From User Interface to Agent Interface: Efficiency Optimization of UI Representations for LLM Agents
Abstract: While LLM agents show great potential for automated UI navigation such as automated UI testing and AI assistants, their efficiency has been largely overlooked. Our motivating study reveals that inefficient UI representation creates a critical performance bottleneck. However, UI representation optimization, formulated as the task of automatically generating programs that transform UI representations, faces two unique challenges. First, the lack of Boolean oracles, which traditional program synthesis uses to decisively validate semantic correctness, poses a fundamental challenge to co-optimization of token efficiency and completeness. Second, the need to process large, complex UI trees as input while generating long, compositional transformation programs, making the search space vast and error-prone. Toward addressing the preceding limitations, we present UIFormer, the first automated optimization framework that synthesizes UI transformation programs by conducting constraint-based optimization with structured decomposition of the complex synthesis task. First, UIFormer restricts the program space using a domain-specific language (DSL) that captures UI-specific operations. Second, UIFormer conducts LLM-based iterative refinement with correctness and efficiency rewards, providing guidance for achieving the efficiency-completeness co-optimization. UIFormer operates as a lightweight plugin that applies transformation programs for seamless integration with existing LLM agents, requiring minimal modifications to their core logic. Evaluations across three UI navigation benchmarks spanning Android and Web platforms with five LLMs demonstrate that UIFormer achieves 48.7% to 55.8% token reduction with minimal runtime overhead while maintaining or improving agent performance. Real-world industry deployment at WeChat further validates the practical impact of UIFormer.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
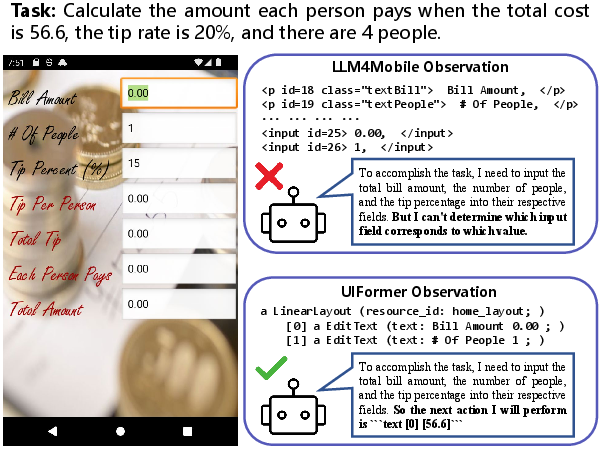
This paper looks at how to make AI “app helpers” faster and cheaper to run. These helpers use LLMs to look at app screens (like Android or web pages), understand them, and decide where to click or type. The problem is: the way the app’s screen is described to the AI uses a huge amount of text (called “tokens”). In fact, 80–99% of the AI’s reading is just the screen description! The paper introduces UIFormer, a method that shrinks these screen descriptions while keeping all the important meaning, so the AI can still do its job well but with far fewer tokens.
What the researchers wanted to find out
Here are the main questions they set out to answer:
- Can we cut down the amount of text (tokens) used to describe app screens without losing important information the AI needs?
- How do we do that automatically, even for very complicated screens made of many nested parts?
- Can this work across different platforms (Android and Web), different AI agents, and different LLMs?
- Will reducing tokens actually make the overall system faster and cheaper, while keeping or improving success rates on real tasks?
How they approached the problem (in simple terms)
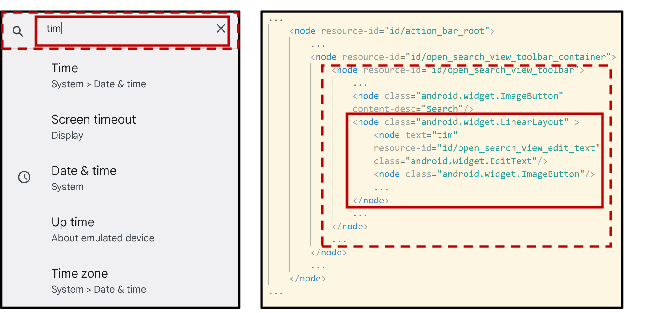
Think of an app screen like a very detailed tree diagram (a “UI tree”), with boxes inside boxes: a button inside a toolbar inside a container, and so on. While users see one simple search box, the UI tree might have 8–12 technical parts to draw it, position it, handle clicks, and style it. Many of those parts are helpful to developers but not necessary for the AI to understand what’s on the screen.
