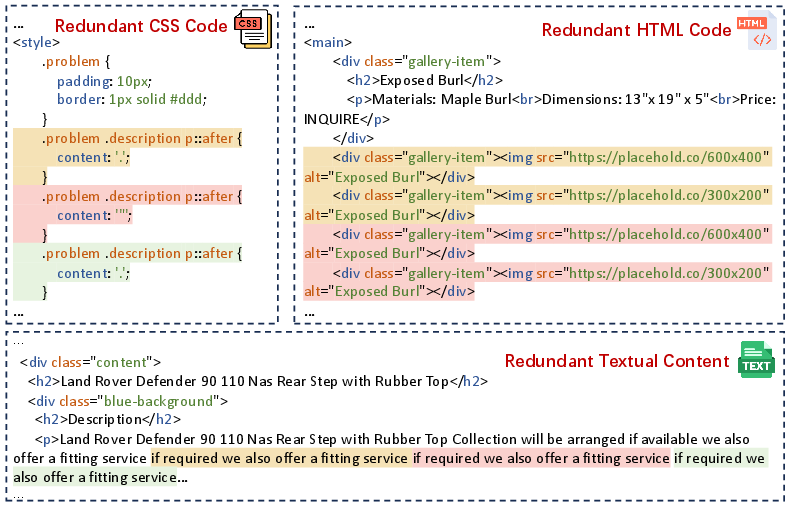
Figure 3: Duplicate code token examples.
EfficientUICoder Framework
EfficientUICoder introduces a bidirectional compression pipeline comprising three modules:
- Element and Layout-aware Token Compression (ELTC): Utilizes UI element detection (UIED) to extract bounding boxes for all UI components, merges fragmented text regions, and constructs a UI element graph. A minimum spanning tree (MST) algorithm is applied to preserve essential layout relationships while minimizing token count.
- Region-aware Token Refinement (RTR): Refines the token set by leveraging attention scores from the visual encoder. Low-attention tokens within selected regions are dropped, while high-attention tokens from unselected regions (e.g., informative backgrounds) are incorporated. The refinement ratio $r$ is tuned to balance compression and semantic preservation.
- Adaptive Duplicate Token Suppression (ADTS): During decoding, HTML/CSS and text repetition frequencies are tracked via custom parsers. An exponential penalty is applied to the logits of repeated tokens over a suppression window $s$, with decay factor $\lambda$, dynamically reducing the probability of redundant token generation.
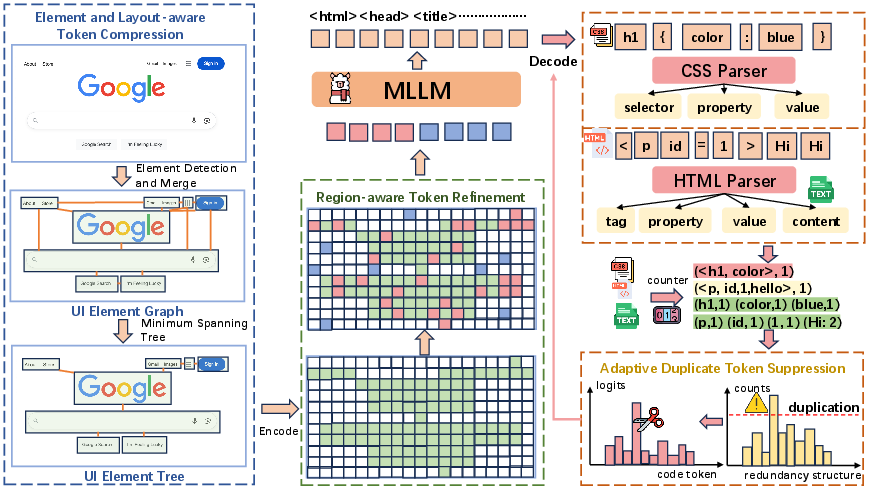
Figure 4: EfficientUICoder framework.
Experimental Results
EfficientUICoder achieves 55–60% image token compression and 56–94% code redundancy reduction without compromising UI2Code performance. On Design2Code and WebCode2M, EfficientUICoder outperforms vanilla and baseline compression methods (Random, FastV, Pdrop, VisionZip) across block-match, text, position, color, CLIP, and BLEU metrics. Notably, EfficientUICoder sometimes surpasses vanilla in certain metrics due to improved focus on key UI elements and effective redundancy suppression.
