- The paper introduces SparseSpec, a training-free acceleration framework for reasoning language models that uses dynamic sparse attention to optimize the KV-cache.
- It employs unified resource-aware scheduling and fused attention kernels to enhance GPU utilization, realizing up to 2.13× throughput improvement over baselines.
- The method integrates delayed verification and dynamic KV-cache management to minimize memory bottlenecks without any additional training overhead.
Accelerating Large-Scale Reasoning Model Inference via Sparse Self-Speculative Decoding
Introduction and Context
The paper "Accelerating Large-Scale Reasoning Model Inference with Sparse Self-Speculative Decoding" (2512.01278) addresses the critical performance challenges of serving reasoning LLMs (RLMs) during inference, particularly when generating lengthy chain-of-thought (CoT) solutions on complex tasks. RLMs such as OpenAI-o1 and DeepSeek-R1 are characterized by output sequences that are orders of magnitude longer than their prompts, resulting in a severe memory-bound bottleneck during batch inference due to the auto-regressive nature of token generation. This is a consequence of each step requiring a full scan of the ever-growing key-value cache (KV-Cache), whose bandwidth demands quickly surpass compute resource utilization, especially on modern accelerators.

Figure 1: Comparison of autoregressive generation, speculative decoding, and SparseSpec. SparseSpec reuses model weights with dynamic sparse attention for speculative steps, focusing on KV-Cache efficiency.
The paper identifies that, for long-sequence tasks, runtime is dominated by KV-Cache memory access rather than compute-bound operations such as MLPs. The challenge is further complicated by workload heterogeneity, high context variance, and output-length unpredictability in RLMs, which limit the effectiveness of static or heuristics-driven techniques. Existing speculative decoding solutions—whether reliant on auxiliary (smaller) draft models or fixed sparse patterns—require additional training or system complexity, and their throughput gains do not scale for large batch, long-output reasoning workloads.
SparseSpec: Methodological Innovations
To address these issues, the authors present SparseSpec, a training-free and lossless acceleration framework for RLMs that leverages self-speculation via dynamic sparse attention. The central innovation is a tight algorithm-system co-design, enabling the original model to serve as both the draft and target during speculative decoding but with sparse attention operations in the drafting phase. This enables reduction in memory bandwidth consumption without sacrificing output fidelity, as all generations are fully verified.
PillarAttn: Dynamic Sparse Attention for Self-Speculation
PillarAttn is introduced as a dynamic sparse attention mechanism tailored for speculative decoding. Rather than relying on static sparsity or external heuristics, PillarAttn exploits locality and semantic context dynamics by extracting critical token indices (those with highest attention scores) during each verification phase and using them in subsequent draft phases. This enables rapid adaptation to evolving context without additional computation or storage overhead, since the attention scores are already computed during verification.
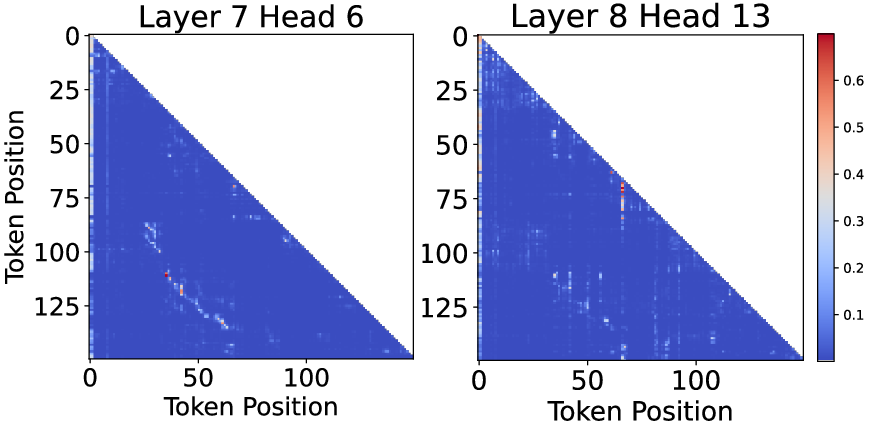
Figure 2: Attention scores in Qwen3-8B on AIME, illustrating high spatial locality but substantial context dynamics during sequence generation.