The challenge: We want to automatically turn this big tree into a simpler version that keeps what matters (like “Search” text and “this is a button”) but removes extra layers. Doing this well is tricky because:
- There isn’t a simple yes/no test to tell if the transformation is “correct.” We need to balance two goals at the same time: keep the meaning and reduce tokens.
- The tree can be huge, and writing a long, perfect “transformation program” by guessing is error-prone.
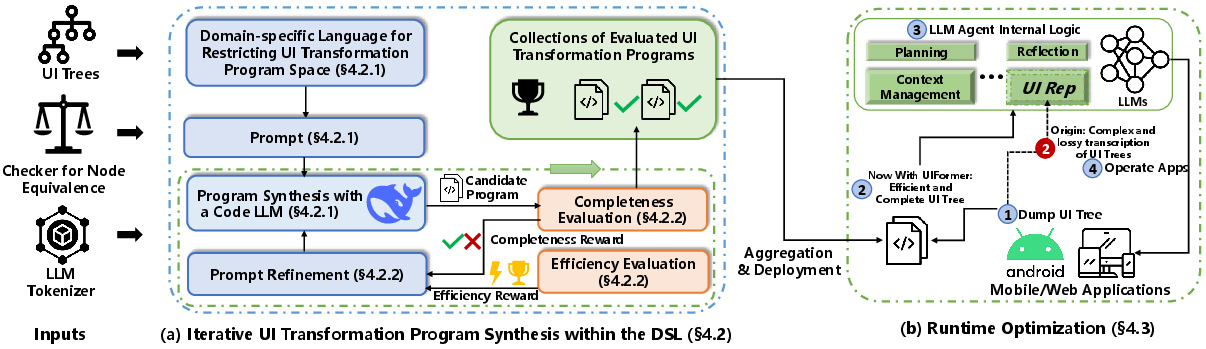
Their solution, UIFormer, works in two phases:
1) Offline: Teach the AI to write the transformation rules
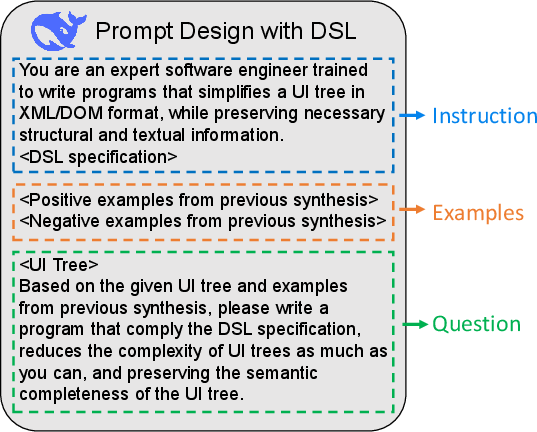
- They use a special mini-language (a “DSL,” or domain-specific language), which is like giving the AI a small toolkit with safe, screen-specific actions. This keeps it from doing wild or risky changes.
- In this toolkit, the AI can:
- Filter out unimportant parts (like purely decorative items).
- Merge multiple small pieces into one meaningful element (like combining parts of a search bar).
- Pass things through unchanged when needed.
- The AI creates candidate transformation programs, tries them, and gets feedback scores on two things:
- Completeness: Did it keep the important meaning and relationships on the screen?
- Efficiency: How many tokens did it cut?
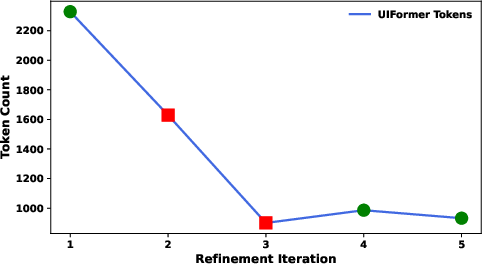
- It repeats and improves (iterative refinement) until it produces a library of good, reusable transformation programs.
2) Runtime: Use those rules like a plug-in
- When an AI agent asks for the screen, UIFormer intercepts the raw UI tree, applies the learned transformations, and passes a simpler, still-meaningful version to the agent.
- It works like a drop-in plug-in, so you don’t have to rewrite the agent.