Human Evaluation
Human annotators consistently prefer EfficientUICoder outputs over baselines, corroborating automatic metric results (Figure 5).
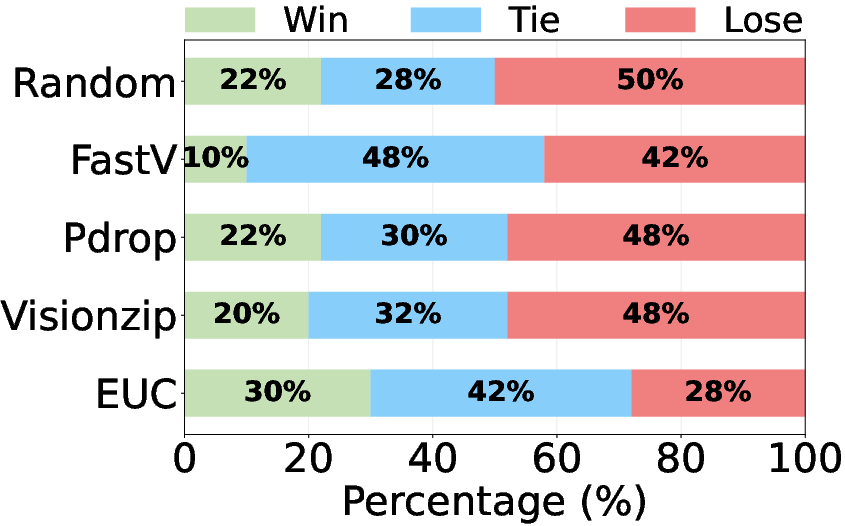
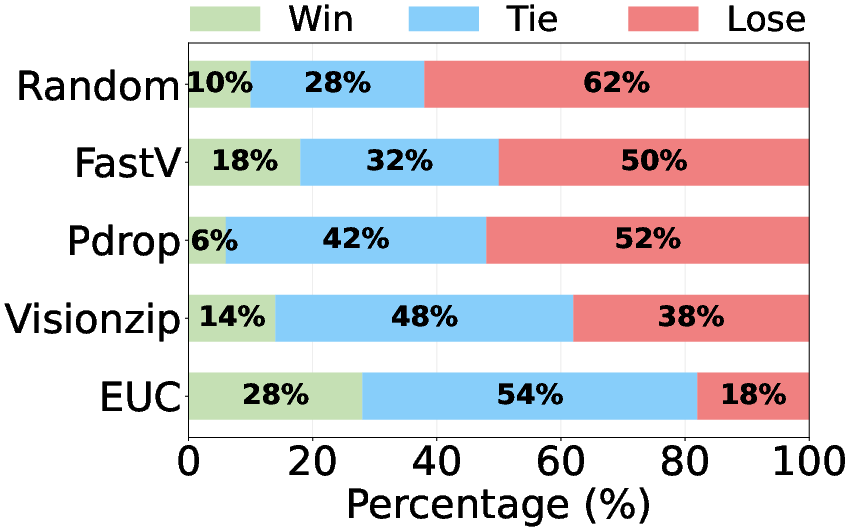
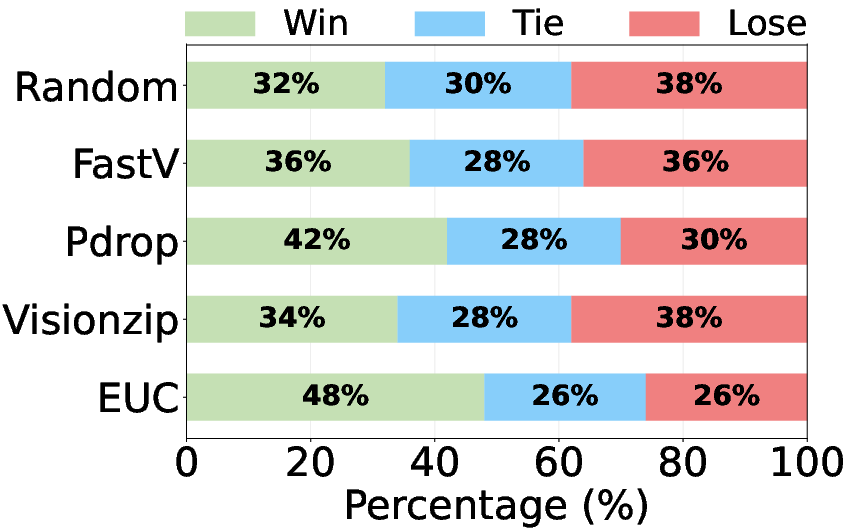
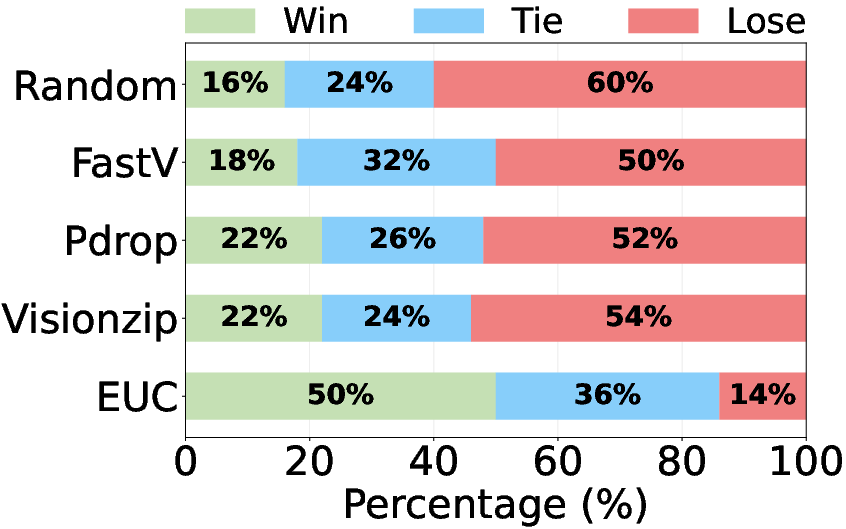
Figure 5: Human Evaluation on Design2Code.
Efficiency Gains
