PhysX-Anything: Simulation-Ready Physical 3D Assets from Single Image
Abstract: 3D modeling is shifting from static visual representations toward physical, articulated assets that can be directly used in simulation and interaction. However, most existing 3D generation methods overlook key physical and articulation properties, thereby limiting their utility in embodied AI. To bridge this gap, we introduce PhysX-Anything, the first simulation-ready physical 3D generative framework that, given a single in-the-wild image, produces high-quality sim-ready 3D assets with explicit geometry, articulation, and physical attributes. Specifically, we propose the first VLM-based physical 3D generative model, along with a new 3D representation that efficiently tokenizes geometry. It reduces the number of tokens by 193x, enabling explicit geometry learning within standard VLM token budgets without introducing any special tokens during fine-tuning and significantly improving generative quality. In addition, to overcome the limited diversity of existing physical 3D datasets, we construct a new dataset, PhysX-Mobility, which expands the object categories in prior physical 3D datasets by over 2x and includes more than 2K common real-world objects with rich physical annotations. Extensive experiments on PhysX-Mobility and in-the-wild images demonstrate that PhysX-Anything delivers strong generative performance and robust generalization. Furthermore, simulation-based experiments in a MuJoCo-style environment validate that our sim-ready assets can be directly used for contact-rich robotic policy learning. We believe PhysX-Anything can substantially empower a broad range of downstream applications, especially in embodied AI and physics-based simulation.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
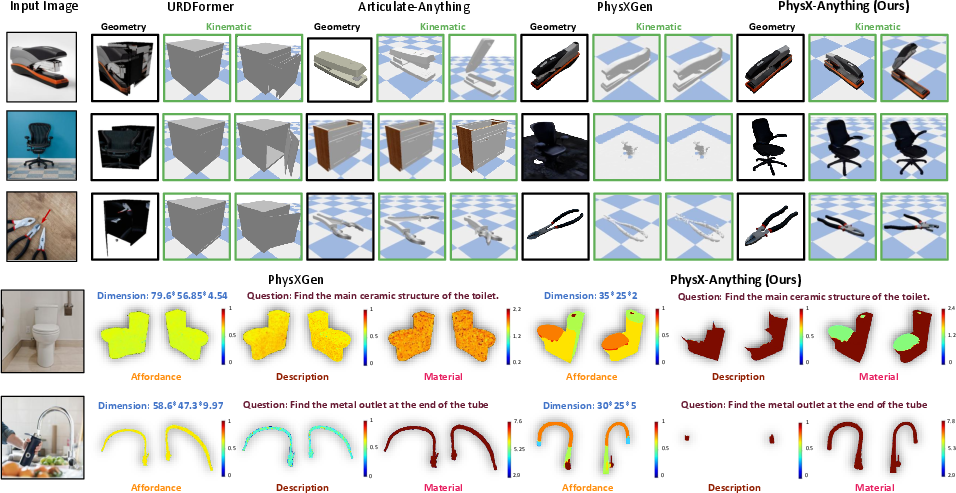
This paper introduces PhysX-Anything, a new AI system that can look at a single real-world photo and create a detailed 3D model of the object in the picture. Unlike most 3D generators, it doesn’t just make a nice-looking shape. It also figures out how the object’s parts move (its “articulation,” like doors and hinges), how big it is, and physical properties like material and weight. The final 3D models can be used directly in physics simulators and robot training environments.
Key Objectives
Here are the simple questions the researchers wanted to answer:
- From just one photo, can we build a 3D object that looks right, moves the way it should, and behaves realistically in a physics simulator?
- Can we make this work using a vision-LLM (an AI that understands both images and text) without special, complex add-ons?
- Can we shrink the large amount of data needed to describe 3D shapes so the AI can handle it easily?
- Can we create a dataset with many everyday objects that includes the physical details robots need?