What they found (and why it matters)
Key results:
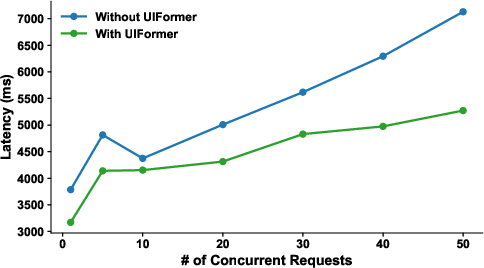
- UIFormer cut tokens by about half (48.7% to 55.8%) across different tests, with almost no runtime delay (about 5.7 milliseconds on average to transform a screen).
- Despite reducing tokens, it kept or even improved the AI’s ability to finish tasks. On both Android apps and websites, agents using UIFormer often had higher success rates.
- It worked with multiple LLMs (like GPT-4o, DeepSeek, Qwen) and different agent frameworks (ReAct, AppAgent, Mobile-Agent-v2). Improvements were consistent.
- Real-world deployment at WeChat showed strong impact: 35% more queries handled per minute and 26.1% lower latency (faster responses).
Why this is important:
- LLM agents often become expensive and slow because their inputs are huge. Since screen descriptions are the biggest part of the input, shrinking them safely makes everything more practical.
- Better efficiency means you can run more tasks, make assistants more responsive, and scale to more complex apps without breaking the bank.
What this could mean going forward
- App helpers and testing bots could become faster, cheaper, and more reliable using UIFormer-like transformation.
- Developers won’t need to hand-craft simplification rules per app; the system learns reusable programs that adapt across platforms.
- This approach—using a safe mini-language plus iterative feedback—could help in other areas where we need to simplify large, structured data while keeping its meaning (not just UI trees).
- As LLM-based UI agents move from research to real products, token-efficient screen representations will be essential for scaling to millions of users and complex apps.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper presents UIFormer for token-efficient UI representation via DSL-constrained program synthesis with iterative LLM refinement. The following gaps and open questions remain for future research:
- Formal correctness guarantees: The “verified” program library is accepted via heuristic rewards, not formal equivalence. How can we provide provable guarantees that transformations preserve semantics (e.g., preservation of interactability, labels, roles, and navigation reachability) across diverse UIs?
- Completeness evaluation oracles: The paper’s completeness evaluator is only sketched (e.g., −10 penalties for incorrect merges). What concrete, task-agnostic oracles (e.g., accessibility role preservation, interactability checks, layout constraints, action replayability) can reliably detect semantic loss without relying on downstream success rates?
- DSL expressivity vs. safety: The DSL restricts transformations to adjacent parent–child operations, which may miss non-local dependencies (e.g., label–input associations via “for” attributes, ARIA describedby relations, overlay modals, cross-container relationships). How can the DSL be extended to support graph-pattern transformations while controlling search-space explosion and ensuring safety?
- Mapping invariants for action execution: When nodes are merged or filtered, how is the mapping from simplified representation back to actionable selectors (e.g., resource IDs, XPath, ARIA roles) preserved? Formal invariants and automated tests for “representation-to-execution” fidelity are needed.
- Dynamic and temporal UI behavior: The approach operates on static snapshots of accessibility/DOM trees. How does it handle temporally varying states (animations, delayed loads, virtualized lists, sticky headers, popovers, modals)? Can temporal-aware transformations (e.g., multi-frame analysis) mitigate semantic drift?
- Multi-modal agents and visual tokens: Many agents rely on screenshots or vision encoders in addition to the UI tree. How can UIFormer co-optimize text and image tokens, align simplified trees with visual context, and avoid inconsistencies between the transformed tree and the screenshot?
- Accessibility preservation and measurement: Merging or filtering may alter ARIA roles, landmarks, focus order, and content descriptions. How can we ensure accessibility fidelity and evaluate it with accessibility-specific metrics (e.g., role/label preservation rates, screen-reader navigability)?
- Coverage across platforms and UI technologies: Evaluation is limited to Android and Web. How does UIFormer generalize to iOS (UIKit/SwiftUI), desktop platforms (Windows UIA, macOS AX), Electron/React Native, Shadow DOM, canvas/WebGL-heavy pages, and VR/AR interfaces?
- Robustness to adversarial or obfuscated UIs: Can UIFormer detect and resist deceptive structures (e.g., clickjacking overlays, hidden elements, obfuscated DOMs) that could cause unsafe merges or filtering?