EfficientUICoder delivers substantial efficiency improvements: up to 44.9% reduction in FLOPs, 41.4% fewer generated tokens, 46.6% lower prefill time, and 48.8% faster inference time on 34B-level MLLMs. These gains are robust across datasets and model scales.
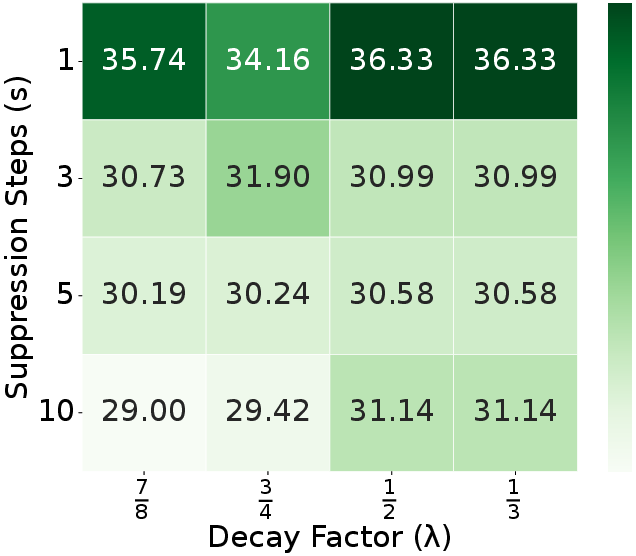
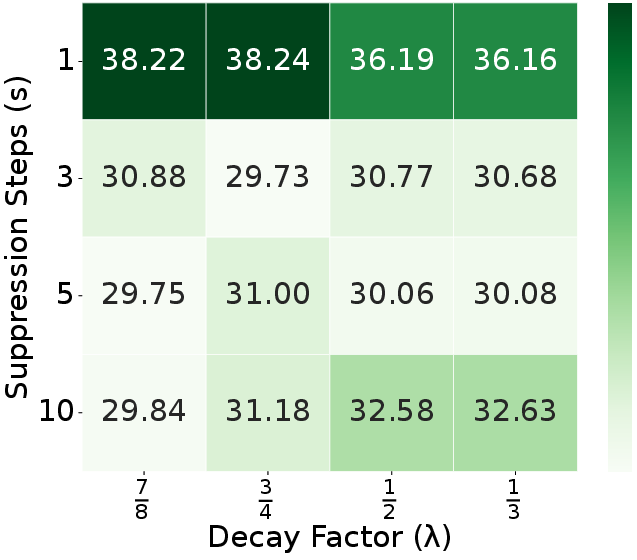
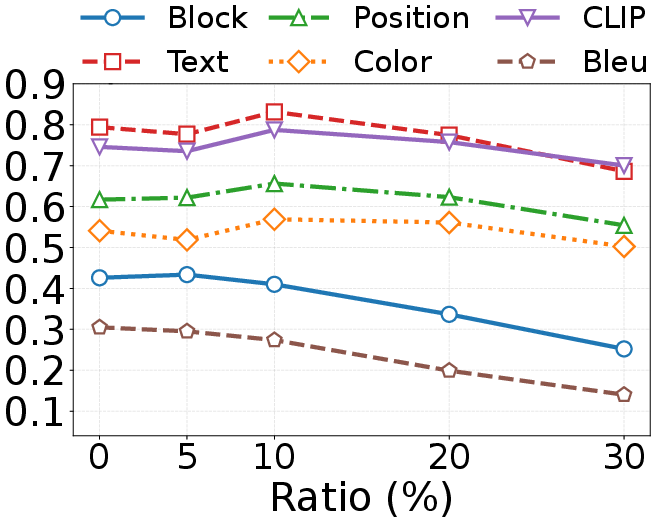
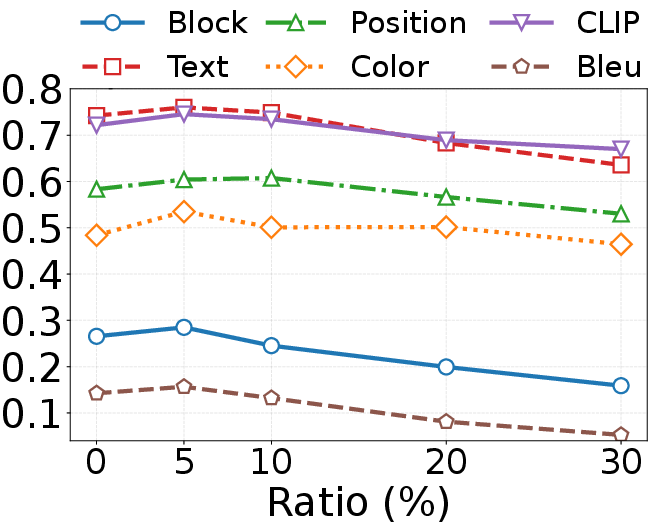
