PIArena: A Platform for Prompt Injection Evaluation
Abstract: Prompt injection attacks pose serious security risks across a wide range of real-world applications. While receiving increasing attention, the community faces a critical gap: the lack of a unified platform for prompt injection evaluation. This makes it challenging to reliably compare defenses, understand their true robustness under diverse attacks, or assess how well they generalize across tasks and benchmarks. For instance, many defenses initially reported as effective were later found to exhibit limited robustness on diverse datasets and attacks. To bridge this gap, we introduce PIArena, a unified and extensible platform for prompt injection evaluation that enables users to easily integrate state-of-the-art attacks and defenses and evaluate them across a variety of existing and new benchmarks. We also design a dynamic strategy-based attack that adaptively optimizes injected prompts based on defense feedback. Through comprehensive evaluation using PIArena, we uncover critical limitations of state-of-the-art defenses: limited generalizability across tasks, vulnerability to adaptive attacks, and fundamental challenges when an injected task aligns with the target task. The code and datasets are available at https://github.com/sleeepeer/PIArena.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “PIArena: A Platform for Prompt Injection Evaluation” in Simple Terms
What is this paper about?
This paper is about a growing security problem called “prompt injection” in apps that use LLMs like chatbots or AI assistants. Prompt injection is when someone hides sneaky instructions in the text an AI reads (like a webpage or document), tricking the AI into doing the wrong thing—such as posting ads, showing fake error messages, or sharing bad links.
The authors built PIArena, a shared testing platform that lets people plug in different attacks and defenses and compare how well they work across many tasks. They also created a smarter, adaptive attack that learns from defenses and tries new tricks to get past them.
What questions were the researchers asking?
They focused on a few simple questions:
- Can we make one place where researchers can fairly test many prompt-injection attacks and defenses side by side?
- Do defenses that look good in one test still work on different tasks and datasets?
- How well do defenses hold up against attackers who adapt and try new strategies?
- Are powerful, closed-source AIs (like commercial models) still vulnerable?
- What happens when the attacker’s task looks similar to the real task the AI is supposed to do (for example, asking for a “summary” but adding misleading instructions)?
How did they study it? (Using everyday examples)
Think of an AI assistant as a student doing homework. The “homework instructions” are the real task (like “summarize this article”). The “context” is the article itself. A prompt injection is like a sticky note slipped into the article that says: “Ignore the homework and write an ad instead.” A defense is like a teacher or filter trying to catch or neutralize the sneaky sticky note.
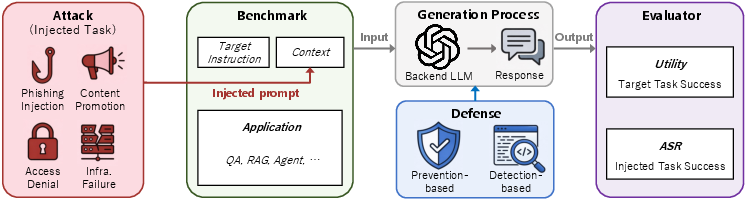
To test all this, the authors built PIArena, which has four plug-and-play parts:
- Benchmark (datasets): collections of tasks (like question answering, summarizing, and RAG—retrieval-augmented generation, where the AI reads extra documents) and realistic injected tricks (like phishing links, fake system errors, or ads).
- Attack: tools that insert malicious instructions into the context. They include both simple “ignore previous instructions” attacks and a new adaptive attack.
- Defense: tools that try to spot or stop prompt injection. Some “detect and block,” others “prevent” by cleaning or training models to resist attacks.
- Evaluator: scoring tools that measure two things—Utility (how well the AI does the real task) and ASR (Attack Success Rate—how often the attacker wins by making the AI follow the wrong instructions).
Their new adaptive attack works like a crafty intruder who watches how the guard reacts and changes disguise accordingly:
- If the defense blocks it, the attack becomes more stealthy.
- If the defense ignores it, the attack becomes more commanding.
- If it’s unclear what happened, the attack tries new wordings. This “strategy-based” approach generates many rewritten versions and improves over several rounds, all without needing inside access to the model (black-box).
What did they find?