How It Works (Methods)
To make this understandable, think of the system like a careful builder following steps:
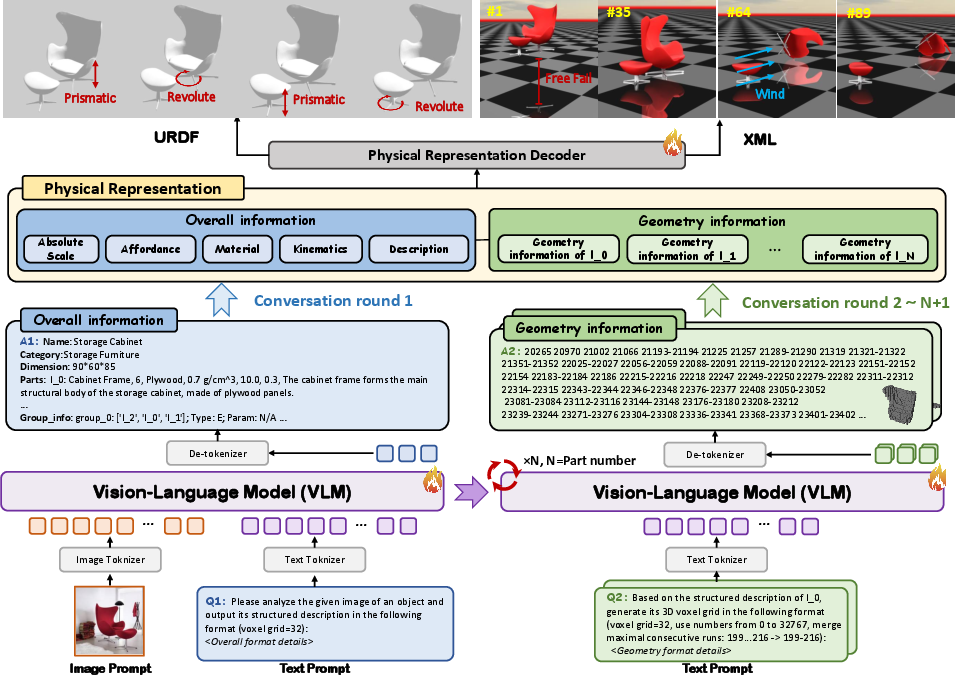
Step 1: An AI that “reads” pictures and words
The team uses a vision-LLM (VLM), similar to a smart assistant that can look at images and understand text. It has a “conversation” with the input image, writing down:
- Overall info: size, weight/density, materials (metal, plastic, etc.), and how parts should move (hinges, sliders, rotation ranges).
- Part-by-part geometry: details of each piece of the object.
Step 2: A simpler way to describe 3D shapes
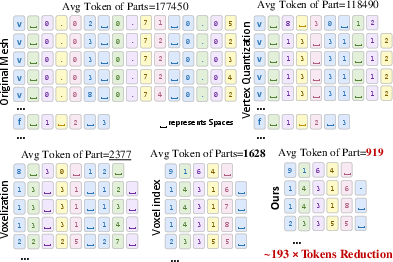
3D models normally need lots of tiny details—too many for the AI to handle directly. The paper introduces a compact shape description:
- Imagine building with Minecraft blocks. These blocks are called “voxels.”
- The AI first makes a coarse version of the object on a 32×32×32 voxel grid (like a rough blocky model).
- To save “tokens” (the pieces of information the AI reads, like words), it writes down only the filled blocks and merges neighboring ones into ranges. This reduces the number of tokens by about 193× compared to regular 3D meshes. In short, it compresses the shape without losing the structure.
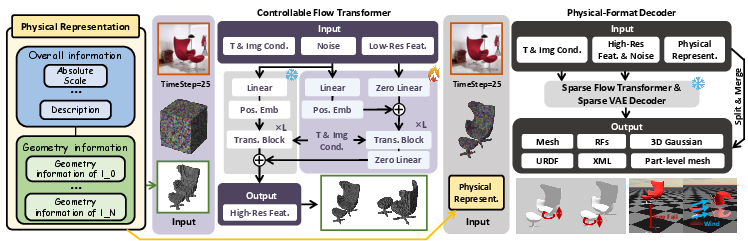
Step 3: Refining the shape
Once the coarse shape is ready, a “controllable flow transformer” (think of it as a detail painter guided by the blocky sketch) adds fine details to turn the blocky shape into a smooth, high-quality 3D model.
