Shift Parallelism: Low-Latency, High-Throughput LLM Inference for Dynamic Workloads (2509.16495v1)
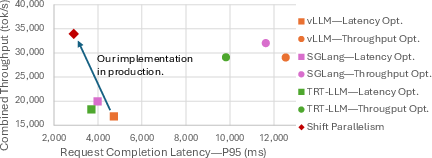
Abstract: Efficient parallelism is necessary for achieving low-latency, high-throughput inference with LLMs. Tensor parallelism (TP) is the state-of-the-art method for reducing LLM response latency, however GPU communications reduces combined token throughput. On the other hand, data parallelism (DP) obtains a higher throughput yet is slow in response latency. Best of both worlds does not exist, and it is not possible to combine TP and DP because of the KV cache variance across the parallelisms. We notice Sequence Parallelism (SP - Ulysses in training) has similar properties as DP but with KV cache invariance. We adapt SP to inference, and combine it with TP to get the best of both worlds. Our solution: Shift Parallelism. Shift Parallelism dynamically switches across TP and SP, and minimizes latency in low traffic without losing throughput in high traffic. The efficient GPU communications of Shift Parallelism yields up to i) 1.51x faster response in interactive workloads and ii) 50% higher throughput in batch workloads, compared to a TP-only solution. We evaluate Shift Parallelism with real-world production traces with dynamic traffic patterns as well as synthetic benchmarking patterns across models, context sizes, and arrival rates. All results affirm the same: Shift Parallelism has a better the latency vs. throughput tradeoff than TP or DP, and hence obtains low latency without degrading throughput in dynamic workloads.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to run LLMs on many GPUs so they answer quickly when traffic is light and handle lots of requests when traffic is heavy. The method is called Shift Parallelism. It “shifts gears” between two existing ways of splitting work across GPUs so the system stays fast and efficient as demand changes.
What questions did the researchers ask?
They focused on a common real-world problem: LLMs see mixed, unpredictable traffic. Sometimes there are just a few chat-style requests that need a fast response. Other times there are big batches (like translating thousands of documents) where overall speed and cost matter most. The key questions were:
- Can we get low response time for single users and high total throughput for big batches using one system?
- Can we switch between GPU strategies on the fly without wasting time rearranging the model’s “memory”?
- Will this work on modern models in real production settings?
How did they do it?
To understand the approach, it helps to know three simple ideas:
1) Three ways to split work across GPUs (with analogies)
- Data Parallelism (DP): Many cashiers, each helping their own customer. Great total throughput, but one customer’s checkout isn’t faster.
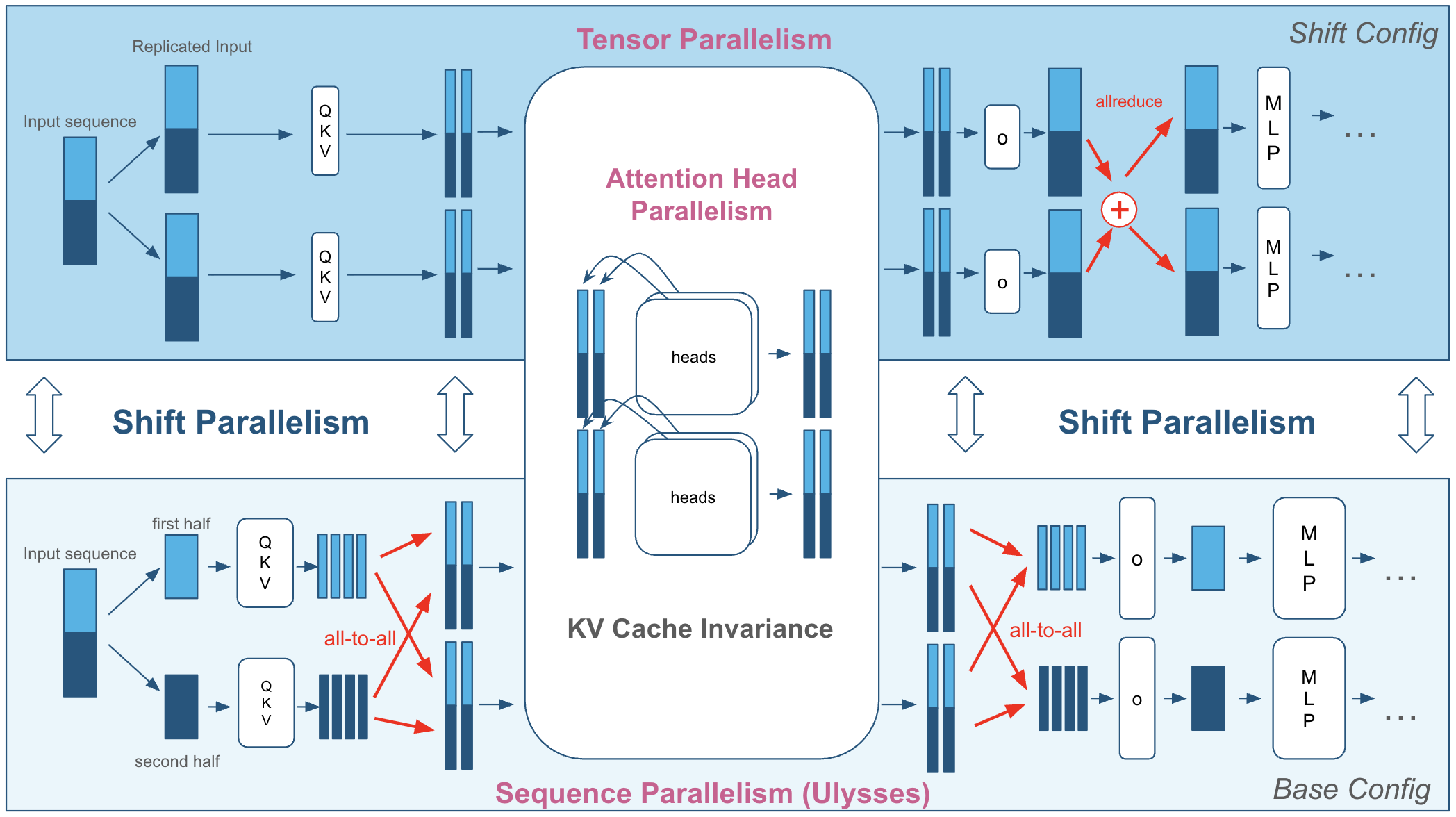
- Tensor Parallelism (TP): One team splits the math inside each layer of the model. Faster per-request speed, but the team must stop often to compare notes, which slows total throughput.