Figure 6: Inference time under different $\lambda$ and $r$.
Ablation and Parameter Studies
Ablation experiments confirm that each module (ELTC, RTR, ADTS) contributes positively to performance and efficiency, with the full combination yielding optimal results. Parameter sweeps show that moderate suppression steps ($s=3$) and decay factors ($\lambda=0.5$) best balance redundancy penalization and output quality. The refinement ratio $r$ is optimal at 5–10%, and adding more tokens from unselected regions yields diminishing returns (Figures 7, 8, 10).
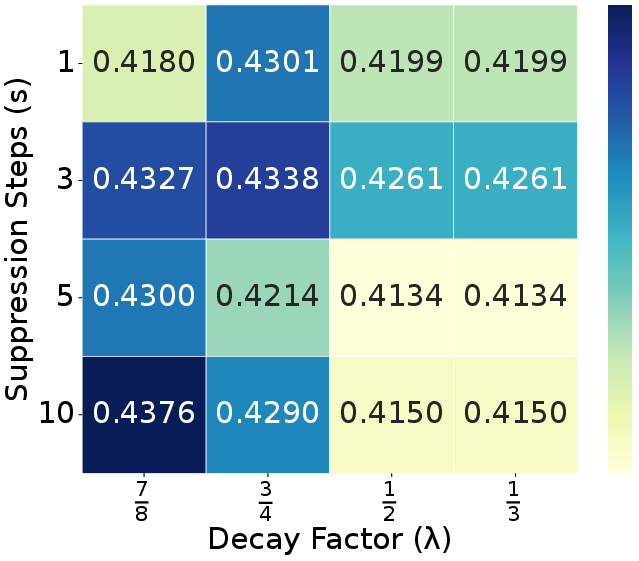
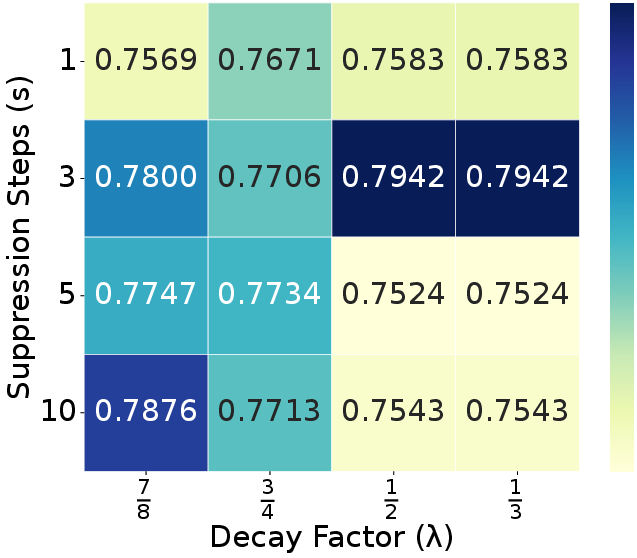
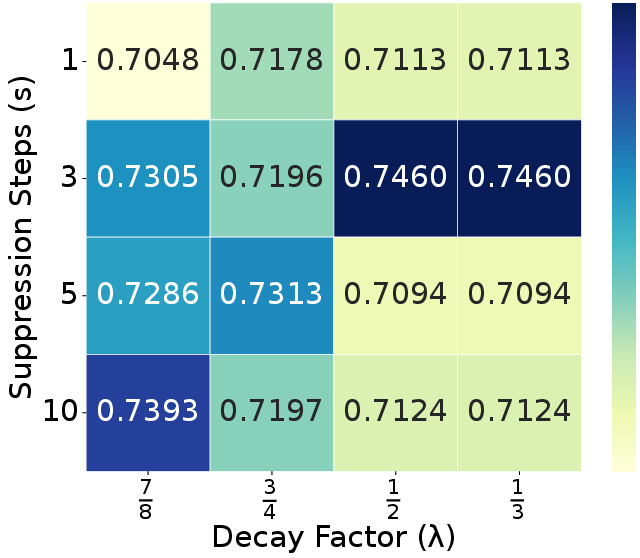
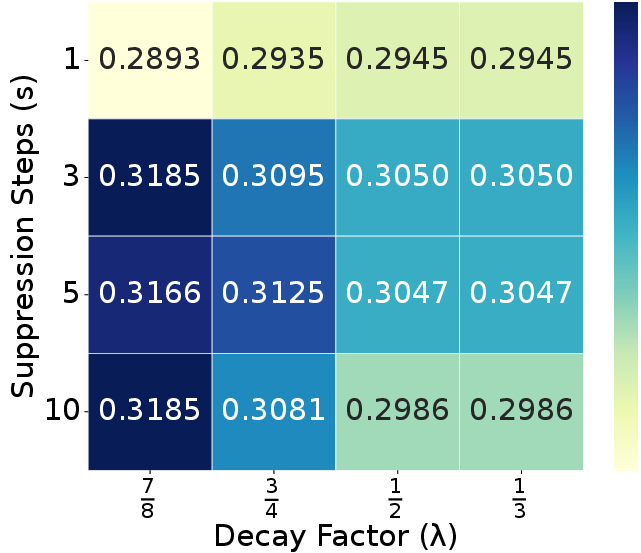
Figure 7: Suppression step $s$ and decay factor $\lambda$ analysis on Design2Code datatset.