Step 4: Output formats ready for simulators
Finally, the system outputs files like URDF and XML. These are like instruction manuals for simulators and robots, telling them:
- The exact size of parts
- How pieces are connected
- Which way things move and by how much With these files, the models can be plugged into physics engines (like MuJoCo) and used right away.
Step 5: A new dataset to train and test on
The team built PhysX-Mobility, a dataset of over 2,000 objects from 47 categories (such as toilets, fans, cameras, coffee machines, staplers), annotated with physical info like materials, weight/density, and movement. This helps the AI learn realistic properties and generalize to new images.
Main Findings and Why They Matter
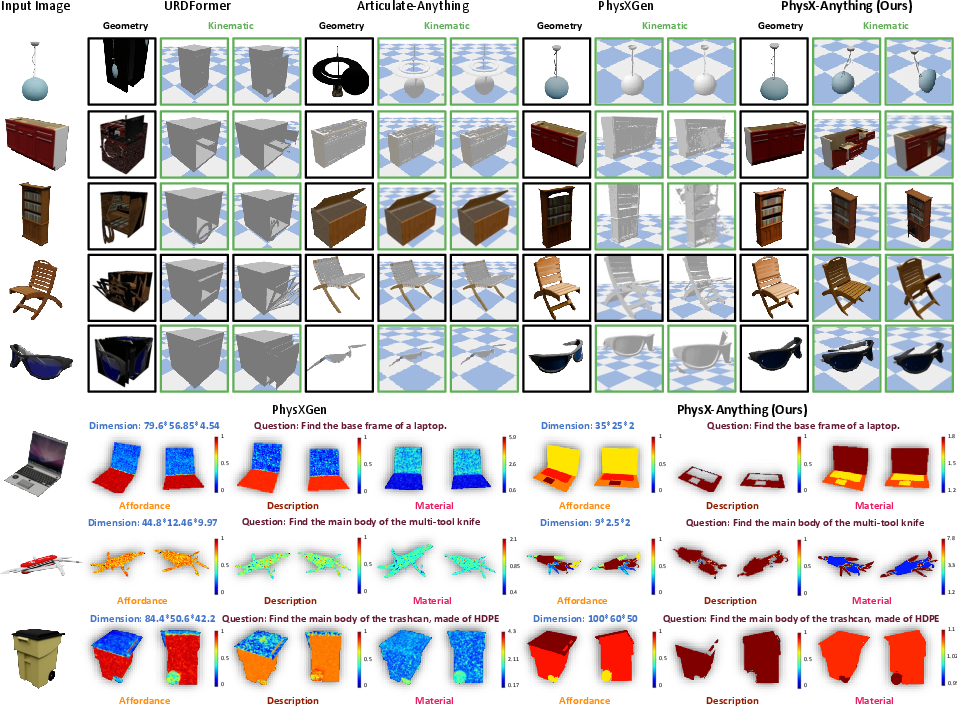
- Better shapes and physics: Compared to other methods, PhysX-Anything makes 3D models with more accurate geometry and more realistic physical attributes. It does better at estimating absolute size, materials, how parts move, and how objects should be handled.
- Works on real photos: On “in-the-wild” images from the internet, the system keeps high quality. Human studies and AI-based evaluations both show strong performance in how well the shapes and articulations match the real objects.
- Ready to use in simulations: The output models can be imported directly into physics engines and robot simulators. The team showed robots learning contact-rich tasks (like manipulating eyeglasses) using these generated assets.
- Efficient representation: The new voxel-based token compression (about 193× fewer tokens) lets a standard vision-LLM learn detailed 3D geometry without special custom tokenizers, making training simpler and more scalable.
Implications and Impact
- Better robot training: Robots can learn more safely and cheaply in simulation using realistic, easily generated 3D objects. This can speed up progress in robotics and embodied AI.
