Text or Pixels? It Takes Half: On the Token Efficiency of Visual Text Inputs in Multimodal LLMs
Abstract: LLMs and their multimodal variants can now process visual inputs, including images of text. This raises an intriguing question: can we compress textual inputs by feeding them as images to reduce token usage while preserving performance? In this paper, we show that visual text representations are a practical and surprisingly effective form of input compression for decoder LLMs. We exploit the idea of rendering long text inputs as a single image and provide it directly to the model. This leads to dramatically reduced number of decoder tokens required, offering a new form of input compression. Through experiments on two distinct benchmarks RULER (long-context retrieval) and CNN/DailyMail (document summarization) we demonstrate that this text-as-image method yields substantial token savings (often nearly half) without degrading task performance.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple question: If a LLM can read images, can we save time and money by showing it a picture of the text instead of giving it the text directly? The authors test turning long passages of text into a single image and feeding that to multimodal LLMs (models that understand both text and images). They find that this “text-as-image” trick can cut the number of tokens the model has to process by about half while keeping the same quality of answers.
Key Objectives
Here are the main things the researchers wanted to figure out:
- Can multimodal LLMs read text inside images well enough to replace large chunks of text?
- How much “compression” (token reduction) can we get without hurting accuracy?
- Does this approach speed up model responses or slow them down?
- How does text-as-image compare to other popular compression methods?
Methods and Approach
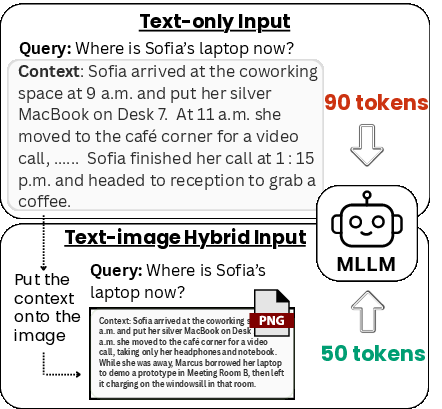
Think of a LLM as a very fast reader that reads in tiny pieces called “tokens.” The more tokens you feed it, the more time and money it takes. The idea here is to swap some of those text tokens for “visual tokens” by turning the text into an image.
What they did:
- They took long text passages (like articles or distractor paragraphs).
- They rendered each passage as a single, neat image (like a screenshot of a page).
- They gave the model two inputs: 1) A short text query (the question or instruction), 2) The image containing the long text.
- The model’s vision part (the “vision encoder”) reads the image and turns it into a smaller number of visual tokens. Then the language part (the “decoder”) uses those tokens plus the short query to produce an answer.
Two kinds of tests:
- Long-context retrieval (RULER “needle-in-a-haystack”): The model must find a specific number hidden in a lot of distracting text. This checks if it can handle long inputs and still find the right detail.
- Document summarization (CNN/DailyMail): The model summarizes news articles. This checks whether the model can handle the content and produce a good summary after compression.
Models tested:
- GPT-4.1-mini (multimodal)
- Qwen2.5-VL-72B-Instruct (open-weight, multimodal)
They measured:
- Accuracy (did the model get the right answer?)
- Token count (how many tokens did the decoder process?)
- Speed (how long did it take end-to-end?)
In simple terms: It’s like taking a photo of a long page and letting the model “scan” it, so it doesn’t have to “read” every word token-by-token. The photo gets compressed into fewer visual tokens, cutting the load on the model’s text processing.