- Sequence Parallelism (SP): A group divides up the input text itself (like sharing pages of a book). They do quick exchanges before/after attention steps, but avoid constant group huddles. SP speeds up the “start” of a request (time to first token), and uses less heavy communication than TP.
2) The KV cache (the model’s short-term memory)
When the model reads a prompt, it stores “keys” and “values” (KV) so it doesn’t re-read everything for each new output token. Think of it as a neatly labeled notebook. If two strategies store notes differently, switching between them is slow—you have to reorganize the notebook. The big insight: SP and TP use the same notebook layout (KV cache invariance), so you can swap between them quickly.
3) Shift Parallelism: automatic gear shifting
Shift Parallelism watches the traffic:
- When batches are small (few requests), it shifts to TP to make each new token come out faster.
- When batches are large (many requests), it uses SP to start responses sooner and pump more tokens per second overall. Because SP and TP share the same KV layout, the system can switch modes without repacking its “notebook.”
Making it work in practice
The authors also:
- Adapted SP for modern models (including GQA, a memory-saving attention variant) and fixed load-balancing problems when batches are tiny.
- Built careful rules so attention “heads” are ordered the same way in both modes, keeping the KV cache consistent.
- Integrated the method into a popular inference engine (vLLM) and tested it on real production traffic patterns and synthetic benchmarks.
What did they find, and why does it matter?
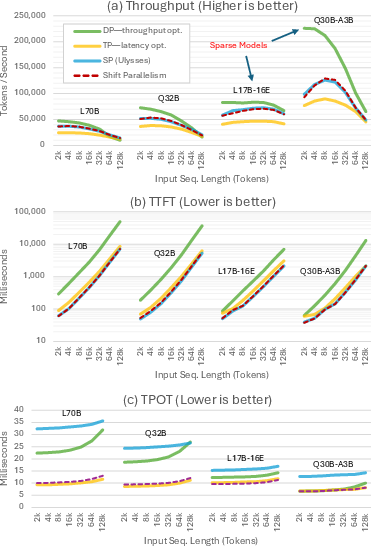
Across many tests (different models, input sizes, and arrival rates), Shift Parallelism consistently gave a better tradeoff between latency and throughput than using only TP or only DP.
Highlights reported in the paper:
- Faster responses in low traffic: up to about 1.5× faster than TP-only in interactive settings; much faster time-to-first-token (TTFT), sometimes up to about 7× better than DP in specific tests.
- Higher throughput in high traffic: up to about 50% more tokens per second than TP-only.
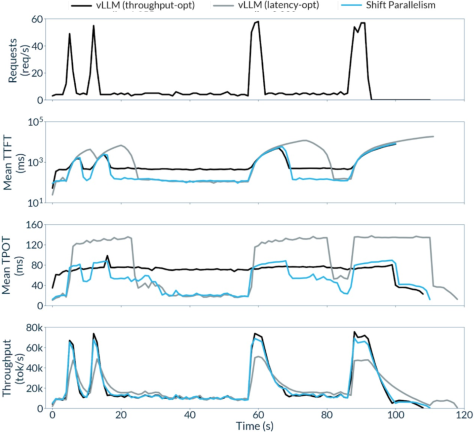
- Under bursty, real-world-like traffic: lowest median TTFT and generation time (TPOT), while keeping throughput close to DP and clearly better than TP.
In simple terms: users waiting for replies see responses sooner, while big jobs finish faster and cheaper—without running separate systems.
What could this change?
- Better user experience: Chats and agents feel snappier when traffic is light.
- Lower cost at scale: Batch jobs process more tokens per second, saving money.
- Simpler operations: One deployment adapts to changing traffic instead of juggling separate clusters for latency and throughput.
