- The paper introduces a novel benchmark that quantitatively evaluates physical reasoning in VLMs by measuring kinematic properties from videos.
- It employs diverse data sources and controlled experiments to reveal that models rely more on pre-trained priors than on precise pixel-level inferences.
- Experimental results show that even top models fall short of human-level reasoning, highlighting the need for innovative training and architectural strategies.
QuantiPhy: A Quantitative Benchmark Evaluating Physical Reasoning Abilities of Vision-LLMs
Introduction and Motivation
QuantiPhy addresses the persistent gap in evaluating vision-LLMs (VLMs) on quantitative physical reasoning. Existing benchmarks for VLMs and embodied AI largely rely on qualitative or multiple-choice visual question answering (VQA) formats, fundamentally limiting insights into whether models genuinely infer or merely memorize kinematic properties such as size, velocity, and acceleration. Human-level physical reasoning routinely integrates visual observation with quantitative estimation, a capacity critical in downstream domains such as autonomous driving, robotics, and AR/VR. QuantiPhy systematically formalizes VLM evaluation on the task of quantitatively inferring kinematic properties from videos, positioning itself as a necessary next step for the field.
Benchmark Task Design
QuantiPhy defines the quantitative kinematic inference task as follows: Given a short video and a single prior on a physical property (either object size, instantaneous velocity, or acceleration, specified in real-world units as text), the model is asked to estimate other kinematic quantities of a (possibly different) target object at specified times. The underlying measurement is always grounded in world coordinates, distinguishing between raw pixel measurements and real-world-scale inference by leveraging the given prior.
The benchmark comprises four core task combinations based on two axes—movement dimensionality (2D vs. 3D) and the nature of the prior (Static: size; Dynamic: velocity or acceleration):