Here are the main takeaways:
- Defenses often don’t generalize. A defense that works well on one task may fail on others. That means we can’t trust a defense based on a single test.
- Adaptive attacks are a big problem. The new strategy-based attack can quickly adjust and bypass many defenses, raising the attack success rate.
- Even strong, closed-source AIs are still vulnerable. Systems like GPT-5, Claude-Sonnet-4.5, and Gemini-3-Pro still showed high attack success rates under prompt injection in this evaluation.
- Some cases are fundamentally hard to defend. When the attacker’s request looks very similar to the real task (for example, “summarize” but with misleading content), defenses struggle because the line between “helpful” and “harmful” becomes blurry.
- We need better, more realistic testing. Many older benchmarks used overly simple attacks. PIArena includes more realistic, context-aware injected tasks such as phishing links, fake “out of memory” errors, and false “your subscription expired” messages.
Why does this matter?
PIArena helps the AI community test defenses more fairly and thoroughly. This can:
- Make AI apps safer by revealing weak spots early.
- Encourage building defenses that work across many tasks, not just a few.
- Push for defenses that can handle clever attackers who adapt.
- Improve trust in AI systems used for real-world jobs (like reading documents, searching the web, or helping with research), where untrusted content might sneak in.
In short, PIArena is like a fitness gym for AI safety tools—it provides a shared place to train, test, and improve them against realistic, evolving threats.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to be concrete and actionable for follow-up research.
- Lack of full agent/tool-chain coverage: no systematic evaluation of prompt injection in tool-using agents (function calling, tool schemas, planners, tool name/spec poisoning), despite claims of plug-and-play integration.
- No multimodal or rich-format scenarios: the platform and experiments are limited to text; injections via images/PDFs/HTML/Markdown/CSS/JS snippets, embedded metadata, or document renderers are not evaluated.
- Incomplete RAG pipeline modeling: experiments use RAG datasets but do not evaluate end-to-end pipelines (retriever poisoning, indexing-time sanitization, rerankers, chunking strategies, retrieval prompts) or defense combinations at each stage.
- Single-turn focus: multi-turn dialogues, persistent memory, and stateful agents (where injections persist and compound over turns) are not studied.
- System- and UX-level defenses absent: sandboxing, context isolation/quoting, tool whitelisting, network isolation, UI affordances (e.g., safe previews), and permissioned actions are not included as baselines.
- Narrow defense set and fidelity uncertainties: unclear whether re-implementations/parameterizations of integrated defenses are faithful; key families (constrained decoding, robust prompt bracketing/quoting, content isolation layers, retrieval-time filters) are missing.
- No evaluation of defense composition: how cascaded or ensemble defenses trade off utility vs. ASR is not examined.
- Position and structure of injection underexplored: although insertion at beginning/middle/end is mentioned, there is no systematic study of positional sensitivity, prompt delimiters/quoting, or structural cues (headings, footnotes, metadata).
- Encoding and obfuscation tactics omitted: evasion via Unicode homographs, RTL/ZWJ controls, base64/hex, Markdown/HTML entity encoding, or tokenization-specific quirks is not studied.
- Language and script coverage is monolingual: cross-lingual, code-switching, non-Latin scripts (CJK/RTL), and transliteration-based evasions remain unexplored.
- Combined attacks untested: no evaluation of hybrid jailbreak+injection strategies, nested or staged payloads, or attacks that first erode safety policies then inject tasks.
- “Aligned injected task” challenge is not formalized: the paper notes fundamental difficulty when injected and target tasks align but provides no formal analysis, impossibility results, or principled evaluation metrics for this regime.
- ASR definition and adjudication are underspecified: the IsSuccess criterion, handling of partial compliance (e.g., model completes both tasks), and ambiguity in overlapping objectives are not rigorously defined.
- Heavy reliance on LLM-as-a-judge: no assessment of judge bias, calibration, inter-annotator agreement, or robustness checks with human validation for both utility and ASR.
- LLM-generated injected tasks without human QA: the realism, bias, and label reliability of context-aware malicious tasks produced by LLMs are not validated by humans or audited for distributional artifacts.