- Broad applicability: It works with modern LLM features and plugs into existing inference frameworks. It also combines well with other speedups like speculative decoding and optimized KV handling.
Bottom line: Shift Parallelism makes LLM servers more flexible and efficient, automatically choosing the best “gear” for the current workload so providers don’t have to pick between fast responses and high throughput.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, framed to be actionable for future work.
- Switching policy and threshold selection
- No principled method for choosing the SP↔TP switching threshold (currently based on “number of batched tokens”). Absent: an analytical or learned policy that accounts for prompt/output lengths, acceptance rates (with speculative decoding), queue length, GPU utilization, and communication/computation balance.
- No analysis of hysteresis or anti-thrashing mechanisms to prevent rapid oscillations between modes under fluctuating loads.
- Switching granularity and overhead
- Unclear exactly when and how mode switches occur within a request (e.g., between prefill and decode steps) and the microsecond–millisecond overheads introduced by graph/context changes.
- No measurements of warm-up/compilation cache effects when maintaining two execution graphs (SP-based base config and full-TP shift config).
- KV cache invariance details
- While head reordering for invariance is outlined, formal guarantees, correctness proofs, and end-to-end reproducibility under mixed (SP, TP) factorization (including odd/non-divisible cases) are not provided.
- No evaluation of numerical drift or determinism differences introduced by head reordering and repeated switching.
- Variable-length batches and padding
- SP’s reliance on padding for load balance at small batch sizes is acknowledged but not quantified (how much padding overhead across realistic ragged batches?).
- No exploration of ragged-sequence aware all-to-all (e.g., segmented all-to-all), length bucketing, or adaptive SP degree per microbatch to reduce padding waste.
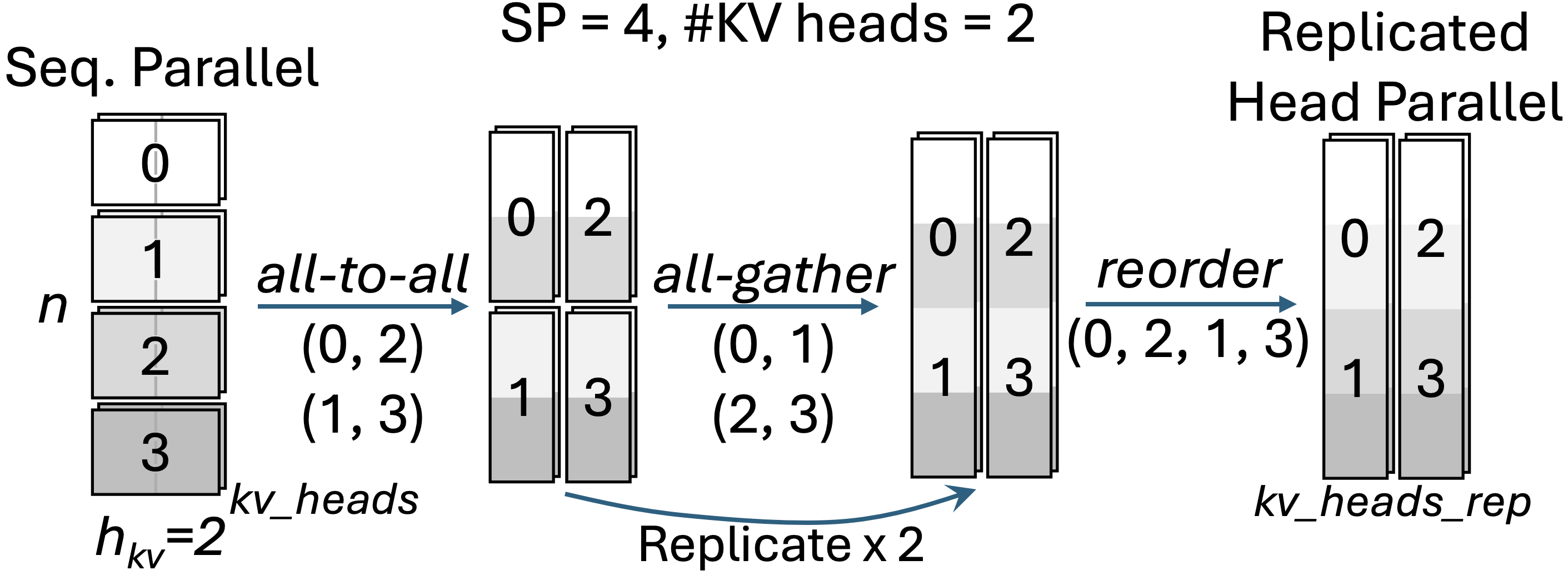
- GQA with few KV heads
- The proposed in-network KV cache replication algorithm (for SP > #KV heads) lacks communication-cost models and comparative measurements vs. TP across hardware tiers and topologies.
- No analysis of contention, NCCL scheduling, or scalability beyond 4–8 GPUs for this replication (especially with many small GQA groups).
- Multi-node and topology dependence
- All experiments are intra-node with NVSwitch. Unclear performance and feasibility over PCIe-only nodes, multi-node (InfiniBand/Ethernet), or mixed topologies where all-to-all costs dominate.