- Handling canvas-based and custom-drawn UIs: For UIs rendered primarily via canvases or custom drawing (minimal DOM semantics), what transformation strategies remain viable, and how can semantics be recovered or approximated?
- Cross-page and stateful tasks: Transformations are local to a single tree. How can UIFormer maintain semantic coherence across page transitions, preserve task-relevant context, and ensure consistency for multi-step workflows?
- Tokenizer-specific optimization: Token counts vary by model (e.g., cl100k vs BPE). Can UIFormer adapt transformation choices to specific tokenizers and dynamically tune for the active LLM to maximize cost–performance?
- Reward shaping and sensitivity: Penalties, thresholds, and acceptance criteria are not justified or analyzed. What is the sensitivity of performance to these choices, and can automatic tuning (e.g., bandits, Bayesian optimization) improve stability and outcomes?
- Offline synthesis cost and scalability: The computational cost, time, and energy of iterative refinement are not reported. How does synthesis scale to large program libraries, very large UI trees (e.g., 50k-token DOMs), or frequent UI updates?
- Program library maintenance and concept drift: UIs evolve rapidly. What mechanisms (e.g., automated monitoring, online learning, periodic resynthesis) ensure the program library remains effective and safe as apps and websites change?
- Failure mode analysis: The paper does not categorize where transformations fail (e.g., text loss, interactability breakage, wrong merges). A systematic failure taxonomy and diagnostics would enable targeted improvements.
- Statistical rigor and reproducibility: Results lack confidence intervals/statistical tests and are based on small subsets (Sphinx-Lite 163 tasks, AndroidControl 500 steps, Mind2Web 50 tasks with top-5 candidates). Full-benchmark evaluations, standard protocols, and public release of code/program library are needed.
- Industry deployment metrics: WeChat deployment reports QPM/latency improvements but no error rates or task success impacts. What are reliability, safety, and rollback strategies in production, and how are failures detected and mitigated?
- Interaction with other compression strategies: The work does not compare or combine with structured encodings (e.g., ID-only references, binary/compact formats, delta updates) or prompt-level compression. Can hybrid approaches further reduce tokens without losing semantics?
- Localization and layout semantics: How does UIFormer handle multilingual content, RTL layouts, font-dependent glyph rendering, and spatial relationships (e.g., alignment, grouping)? Can geometric/layout cues be incorporated to avoid merging distinct elements?
- Long-context and history interactions: Reduced per-step tokens may still face context-window limits in long tasks. How do transformations interact with memory strategies (summarization, retrieval) and affect reasoning fidelity over long histories?
- Dependence on strong code LLMs: Program synthesis uses DeepSeek-V3; robustness with smaller/open-source code models is not assessed. What are the minimum model capabilities required, and how does choice of code LLM affect program quality and safety?
- Human-in-the-loop verification: No mechanism is provided to incorporate expert feedback or curated negative examples beyond automatic evaluators. Can minimal human oversight substantially improve completeness and reduce edge-case failures?
- DSL design transparency: The full DSL specification, templates, and property-preservation rules (e.g., which attributes must be retained) are not fully detailed. A formal, public specification would improve reproducibility and enable comparative studies.
- Global compositional guarantees: Local parent–child transformations may interact and cause cascading failures. Can compositional proof techniques or global consistency checks ensure that the cumulative effect preserves overall UI semantics?
- Information-theoretic bounds: The paper motivates efficiency but does not quantify minimal sufficient UI representations for agent performance. Can we formalize and estimate lower bounds on tokens necessary for specific task classes?
- On-device constraints: Runtime overhead is measured on servers; viability on constrained devices (mobile CPUs/NPUs), memory footprint, and integration with real-time interaction loops remain open.
- Benchmark comparability: Using top-5 candidate actions in Mind2Web deviates from standard evaluation settings. How does UIFormer perform under canonical protocols, and can results be directly comparable to prior state-of-the-art?
Practical Applications
Immediate Applications
The following applications can be deployed now based on the paper’s validated findings (48–56% token reduction with maintained or improved task success; WeChat deployment: +35% QPM, −26% latency), the DSL-based synthesis method, and the agent-agnostic plugin design.