- 2D-Static: Inferring quantities in planar scenes with static priors.
- 2D-Dynamic: Inferring in 2D with motion-derived priors.
- 3D-Static: Volumetric reasoning with static priors.
- 3D-Dynamic: 3D with temporal priors.
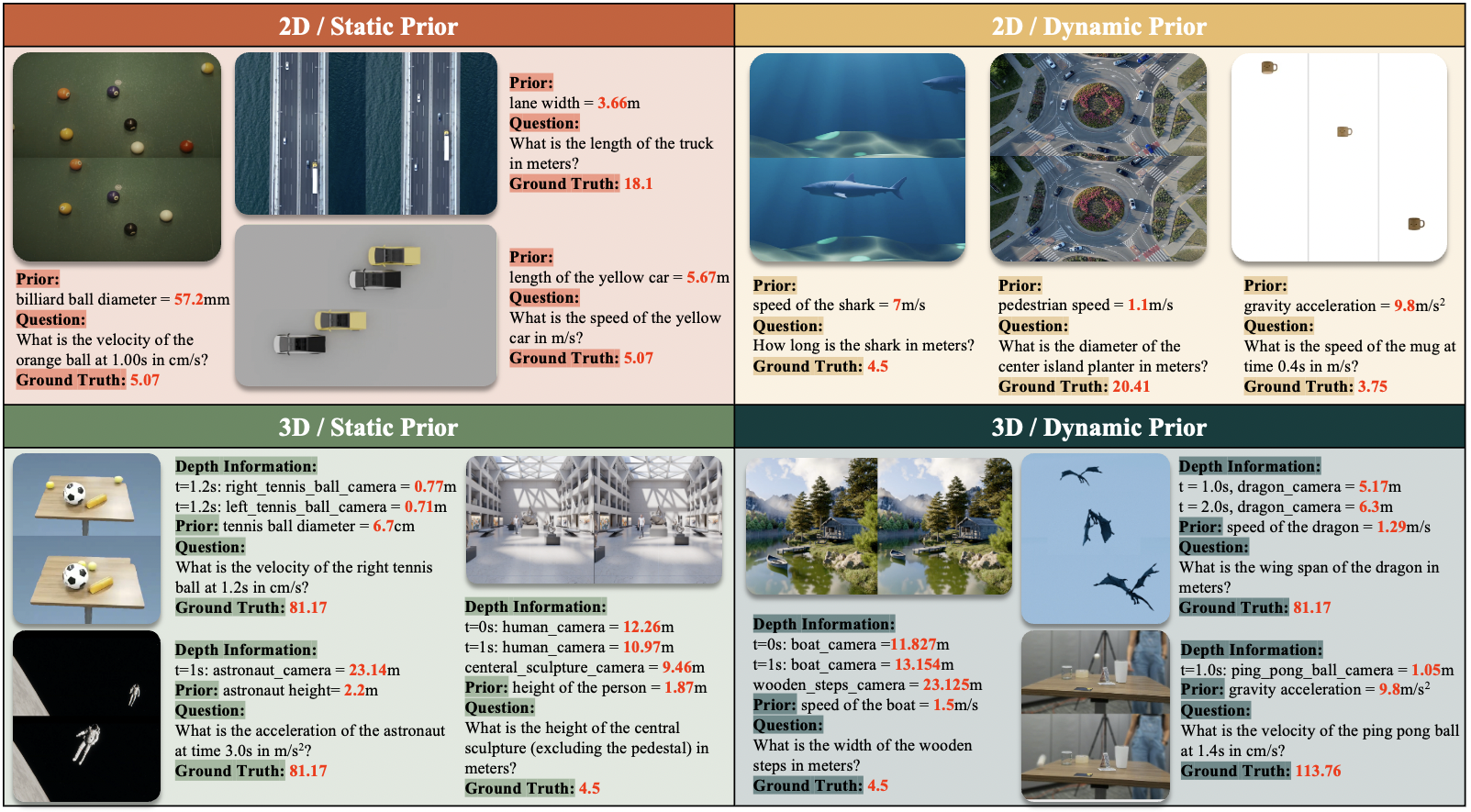
Figure 1: Sample examples from QuantiPhy, illustrating the four core task combinations defined by Dimensionality {2D, 3D} and Physical Prior {Static, Dynamic}.
Videos and associated tasks are balanced across these categories to cover diverse kinematic events and difficulty regimes.
Dataset Collection and Annotation
Video data is curated across three sources: Blender simulation, multi-camera lab captures, and carefully selected internet videos. Blender-generated content allows precise control over motions and environment, providing high-fidelity ground truth for size, velocity, and acceleration. Lab-captured videos are annotated using a custom interface for pixel-accurate depth readings. Annotators further ensure world-to-pixel mapping through visible reference objects and measure pixel-space quantities, which, combined with the given prior, yield scaling factors for quantitative conversion.
To probe the effect of visual context, videos are rendered or post-processed with varying background complexity—uniform color, simple, or cluttered (complex)—and with either single or multiple moving objects for reference.
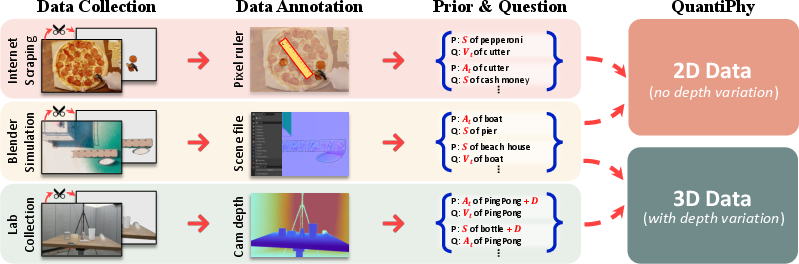
Figure 2: The construction of QuantiPhy proceeds in three sequential stages: collection of raw videos from three sources, segmentation with solid backgrounds, and annotation of (prior, question, ground truth) triplets.
Evaluation Protocol and Metric
Evaluation covers 21 state-of-the-art VLMs (6 proprietary, 15 open-weight), with human baselines contextualized via a controlled user study using the same interface and priors. The main metric is Mean Relative Accuracy (MRA): answers receive partial credit based on whether their relative error falls below a set of strict thresholds, yielding a robust quantitative assessment that avoids the brittleness of exact-match or the insensitivity of qualitative scoring.