- No treatment of pipeline parallelism or tensor parallelism across nodes and how KV invariance generalizes there.
- Memory overhead of separate models
- The “separate model” approach replicates weights for the shift config; memory feasibility is not quantified for lower-memory GPUs (e.g., 80 GB A100) or very large models.
- No head-to-head runtime comparison between “on-the-fly slicing” vs. “separate models” beyond citing FP8 transpose constraints; missing detailed performance/memory/latency trade-offs.
- Impact on maximum context length and concurrency
- Weight replication and SP padding both consume memory; effect on maximum prompt length, batch size, and KV cache capacity is not analyzed end-to-end.
- QoS, fairness, and tail latency
- Results mainly report medians. 95th/99th percentile TTFT/TPOT and completion-time tails under bursty traffic, mixed SLAs, and mode switching are not provided.
- No scheduler design for isolating interactive from batch requests while still exploiting Shift Parallelism (e.g., admission control, priority queues).
- Interaction with vLLM continuous batching and paged KV
- Unclear how SP’s all-to-all and padding interact with vLLM’s continuous batching, block management, and preemption; potential head-of-line blocking and internal fragmentation are not quantified.
- Integration with DP
- The paper asserts DP and TP cannot be combined due to KV layout mismatch; no investigation of on-the-fly KV remapping, selective KV migration, or cluster-level strategies that compose DP with SP/TP without duplicating deployments.
- Speculative decoding and SwiftKV interplay
- Mode selection is not adapted to speculative decoding acceptance rates, draft length, or SwiftKV prefill optimizations; no sensitivity paper on how these features shift the optimal SP↔TP boundary.
- Streaming user experience
- Token-level jitter and inter-token spacing stability during frequent mode switches is not measured; no analysis of perceived latency in streaming UIs.
- Energy and cost modeling
- No direct power measurements or cost-per-token analyses across modes; missing models that relate communication intensity (all-to-all vs. all-reduce) to energy efficiency.
- Fault tolerance and robustness
- No discussion of handling GPU or NCCL failures mid-flight with a shared KV cache; recovery, cache reconstruction, and request resumption are open.
- Applicability to model families
- MoE models are acknowledged but not thoroughly evaluated; unknowns include expert routing variability under SP, KV invariance across experts, and communication amplification with active expert subsets.
- Other architectures (e.g., MQA-only, multimodal encoders/decoders, linear-attention variants, recurrent memory models) are not examined.
- Quantization and kernel portability
- Results rely on FP8/Hopper; it is unclear how INT8/INT4 (AWQ/GPTQ) or W8A8 kernels interact with SP all-to-all and head reordering. Accuracy/performance impacts are unreported.
- Portability to AMD ROCm, TPU, or custom collectives is unexplored.
- Compiler and CUDA Graph capture
- The paper mentions adjustments for capturing all-to-all but does not quantify compile/warm-up time, graph cache hit rates, or runtime overheads under dynamic shapes and frequent switching.
- Communication microbenchmarks and models
- Missing microbenchmarks that break down per-layer compute vs. communication for SP vs. TP across sequence lengths and head counts; no predictive model to guide optimal SP/TP degrees.
- Heuristic constraints with head counts
- Practical constraints when SP×TP does not align with the number of heads (e.g., remainder heads) are not detailed; the overhead of head re-indexing and re-packing is unknown.
- Multi-tenant and multi-model co-location
- With weight replication for the shift config, feasibility of running multiple models on one node (common in production) is unaddressed; memory pressure and interference are open issues.
- Security/isolation considerations
- Shared KV cache across configurations (and possibly multiple components) raises questions about isolation between tenants/models, cache poisoning risks, and auditing.
- Theory of optimality
- No formal analysis or bounds for TTFT/TPOT/throughput as functions of SP and TP degrees, sequence length distribution, head counts, and interconnect bandwidth; lack of a provably near-optimal policy.
- Comprehensive reproducibility
- Some implementation details (exact repository commits, configs, NCCL tuning, graph-capture settings) and full datasets/traces are either not linked or partially described, limiting reproducibility.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging the paper’s implemented methods, open-source integration, and demonstrated production results.
- Cloud LLM serving: dynamic latency–throughput optimization in a single deployment
- Sector: software/cloud/AI platforms
- Use case: Replace separate TP and DP clusters with one Shift Parallelism-enabled vLLM deployment that auto-switches between SP and TP based on live batch size and traffic.
- Tools/workflows: Shift Parallelism plugin for vLLM; threshold-based mode switching; KV-cache-invariant head ordering; production monitors for TTFT/TPOT/throughput; CUDA graph capture configuration.