- Cost/latency reduction for production LLM GUI agents
- Sectors: software, e-commerce, finance operations, customer support, RPA platforms
- Tools/products/workflows: drop-in “UIFormer” plugin between DOM/accessibility APIs and agent prompts; adapters for Selenium/Playwright/Appium; config to choose per-platform rule libraries; dashboards tracking token budget and QPM/latency
- Assumptions/dependencies: access to DOM/Accessibility trees; agent uses text-based UI representations; safe rollout with A/B testing and rollback; monitoring for semantic regressions
- Scalable automated UI testing in CI/CD
- Sectors: software quality assurance, DevOps, mobile/web app development
- Tools/products/workflows: integrate with test agents (ReAct/AppAgent/Mobile-Agent-V2) in CI; synthesize per-app transformation programs offline from recorded UI traces; enforce “token budget gates” to expand test coverage within fixed spend
- Assumptions/dependencies: stable accessibility/DOM export in test environments; representative training traces for synthesis; fallbacks to raw UI when tests fail
- High-volume web task automation and data ops
- Sectors: web automation, data labeling/scraping, marketplace ops
- Tools/products/workflows: browser extensions that intercept DOM and apply transformations before agent calls; Mind2Web-like flows for form filling, search, and data extraction at lower cost
- Assumptions/dependencies: permission to access DOM; robust handling of virtualized lists, shadow DOM, infinite scroll
- Customer support copilots working across SaaS dashboards
- Sectors: customer support, IT operations, CRM
- Tools/products/workflows: RPA/bot builders add UIFormer as a preprocessing stage; playbooks for repetitive multi-step workflows (refunds, user management) with reduced latency and tokens
- Assumptions/dependencies: consistent UI flows and permissions; transform programs updated as UIs change
- On-device/mobile assistants with lower resource usage
- Sectors: mobile/edge AI, accessibility
- Tools/products/workflows: Android AccessibilityService hooks to apply transformations locally; faster, cheaper app navigation for voice assistants and accessibility agents
- Assumptions/dependencies: local processing allowed; adequate access to the view hierarchy; bilingual/RTL layout handling where relevant
- Accessibility summarization and guidance
- Sectors: accessibility tech, public services
- Tools/products/workflows: generate concise, semantically faithful UI summaries for screen readers; prioritize actionable controls; reduce cognitive load and latency
- Assumptions/dependencies: strict completeness checks in synthesis; careful evaluation with diverse accessibility needs; local processing for privacy
- Security and QA agents for app hardening
- Sectors: security testing, compliance, app vetting
- Tools/products/workflows: broader UI fuzzing/coverage with fixed budgets; integrate with vulnerability detection agents to explore more flows
- Assumptions/dependencies: ensure transformations do not remove security-relevant cues; program libraries kept up to date per app version
- Sustainability and cost reporting for AI ops
- Sectors: enterprise AI operations, cloud cost management
- Tools/products/workflows: token and carbon dashboards highlighting savings from UI optimization; procurement guidance to prefer agents with representation optimization
- Assumptions/dependencies: access to reliable token-to-emissions factors; governance to track savings and set efficiency KPIs
- Academic benchmarking and reproducibility
- Sectors: academia, open-source evaluation
- Tools/products/workflows: publish baselines that control for UI token load; release DSL programs and examples; evaluate co-optimization (efficiency + completeness) across agents/LLMs/platforms
- Assumptions/dependencies: open benchmarks with raw UI trees; standardized reporting of token composition by prompt component
Long-Term Applications
These opportunities are promising but require further research, scaling, or ecosystem development (e.g., broader datasets, standards, or platform-level changes).
