- The paper introduces PixelPrune, a training-free, pixel-domain patch selector that leverages predictive coding for significant token reduction before Vision Transformer encoding.
- It discards 30–80% of tokens on structured images, achieving up to 4.2× end-to-end inference acceleration and 6.6× reduction in encoder FLOPs with negligible accuracy loss.
- The method ensures exact or bounded-reconstruction guarantees while generalizing across document, GUI, and general-domain benchmarks, enabling efficient VLM processing.
PixelPrune: Pixel-Level Adaptive Visual Token Reduction via Predictive Coding
Overview
"PixelPrune: Pixel-Level Adaptive Visual Token Reduction via Predictive Coding" (2604.00886) addresses the computational inefficiencies inherent in Vision-LLMs (VLMs) for document understanding and GUI interaction, where high-resolution images yield an abundance of redundant visual tokens. The paper introduces PixelPrune, a training-free, parameter-free, pixel-domain patch selector that leverages predictive coding to eliminate redundant visual tokens prior to Vision Transformer (ViT) encoding. The resultant reduction in token count provides substantial end-to-end acceleration in both inference and training with negligible accuracy degradation, and demonstrates robust generalization across document, GUI, and general-domain benchmarks.
Motivations and Limitations of Existing Methods
Most prior VLM token reduction methods operate at or after the feature level, pruning visual tokens post-ViT using learned metrics or attention scores. Such approaches incur the full computational burden of the initial patch embedding and self-attention operations. Moreover, existing methods disregard the pixel-level redundancy characteristic of structured domains such as documents and GUIs, which frequently contain large regions of uniform or identical pixels (e.g., white margins, toolbars).
An analysis presented in the paper reveals that across document and GUI benchmarks, only 22-71% of image patches are pixel-unique within an image, indicating extensive redundancy unaddressed by standard feature-based approaches. This motivates a direct, pixel-level removal strategy that minimizes unnecessary neural computation ab initio.

Figure 1: PixelPrune patch selection on a document image (left) and GUI screenshot (right). Kept patches are shown in original color; dropped patches are grayed out. Token reduction: 70% (document) and 93% (GUI).
Methodology
PixelPrune operates in the pixel domain and, crucially, precedes any neural network inference. The main procedure comprises:
- Patch Decomposition: Images are divided into fixed-size patches (e.g., 16×16, merged into 32×32 for Qwen3-VL).
- Predictive Coding: Each patch is predicted from spatially causal neighbors, omitting those whose pixel content is either identical (lossless, τ=0) or sufficiently close (lossy, τ>0) to their predictions.
- Predictor Construction: The preferred "Pred-2D" predictor evaluates each candidate patch using its left, upper, and upper-left neighbors, adopting a selection strategy reminiscent of the median-edge predictor from classical image compression (Figure 2).
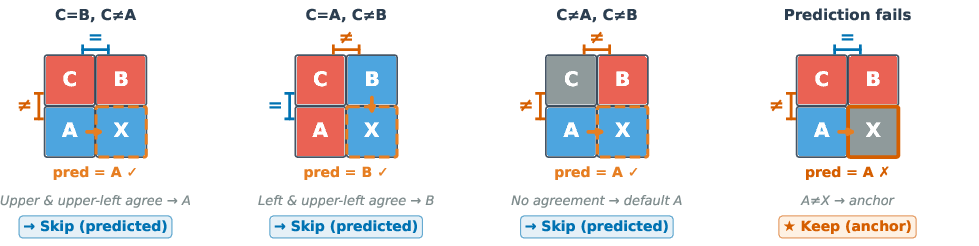
Figure 2: Illustration of PixelPrune's Pred-2D prediction. For each target patch X, three causal neighbors---A (left), B (upper), C (upper-left)---determine the predicted patch X^.
- Recoverability: The method guarantees that, for lossless compression, the decoder can reconstruct the full image exactly given the reduced patch set and the predictive coding strategy. For bounded-lossy settings (τ>0), the pixel error for any omitted patch is upper-bounded by 32×320.
PixelPrune integrates seamlessly with architectures in which the original patch coordinates can be preserved (e.g., NaViT-based ViTs with absolute/relative positional encodings). The selector is fully differentiable, stateless, and negligible with respect to both computational and memory overhead.
Analysis of Visual Encoder Bottlenecks
A critical empirical observation from the paper concerns the distribution of computational cost across the VLM pipeline: for large-scale, high-resolution images, the ViT encoder dominates prefill latency, accounting for up to 86% of total prefill time at 32×321 pixel input for small-scale (2B) Qwen3-VL variants.