- Faster content creation: Game developers, researchers, and educators could turn simple photos into interactive 3D assets with physical behavior, reducing time and effort.
- Bridges a key gap: Many 3D methods stop at looks; PhysX-Anything goes further by adding movement and physical realism. This unlocks new applications in simulation, control, and interactive environments.
- Scalable approach: Because the method uses a general-purpose vision-LLM and a compact shape description, it could grow to support more object types and tougher tasks without overly complex changes.
In short, PhysX-Anything shows that from a single picture, we can create 3D models that don’t just look right—they act right. That’s a big step toward smarter, more practical AI systems that understand and interact with the physical world.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved by the paper; each item pinpoints a missing piece or uncertainty that could guide future research.
- Single-image ambiguity: How to robustly resolve occlusions, back-side geometry, and view-dependent effects (e.g., specular highlights, transparency) from one photo without multi-view or depth cues.
- Absolute scale in the wild: The method claims large scale-error reductions on the curated dataset, but it does not explain how absolute scale is inferred when camera intrinsics and reference objects are unknown in real scenes; no calibration strategy or uncertainty bounds are given.
- Physical parameter inference: The pipeline lacks a transparent mechanism for estimating friction, restitution, damping, inertia tensors, and mass distribution from appearance; it is unclear if material labels are simply mapped to hand-picked constants and whether these estimates generalize.
- Rigid-only assumption: Deformable, compliant, soft, cloth-like, or fluid objects are out of scope; no pathway for elastic/compliant joints, springs, belts, cables, or gear constraints is provided.
- Multi-material heterogeneity: Within-part spatially varying materials and densities (e.g., composites, inserts, coatings) are not modeled or evaluated.
- Coarse voxel bottleneck: The 323 coarse voxel representation risks losing thin structures and fine mechanisms; the trade-off between resolution, latency, and fidelity (and how to scale beyond 323) is not characterized.
- Run-length-style geometry tokenization: The contiguous-index merging scheme’s robustness to tokenizer behaviors (number splitting, locale/language tokenization), error propagation, and portability across LLM tokenizers is not analyzed.
- Part-wise independence: Part geometries are generated independently (with only overall context), creating potential inter-part inconsistencies (misalignments, interpenetrations, tolerance mismatches) with no explicit global consistency or collision-free constraints.
- Part segmentation reliability: The nearest-neighbor segmentation from voxel assignments may mis-segment symmetric or interlocking parts; no quantitative part-level segmentation accuracy is reported.
- Kinematic GT evaluation: “Kinematic parameters (VLM)” are evaluated via VLM judgments; there is no dataset-wide, ground-truth, numeric error analysis of joint axes, limits, link hierarchy, and DOF versus the annotated assets.
- Simulation stability metrics: There is no systematic evaluation of contact stability, penetration rates, constraint violations, or solver convergence under varying simulation conditions; failure modes in contact-rich tasks are not quantified.
- Cross-engine compatibility: Despite URDF/XML export, only a MuJoCo-style environment is shown; portability, parameter mapping, and behavior consistency across Bullet/PyBullet, PhysX, ODE, Isaac Gym, or Unity/Unreal engines are untested.
- Dynamics completeness: It remains unclear how joint damping, friction cones, actuator models/limits, and center-of-mass/inertia are computed or validated; small errors could cause large simulation artifacts.
- Texture and reflectance realism: No quantitative metrics (e.g., perceptual or BRDF accuracy) are reported; the mapping from “material” to physically meaningful optical and haptic properties is unspecified.
- Dataset scale and bias: PhysX-Mobility (~2K objects, 47 categories) may be too small for open-world generalization; annotation protocols, inter-annotator agreement, and error analysis of physical labels are not described.
- Limited in-the-wild evaluation: ~100 images and 14 raters may not capture real-world diversity (clutter, lighting extremes, rare categories); there is no standardized benchmark for physical inference in the wild.
- VLM-based scoring bias: Heavy reliance on GPT-like metrics for geometry/kinematics can be biased and non-repeatable; physics-grounded, human-independent metrics are needed.