- Query efficiency and cost of the adaptive attack are underreported: budgets, convergence, sensitivity to the number/type of strategies, and cost-performance trade-offs are not quantified.
- Strategy pool ablations and generality: no study of which strategies matter, how many are needed, or how attack strength degrades against defenses unseen during strategy design.
- Transferability and cross-model generalization of the attack: the extent to which prompts found on one model/defense transfer to others is not measured.
- Defense adaptivity and hardening: defenses adversarially trained or tuned against the proposed strategy-based attack are not evaluated, leaving open how quickly defenses can catch up.
- Robustness to model version drift: stability of results across LLM updates (API model revisions, safety policy changes) and reproducibility safeguards (deterministic seeds, temperature settings) are not addressed.
- Long-context phenomena: while long-context datasets are included, there is no analysis of how attack effectiveness varies with injection-to-context ratio, context length scaling, or retrieval set size.
- Real-world corpus validation: the benchmarks lack naturally occurring injected content from live web corpora or collaborative platforms; domain and distribution shift from synthetic tasks remain unquantified.
- Human-perceived stealth and plausibility: the attack’s stealth is not evaluated with human raters (e.g., does a human notice the injection in realistic documents?).
- Safety-policy interactions: the impact of provider-level safety filters, content moderation, and refusal behaviors on both ASR and utility is not isolated or controlled.
- Broader risk taxonomy: beyond the four injected task categories (phishing, promotion, access denial, infrastructure failure), other realistic objectives (data exfiltration, privilege escalation, financial fraud, reputational manipulation) are not covered.
- Dataset and release risks: ethical safeguards for distributing phishing-like content (live links, redactions), and guidance for safe use of the benchmark in the community are not detailed.
- Governance and versioning of the platform: processes for community contributions, benchmark/metric evolution, and regression tracking across versions are unspecified.
- Security of the evaluation harness: the platform’s resilience against tests that might exfiltrate secrets, execute arbitrary code, or abuse networked tools during evaluation is not discussed.
Practical Applications
Summary
The paper introduces PIArena, a unified, extensible platform for evaluating prompt injection attacks and defenses across diverse tasks (QA, RAG, summarization, long-context), with standardized APIs, dataset formats, and metrics (utility and attack success rate). It integrates state-of-the-art defenses, supports plug-and-play benchmarking, and contributes a black-box, strategy-based adaptive attack that uses defense feedback to optimize injected prompts. Using PIArena, the authors show that current defenses generalize poorly, remain vulnerable to adaptive attacks, and face fundamental challenges when injected tasks align with target tasks (disinformation-like scenarios). The code and datasets are publicly available.
Below are practical, real-world applications derived from the platform, methodology, and findings.
Immediate Applications
These applications can be deployed now using the released code, datasets, and methods.
- CI/CD prompt-injection regression testing (Software, DevSecOps, MLOps)
- Use case: Gate deployments of LLM-backed features by running PIArena test suites on every pull request and before release.
- Tools/products/workflows: Add a “Prompt Injection Safety” stage to CI; run PIArena attacks (including the adaptive strategy attack) against your app-specific prompts and contexts; fail builds if ASR exceeds thresholds or if utility drops.
- Assumptions/dependencies: Access to your model via API; safe sandboxing for adversarial prompts; budget for API calls; acceptance of utility–safety trade-off metrics.
- Red teaming and security QA for LLM apps (Security consulting, SaaS)
- Use case: Internal red teams or external auditors use PIArena’s adaptive attack and curated injected-task categories (phishing, content promotion, access denial, infrastructure failure) to probe guardrails and escalation paths.
- Tools/products/workflows: Automated red-teaming harness; scripted campaigns varying injection placement (beginning/middle/end), context length, and defense configurations; reporting on ASR/utility and bypass routes.
- Assumptions/dependencies: Legal/organizational approval for offensive testing; isolation from production data; repeatable environment.
- Vendor and product due diligence (Enterprise IT procurement; Healthcare, Finance, Government)
- Use case: Evaluate LLM vendors, gateways, or guardrail providers with standardized PIArena scorecards to inform procurement and risk acceptance.