Main Findings
- Big token savings without hurting accuracy:
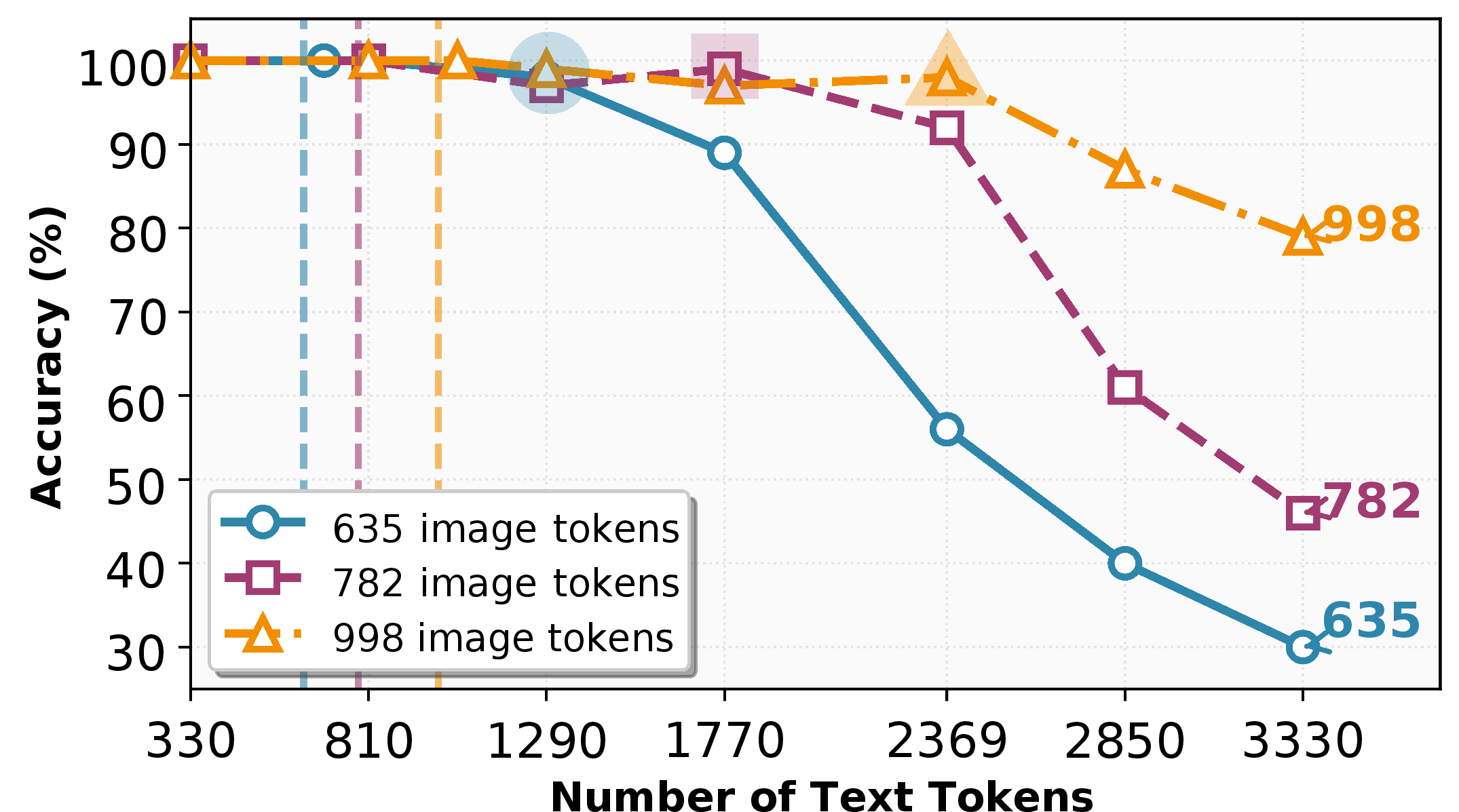
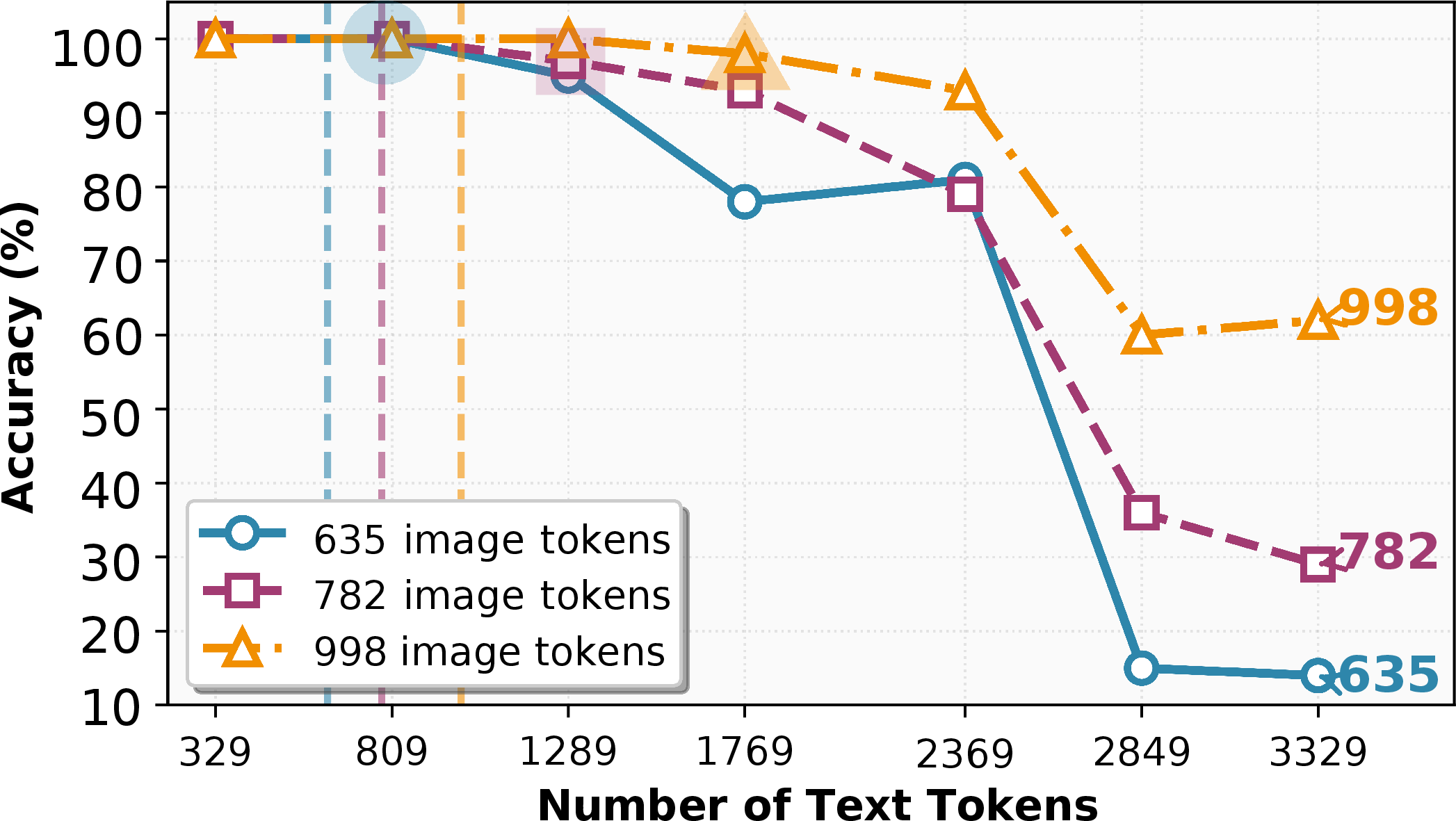
- On the RULER retrieval task, feeding the text as an image often reduced decoder tokens by about 42–58% while keeping accuracy very high (about 97–99%).
- In other words, they could often cut the input in half and still get the same performance.
- Predictable “safe compression”:
- There’s a limit to how much text you can compress into an image before accuracy drops. Across models, the safe zone was roughly a 2× compression (half the tokens), and this limit grows when you allow more visual tokens (bigger or more detailed images).
- Speed improvements on large models:
- For the large Qwen2.5-VL-72B model, processing shorter decoder sequences led to 25–45% faster inference overall, even with the extra step of image processing.
- For GPT-4.1-mini, the image step added a small overhead, but the token savings were still substantial.
- Better than popular pruning baselines at the same compression:
- On CNN/DailyMail summarization, the text-as-image approach outperformed two well-known token-pruning methods (Select-Context and LLMLingua-2) on standard quality metrics (like ROUGE and BERTScore), while keeping similar or greater compression rates (~40% of tokens kept).