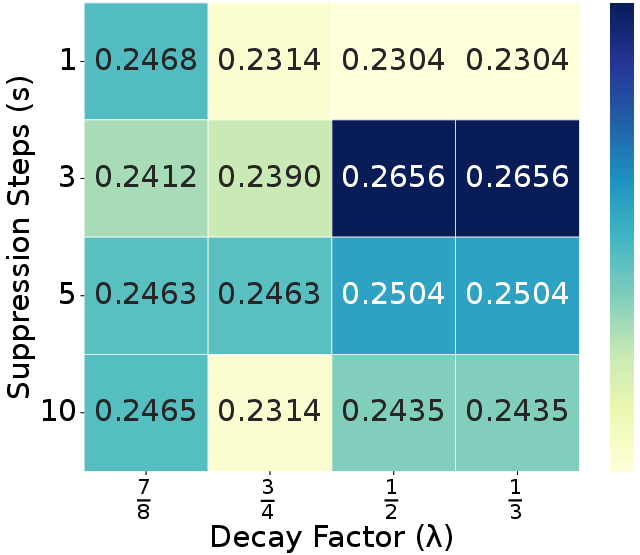
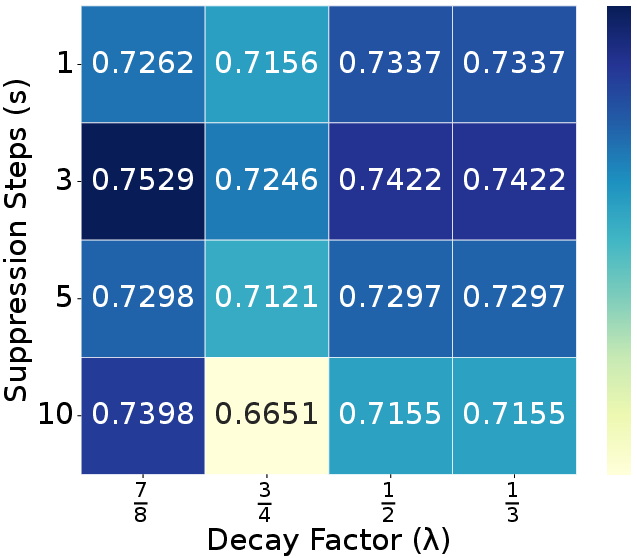
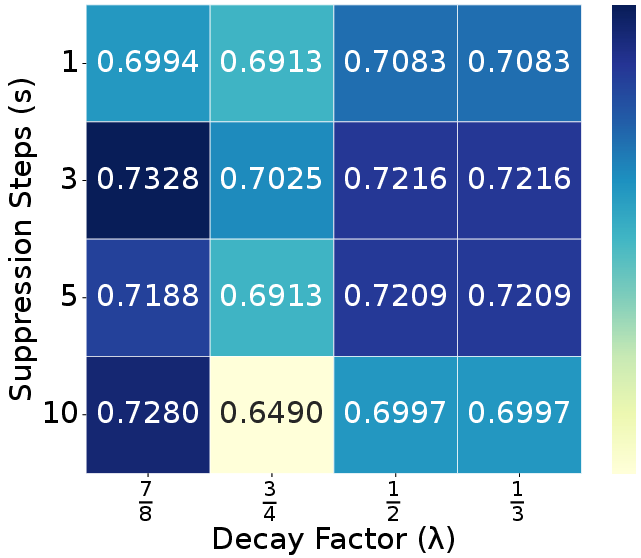

Figure 8: Suppression step $s$ and decay factor $\lambda$ analysis on WebCode2M datatset.
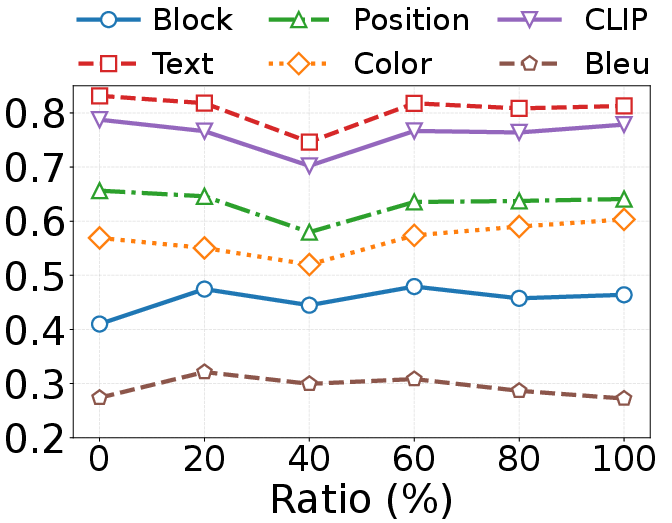
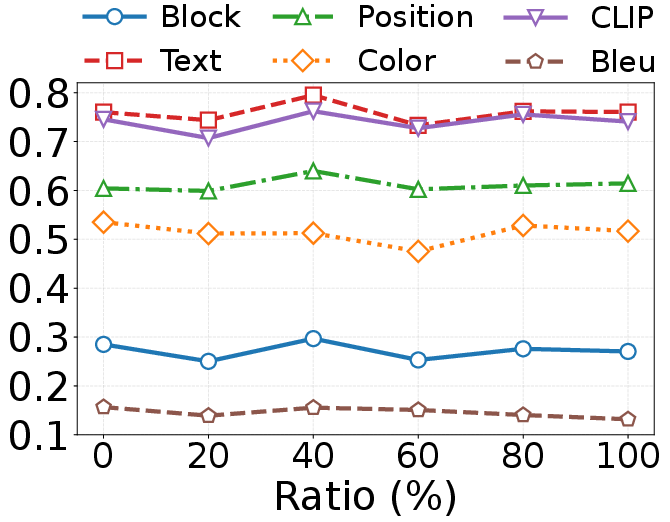
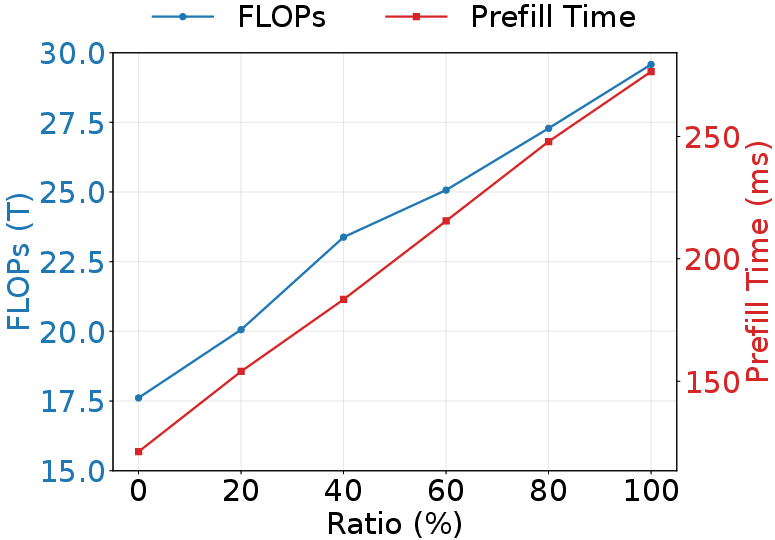
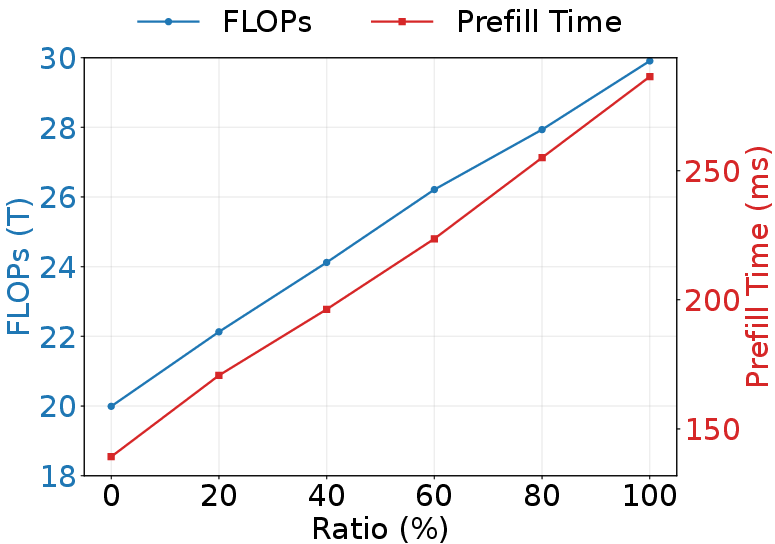
Figure 9: The performance and efficiency on two datasets when adding unselected token. D2C denotes Design2Code and WC2M denotes WebCode2M.
Case Studies
Qualitative analysis demonstrates that EfficientUICoder reliably selects tokens covering all critical UI elements, avoids background redundancy, and prevents cyclical code generation. In contrast, baseline methods either omit essential components or generate excessive duplicates, resulting in incomplete or invalid webpages (Figures 11, 12).

Figure 10: Case study of webpages generated by Vanilla, EfficientUICoder and VisionZip.