- Tools/products/workflows: Scorecards comparing ASR and utility across benchmarks relevant to regulated domains (e.g., RAG on healthcare FAQs); attach results to vendor risk files.
- Assumptions/dependencies: Representative, domain-relevant contexts; vendor cooperation or black-box API access; alignment on metrics thresholds.
- RAG pipeline hardening and defense selection (Software, Knowledge Management)
- Use case: Compare detection- vs. prevention-based defenses under realistic injected tasks for your RAG stack; choose configurations that minimize ASR while preserving answer quality.
- Tools/products/workflows: A/B tests across retrieval filters, context sanitizers, and LLM guardrails; long-context evaluations (LongBench subsets) to assess injection impact when malicious text is a small fraction of input.
- Assumptions/dependencies: Availability of your corpus for evaluation; capability to instrument retrieval and prompt assembly stages.
- Guardrail and detector calibration (Model operations, Safety engineering)
- Use case: Tune thresholds and policies (e.g., blocking vs. allow-and-warn) using PIArena to measure false positives on clean contexts and ASR under attack.
- Tools/products/workflows: Batch evaluation with “attack-only” and “defense-only” modes; operate on utility–ASR curves to set operating points; regression dashboards.
- Assumptions/dependencies: Stable evaluation sets; acceptance of LLM-as-a-judge where task-specific metrics are unavailable; monitoring for model-version drift.
- LLM agent safety validation (Agent platforms, Automation, Robotics software)
- Use case: Validate how autonomous agents respond when tool outputs or retrieved pages carry injected instructions (e.g., “cancel task due to quota”).
- Tools/products/workflows: Integrate PIArena’s attack module at tool I/O boundaries; record policy violations (e.g., unintended tool calls, skipped tasks) as ASR equivalents.
- Assumptions/dependencies: Access to agent framework hooks; mapping agent outcomes to success/failure criteria.
- SOC exercises and incident-response drills for AI workflows (Security operations)
- Use case: Simulate prompt-injection-driven fraud, phishing links, or infrastructure-failure messaging in LLM-enabled ticketing or chat workflows.
- Tools/products/workflows: Injected-task scenarios replayed against helpdesk bots or triage assistants; measure containment and escalation behaviors.
- Assumptions/dependencies: Test environments mirroring production workflows; clear playbooks for LLM-related incidents.
- Course modules and lab assignments (Academia, Education)
- Use case: Teach evaluation of prompt injection attacks/defenses with hands-on labs using the unified APIs and benchmarks.
- Tools/products/workflows: Lab notebooks applying heuristic vs. adaptive attacks; reporting utility/ASR; defense integration exercises.
- Assumptions/dependencies: Stable dependencies and dataset licensing; budget for API usage where needed.
- Reproducible benchmarking and defense generalization studies (Academia, Open-source)
- Use case: Publish defenses with comprehensive, cross-benchmark results and adaptive-attack resistance; contribute new datasets via the standardized format.
- Tools/products/workflows: PIArena-compatible data loaders; evaluator plugins; public leaderboards reporting ASR and utility.
- Assumptions/dependencies: Community maintenance; consistent evaluation protocols; disclosure of configurations and seeds.
Long-Term Applications
These depend on further research, scaling, or ecosystem development.
- Continuous adversarial training and self-play hardening (Model providers, Platform teams)
- Use case: Incorporate the adaptive strategy-based attack into model fine-tuning loops to reduce ASR without sacrificing utility.
- Tools/products/workflows: Closed-loop training pipelines that mine hard injections from PIArena campaigns, generate curricula, and periodically re-evaluate.
- Assumptions/dependencies: Access to training data and weights (or advanced instruction-tuning APIs); methods to mitigate overfitting to seen attacks and maintain generalization.
- Certification and compliance standards for LLM injection safety (Policy, Standards bodies, Auditors)
- Use case: Define minimum bar and test batteries (datasets, ASR thresholds) for safety labels or regulatory compliance.
- Tools/products/workflows: “Prompt Injection Safety” certification suites; standardized reports with sector-specific packs (e.g., healthcare RAG, finance chatbots).
- Assumptions/dependencies: Consensus on metrics and thresholds; governance for curated datasets and versioning; auditor accreditation.