Why This Matters
- Cost and speed: LLM APIs often charge per token, and longer inputs slow everything down. Replacing chunks of text with an image can lower cost and improve throughput.
- No retraining needed: This trick works “out of the box” with existing multimodal models—no fine-tuning or extra training is required.
- Plays well with other methods: You can still use traditional text compression techniques and then render the result as an image for even more savings.
- Broad applications: Long emails, reports, or chats could be handled more efficiently. It might also help in areas where pruning is hard because most of the text is important (like math or legal passages).
In short, the paper shows a simple, practical idea: give models pictures of text. When done right, it can cut token usage by about half, keep accuracy high, and even speed up processing on larger systems. This opens a new path for making long-context tasks more affordable and faster, encouraging future work to mix visual compression with existing text-based tricks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed as concrete directions future work can act on.
- External validity across tasks: Evaluate text-as-image compression on tasks beyond retrieval and news summarization, including multi-hop QA, open-book QA, fact verification, mathematical reasoning (LaTeX-heavy), code understanding/generation (exact copying and syntax), table extraction, translation, and long-form dialogue.
- Extreme context scaling: Test the approach on document sets and histories spanning tens to hundreds of thousands of tokens, requiring multi-image inputs and/or retrieval-chunking, and quantify accuracy, latency, and throughput at these scales.
- Exactness-sensitive outputs: Measure fidelity on tasks that require verbatim copying (quotes, IDs, code, citations), substring localization, and regex-style extraction, where OCR-like misreads or formatting changes can cause failures.
- Multilingual and script diversity: Assess robustness across scripts (CJK, Arabic, Devanagari), right-to-left layouts, diacritics, mixed scripts, and low-resource languages to determine compression limits outside English.
- Real-world document robustness: Stress-test with scanned PDFs, camera photos, low DPI, compression artifacts, skew, noise, watermarks, low contrast, and handwriting; quantify accuracy vs. degradation.
- Layout and reading-order sensitivity: Systematically study multi-column layouts, footnotes, sidebars, tables, figures, page headers/footers, hyphenation, and wrapped lines to ensure the model reads in the intended order without content omission.
- Math, tables, and code rendering: Benchmark special content types (equations, chemical formulas, tables, code blocks, diagrams) to determine required resolutions and rendering choices that preserve semantics.
- Resolution vs. visual-token budget scaling: Provide a fuller sweep over font sizes, line spacing, image widths/heights, and DPI to derive a scaling law for accuracy as a function of text density and visual tokens k, and learn adaptive policies that select resolution per document.
- Single- vs. multi-image trade-offs: Compare one large image to multiple paginated images for very long inputs; study how splitting affects k, reading order, memory footprint, and performance.
- Vision encoder design ablations: Evaluate different vision encoders, patch sizes, pooling strategies, and projection heads, and quantify how architectural choices change text-token tolerance m⋆ and compression ratio ρ.
- Visual token compression: Combine with visual-token compression methods (e.g., pooling, token pruning, TokenCarve-like approaches) and measure end-to-end accuracy, latency, and memory impacts.
- Joint with text pruning/RAG: Empirically test stacking text pruning before rendering and/or integrating retrieval (RAG) to quantify additive gains and routing policies for when to use pixels vs. text.
- Latency/throughput profiling: Provide fine-grained profiling (encode/kv-cache/decoding time), GPU memory, batch size effects, and server-side concurrency to identify regimes where vision overhead is amortized.
- Cost accounting and pricing: Conduct a cost-per-query analysis that reflects actual API pricing for images vs. tokens and on-prem compute cost (FLOPs, energy), rather than relying only on decoder-token counts.
- Standardized token/compute metrics: Align token accounting across models (API-reported vs. internal embeddings), and report compute-normalized metrics (e.g., KV cache size, attention FLOPs) for apples-to-apples comparisons.
- Baseline coverage and strength: Compare against stronger and more diverse compressors (e.g., LongLLMLingua, RECOMP, xRAG/one-token, RefreshKV variants, 500xCompressor), including learned abstractive and hybrid approaches at matched compression ratios.
- Human evaluation and faithfulness: Add human judgments and factual consistency checks (entity-level faithfulness, QA-based faithfulness) to complement ROUGE/BERTScore and detect subtle content loss introduced by imaging.