- Failure case analysis: The paper does not document typical failure modes (e.g., transparent/reflective parts, extreme thinness, cluttered scenes, highly articulated mechanisms), nor suggests detection/mitigation strategies.
- Scene-level scope: The pipeline targets single objects; segmentation, instance selection, and interaction modeling in multi-object scenes with occlusions remain open.
- Uncertainty quantification: The model returns point estimates; there is no uncertainty over geometry, materials, or physical parameters for downstream risk-aware planning and simulation.
- Efficiency and scalability: Training cost, inference latency, memory footprint, and throughput at different resolutions are not reported; feasibility for large-scale or time-critical applications is unclear.
- Mesh quality guarantees: No analysis of watertightness, manifoldness, self-intersections, or degeneracies of generated meshes; the impact of such defects on simulation robustness is unquantified.
- URDF validity checks: No automatic validation metrics (parsing success rate, joint chain correctness, collision-free default pose, link inertia sanity) are reported.
- Affordance metrics: Affordance evaluation relies on human ratings; definitions, ground-truth sources, and reproducible, quantitative benchmarks are missing.
- Long-tail and OOD generalization: Performance on rare categories, highly complex mechanisms (e.g., strollers, multi-DOF hinges), and extreme geometries is not systematically assessed.
- Equation/spec clarity: The controllable flow transformer loss appears malformed in print; full, precise formulation, conditioning specifics, and ablations on guidance strength are missing.
- Tokenizer independence: The claim of “no special tokens” leaves open how robust the format is across different tokenizers/languages and whether number-driven sequences induce undesirable token splits.
- Scale realism for robotics: Claims about “safe manipulation of delicate objects” lack quantitative success/damage metrics, and there is no sim-to-real validation of learned policies on generated assets.
- Licensing and reproducibility: Details on the release of code, trained models, annotations, and licensing of derivative assets (given PartNet-Mobility origins) are not clarified.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can leverage PhysX-Anything today, along with sectors, likely tools/workflows, and key assumptions or dependencies.
- Robotics and Embodied AI — Photo-to-Simulation Asset Pipeline
- Application: Turn a single photo of household or industrial objects into sim-ready 3D assets with articulation and physical properties, enabling rapid environment setup and policy training.
- Tools/Workflows: Photo → PhysX-Anything → URDF/XML + part-level meshes → import to MuJoCo-style engines (e.g., robopal/MuJoCo) → train manipulation policies (e.g., cabinet opening, faucet turning, eyeglasses handling).
- Assumptions/Dependencies: URDF/XML compatibility with the chosen simulator; sufficient GPU/compute; accuracy depends on image quality and category coverage; physical property inference may need spot checks for safety-critical tasks.
- Software/Simulation Infrastructure — Asset Authoring and Conversion
- Application: A “Photo-to-URDF/XML” authoring tool for engineers and researchers to generate articulated, physically parameterized assets directly from images.
- Tools/Workflows: Web or CLI service wrapping the VLM pipeline; export meshes, radiance fields, 3D Gaussians; automated unit tests validating articulation ranges and mass properties.
- Assumptions/Dependencies: Integration with existing build pipelines; licensing and governance for input photos; compute and storage for batch processing.
- Gaming and VR — Faster Interactive Asset Creation
- Application: Convert concept art or marketing images into interactive, physically plausible assets (with joints, colliders, and approximate materials) for Unity/Unreal workflows.
- Tools/Workflows: Image → PhysX-Anything → part-level meshes + rigid-body rigs → engine import and gameplay prototyping.
- Assumptions/Dependencies: Stylized art may degrade physical realism; manual artist pass still advised; export format bridges from URDF/XML to engine-native physics constraints.
- E-commerce and Retail — Interactive Product Visualization
- Application: Create physics-enabled product previews from catalog images (e.g., opening/closing mechanisms, size-aware placement).
- Tools/Workflows: Merchant uploads photo → PhysX-Anything generates sim asset → embed in web viewer for articulation demos and size/fit visualization.