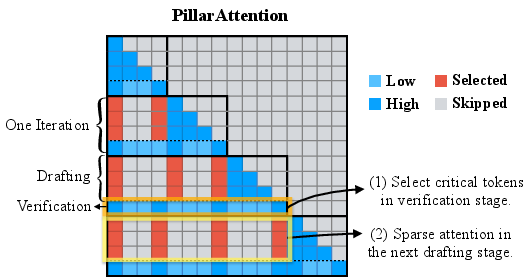
Figure 3: PillarAttn workflow. SparseSpec performs full attention and dumps scores in verification, identifying sparse patterns for next k draft steps.
Unified Resource-Aware Scheduling and Fused Kernels
To combat workload imbalance due to heterogeneous resource usage in draft and verification phases, SparseSpec integrates a unified batch scheduler that mixes draft and verification requests in each batch. Resource-aware scheduling is achieved via a greedy bin-packing strategy, resulting in more stable GPU utilization and batch sizes, avoiding both undersaturation and oversaturation.
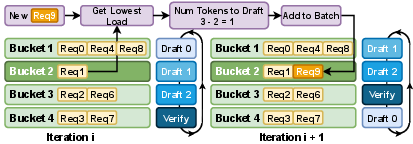
Figure 4: Resource-aware batch scheduler distributing new requests optimally to minimize phase workload fluctuation.
Additionally, SparseSpec features a fused attention kernel that dynamically dispatches optimal kernel templates for draft (sparse) and verification (full) attention within a single persistent kernel, achieving superior hardware bandwidth utilization compared to naive or sequential approaches.
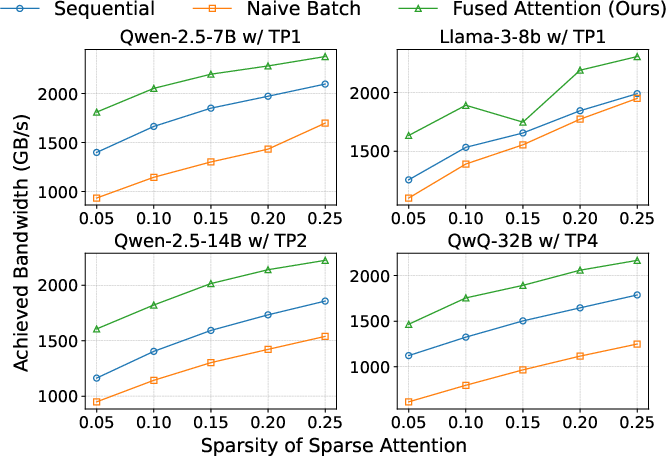
Figure 5: Performance gain of fused attention kernels over sequential and naive batching schemes.
Delayed Verification and Dynamic KV-Cache Management
To address CPU/GPU synchronization bottlenecks, SparseSpec asynchronously overlaps metadata preparation for non-verification requests while verification-phase requests are delayed by one iteration. This overlap substantially reduces critical-path CPU latency.