Experimental Results and Analysis
Closed-source models (ChatGPT-5.1, Gemini-2.5 Pro/Flash) perform best, with top MRA scores of ~53.1—comparable to, but not exceeding, human annotator averages. The best open-weight model, Qwen3-VL-Instruct-32B, closely follows, while smaller or earlier systems lag substantially. Notably, scaling within a model family (e.g., Qwen3, InternVL) improves quantitative reasoning, especially in dynamic (temporally variable) tasks.
Despite access to precise video and textual input, most models systematically underperform the theoretical optimum achievable by exact pixel-level algebraic computation. Analysis confirms a strong bias toward pre-trained world knowledge and semantic priors, rather than faithful exploitation of visual cues and explicit numerical priors. The gap becomes pronounced in the counterfactual setting, where models are given implausible priors; their outputs remain anchored to memorized magnitudes, disregarding the altered input.
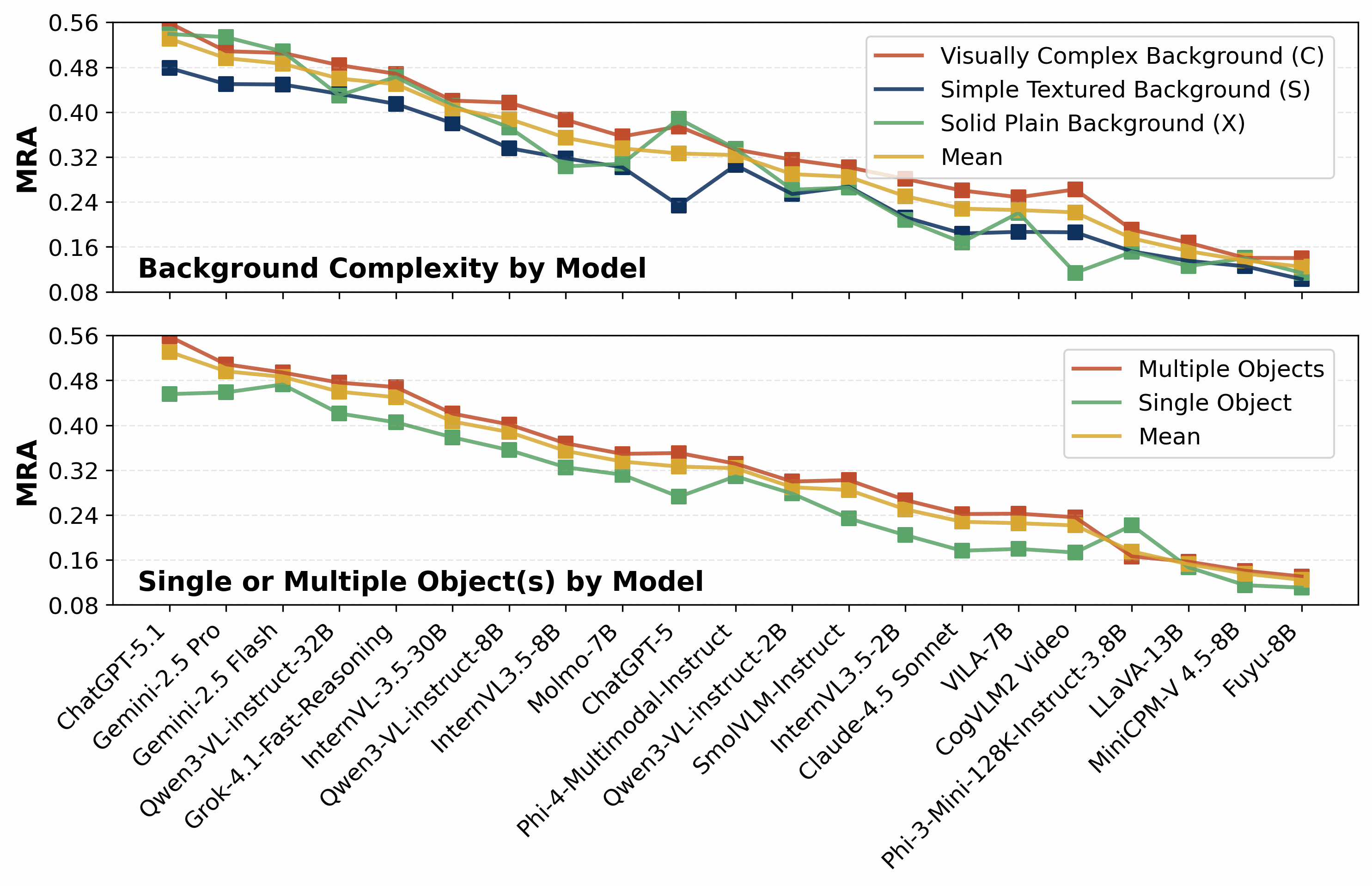
Figure 3: Effect of scene context. Mean Relative Accuracy (MRA) for all models is plotted across background complexity and object count conditions, illustrating mild background effects and strong gains from multiple objects.