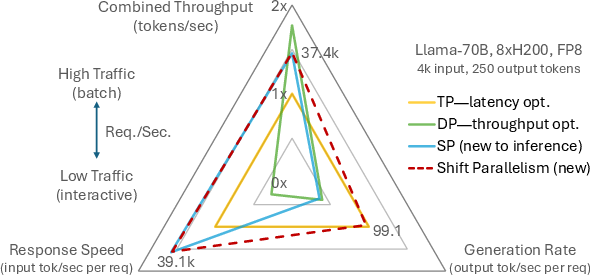
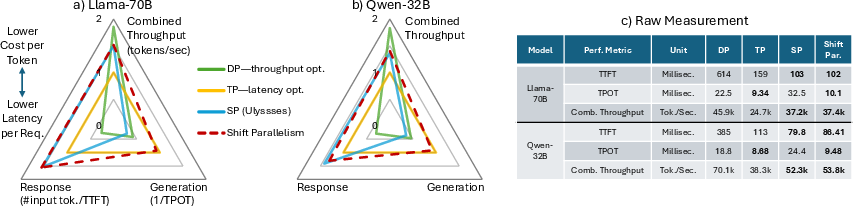
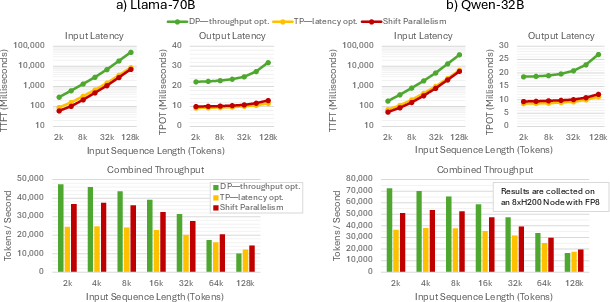
- Benefits: Up to ~1.5× faster response (TTFT) at low traffic and ~50% higher throughput at high traffic compared to TP-only; near-DP throughput with substantially lower latency.
- Assumptions/dependencies: NVLink/NVSwitch-class interconnect for efficient all-to-all; sufficient GPU memory for dual-weight strategy (overhead ≈ 1/SP); models with compatible GQA/head layouts; accurate traffic measurement; vLLM ≥ 0.9.2 and plugin support.
- Enterprise multi-tenant SLA routing with fewer nodes
- Sector: finance, healthcare, e-commerce, customer support
- Use case: Serve mixed workloads (interactive agent loops, chatbot sessions, document batch jobs) in one fleet, using Shift Parallelism to keep TTFT/TPOT low without sacrificing batch throughput.
- Tools/workflows: SLA-aware router prioritizing latency-critical requests; queue segmentation with dynamic switching; operational dashboards for burst handling; cost-per-token tracking.
- Benefits: Less fleet duplication (eliminate separate TP and DP clusters), improved QoS under bursts, reduced operational complexity and cost.
- Assumptions/dependencies: Accurate classification of request types and arrival rates; policy rules for switching thresholds; monitoring and alerting integrated into MLOps stack.
- Agentic systems and chatbots with faster user response
- Sector: customer support, education, productivity apps, coding assistants
- Use case: Lower TTFT and TPOT in interactive loops (code refinement, conversational flows) while preserving throughput if traffic spikes.
- Tools/workflows: Burst-aware chat backend; latency-focused mode when batches are small; complementary use with SwiftKV and speculative decoding for further speedups.
- Benefits: Up to 6.97× lower TTFT vs DP and up to 2.45× lower TPOT vs DP; stable responsiveness during bursts.
- Assumptions/dependencies: Small-batch padding overhead in SP is acceptable; outputs that are long may prefer TP mode; session-level metrics drive auto-switching.
- Batch processing (summarization, translation, labeling)
- Sector: media, legal, research, back-office automation
- Use case: Schedule large batched jobs to run with SP-heavy configuration for higher combined throughput while retaining a responsive control plane for ad hoc queries.
- Tools/workflows: Batch job runner using SP; throughput target tuning; integration with speculative decoding to increase tokens/s further.
- Benefits: Higher throughput during bursts (up to ~1.51× vs TP); faster completion for large jobs; lower cost per token.
- Assumptions/dependencies: Long contexts may become bandwidth-bound (KV-cache reads); throughput degrades with very large sequences; robust interconnect required.
- Production stack upgrades: combine Shift Parallelism with SwiftKV and speculative decoding
- Sector: cloud AI providers and SaaS
- Use case: Integrate Shift Parallelism with SwiftKV (optimized prefill) and speculative decoding to achieve lower completion time and higher tokens/s in production.
- Tools/workflows: Unified serving stack; dataset filters compatible with speculative decoding; model-specific tuning for draft/target pairing.
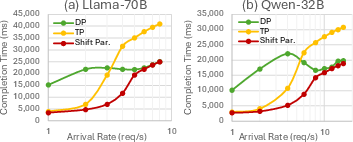
- Benefits: Reported 3.4× lower completion time and 1.06× higher throughput vs leading open-source systems for mixed real-world traces.
- Assumptions/dependencies: Speculative decoding compatibility; careful calibration of draft models; data distribution that benefits speculative strategies.
- GPU communications and model-engineering improvements
- Sector: HPC software, inference engine developers
- Use case: Adopt neighborhood collectives and fused all-to-all/all-gather paths for GQA KV-cache replication when SP > #KV heads; use general process-to-data mapping for KV invariance.
- Tools/workflows: Communication primitive libraries; NCCL or custom collectives; deterministic head ordering and shard mapping.
- Benefits: Enables SP on models with few KV heads; unlocks dynamic switching without cache copying.