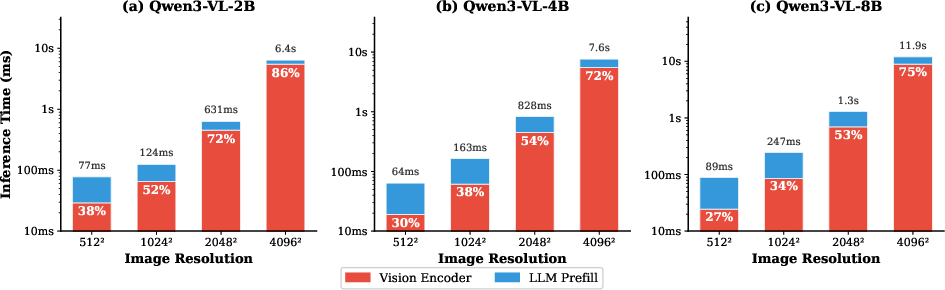
Figure 3: Prefill latency breakdown across Qwen3-VL scales (2B, 4B, 8B) at five resolutions. The vision encoder constitutes the major computational bottleneck at high resolution.
Consequently, performing patch redundancy removal pre-ViT directly decreases both quadratic self-attention FLOPs and linear embedding computation, with subsequent benefits compounding through patch merger and LLM decoding.
Empirical Results
Evaluation is conducted along domain (document, GUI, general-domain) and training regime (training-free, knowledge distillation, scratch) axes.
- Token Reduction: PixelPrune regularly discards 30–80% of tokens on document and GUI images under lossless (32×322) matching. On ScreenSpot Pro Scientific, only 26% of tokens are retained.
- Inference Speedup: Up to 4.232×323 end-to-end inference acceleration and 6.632×324 reduction in vision encoder FLOPs are reported.
- Training Acceleration: Training-from-scratch incorporating PixelPrune yields 1.932×325 speedup and reduces peak memory load by 33.6%.
- Benchmark Accuracy: Accuracy with PixelPrune is within 32×3260.3% of the full-token baseline on most document and GUI tasks, under either zero-shot or knowledge-distilled regimes.
- Generalization: On general-domain benchmarks, PixelPrune retains 80–100% of tokens with negligible drop in accuracy (≤1.1%), with modest further token reduction under near-lossless settings.
Design Ablations
The Pred-2D predictor consistently produces the lowest retain ratios among three strategies, exploiting both horizontal and vertical redundancy. All methods exhibit highly similar downstream accuracy, indicating that effective redundancy identification, not the depth of the network at which pruning occurs, is the dominant factor in maintaining fidelity.
Empirical analysis demonstrates that pruning tokens prior to the ViT encoder is both optimal for efficiency and competitive in accuracy compared to pruning at internal ViT layers. Token reduction at later network stages confers only marginal differences in output performance but results in substantially higher compute loads.
Theoretical and Practical Implications
PixelPrune's parameter-free, deterministic, and training-free nature, coupled with exact or bounded-reconstruction guarantees, contrasts sharply with recent learned or attention-dependent pruning paradigms. The method exploits a domain property—high local pixel redundancy—that is especially pronounced in structured images and underutilized by prior art. Its compatibility with highly optimized architectures (e.g., supporting FlashAttention, batch processing) and training pipelines underscores practical deployability for latency- and memory-constrained VLM applications.
Notably, the method's efficacy extends to training acceleration, opening the possibility for larger-scale VLM training within fixed resource budgets. Additionally, its recoverability property provides architectural robustness, allowing downstream models to flexibly adjust between accuracy and efficiency as operational constraints require.
PixelPrune expands the VLM system designer's toolkit: it provides a means to probe the limit of token reduction achievable by content-level redundancy alone and offers a strong baseline against which future, more complex, or semantically informed token reducers must be compared.
Conclusion
PixelPrune sets a new standard for pre-neural, adaptive visual token reduction in structured visual domains. By leveraging predictive coding for parameter-free, pixel-domain redundancy extraction, it achieves strong token reduction ratios, training and inference acceleration, and negligible impact on task performance. The work suggests that incorporating classical image redundancy principles can yield significant efficiency gains in modern VLM pipelines, motivating the reconsideration of pixel-level signals in the design and pre-processing of multimodal learning systems. Future developments may explore hybrid approaches combining content-adaptive, pixel-domain reduction with semantic feature-based schemes, or extending the approach to more complex visual modalities.