- Standardized UI representation layer for agent ecosystems
- Sectors: software, standards bodies
- Tools/products/workflows: W3C-like guidance for “agent-ready” UI representations; common schemas for compressed, semantically complete DOM/accessibility exports
- Assumptions/dependencies: vendor buy-in; backward compatibility; security/privacy review of exported attributes
- Continual, app-specific synthesis and drift handling
- Sectors: enterprise IT, large app portfolios
- Tools/products/workflows: pipelines that retrain/refine DSL programs on each app release using recorded telemetry; automatic drift detection and rollback; per-app rule registries
- Assumptions/dependencies: safe feedback loops; privacy-compliant logging; robust reward shaping for soft-objective synthesis
- Multimodal co-optimization (visual + structural)
- Sectors: multimodal AI, mobile/web
- Tools/products/workflows: hybrid transformations that exploit layout/screenshot cues to remove purely decorative structures while preserving semantics; camera/canvas-heavy apps
- Assumptions/dependencies: reliable screenshot capture and alignment; handling of non-accessible canvas/WebGL UIs; additional evaluation signals
- Pretraining/fine-tuning LLMs on optimized UI corpora
- Sectors: foundation models for agents
- Tools/products/workflows: train models to natively consume compressed UI formats; smaller context windows; better reasoning over hierarchical UIs
- Assumptions/dependencies: large, diverse datasets of orig→optimized pairs; licensing for training; compatibility with future DSL evolutions
- Privacy-preserving assistants for regulated sectors
- Sectors: healthcare (EHR navigation), finance (KYC/workflows), government services
- Tools/products/workflows: on-device or on-prem UI preprocessing; send only compressed, semantics-preserved text to cloud models or use local LLMs
- Assumptions/dependencies: strict PII handling; certification/compliance audits; performance on domain-specific, dense UIs
- Safety- and compliance-aware transformation with formal guarantees
- Sectors: safety-critical systems, compliance
- Tools/products/workflows: extend DSL with contracts/invariants; formal verification that transformations never drop critical semantics (e.g., warnings, consent, prices)
- Assumptions/dependencies: verified libraries; domain ontologies for “critical UI information”; tool support in CI
- Agent-native OS/browser support
- Sectors: OS vendors, browser engines
- Tools/products/workflows: system APIs to export “agent-optimized” trees; hardware-accelerated capture/transform; per-app policies controlling what can be exported
- Assumptions/dependencies: API standardization; permissions/security models; developer tooling
- Carbon-aware scheduling and policy levers
- Sectors: sustainability, public policy
- Tools/products/workflows: policies incentivizing efficiency-first agent deployments in public sector; procurement criteria requiring representation optimization; reporting frameworks
- Assumptions/dependencies: accepted measurement methodologies; governance and enforcement mechanisms
- Human-in-the-loop authoring tools
- Sectors: product/UX, QA
- Tools/products/workflows: IDE plugins that visualize UI trees, suggest transformations, simulate agent perception, and let developers codify domain rules in the DSL
- Assumptions/dependencies: intuitive UIs for non-PL experts; guardrails against over-aggressive pruning
Notes on Feasibility, Assumptions, and Dependencies (cross-cutting)
- Technical prerequisites: access to reliable DOM/Accessibility trees; stable capture in dynamic UIs (virtualized lists, shadow DOM, infinite scroll); multilingual and RTL support
- Robustness: app/website updates can break transformations; requires drift monitoring, automated regression tests, and a safe fallback path (raw UI)
- Model compatibility: benefits accrue to agents that consume structured text; pure vision-only agents require hybrid approaches
- Safety/privacy: ensure that transformation does not remove or obscure safety-critical cues (e.g., consent, pricing, warnings) and that preprocessing complies with privacy constraints
- Resource profile: offline synthesis uses a capable code LLM and representative examples; runtime overhead is negligible (~milliseconds) but should be monitored at scale
Glossary
- Accessibility tree: A hierarchical accessibility-focused representation of a UI used by assistive technologies and automation. "Android accessibility trees or web DOM trees"
- Agent-agnostic plugin: A plugin designed to integrate with different agent frameworks without requiring agent-specific changes. "we implement UIFormer as an agent-agnostic plugin requiring minimal modification to LLM agents"
- Binary predicate expressions: Boolean expressions over structural properties used to decide filtering operations in UI transformations. "binary predicate expressions for parent node filtering based on structural properties (e.g., node type, attribute patterns, child count)"
- Boolean oracles: Binary correctness checks used in program synthesis to validate whether a program meets its specification. "the lack of Boolean oracles, which traditional program synthesis uses to decisively validate semantic correctness"
- Composite reward function: A combined metric that aggregates multiple objectives (e.g., completeness and efficiency) to evaluate synthesized programs. "using a composite reward function:"
- Combinatorial explosion: Rapid growth of the search space due to the number of possible program transformations or node removals. "Combinatorial explosion of the program search space."