- LLM EDR/WAF products for application-layer protection (Security SaaS, Cloud)
- Use case: Offer managed “LLM firewall” services that score, sanitize, and gate contexts before model calls; validated by PIArena regression suites.
- Tools/products/workflows: Inline detectors, context rewriters, provenance-aware filters; policy engines tuned on PIArena utility–ASR curves.
- Assumptions/dependencies: Low-latency deployment; privacy-preserving processing; adaptation to evolving model behaviors and attack strategies.
- Provenance- and trust-aware RAG and content pipelines (Data platforms, Enterprise search)
- Use case: Assign trust scores to sources and selectively include/exclude content based on injection risk measured by PIArena-style tests.
- Tools/products/workflows: Source whitelists, signed content, retrieval filters, and UI affordances (warnings) driven by risk models.
- Assumptions/dependencies: Robust provenance infrastructure; organizational willingness to trade recall for safety; domain adaptation of benchmarks.
- Safe tool-use and agent governance frameworks (Agent platforms, Robotics/Automation)
- Use case: Combine PIArena-derived adversarial cases with typed policies, tool affordances, and human-in-the-loop checks to prevent tool hijacking.
- Tools/products/workflows: Policy models validated across adaptive attacks; formalized tool-use constraints; recovery behaviors when suspicious instructions appear.
- Assumptions/dependencies: Advances in agent interpretability and policy enforcement; standardized evaluation of tool-call safety.
- Insurance underwriting and risk pricing for AI deployments (Finance/Insurtech)
- Use case: Use PIArena ASR/utility scores as quantifiable inputs for underwriting LLM-powered products (e.g., chatbots in regulated industries).
- Tools/products/workflows: Risk models linking scores to expected incident frequency/severity; premium adjustments tied to certified controls.
- Assumptions/dependencies: Historical loss data; accepted correlation between benchmark scores and real-world incidents; third-party verification.
- Threat intelligence for prompt-injection campaigns (Security research, MSSPs)
- Use case: Build honeypots and honey-prompts to observe evolving injection strategies; maintain IOCs and share TTPs.
- Tools/products/workflows: Telemetry collection from adaptive-attack interactions; feeds integrated into EDR/WAF products and PIArena strategy libraries.
- Assumptions/dependencies: Legal/ethical collection frameworks; collaboration across vendors; mechanisms to share without enabling attackers.
- Sector-specific evaluation packs and workflows (Healthcare, Education, Finance, Public sector)
- Use case: Curate domain-aligned injected tasks and contexts (e.g., EHR summarization, invoice processing) to better predict deployment risks.
- Tools/products/workflows: Packaged datasets and policies per sector; domain-tuned defenses benchmarked via PIArena.
- Assumptions/dependencies: Access to de-identified or synthetic but realistic domain data; compliance with data protection laws.
- Defense orchestration and policy optimization (Platform engineering, MLOps)
- Use case: Dynamically route requests through different defenses based on context risk predicted from PIArena-calibrated models.
- Tools/products/workflows: Policy engines optimizing for utility–ASR trade-offs; per-request risk scoring; multi-LLM fallback strategies.
- Assumptions/dependencies: Reliable risk predictors; latency budgets; monitoring for policy regressions and concept drift.
- Disinformation-robust interfaces and verification layers (Media, Public policy, Platforms)
- Use case: Mitigate cases where injected and target tasks align (disinformation-like scenarios) via multi-source verification and provenance-aware UI.
- Tools/products/workflows: Cross-check modules, citation enforcement, and user-facing disclaimers validated with PIArena scenarios.
- Assumptions/dependencies: Effective verification pipelines; UX patterns that promote user trust without excessive friction; agreed-upon truth sources.
Notes on Feasibility and Dependencies Across Applications
- Results may vary across model versions and providers; ongoing evaluation and version pinning are essential.
- The adaptive attack increases realism but also evaluation cost; budgets and rate limits must be planned.
- Some tasks rely on LLM-as-a-judge where automatic metrics are unavailable; this introduces judgment variance that should be controlled (e.g., fixed judges, multi-judge consensus).