- Assumptions/Dependencies: Single-image scale estimation uses priors and may require manual dimension calibration; material/density approximations may be coarse; IP permissions for product imagery.
- Education — Everyday Physics and Robotics Labs
- Application: Build classroom modules where students turn real-world object photos into simulation labs (articulation, mass, constraints) to study dynamics and control.
- Tools/Workflows: Course platform → student uploads photo → asset generation → simulator exercises (force/torque limits, joint ranges).
- Assumptions/Dependencies: Access to compatible simulators; simplified safety constraints for classroom use; instructor guidance on model validation.
- Industrial Training and Maintenance — Rapid Digital Twins for Equipment Familiarization
- Application: Generate preliminary digital twins of tools/equipment from photos for VR training on articulation/handling (e.g., latches, levers, panels).
- Tools/Workflows: Field snapshot → PhysX-Anything → URDF/XML → VR training environment with physics-based tasks.
- Assumptions/Dependencies: Single-view occlusions limit fidelity; physical attributes are approximations and may need expert review; safety-critical deployments require validation.
- Research — Benchmarking and Dataset Augmentation
- Application: Augment embodied AI datasets with sim-ready assets across 47 categories; evaluate physical reasoning and articulation understanding in VLMs.
- Tools/Workflows: PhysX-Mobility → model fine-tuning/evaluation; standardized URDF/XML assets for fair comparisons; user studies or VLM-based assessments.
- Assumptions/Dependencies: Dataset licensing and documentation; reproducible evaluation protocols; careful handling of in-the-wild distribution shifts.
- Insurance and Claims — Preliminary Object Reconstruction
- Application: Generate approximate 3D models with physical attributes from claim photos to visualize damage scenarios or assess replacement costs.
- Tools/Workflows: Claims portal ingestion → asset generation → scenario simulation (e.g., impact or stress).
- Assumptions/Dependencies: Accuracy bounded by single-image inference; requires disclaimers and expert oversight; legal and privacy compliance.
Long-Term Applications
The following use cases are high-impact but need additional research, scaling, or integration (e.g., multi-view reasoning, better material/scale estimation, standards).
- Robotics — On-the-Fly Manipulation of Novel Objects from a Single Image
- Application: Robots perceive a new object, auto-generate a sim-ready model (geometry, joints, mass), plan in simulation, and execute in the real world with minimal human intervention.
- Tools/Workflows: Perception → PhysX-Anything → sim policy planning → sim-to-real transfer with online adaptation and tactile feedback.
- Assumptions/Dependencies: Improved scale/material inference, robust domain adaptation, sensor fusion; safety verification for physical deployment.
- Facility and Home Digital Twins at Scale
- Application: Scene-level generation of articulated digital twins for homes/offices from photo inventories, enabling maintenance planning and ergonomic/safety assessments.
- Tools/Workflows: Multi-object scene capture → per-object sim-ready assets → assembly into scene graph → interactive simulation (HVAC access, cabinet layouts).
- Assumptions/Dependencies: Multi-view and scene SLAM integration; standardized scene formats; richer material/functional metadata.
- Autonomous Warehousing and Logistics
- Application: Create sim-ready models of new SKUs from catalog images to accelerate grasp planning, packing, and manipulation policy training.
- Tools/Workflows: Catalog ingestion → PhysX-Anything → warehouse simulation → policy deployment for picking/placing.
- Assumptions/Dependencies: Validation of density and friction properties; integration with WMS and robot controllers; regulatory compliance and product IP constraints.
- Healthcare and Assistive Robotics
- Application: Personalized manipulation policies for assistive devices (e.g., custom utensils, mobility aids) reconstructed from patient-provided images.
- Tools/Workflows: Clinician app → asset generation → simulation-based therapy planning → robot assistance.
- Assumptions/Dependencies: Medical device standards and approvals; robust physical fidelity and safety; protected health information handling.
- Consumer AR — Interactive Photo-to-AR with True Articulation
- Application: Smartphone apps that turn a photo into an interactive AR object with opening/closing parts and approximate physical behavior for planning and visualization.