- Constraint-based optimization: An approach that restricts possible solutions via constraints to guide synthesis toward valid and efficient programs. "conducting constraint-based optimization with structured decomposition of the complex synthesis task"
- DOM tree: The hierarchical representation of a web page’s elements used for rendering and interaction. "web page DOMs"
- Domain-specific language (DSL): A restricted programming language tailored to a specific domain to simplify and constrain program synthesis. "a domain-specific language (DSL) that captures UI-specific operations"
- Example-driven synthesis: Program synthesis guided by input-output examples rather than formal specifications. "standard specification-based and example-driven synthesis approaches fall short"
- Few-shot prompting: Prompting an LLM with a small number of curated examples to improve generation quality. "through few-shot prompting with carefully curated examples"
- Flattening approach: A transformation that converts hierarchical structures into flat sequences, often losing structural relations. "this flattening approach discards parent-child relationships"
- GUI agents: LLM-powered agents that interact with graphical user interfaces to perform tasks. "LLM-powered Graphical User Interface (GUI) agents"
- Heuristic-based transformation: Rule-of-thumb methods to transform UI representations that risk dropping important context. "heuristic-based transformation approaches can lose critical information"
- Iterative refinement: A looped process where candidate programs are synthesized, evaluated, and improved based on feedback. "LLM-based iterative refinement with correctness and efficiency rewards"
- LLM: A neural model trained on vast text corpora capable of understanding and generating language for complex tasks. "LLM agents show great potential"
- Latency: The time delay in processing or responding; in deployment, the delay experienced in agent services. "reduces 26.1% latency in production environments"
- Leaf nodes: Terminal nodes in a UI tree that contain no children, often representing atomic UI elements. "For leaf nodes, the DSL enables conditional view creation or filtering based on node properties"
- LLM-based transformation: Using an LLM to directly transform UI representations, often incurring extra token processing cost. "LLM-based transformation approaches would paradoxically increase token consumption"
- Merge operations: Consolidation steps that combine related child views into a single representation to reduce redundancy. "UI-specific merge operations"
- Multi-objective optimization: Optimization targeting multiple goals simultaneously, such as efficiency and completeness. "solving a multi-objective optimization problem."
- Parent-child relationships: Structural links in a UI hierarchy that indicate containment and are crucial for navigation and reasoning. "parent-child relationships that are essential for understanding UI structure and navigation paths"
- Program synthesis: Automatically generating programs that satisfy constraints, examples, or specifications. "traditional program synthesis uses to decisively validate semantic correctness"
- Query per minute (QPM): A throughput metric indicating how many queries an agent system can process per minute. "improves 35% query per minute (QPM) and reduces 26.1% latency"
- ReAct: An agent framework that interleaves reasoning and action for interactive tasks. "We adopt ReAct, a simple yet effective agent framework"
- Recursive locality: The property that complex hierarchical structures can be optimized via local, bottom-up transformations. "driven by recursive locality"
- Runtime-optimization phase: The phase where synthesized transformations are applied during agent execution. "a runtime-optimization phase"
- Satisfiability checks: Formal verification steps to confirm whether a program’s logic satisfies constraints or specifications. "such as test-case assertions or satisfiability checks"
- Semantic completeness: Preservation of essential meaning and context needed for downstream reasoning after transformation. "co-optimization of token efficiency and semantic completeness"
- Semantic redundancy: Extra structural details that inflate representation size without adding meaningful information. "creates semantic redundancy from an LLM perspective."
- Specification-based synthesis: Program synthesis guided by formal specifications rather than examples. "standard specification-based and example-driven synthesis approaches fall short"
- Structured decomposition: Breaking a complex synthesis task into smaller, manageable components to simplify search. "structured decomposition of the complex synthesis task"
- Token consumption: The number of tokens used in prompts or inputs, directly impacting cost and runtime. "Token consumption is measured using the respective tokenizers of GPT-4o, DeepSeek-V3, and Qwen-2.5"
- Token efficiency: The goal of minimizing token usage while retaining necessary information. "co-optimization of token efficiency and semantic completeness"
- Token reduction reward: A feedback signal incentivizing transformations that lower token counts. "token reduction reward"
- Tokenizers: Model-specific utilities that split text into tokens used for LLM processing. "using the respective tokenizers of GPT-4o, DeepSeek-V3, and Qwen-2.5"
- UI-PS: The formulation of UI representation optimization as a program synthesis problem. "UI representation optimization as a program synthesis problem, termed as UI-PS."
- UIFormer: An automated framework that synthesizes UI transformation programs to reduce tokens while preserving semantics. "we present UIFormer, the first automated optimization framework that synthesizes UI transformation programs"
- vLLM inference framework: A high-throughput system for serving LLMs efficiently during experiments or deployment. "using vLLM inference framework"
Collections
Sign up for free to add this paper to one or more collections.