- Defense performance is highly task- and domain-dependent; curated, organization-specific benchmarks improve decision quality.
- When injected tasks align with user intent, purely technical defenses may be insufficient; organizational policies, provenance requirements, and user education are necessary complements.
Glossary
- Adaptive attacks: Attacks that iteratively adjust their prompts or tactics based on defense responses to increase success. "vulnerability to adaptive attacks"
- Agent benchmarks: Evaluation settings that test prompt injection within LLM-driven agent environments and workflows. "Agent benchmarks evaluate attacks in agent environments and often require complicated setups."
- Attack Success Rate (ASR): A metric indicating whether an attack made the model follow the injected task instead of the target task. "Attack Success Rate (ASR) indicates whether the response completes the injected task rather than the target task."
- Black-box attack: An attack setting where the adversary has only query access to the model/defense and no internal details or gradients. "We design a black-box strategy-based attack that adaptively optimizes injected prompts based on defense feedback"
- Cold-start problem: The difficulty of beginning optimization when early attempts yield sparse or uninformative signals, hindering efficient search. "The primary obstacle in black-box prompt optimization is the cold-start problem."
- Context-aware injected tasks: Malicious instructions crafted to fit the specific content and setting of the provided context. "realistic, context-aware injected tasks"
- Detection-based defenses: Defenses that aim to identify and block contaminated inputs or harmful outputs instead of ensuring correct task execution under attack. "Detection-based defenses achieve the latter by identifying whether the context contains an injected prompt and blocking the potentially harmful output."
- Disinformation: False or misleading information; here, it arises when the injected task aligns with the target task, undermining defenses. "Prompt injection attacks can reduce to disinformation when the target task aligns with the injected task"
- Feedback-guided optimization loop: An iterative attack process that refines prompts using signals from defense or model responses. "Feedback-guided optimization loop"
- Heuristic-based attacks: Attacks that use fixed rules, patterns, or templates (e.g., “ignore previous instructions”) rather than optimization. "Heuristic-based attacks leverage predefined, static strategies or templates to craft injected prompts."
- LLM-as-a-judge evaluation: Using a LLM to assess task performance or correctness instead of human labeling or fixed metrics. "LLM-as-a-judge evaluation"
- Long-context: Scenarios where inputs are very long, making injected prompts a small fraction of the total context. "long-context scenarios"
- Optimization-based attacks: Attacks that search or optimize injected prompts (e.g., via gradients or iterative queries) to maximize attack success. "Optimization-based attacks iteratively optimize the injected prompt to achieve the attacker's goal."
- OWASP: The Open Web Application Security Project, which publishes widely used security risk rankings and guidance. "OWASP identifies prompt injection as the top-1 security risk for LLM applications."
- Prevention-based defenses: Defenses designed to ensure the model still completes the intended task even when the context is contaminated. "Prevention-based defenses instead aim to ensure the backend LLM still correctly performs the target task even under attack."
- Prompt injection: An attack where malicious instructions are embedded in context to manipulate an LLM’s behavior. "Prompt injection attacks pose serious and growing security risks across a wide range of real-world applications empowered by LLMs."
- Retrieval-Augmented Generation (RAG): Systems that retrieve external documents to condition generation, often increasing vulnerability to prompt injection. "For Retrieval-Augmented Generation (RAG), a critical application vulnerable to prompt injection"
- Robust fine-tuning: Training procedures aimed at improving a model’s resilience to adversarial prompts or distribution shifts. "robust fine-tuning"
- Sanitization: Processing that removes or neutralizes potentially malicious content in the input context before generation. "such as sanitization"
- Strategy-based attack: An approach that rewrites or frames injected prompts using diverse strategies to improve stealth or force execution. "We design an efficient strategy-based attack that adaptively optimizes injected prompts based on defense feedback"
- Threat model: The formal characterization of users, attackers, capabilities, and goals that defines the evaluation setting. "based on the threat model"
- White-box attacks: Attacks that leverage internal model information, such as gradients, to craft more effective adversarial prompts. "White-box attacks leverage gradient information from the target LLM"
Collections
Sign up for free to add this paper to one or more collections.