- Tools/Workflows: Mobile capture → on-device/edge inference → ARKit/ARCore integration → measured placement.
- Assumptions/Dependencies: On-device efficiency; precise scale anchoring (e.g., fiducials/LiDAR); UI/UX for calibration.
- Public Policy and Standards — Physical-Attribute-Rich Object Schemas
- Application: Inform standards bodies on JSON/URDF schemas that encode articulation and physical properties for interoperable simulation assets across engines.
- Tools/Workflows: Consortium drafts → reference implementations → test suites → cross-engine compliance.
- Assumptions/Dependencies: Multi-stakeholder alignment; legal/IP frameworks; stability across simulator versions.
- Commercial Platforms — “Photo-to-Sim” SaaS and Marketplaces
- Application: Cloud services that convert images into sim-ready assets; marketplaces distributing vetted assets with physics metadata for robotics, games, and VR.
- Tools/Workflows: API endpoints; moderation pipelines for IP/safety; analytics on usage/performance.
- Assumptions/Dependencies: Scalable compute; content governance; customer integrations (Unity/Unreal/Isaac/ROS).
- Forensics and Safety Analysis
- Application: Reconstruction and simulation of incident objects from limited imagery to analyze articulation failures or hazardous interactions.
- Tools/Workflows: Case ingestion → asset generation → physics-based scenario tests.
- Assumptions/Dependencies: Multi-view requirement for high-stakes cases; evidentiary standards; expert validation.
- Sustainability and Product Design
- Application: Early-stage design exploration using photo-derived models to approximate physical behavior, aiding ergonomics and durability studies.
- Tools/Workflows: Design sprint tooling → simulation loops → rapid concept iteration.
- Assumptions/Dependencies: Enhanced materials modeling (beyond density); coupling with FEM/CFD where needed; designer-in-the-loop calibration.
Cross-Cutting Assumptions and Dependencies
- Generalization: Performance is strongest on covered categories (47 in PhysX-Mobility); rare or highly specialized objects may require fine-tuning or multi-view input.
- Physical Fidelity: Density, friction, and material properties are inferred; safety-critical use demands validation or measurement.
- Scale Estimation: Absolute scale benefits from VLM priors but may need calibration (reference objects, known dimensions).
- Input Quality: Occlusions, reflections, or stylization can degrade geometry or articulation inference.
- Compute and Integration: GPU resources are needed for high-throughput pipelines; exporters and adapters may be required for different engines (URDF/XML → native physics formats).
- Legal/IP: Use of product photos must comply with licensing; generated assets should be governed by clear IP and safety policies.
Glossary
- 3D Gaussians: A point-based 3D representation using anisotropic Gaussian primitives to model and render geometry and dynamics. "including mesh surfaces, radiance fields, and 3D Gaussians."
- Absolute scale: The real-world size of an object expressed in physical units, crucial for simulation and interaction. "such as density, absolute scale, and joint constraints"
- Affordance: The actionable possibilities an object offers based on its shape and physical properties. "\textcolor{color1}{Affordance} "
- Articulation: The structure of movable parts and joints within an object defining how parts can move relative to each other. "recovering both its articulation structure and physical properties"
- Articulated object: An object composed of multiple parts connected by joints allowing motion among parts. "Articulated object generation has attracted increasing attention due to its wide range of applications."