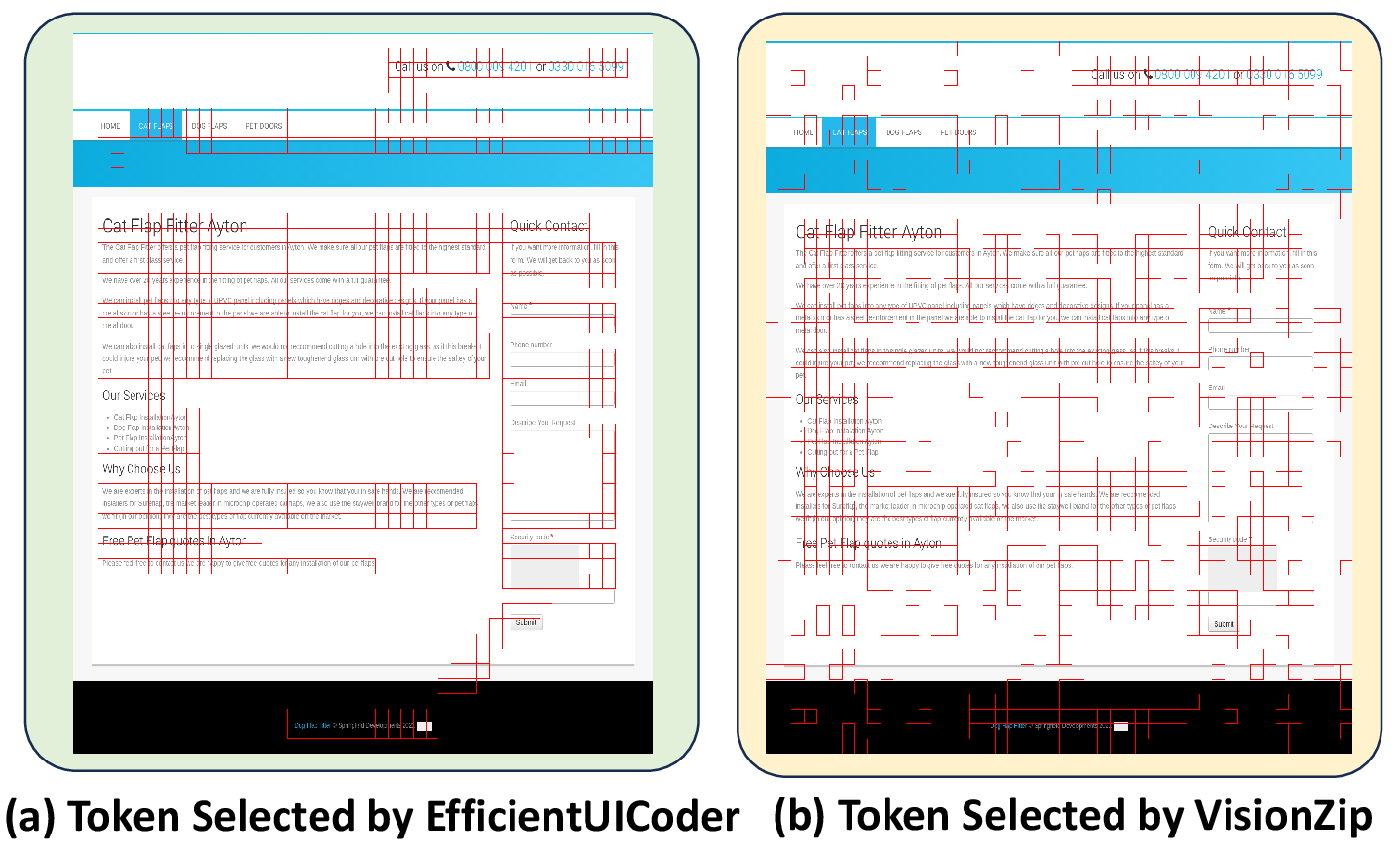

Figure 11: Token selection results.
Implementation Considerations
EfficientUICoder requires access to the visual encoder's attention maps and the ability to modify both encoding and decoding stages of the MLLM. This restricts deployment to open-source models (e.g., Llava-v1.6) rather than commercial black-box APIs. The framework is compatible with standard UI element detection tools and can be integrated into existing MLLM pipelines with moderate engineering effort. Resource requirements scale with model size, but the compression modules substantially mitigate memory and compute bottlenecks.
Implications and Future Directions
EfficientUICoder establishes that bidirectional token compression—jointly optimizing input and output redundancy—can dramatically improve the efficiency and reliability of MLLM-based UI2Code systems. The approach is extensible to other multimodal code generation tasks (e.g., slide, poster, or app synthesis) and can be adapted for real-time or resource-constrained deployment scenarios. Future work may explore adaptive compression strategies conditioned on design complexity, integration with commercial MLLMs as APIs evolve, and further refinement of redundancy detection via learned or self-supervised methods.
Conclusion
EfficientUICoder provides a principled, empirically validated solution to the computational challenges of MLLM-based UI code generation. By combining element/layout-aware token selection, attention-guided refinement, and dynamic output suppression, it achieves high compression ratios and efficiency gains without sacrificing output fidelity. The framework advances the state of the art in multimodal code generation and offers a robust foundation for scalable, practical deployment in web development automation.