- Failure-mode analysis: Catalog and quantify common errors (digit transpositions, punctuation loss, hyphenation errors, column misreads, table misalignment), and identify rendering configurations that mitigate them.
- Safety and adversarial risks: Test susceptibility to cross-modal prompt injection, steganographic instructions, adversarial patches, and policy-evasion via images; propose and evaluate mitigations.
- Privacy and compliance: Analyze whether converting sensitive text to images affects PII redaction, logging, watermarking, data retention, and filter efficacy; provide guidelines for secure deployment.
- Fine-tuning potential: Explore instruction tuning or lightweight adaptation of the vision-LLM connector to improve text-in-image reading fidelity and push compression beyond the observed ~2× without accuracy loss.
- Theoretical understanding: Develop a model of why ~half the decoder tokens can be saved (e.g., capacity allocation between vision encoder and decoder, information density of visual tokens) and predict m⋆ as a function of k and model size.
- Integration with long-context mechanisms: Study interactions with long-context architectures (e.g., local/global attention, retrieval heads, streaming/KV refresh) to jointly optimize compute and accuracy.
- Output-length effects: Measure impacts when generating long outputs (reports, code files) where decoder-side compute dominates, and evaluate whether image-based inputs change generation stability or repetition.
- Reproducibility and closed-model variance: Mitigate reliance on proprietary models/API token counters by releasing standardized evaluation harnesses, seeds, and open-source replications; report variance across model versions.
- Renderer and stylesheet dependence: Test alternate renderers (HTML/CSS screenshots, browser screenshots), styles, and fonts to see how rendering choices affect k, readability, and performance.
- Ordering and referencing: Evaluate tasks requiring page/section references, citations, or figure/table cross-references to ensure that image-based contexts preserve navigability and grounding.
Practical Applications
Overview
The paper demonstrates a simple, deployable way to cut decoder token usage by roughly 40–60% in multimodal LLMs: render long text context as a single image, pass that image plus a short textual query to the model, and let the vision encoder produce compact visual tokens for the language decoder. Across retrieval (RULER) and document summarization (CNN/DailyMail), this “text-as-image” compression preserved accuracy and often improved end-to-end latency on large decoders without any fine-tuning. The approach is model- and task-agnostic, uses off-the-shelf MLLMs, and can serve as an implicit compression layer.
Below are actionable applications derived from the findings, grouped by immediacy, with sector links, potential tools/workflows, and assumptions/dependencies.
Immediate Applications
These can be implemented now with existing multimodal LLMs and a text-to-image rendering pipeline.
- Token-efficient chat assistants and conversation memory compression
- Sector: software, customer support, education
- Workflow/product: a “context manager” that renders prior conversation turns into an image and keeps the latest user query in text; injects the image + query to GPT-4-Vision/Qwen-VL for response generation.
- Why now: ~2× reduction in decoder tokens with comparable accuracy; reduced latency on large decoders; no model changes required.
- Assumptions/dependencies: requires a multimodal model that reliably reads text in images; rendering quality (font size, resolution) must preserve legibility; provider billing for visual tokens must be cost-effective; privacy controls for PII in images.
- News and enterprise document summarization at lower cost
- Sector: media, enterprise knowledge management, education
- Workflow/product: a summarization microservice that converts long articles/reports into a single image and uses an MLLM to produce summaries; integrates with CMS or document pipelines.
- Why now: matched compression rates outperform token-pruning baselines (ROUGE/BERTScore) while cutting token count by ~60%.
- Assumptions/dependencies: consistent rendering (e.g., LaTeX → rasterization at ~300 dpi), visual token budget tuned to ~½ text-token cost; fallback to text-only mode for very long documents (multi-page).
- Legal/compliance triage and clause/number retrieval (“needle-in-a-haystack”)
- Sector: legal, policy, compliance
- Workflow/product: a triage tool that ingests long contracts/regulations as an image and answers targeted queries (e.g., clause identification, numeric thresholds); supports visual highlighting of found items.
- Why now: RULER-style retrieval shows 97–99% accuracy with up to ~58% fewer decoder tokens.
