- The paper introduces a large-scale dataset with 2 million videos covering 71 physical phenomena to benchmark visual physics learning and reasoning.
- It details a multi-view and monocular camera setup that improves physical plausibility in generative video models using a novel PMF metric.
- The paper benchmarks challenges in future frame prediction, physical properties estimation, and motion transfer, guiding future research directions.
PhysInOne: A Large-Scale Suite for Visual Physics Learning and Reasoning
Motivation and Dataset Construction
PhysInOne addresses a key deficit in physically-grounded visual training data for AI: prior datasets are narrowly scoped, typically covering few scenes or phenomena and limited object diversity. In contrast, PhysInOne systematically scales to 2 million videos across 153,810 distinct dynamic 3D scenes, comprehensively annotated and spanning 71 basic physical phenomena (including mechanics, optics, fluid dynamics, magnetism) with multiobject, multiphysics activities. Scene construction leverages diverse assets—2,231 objects, 623 materials, 528 backgrounds—to instantiate physical laws strictly (Newton's Laws, Hooke's Law, Mass and Momentum Conservation, etc.), advancing beyond the oversimplified geometric and physical settings of predecessors.

Figure 1: Spanning 71 basic physical phenomena scaled to 3,284 multiphysics activities, PhysInOne comprises 153,810 unique scenes featuring 2,231 objects across 528 backgrounds and 623 materials, yielding 2 million videos with comprehensive annotations.
Camera sampling ensures both multiview and challenging monocular videos per scene (12 fixed + 1 moving camera), with dense visual and physical annotations (meshes, trajectories, segmentation masks, material properties, text descriptions). The dataset's partitioning maintains asset exclusivity across train/val/test splits, preventing data leakage. PhysInOne's scale, diversity, and comprehensive annotation establish a new quantitative benchmark for visual physics learning at scale.
Physics-Aware Video Generation
Existing state-of-the-art generative video models lack robust adherence to physical laws: generated clips frequently exhibit physically implausible motions. PhysInOne enables fine-tuning of foundation models (e.g., SVD-XT, CogVideoX, Wan2.2) with text-video pairs. Fine-tuning substantially improves physical plausibility, validated both quantitatively via the introduced Physical Motion Fidelity (PMF) metric and qualitatively through human studies. PMF is a spectral dynamics metric based on normalized 3D DFT energy invariants, robust to spatiotemporal shifts and appearance variations but sensitive to discrepancies in motion pattern distributions. Human ratings of physical plausibility exhibit strong correlation with PMF.
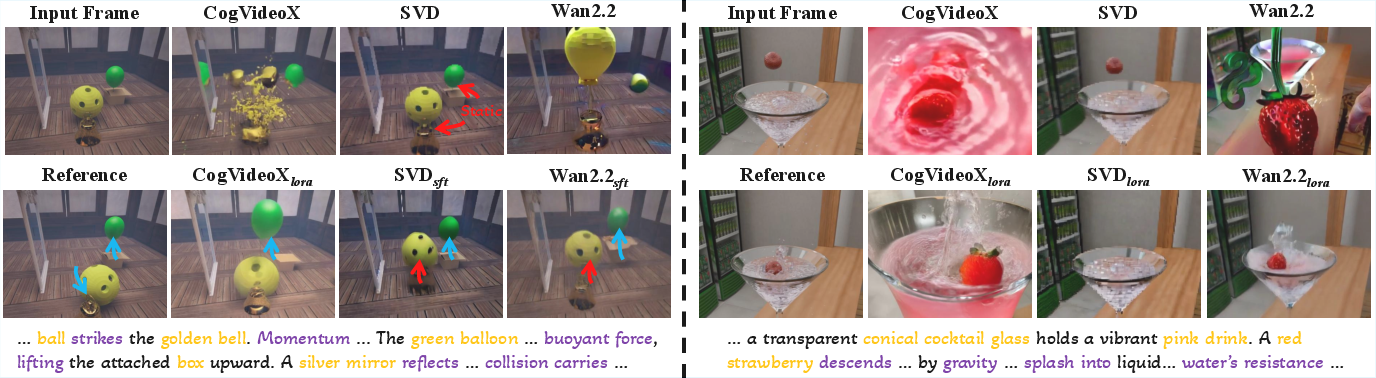
Figure 2: Qualitative examples demonstrating improved physical plausibility in videos generated after fine-tuning on PhysInOne.
Strong numerical improvements are observed: SVD-XT fine-tuned on PhysInOne achieves PMF = 3.147 (using SFT) vs 2.753 pretrained, human rating 6.08 vs 6.09, and FVD 143 vs 203. Magnetism and fluid dynamics are best modeled, while mechanics and optics remain challenging—these domain discrepancies highlight fundamental future directions.
Future Frame Prediction
PhysInOne benchmarks both long-term and short-term future frame prediction in physically grounded dynamic scenes for multiview and monocular settings. 4D modeling approaches (TiNeuVox, DefGS, FreeGave, TRACE) and video prediction models (ExtDM, MAGI-1) are evaluated. While trained viewpoints yield reasonable PMF (DefGS: PMF 3.980 seen/3.347 novel), novel viewpoint predictions sharply degrade (e.g., TiNeuVox: PMF 3.710 seen/2.885 novel), indicating that modeling multiobject physical motion across arbitrary 3D perspectives remains unsolved.