- Assumptions/dependencies: High-bandwidth interconnect; careful ordering to maintain KV-cache consistency; models with head-parallelizable attention.
- Bursty workload benchmarking and capacity planning
- Sector: MLOps/DevOps
- Use case: Adopt the paper’s bursty traffic benchmark and metrics (TTFT, TPOT, combined tokens/s) to size fleets, set SLAs, and choose SP/TP thresholds.
- Tools/workflows: Synthetic trace generation; performance dashboards; A/B tests for threshold tuning; cost breakdown analytics.
- Benefits: Better fleet sizing; predictable behavior under mixed workloads; controlled cost per token.
- Assumptions/dependencies: Representative traces; stable threshold policies; observability covering latency and throughput.
Long-Term Applications
These applications will benefit from further research, engineering, or scaling beyond single-node, single-engine setups.
- Multi-node, cross-cluster Shift Parallelism
- Sector: cloud platforms, hyperscalers
- Use case: Extend KV-cache invariance and switching logic across nodes (RDMA/NVLink clusters) to support cluster-wide dynamic mode changes without cache copying.
- Tools/workflows: Cluster-level orchestrator; KV sharding and re-sharding protocols; RDMA-aware collectives; traffic-aware global scheduler.
- Dependencies: Efficient inter-node all-to-all; low-cost KV-cache state movement; fault tolerance in reconfiguration; formal performance models.
- MoE-aware dynamic switching
- Sector: model-serving for mixture-of-experts (MoE)
- Use case: Integrate SP/TP switching with expert routing to handle active-parameter variability while keeping KV-cache consistent across experts.
- Tools/workflows: MoE-aware shard layouts; per-expert KV invariance; expert-activation telemetry; gating-aware threshold tuning.
- Dependencies: Correct handling of small KV-head counts; efficient replication strategies; compatibility with MoE schedulers; potential changes in attention implementation.
- Energy-aware and carbon-aware inference control
- Sector: energy, sustainability, green AI policy
- Use case: Switch modes to minimize energy per token or per request under grid signals, carbon intensity, or data center thermal constraints.
- Tools/workflows: Telemetry-driven controllers; energy models for TTFT/TPOT/throughput; integration with carbon-aware schedulers.
- Dependencies: Accurate energy instrumentation; predictable mode energy profiles; policy tie-ins for operational targets.
- Adaptive, learned switching (auto-tuning thresholds)
- Sector: software/AI platforms, academia
- Use case: Use reinforcement learning or Bayesian optimization to adapt switching thresholds in real time to maximize a composite objective (e.g., latency SLOs and cost).
- Tools/workflows: Online learners; evaluators tied to TTFT/TPOT/throughput; guardrails for stability; safe exploration policies.
- Dependencies: Stable telemetry; drift detection; rollback mechanisms; robust reward shaping to avoid oscillations.
- Standardization of KV-cache invariance APIs
- Sector: AI infrastructure standards, open-source communities
- Use case: Define portable APIs/specs for head ordering, shard mapping, and cache layouts to enable interop across engines (vLLM, TensorRT-LLM, SGLang) and models.
- Tools/workflows: Reference implementations; conformance test suites; documentation of invariance constraints.
- Dependencies: Community alignment; cross-engine support; migration tooling for existing deployments.
- Compiler/kernel support to eliminate dual-weight overhead
- Sector: GPU compilers, hardware vendors
- Use case: Enable on-the-fly weight slicing without costly transposes for FP8 tensor cores, removing the need for separate base/shift models.
- Tools/workflows: Kernel enhancements; memory-layout-aware codegen; autotuning for fused collectives.
- Dependencies: Hardware support for flexible FP8 layouts; compiler maturity; validation on diverse models.
- Hybrid DP + Shift Parallelism across service layers
- Sector: cloud AI serving
- Use case: Use DP across nodes and Shift Parallelism within nodes to approach DP’s peak throughput while preserving low latency for interactive requests.
- Tools/workflows: Multi-tier router; cache-aware placement; batched DP orchestration with local SP/TP switching.
- Dependencies: Managing KV-state boundaries (DP incompatible with cache sharing); potential cache migration or duplication; routing complexity.
- Robustness and resilience under GPU failures
- Sector: reliability engineering, regulated industries
- Use case: Maintain KV-cache consistency and fast failover when GPUs drop, with dynamic rebalancing of SP/TP groups and head orders.
- Tools/workflows: Checkpointed KV-cache layouts; health monitors; graceful re-sharding procedures.
- Dependencies: Fast detection; minimal state movement; predictable recovery latency; formal SLO guarantees.
- Edge and on-device adaptation
- Sector: robotics, embedded, mobile
- Use case: Adapt SP/TP concepts to heterogeneous edge setups (CPU+GPU+NPU) to optimize TTFT in interactive control loops and throughput for batch tasks.
- Tools/workflows: Lightweight collectives; micro-batching and cache reuse; simplified head-parallelism on constrained devices.
- Dependencies: Limited memory/interconnect; model downsizing/quantization; careful trade-offs for padding and replication.
