- The paper presents a CPU-free serving stack that offloads LLM orchestration to GPU and SmartNIC, eliminating host CPU involvement.
- It employs device-side CUDA scheduling and DPU-based tokenization to achieve up to 8.47× lower tail latency and 2.1× higher throughput.
- The approach ensures improved energy efficiency and performance isolation, enabling scalable and robust datacenter deployments.
CPU-Free LLM Inference: The Blink Serving Architecture
Motivation and Problem Analysis
LLM inference is a dominant datacenter service, yet the critical path in mainstream serving stacks remains host-CPU-centric. Existing systems (e.g., vLLM, SGLang, TensorRT-LLM) depend on the CPU for token-level orchestration: request admission, continuous batching, kernel dispatch, and KV-cache management. Such coupling renders inference highly sensitive to CPU resource contention, especially in multi-tenant deployments. Empirical analysis shows severe throughput degradation and tail-latency inflation under moderate CPU interference, with baseline systems retaining only 28–54% of their isolated throughput. Conventional datacenter mitigations (huge pages, core pinning, cache partitioning) are fundamentally ineffective in preventing interference-induced performance degradation due to irreducible host-side orchestration overhead.
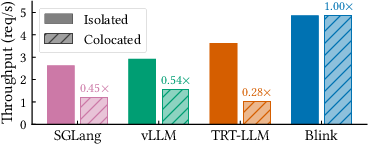
Figure 1: Throughput comparison on Qwen-3, demonstrating that Blink is unaffected by colocation while baselines degrade; annotations show the ratio between colocated and isolated throughput.
Architecture: Eliminating the Host CPU from the Critical Path
Blink proposes a serving stack with the host CPU removed from the steady-state path. The serving responsibilities are restructured: the SmartNIC (DPU) takes over request ingress and handles protocol parsing, tokenization, and streaming, directly placing input tokens into GPU memory via RDMA. The GPU maintains a persistent CUDA scheduler kernel implementing batching, KV-cache management, and device-side graph launch, enabling continuous batching and per-token scheduling without host intervention.
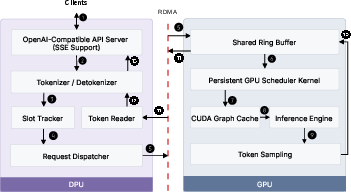
Figure 2: Blink architecture, where after initialization, only DPU and GPU are involved in inference; circles trace a request’s lifecycle from network ingress to token generation.
SmartNICs (DPU) excel in network and memory bandwidth per core, making them apt for transport and request management. The GPU handles latency-critical scheduling through a persistent kernel that scans a ring buffer (shared via one-sided RDMA) for incoming requests and manages decode state transitions. Device-side CUDA graph launch (fire-and-forget mode) minimizes kernel dispatch latency and enables unbounded token generation with amortized launch-window recovery.
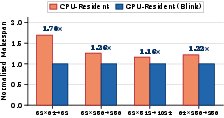
Figure 3: Normalized makespan for CPU- vs. GPU-resident scheduling; GPU scheduling eliminates per-token PCIe round-trip, with 1.16–1.70× reduction in makespan.
Blink is evaluated against TRT-LLM, vLLM, and SGLang across four models (Llama-3 8B, Phi-4 15B, Qwen-3 32B, Qwen-3 30B-A3B). Under isolation, Blink achieves up to 8.47× lower P99 time-to-first-token (TTFT), up to 3.40× lower P99 time-per-output-token (TPOT), and up to 2.1× higher decode throughput. For example, on Qwen-3 30B-A3B, baselines incur 3.45–8.47× higher TTFT and 1.85–3.40× higher TPOT. Device-side orchestration yields these gains by removing host scheduling and kernel dispatch from the per-token loop.
Blink’s performance remains stable under CPU interference, sustaining up to 6.46× higher decode throughput and 4.87× higher request throughput than baselines, whose throughput collapses (only retaining 28–48% of isolated capacity). Tail latency is virtually unchanged: TTFT and TPOT inflation under interference stays within 1.14× and 1.04×, respectively, for Blink, whereas baselines inflate up to 18.84× and 11.1×.
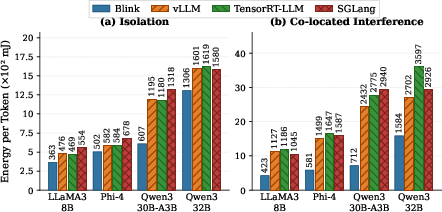
Figure 4: Energy per token under isolated and interference conditions; Blink achieves up to 48.6% lower energy per token in isolation, and up to 70.7% under interference.
Blink’s efficiency translates directly to lower energy consumption. It achieves up to 48.6% lower energy per token in isolation and up to 70.7% under interference compared to baseline systems, which is attributable to stable throughput as wall power remains comparable across systems.
Tokenization and prompt handling are offloaded to the DPU. Blink’s tokenizer, implemented on ARM A78 cores, outperforms HuggingFace’s and llama.cpp’s tokenizers on Xeon by 8–19.7× across input lengths, avoiding a bottleneck even at scale.
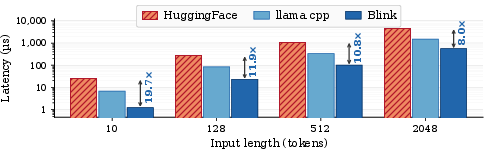
Figure 5: Tokenization latency comparison on BlueField-3 ARM vs. Intel Xeon; Blink delivers 8–19.7× speedup over HuggingFace.
System Extensibility and Practical Deployment
Blink is compatible with any model compiled for TensorRT and supports dense, MoE, and encoder-decoder architectures with no modifications. Scheduling policies (e.g., FCFS, continuous batching) and device-side optimizations (chunked prefill, prefix caching, speculative decoding, KV offloading) are orthogonal and integrable within Blink's GPU-resident scheduler. Multi-GPU extensions (tensor/pipeline parallelism) require replica schedulers and GPU-native communication primitives (NCCL, IBGDA) without violating CPU-free critical path constraints.
Blink’s OpenAI-compatible HTTP interface and SSE streaming enable drop-in deployment. The architecture cleanly decouples provisioning/init (CPU involvement) from steady-state inference (DPU+GPU only), facilitating server consolidation and resource sharing.
Prior SmartNIC-based inference systems (Lynx, SplitRPC, Conspirator, OS2G) operate on one-shot or job-level granularity and retain host CPU on the critical path, lacking support for autoregressive LLM features like token-level continuous batching and KV-cache management. Typical optimizations focus on improving host-driven orchestration (continuous batching, memory efficiency) whereas Blink eliminates host orchestration entirely, establishing persistent accelerator-native control.
Conclusion
Blink demonstrates that CPU-free LLM inference serving is not only feasible but highly advantageous in throughput, latency, isolation, and energy efficiency. By restructuring the serving stack to delegate control and data plane functions to the GPU and SmartNIC DPU, Blink achieves strong numerical improvements—up to 8.47× lower tail latency, 2.1× higher throughput, and up to 70.7% energy reduction under interference. Its architectural decoupling guarantees performance isolation and unlocks server consolidation as datacenter scale increases, providing a robust foundation for future AI deployment frameworks (2604.07609).