Qualitative Case Studies
Case analyses of top-performing systems underscore this lack of input faithfulness. In tractable cases, models apply the correct pixel-to-world scaling and produce accurate inference; but under counterfactual or ambiguous priors, they revert to statistical heuristics or canonical values (e.g., reporting 9.8m/s2 for gravity regardless of simulation parameters).

Figure 4: Faithful pixel–prior reasoning in which the model executes the correct sequence of pixel measurement, scale estimation, and quantitative inference.
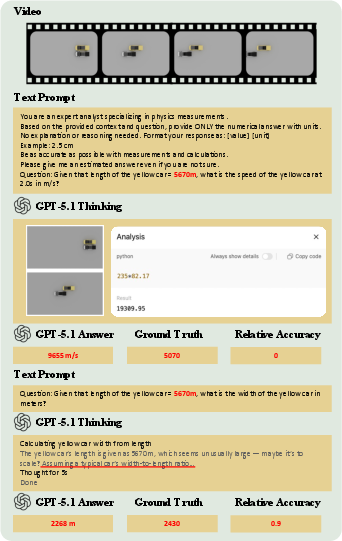
Figure 5: Counterfactual prior breaks faithfulness; model ignores the modified prior and defaults to memorized size ratios.

Figure 6: Video ablation reveals reliance on priors; with video removed, model still outputs plausible values derived from parametric knowledge.

Figure 7: Strong gravitational prior overrides counterfactual physics, with the model hallucinating canonical gravity regardless of video evidence.
Prompting and Structured Reasoning
Chain-of-thought (CoT) prompting, which decomposes the task into subproblems (pixel measurement, scale calculation, inference), fails to close the gap or significantly enhance accuracy except in isolated cases. Error propagation often leads to degraded performance, indicating limitations in robust intermediate quantitative reasoning ability.
Implications and Future Directions
Theoretical implications are clear: The dominant VLMs, even at scale, do not yet robustly ground quantitative physical inference in pixel-level visual evidence and explicit numeric priors. They instead behave as powerful pattern-matching engines optimizing for verbal plausibility, not physically faithful measurement or extrapolation.
Practically, this limits their deployment in safety-critical applications such as embodied robotics, self-driving systems, and computational science domains where faithful, context-sensitive quantitative reasoning is non-negotiable.
The observed failures—such as the inability to adjust predictions with counterfactual priors or to break from rigid parametric memory when tasked with synthetic physics—strongly motivate new VLM objectives and training paradigms. Examples include tighter integration of explicit geometric solvers, training on synthetic counterfactuals, or embedding differentiable physics simulators in model architecture.
QuantiPhy's design as a scalable, balanced, and diagnostic benchmark provides a substrate for such research, distinguishing true physical measurement from plausible guessing and enabling future model ablations, architectural innovations, and robust quantitative performance gains. Benchmark expansion to rotational/multi-body dynamics, non-rigid objects, and moving cameras is suggested as critical next steps.
Conclusion
QuantiPhy establishes a rigorous new standard for evaluating physical reasoning in vision-LLMs at the quantitative level. Assessment of 21 models reveals that current systems, including the strongest proprietary LMMs, are not yet capable of reliable, input-faithful quantitative physical inference. Advances in architecture, training, and data are essential to push VLMs beyond statistical plausibility toward true scientific and embodied intelligence. The benchmark and findings chart a clear experimental and methodological path for future work in physically grounded AI reasoning.