- Policy and governance for mixed-workload fairness and QoS
- Sector: public policy, enterprise governance
- Use case: Define fairness, priority, and QoS policies for shared LLM infrastructure where mode switching can advantage certain tenants or request classes.
- Tools/workflows: Policy engines; audits of latency/throughput distribution; governance dashboards.
- Dependencies: Transparent metrics; stakeholder agreement; compliance requirements (e.g., healthcare/customer support SLOs).
Notes on feasibility constraints common to most applications
- KV-cache invariance is central: attention head ordering and shard mapping must remain consistent across modes; any engine/model deviations break seamless switching.
- Interconnect quality matters: efficient all-to-all/all-gather (NVSwitch/NVLink/RDMA) strongly influences SP efficiency and overall gains.
- Memory overhead trade-off: dual-model weights increase memory usage by ≈1/SP; sizing must consider KV-cache footprint for long contexts.
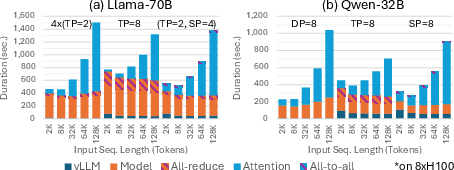
- Workload characteristics: very long contexts can be bandwidth-bound, reducing throughput gains; small batch SP requires padding and may increase TPOT.
- Engine integration details: CUDA graph capture and compilation constraints must be addressed; version-specific behaviors in vLLM/other engines can affect stability.
- DP remains the pure throughput leader for massive independent batches; Shift Parallelism optimizes the latency–throughput frontier but doesn’t fully replace DP for all scenarios.
Glossary
- All-gather: A collective communication primitive where each process gathers data from all others in its group. Example: "Then ii) we replicate the heads in network using a neighborhood all-gather within GQA groups ."
- All-reduce: A collective operation that aggregates values (e.g., sums) across processes and distributes the result back to all. Example: "It has to synchronize the embeddings across layers with costly all-reduce communications."
- All-to-all: A communication primitive where each process sends distinct data to every other process and receives distinct data from all. Example: "resulting in all-to-all communications before and after the attention layer"
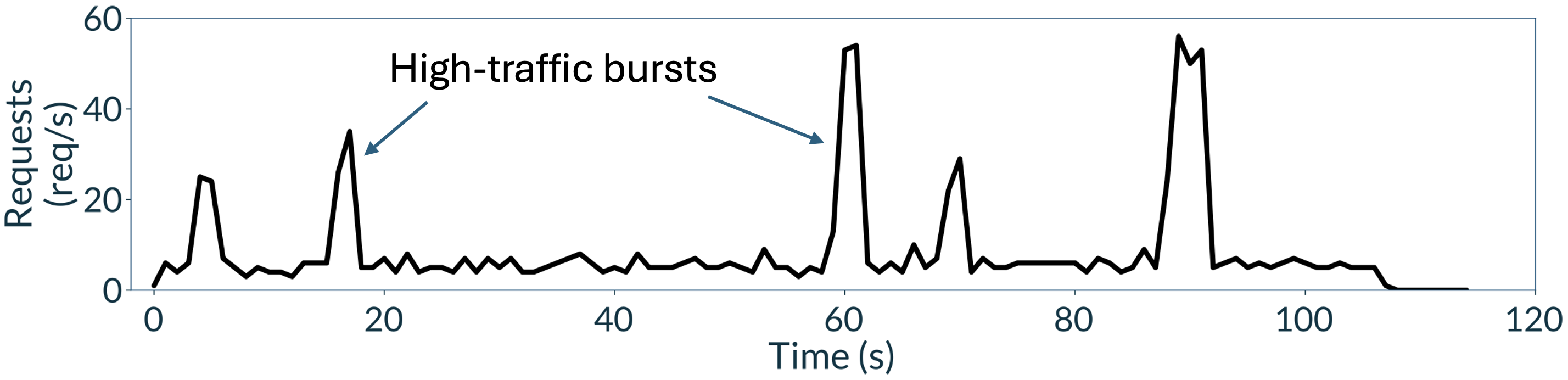
- Arrival rate: The frequency at which requests enter the system, used to characterize traffic load. Example: "we test Shift Parallelism across a wide range of intermediate traffic by varying the request arrival rates."
- Attention head: An independent component within multi-head attention that learns distinct attention patterns over inputs. Example: "each attention head requires the full sequence"
- Base configuration: The primary parallel setup used during normal operation before switching, typically SP or mixed SP–TP. Example: "Base configuration: Uses SP or a mixed (SP, TP) setup, as long as SP TP = P, where P is the total number of GPUs."
- Bursty traffic: Workload pattern with sudden spikes in request volume followed by quieter periods. Example: "the result is a highly bursty traffic pattern"
- CUDA graph capture: A mechanism to record and replay GPU workloads to reduce launch overhead and improve latency. Example: "For achieving low latency in inference, it is crucial to enable compilation and CUDA graph capture mechanisms in vLLM because the batch size can be small in low traffic."
- Data Parallelism (DP): A strategy that replicates the model across devices and processes different inputs in parallel to maximize throughput. Example: "Data parallelism (DP) parallelizes across request boundaries in embarrassingly parallel, providing high throughput."