- Assumptions/dependencies: legible layout preservation (small fonts may require higher-resolution images); extremely long documents need chunking or tiling; audit logs must capture image inputs.
- Finance research on filings and earnings call transcripts
- Sector: finance, fintech, research
- Workflow/product: a research assistant that compresses transcripts/10‑Ks/10‑Qs as images and supports Q&A and summarization with reduced token costs; integrates with existing ETL pipelines.
- Why now: same compression benefits apply to long textual financial contexts; cost savings accrue on per-token billing.
- Assumptions/dependencies: robust multimodal model performance on dense text; compliance and data governance for sensitive inputs; provider-specific pricing on visual tokens.
- Healthcare clinical note summarization (on-prem)
- Sector: healthcare
- Workflow/product: an on-prem summarization service using open-weight multimodal models (e.g., Qwen2.5-VL) that renders clinical notes to images for token-efficient summarization.
- Why now: latency gains on larger decoders with meaningful token reduction; privacy-preserving local deployment feasible.
- Assumptions/dependencies: HIPAA/GDPR compliance; domain validation for medical accuracy; rendering tuned to clinical note formats; image-based prompts must be logged and access-controlled.
- OCR-less document understanding for scanned or screenshot inputs
- Sector: enterprise content processing, digital transformation
- Workflow/product: ingest scanned PDFs or screenshots directly into multimodal LLMs (no separate OCR), using the image as the compressed context plus a textual query.
- Why now: models already read text in images; reduces pipeline complexity and token count simultaneously.
- Assumptions/dependencies: image quality (noise, skew) affects comprehension; fallback OCR when scans are poor; confirm provider capability to count and handle visual tokens efficiently.
- RAG pipeline optimization with visual passages
- Sector: software, AI platforms
- Workflow/product: a RAG orchestrator that routes retrieved passages to rendering-as-image when token budgets are tight, keeping only the user query and key instructions in text.
- Why now: orthogonal to retrieval and token-dropping; practical additive savings without fine-tuning.
- Assumptions/dependencies: multi-image prompts may increase visual token budget; careful chunking/selection to avoid excessive k; benchmark routing policies for different tasks.
- Cost/latency controls in LLM operations
- Sector: AIOps, platform engineering
- Workflow/product: a “visual prompt compression” SDK that auto-switches to text-as-image for long contexts; policy rules to stay within budgets and reduce latency on large decoders.
- Why now: paper shows up to ~45% end-to-end speedups on larger models; predictable compression ratio around 2×.
- Assumptions/dependencies: vendor pricing for images/visual tokens; small-model overhead may negate wins; monitoring required to ensure accuracy parity at chosen resolutions.
Long-Term Applications
These require further research, scaling, model adaptation, or ecosystem changes.
- Adaptive visual compression layer integrated into LLM frameworks
- Sector: software, LLM infrastructure
- Product: a library/plugin for vLLM/LLM servers that auto-renders context to images with dynamic resolution, learns per-model k↔m* tolerance, and optimizes latency/accuracy trade-offs.
- Research needs: adaptive resolution selection; legibility scoring; per-architecture visual token budgeting; auto-tuning on new tasks.
- Hybrid compression stacking (text pruning + visual rendering + xRAG)
- Sector: software, AI platforms
- Product: a modality router that decides for each span whether to keep text, prune, embed (xRAG), or render as image, targeting maximal compression with minimal loss.
- Research needs: routing criteria and meta-controllers; compounding effects on accuracy/latency; cross-task generalization.
- Extreme long-context, multi-page document reasoning
- Sector: legal, government, enterprise archives
- Product: a “pagerized” visual context system that tiles tens of thousands of tokens across pages, supports cross-page references, and maintains indexable anchors.
- Research needs: efficient multi-image attention; memory management; cross-page retrieval and reasoning strategies; evaluation at 10k–100k+ token scales.
- Domain-specific visual reading enhancements (math, code, tables)
- Sector: education, software engineering, data analytics
- Product: fine-tuned MLLMs that read complex typeset math, code snippets, and dense tables from images without performance degradation, enabling sizable token savings.