Figure 3: Qualitative examples of long-term future frame prediction by current methods for trained viewpoints.
Short-term prediction tasks for robotics scenarios show improved PMF (FreeGave: 4.742 seen/3.706 novel), underscoring the potential for embodied physics-aware planning. Nevertheless, performance gaps on novel views persist across all tested models.
Physical Properties Estimation
PhysInOne exposes the complexity of system identification ("inverse physics"): estimation of material parameters (Elastic modulus, Poisson ratio, fluid viscosity, friction angle, etc.) from visuals. Representative methods PAC-NeRF and GIC are evaluated across five material categories (elastic solids, plasticine, Newtonian and non-Newtonian fluids, granular substances). While both baselines achieve physically plausible estimates and reasonable resimulation scores (e.g., GIC: PMF 5.938, PSNR 26.90), significant errors arise for complex objects and intricate backgrounds. The dataset's challenging cases reveal the limitations of current approaches in disentangling, editing, and generalizing physical parameter inference.

Figure 4: Qualitative resimulation results using estimated physical properties. Both baselines fail to accurately infer properties for complex objects against intricate backgrounds, leading to physically implausible outcomes.
Motion Transfer
Motion transfer methods (MotionPro, GoWithTheFlow) leveraging optical flow and noise warping are benchmarked on PhysInOne. Although generated frames preserve visual realism, both fail to transfer multiphysical and multiobject motion with fidelity—complex dynamics (e.g., falling balls, interacting cars) are lost. PMF scores emphasize these gaps (MotionPro: PMF 3.484, GoWithTheFlow: 3.309). Current approaches remain insufficient for AI-driven animation or virtual prototyping where realistic physical motion transfer is essential.

Figure 5: Qualitative motion transfer results from GoWithTheFlow and MotionPro. Generated frames retain visual realism but fail to transfer complex physical motions (e.g., moving cars, falling ball).
Practical and Theoretical Implications
PhysInOne's construction and benchmark results catalyze new research directions in physically-plausible generative modeling, 4D simulation, system identification, and embodied AI. The strong quantitative improvements in physical plausibility upon fine-tuning (especially PMF-based) demonstrate the necessity of scale and diversity in training data for physical reasoning. However, definitive learning of complex physical dynamics across domains and novel views, and robust inference of intrinsic parameters, remains highly challenging. Further, motion transfer in AI-generated content will require fundamentally new representations beyond optical flow.
The dataset also enables systematic evaluation of methods with physics-grounded metrics—moving beyond conventional appearance-based metrics. PMF, in particular, provides a robust quantitative framework for assessing dynamic fidelity. The theoretical implications span learning invariant representations for physical dynamics, generalizing system identification, and developing controllable world simulators.
Conclusion
PhysInOne establishes a rigorous benchmark for visual physics learning, reasoning, and simulation, addressing orders-of-magnitude gaps in scale and diversity. Fine-tuning foundation models on PhysInOne significantly increases physical plausibility in generated videos. Current methods, however, underperform in learning complex multiobject dynamics and physical property estimation, substantiating the dataset’s role in revealing and motivating future advances in physically-grounded AI systems (2604.09415).