- Autoregressive modeling: A generative approach that predicts each token conditioned on previously generated tokens. "Beyond diffusion-based models, several works introduce autoregressive modeling into 3D generation"
- CD (Chamfer Distance): A geometric distance metric measuring similarity between two point sets or shapes. "CD "
- ControlNet: A conditioning framework for diffusion models that injects external guidance signals to control generation. "inspired by ControlNet~\cite{zhang2023adding}"
- Diffusion models: Generative models that synthesize data by iteratively denoising from random noise guided by learned score functions. "DreamFusion introduced the SDS loss, which leverages the strong prior of 2D diffusion models"
- Feed-forward methods: Non-iterative generative approaches that produce outputs in a single pass for efficiency and robustness. "Recently, feed-forward methods have become the mainstream in 3D generation due to their favorable efficiency and robustness"
- Flow transformer: A transformer-based architecture coupled with flow/diffusion principles to generate fine-grained geometry. "a controllable flow transformer inspired by ControlNet"
- F-score: The harmonic mean of precision and recall adapted to evaluate geometric reconstruction quality. "F-score "
- GANs (Generative Adversarial Networks): Generative models trained via adversarial objectives between a generator and a discriminator. "generative adversarial networks (GANs) played a central role in the early stage of this field"
- Janus problem: A failure mode in 3D generation where an object exhibits multiple inconsistent front faces or ambiguous geometry. "the multi-face Janus problem"
- Joint constraints: Limits and parameters that govern how joints can move (e.g., ranges, axes, and types). "such as density, absolute scale, and joint constraints"
- Kinematic graph: A graph representation of an articulated object’s links and joints encoding possible motions. "combining the kinematic graph of an articulated object with diffusion models"
- Kinematic parameters: Numerical descriptors of joint motion, such as axis location, motion range, and direction. "we convert key kinematic parameters into the voxel space"
- MuJoCo: A high-performance physics engine for model-based control and robotics simulation. "simulation-based experiments in a MuJoCo-style environment validate that our sim-ready assets can be directly used"
- PSNR (Peak Signal-to-Noise Ratio): A signal fidelity metric used to evaluate reconstructed geometry or render quality. "PSNR "
- Radiance fields: Continuous volumetric representations (e.g., NeRFs) that model color and density for view synthesis. "including mesh surfaces, radiance fields, and 3D Gaussians."
- Retrieval-based paradigm: A generation approach that selects existing assets from a library and augments them rather than synthesizing from scratch. "many of these methods adopt retrieval-based paradigms: they retrieve an existing 3D model and attach plausible motions"
- SDS loss (Score Distillation Sampling): A loss that distills guidance from a diffusion model into 3D optimization to enable text-to-3D. "DreamFusion introduced the SDS loss"
- Simulation-ready (sim-ready): Assets that include geometry, articulation, and physical attributes required for direct deployment in physics simulators. "the first simulation-ready (sim-ready) physical 3D generative paradigm"
- Structured latent diffusion model: A diffusion model trained in a structured latent space tailored for efficient and scalable 3D generation. "we adopt a pre-trained structured latent diffusion model~\cite{trellis} to generate 3D assets"
- Token budget: The maximum number of tokens a model can process in its context, constraining input representation length. "the limited token budget of VLMs"
- Tokenizer: The component that converts input data (text or serialized geometry) into discrete tokens for a model. "introducing additional special tokens and a new tokenizer for geometry"
- URDF (Unified Robot Description Format): An XML-based format for describing robot models, links, joints, and physical properties. "exports URDF and XML files that can be directly deployed in physics engines"
- Vertex quantization: Discretizing mesh vertex coordinates to reduce precision and token sequence length for serialization. "text-serialized representations based on vertex quantization"
- Vision–LLM (VLM): A multimodal model that jointly understands images and text to perform tasks like conditioned 3D generation. "motivated by the strong performance of visionâLLMs (VLMs), recent approaches have begun to employ VLMs to generate 3D assets"
- Voxel-based representation: A volumetric grid (voxels) encoding occupancy or attributes to represent 3D geometry explicitly. "Motivated by the impressive trade-off between fidelity and efficiency of voxel-based representations"
- VQ-GAN (Vector-Quantized GAN): A generative model that uses vector quantization in a GAN framework to compress and synthesize discrete latents. "3D VQ-GAN~\cite{ye2025shapellm} can further compress geometric tokens"
- VQ-VAE (Vector-Quantized VAE): A variational autoencoder with discrete latent codes via vector quantization for compact representation. "ShapeLLM-Omni adopts a 3D VQ-VAE to compress the token sequence length"
Collections
Sign up for free to add this paper to one or more collections.