- Research needs: curated datasets of domain text-as-image; architecture tweaks for layout and syntax fidelity; evaluation vs. text-only baselines.
- “LLM-ready PDF” standards and rendering guidelines
- Sector: publishing, tooling, document platforms
- Product: best-practice templates (fonts, spacing, line-length, contrast, anchors) that maximize readability and compression when consumed by MLLMs via images.
- Research needs: standardized metrics relating layout to visual token efficiency; interoperability with accessibility (alt-text) and archival needs.
- Security and compliance for image-based prompts
- Sector: security, compliance
- Product: image content scanning for sensitive information, watermarking, and prompt-injection detection in images; governance policies for visual inputs.
- Research needs: detection models for image-embedded malicious instructions; auditability of image prompts; redaction tooling for visual content.
- Sustainability policy and compute efficiency incentives
- Sector: policy, energy, cloud providers
- Product: guidelines and incentives for modality shifting (text→image) to reduce compute and emissions in long-context workloads; standardized reporting.
- Research needs: lifecycle assessments quantifying energy savings per compression strategy; public benchmarks; collaboration with cloud vendors.
- Pricing and billing models for visual tokens
- Sector: cloud/AI providers, finance
- Product: standardized per-visual-token billing and cost calculators that reflect actual decoder savings; enterprise contracts including “visual compression” clauses.
- Research needs: transparent tokenization accounting for images; cross-provider comparability; customer education and procurement integration.
Glossary
- BERTScore: A metric that evaluates the quality of generated text by comparing contextual embeddings from a pretrained LLM. "Summary quality is evaluated with ROUGE \citep{lin-2004-rouge} and BERTScore \citep{zhang2020bertscoreevaluatingtextgeneration}."
- Compression ratio: The proportion by which input tokens are reduced when using an alternative representation, defined as ρ = (text tokens)/(image tokens). "A higher indicates greater token savings."
- Decoder tokens: The tokens consumed by the LLM’s decoder during inference, determining compute and cost. "This leads to dramatically reduced number of decoder tokens required, offering a new form of input compression."
- Dense embedding token: A single high-dimensional vector that encodes an entire document, used to compress context for generation. "Extreme Retrieval-Augmented Generation (xRAG) replaces full documents with one dense embedding token, achieving a compression ratio without fine-tuning the LM~\citep{cheng2024xrag}."
- Hybrid text-vision prompting: Supplying instructions partly as text and partly as images to a multimodal model. "Our work also relates to the concept of hybrid text-vision prompting, where instructions are given partially in text and partially as an image \citep{aggarwal2025programmingpixelscomputerusemeets}."
- Instruction-Aware Contextual Compression (IACC): A method that filters retrieved passages based on the user query to reduce context length while maintaining accuracy. "Instruction-Aware Contextual Compression (IACC) filters noisy RAG passages based on the user query, halving context length while retaining QA accuracy~\citep{hou2024iacc}."
- LaTeX-based typesetting pipeline: A rendering process that formats text into pages/images while preserving layout and line breaks. "using a LaTeXâbased typesetting pipeline that preserves the layout and lineâbreaks of the original text (see Figure~\ref{fig:img_pipeline})."
- Latency: The time taken to process and generate outputs end-to-end. "End-to-end latency."
- LLMLingua-2: A learned token-level compression model that predicts whether to keep or drop each token. "(2) LLMLingua-2~\citep{pan-etal-2024-llmlingua}: trains a Transformer encoder to predict, token by token, whether to retain or discard."
- Long-context retrieval: Tasks that require finding specific information within very long inputs. "RULER S-NIAH long-context retrieval accuracy, text-as-image compression statistics, and model latency."
- Multimodal LLM (MLLM): A LLM that can process multiple input modalities, such as text and images. "One novel avenue for input compression is to leverage the ability of multimodal LLMs (MLLMs) \citep{liu2023visual, fang2024uncertainty} to read text from images."
- Needle-in-a-haystack: A retrieval setting where a single relevant item is hidden among many distractors. "We evaluate our text-as-image compression strategy on the RULER S-NIAH (single needle-in-a-haystack) task \citep{hsieh2024rulerwhatsrealcontext}, where a single target number (needle) is hidden in a long distractor passage (haystack)."