- Decoding: The autoregressive generation phase where output tokens are produced one by one using past context. Example: "And while SP cannot parallelize decoding steps, resulting in the worst TPOT compared to TP and DP"
- FP8 quantization: Representing weights/activations in 8-bit floating point to boost speed and reduce memory use. Example: "all with FP8 quantization."
- Grouped Query Attention (GQA): An attention variant where multiple query heads share a smaller set of key/value heads to save memory. Example: "GQA saves memory by sharing each KV head with multiple query heads."
- Head parallelism: Distributing attention heads across devices to parallelize attention computations. Example: "Head Parallelism is commonly used with SP and TP, where the attention heads are distributed across the GPUs equally."
- Hopper tensor cores: Specialized matrix-math hardware units on NVIDIA Hopper GPUs optimized for mixed/low-precision operations. Example: "due to an FP8 hardware limitation of Hopper tensor cores."
- In-network KV cache replication: Duplicating key/value states across devices via communication collectives to satisfy parallel layout constraints. Example: "we propose an in-network KV cache replication algorithm with multi-step neighborhood collectives."
- KV cache: Stored key and value tensors from prior tokens used to speed up attention during autoregressive decoding. Example: "This is possible because the KV cache memory layout remains invariant between TP and SP, allowing Shift Parallelism to switch modes seamlessly, based on batch size and traffic patterns."
- KV cache invariance: Maintaining an identical layout and ordering of KV tensors across parallel configurations to allow seamless switching. Example: "The key insight is that both configurations must share the same KV cache layout—what we call KV cache invariance."
- Mixture of Experts (MoE): A model architecture that activates only a subset of expert sub-networks per token to improve efficiency or capacity. Example: "which are mixture of experts (MoE) models"
- Multi-Head Attention (MHA): The attention mechanism that runs multiple attention heads in parallel to capture diverse relationships. Example: "The Multi-Head Attention (MHA) consists multiple heads"
- Neighborhood collectives: Collective communication patterns restricted to subsets (neighborhoods) of processes to reduce overhead. Example: "with multi-step neighborhood collectives."
- NVSwitch: NVIDIA’s on-node switch fabric that provides high-bandwidth, low-latency GPU-to-GPU communication. Example: "The GPUs are interconnected with an NVSwitch network with 900 GB/s rated bandwidth."
- Prefill: The initial phase that processes the entire input context to build KV cache before token-by-token decoding. Example: "In prefill, the input tokens are batched and propagated altogether over all of the transformer layers and initializes the KV cache"
- Process-to-data mapping: The assignment strategy that aligns how processes own or access specific data shards to ensure consistency and efficiency. Example: "We resolve this by developing a general process-to-data mapping to ensure KV cache consistency"
- QKV projection: The linear transformation that produces the query (Q), key (K), and value (V) tensors from embeddings for attention. Example: "TP solves this problem by replicating the KV weights in the QKV projection (see Section~\ref{sec:transformer})"
- Row parallelization: Splitting a weight matrix by rows across devices, often requiring result aggregation. Example: "Yet, row parallelization requires all-reduce with communication cost, where is the sequence length."
- Sequence Parallelism (SP): Splitting input sequences across devices to parallelize within-request work; termed Ulysses in training. Example: "Sequence Parallelism (SP---Ulysses in training) has similar properties as DP but with KV cache invariance."
- Shift Parallelism: A method that dynamically switches between SP and TP to optimize latency and throughput under changing traffic. Example: "Shift Parallelism dynamically switches across TP and SP, and minimizes latency in low traffic without losing throughput in high traffic."
- Speculative decoding: A technique that uses a draft model or hypotheses to accelerate generation while verifying outputs. Example: "To that extent, we integrated Shift Parallelism with SwiftKV and speculative decoding in our production environment."
- SwiftKV: A system/technique aimed at optimizing KV-cache-related operations for faster inference. Example: "composing with SoTA inference technologies like SwiftKV and Speculative Decoding"
- Tensor cores: Specialized GPU units that accelerate matrix multiplications, especially for low/mixed-precision arithmetic. Example: "Each GPU has 141 GB memory with 4.8 TB/s bandwidth, and also provides a peak dense matrix multiplication of 1,979 FP8 TFLOPS with tensor cores."
- Tensor Parallelism (TP): Partitioning model weights/computation across devices (e.g., by columns/rows) to reduce per-request latency. Example: "Tensor parallelism (TP) partitions the model weights and computation in each layer."
- Time-per-output-token (TPOT): The average time to generate each subsequent output token after the first token. Example: "Time-per-output-token (TPOT, ms): After the first response token is received, the time between each subsequent token until the response is completed."
- Time-to-first-token (TTFT): The latency from request submission until the first output token is produced. Example: "Time-to-first-token (TTFT, ms): The time after a client submits a prompt until the first characters of response text (tokens) are received."
- vLLM: An open-source LLM inference engine/framework used for high-throughput serving. Example: "It is integrated into vLLM via a plug-in system (Section~\ref{sec:integration}) and is already deployed in production."
Collections
Sign up for free to add this paper to one or more collections.

