- The paper introduces a dual-branch architecture that fuses a pretrained video diffusion backbone with a physics-aware latent branch to internalize dynamic physical laws.
- The paper demonstrates significant improvements, including a 50.4% boost in Physical Commonsense and enhanced semantic adherence across multiple benchmarks.
- The paper leverages bidirectional cross-attention and recursive loss balancing to achieve stable joint modeling of visual and physical dynamics in video generation.
Physics-Infused Video Generation: A Technical Review of Phantom (2604.08503)
Problem Motivation and Approach
The paper "Phantom: Physics-Infused Video Generation via Joint Modeling of Visual and Latent Physical Dynamics" (2604.08503) addresses a critical challenge in generative video modeling: existing models excel in visual realism but fail to capture the underlying physical laws governing dynamic behavior. Scaling data and model size has not bridged this gap. The authors propose direct integration of latent physical inference and prediction into the generative pipeline, disallowing reliance on post-hoc prompt engineering or external simulators.
Phantom (\videogen{}) introduces a dual-branch flow-matching architecture, coupling a pretrained video diffusion backbone (Wan2.2-TI2V-5B) with a dedicated physics branch. The latter operates in a physics-aware latent space derived from V-JEPA2, a self-supervised video encoder shown to capture intuitive physics properties.
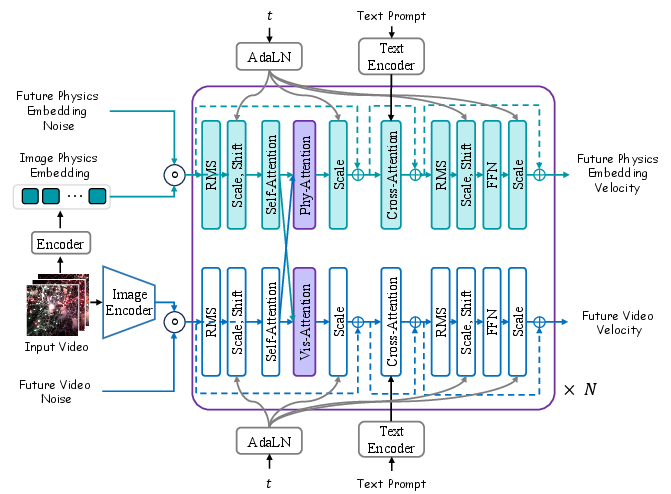
Figure 1: Overview of \videogen{}, illustrating parallel visual and physics latent flow-matching branches with bidirectional cross-attention for joint modeling of visual and physical dynamics.
Architecture and Training Paradigm
Phantom's architecture consists of two parallel latent branches: the visual branch (reusing Wan2.2 modules) and the physics branch (initialized from scratch). Both branches encode observed frames into modality-specific latent spaces. Visual latents are processed by a video VAE encoder; physical latents are extracted via V-JEPA2, whose representations have empirically demonstrated strong intuitive physics priors.
Bidirectional cross-attention layers allow dynamic modulation between branches, balancing modality-specific expressivity and information exchange. This explicit separation avoids feature entanglement instability seen in joint-attention alternatives, while tightly coupling the evolution of visual and latent physical states.
During training, all visual branch parameters are frozen, preserving generative priors, while the physics branch and cross-attention layers are optimized. The visual and physics loss terms are balanced using a recursive weighting schedule, mitigating instability due to high gradient magnitudes in the physics branch.
Physical Consistency and Quantitative Evaluation
Phantom was trained on OpenVidHD-0.4M, leveraging text-to-video and text-/image-to-video modes with variable context lengths. Quantitative evaluation employs VBench-2, VideoPhy, VideoPhy-2, and Physics-IQ—benchmarks designed to probe physical commonsense, semantic adherence, and real-world reasoning.
The model consistently outperformed general-purpose and physics-focused baselines:
- On VideoPhy, Phantom improves Semantic Adherence by 14.5% and Physical Commonsense by 50.4% relative to Wan2.2-TI2V-5B.
- Physics-IQ scores increase by 33.9% (single-frame), demonstrating superior extrapolation from real-world motion.
- VBench-2 reveals enhancements in Human Fidelity (+2.7%), Physics (+6.0%), and Controllability (+9.4%); composition is improved (+11.7%), though diversity scores drop, attributable to suppression of unrealistic variation.
These results confirm that joint modeling of physics-aware latent states enables the generation of sequences congruent with real-world dynamics, without compromising perceptual quality.
Qualitative Analysis
The paper presents diverse qualitative comparisons on text-to-video and text-/image-to-video generation tasks.

Figure 2: Qualitative comparison between Wan2.2-TI2V and Phantom on scenarios like object deformation and pouring, demonstrating improved motion plausibility and semantic alignment.

Figure 3: Text-/Image-to-Video generation samples; conditioning frame marked in red. Phantom exhibits proper temporal causality and maintains physical realism during material interactions.

Figure 4: Text-to-Video generation examples; Phantom captures correct momentum transfer and material deformation, illustrating internalized physics-aware modeling.
Particularly notable are cases involving elasticity, contact, buoyancy, and fluid viscosity. The base model frequently produces abrupt halting, semantic drift, or violates momentum conservation; Phantom maintains continuity and respects physical constraints. In force-conditioned video generation (Figure 5), Phantom responds correctly to spatially-localized external forces, indicating generalization to explicit physical control signals.

Figure 5: Force-conditioned video generation results. Phantom successfully synthesizes motion consistent with temporally aligned external force inputs.
Implications and Future Directions
Phantom demonstrates that embedding a physics-aware latent mechanism alongside visual generation substantially improves physical consistency across challenging benchmarks. The approach circumvents limitations of simulator-driven or inference-time guided models by directly internalizing physics dynamics within the generative process. The results validate the hypothesis that next-frame prediction objectives alone are insufficient for generalizable physical reasoning, motivating further integration of structured latent dynamics.
Potential future developments include extending latent physical representations to more granular control (e.g., force, torque, multi-material phenomena), leveraging multi-modal physics sensors, and integrating Phantom into world model frameworks for downstream reasoning tasks. Intrinsic modeling of physics-aware states may lead to advances in robust simulation, video-based reinforcement learning, and controlled generative planning.
Conclusion
Phantom (\videogen{}) advances video generation by jointly modeling visual and latent physical dynamics within a unified flow-matching generative paradigm. By coupling a pretrained backbone with a physics-aware branch, the model reliably synthesizes physically plausible video sequences, outperforming existing baselines in both perceptual realism and physical adherence. The integration of internalized physics-aware representations sets a foundation for future progress in physically consistent generative modeling and world simulation.