- pdflatex: A LaTeX engine that compiles documents into PDF, used here to render text before image rasterization. "All text-as-image rendering is performed with pdflatex followed by rasterization at 300~dpi."
- Projection layer: A mapping (often linear) that transforms visual embeddings into a form suitable for the language decoder. "These embeddings are passed through a projection layer (e.g., a linear map) and become part of the language decoderâs input"
- Rasterization: Converting vector or PDF content into a pixel-based image at a specified resolution. "All text-as-image rendering is performed with pdflatex followed by rasterization at 300~dpi."
- Retrieval-Augmented Generation (RAG): A framework where external documents are retrieved and fed to an LLM to improve generation quality and efficiency. "Retrieval Augmented Generation (RAG) has been a powerful tool for LLMs to efficiently process overly lengthy contexts."
- ROUGE: A set of metrics for summarization quality based on n‑gram overlap between generated and reference texts. "Summary quality is evaluated with ROUGE \citep{lin-2004-rouge} and BERTScore \citep{zhang2020bertscoreevaluatingtextgeneration}."
- RULER: A long-context benchmark that tests models’ retrieval and reasoning over extended inputs. "Through experiments on two distinct benchmarksâRULER (long-context retrieval) and CNN/DailyMail (document summarization)âwe demonstrate that this text-as-image method yields substantial token savings (often nearly half) without degrading task performance."
- Select-Context: A token-pruning method that retains tokens with high estimated self-information. "(1) SelectâContext~\citep{li-etal-2023-compressing}: keeps tokens whose self-information (estimated by a small LLM) exceeds a learned threshold."
- Self-attention: The mechanism in Transformers that computes pairwise token interactions; its complexity scales quadratically with sequence length. "the self-attention mechanism's complexity scales quadratically with the input length~\citep{vaswani2017attention}."
- Text-as-image: The practice of rendering text as an image for input to a multimodal model to reduce decoder tokens. "we demonstrate that this text-as-image method yields substantial token savings (often nearly half) without degrading task performance."
- Text-token tolerance: The maximum text length that can be compressed into visual tokens without measurable accuracy loss. "The text-token tolerance (largest within 3 points of the text-only baseline) is shaded in the plots and reported in Table~\ref{tab:nihs_accuracy}."
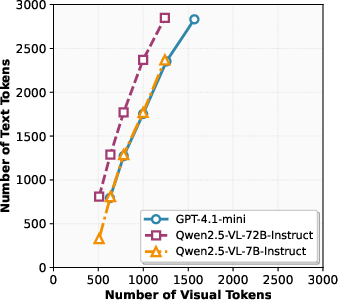
- Token budget: The total number of input tokens provided to the model under a given prompting scheme. "The corresponding token budget is"
- Token pruning: Techniques that remove less informative tokens from the input to reduce cost while aiming to preserve performance. "We compare our approach against two widely used tokenâpruning techniques that operate purely in the text modality:"
- Throughput: The rate at which inputs can be processed, influencing deployment efficiency and cost. "deploying LLMs at scale (e.g., in chat assistants or document analysis) is constrained by throughput and cost per token~\citep{palm540b2022,duoattention2024,refreshkv2025, li2025chunk}."
- Vision encoder: The neural module that converts images into a sequence of visual embeddings/tokens for the LLM. "the vision encoder produces a compact set of visual tokens for the decoder, directly reducing sequence length without fine-tuning or supervision."
- Visual budget: The number of visual tokens available to the decoder, which governs how much text can be compressed into an image. "Larger visual budgets () increase tolerance to over 2{,}300 tokens while still saving 42â58\% of the decoder context."
- Visual tokens: Discrete embeddings produced from images that the LLM decoder consumes similarly to text tokens. "so it processes just 50 visual tokens as input to the LLM decoderâcutting token usage by nearly half"
- Wall-clock time: The actual elapsed time to run inference, used to measure practical latency and speedups. "throughput and latency (wall-clock time per example)."
Collections
Sign up for free to add this paper to one or more collections.