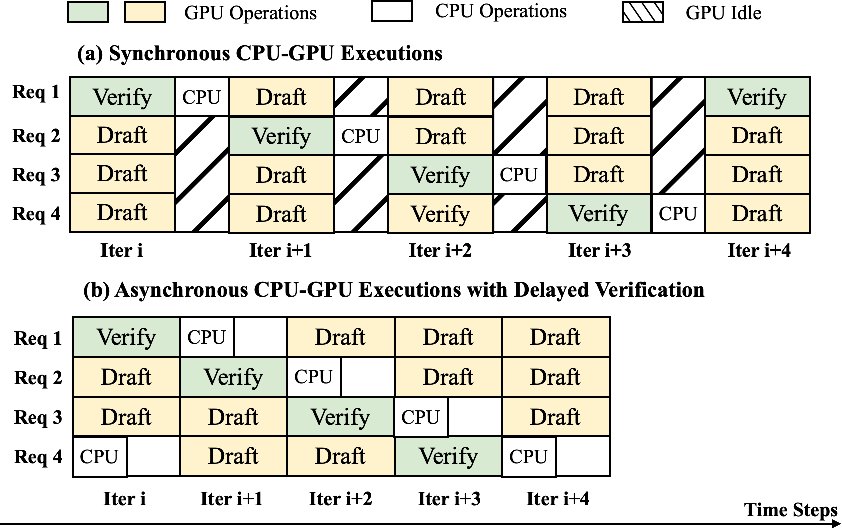
Figure 6: Delayed drafting enabling asynchronous CPU-GPU execution during speculative decoding.
The dynamic KV-Cache manager aggressively schedules new requests to maximize GPU memory utilization, offloading to host memory as needed with per-chunk granularity and low overhead, thus avoiding both recomputation and memory wastage caused by output-length variance.
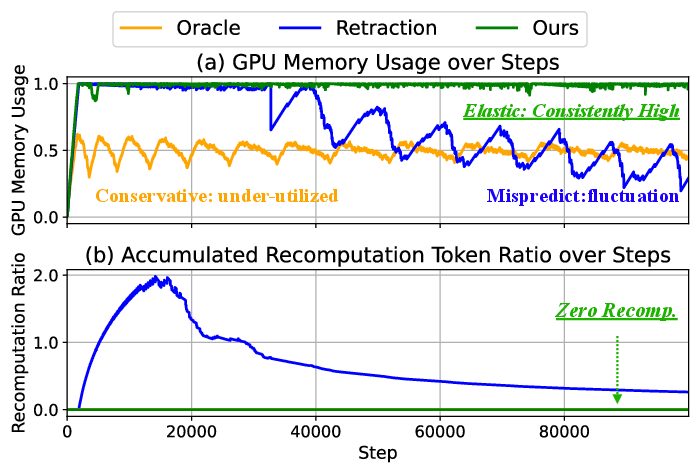
Figure 7: SparseSpec achieves near-maximal KV-Cache utilization without recomputation penalty over long runs.
Empirical Evaluation
Throughput and Acceptance Rate
SparseSpec is comprehensively evaluated using Qwen3-1.7B/8B/14B on reasoning-focused datasets (AIME, OlympiadBench, LiveCodeBench), benchmarked against state-of-the-art systems such as vLLM (baseline), NGram, MagicDec, TriForce, and EAGLE3 (training-based).
Strong numerical results include:
- Up to 2.13× end-to-end throughput improvement over vLLM baseline (memory-bound bottleneck).
- Up to 1.36×–1.76× speedup over existing, well-tuned training-free speculative decoding (NGram, MagicDec, TriForce).
- Consistently outperforms EAGLE3, training-based speculative decoding with separate draft models, despite requiring no additional training or deployment complexity.
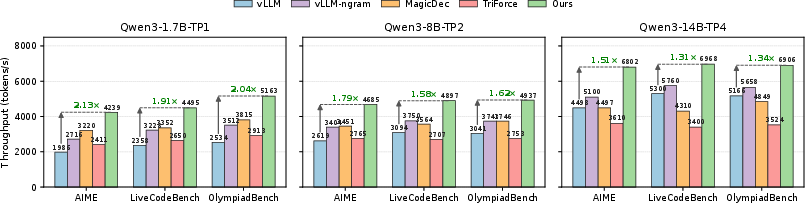
Figure 8: End-to-end throughput comparison showcasing SparseSpec's consistent advantage over other training-free inference acceleration methods.
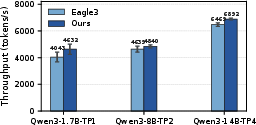
Figure 9: SparseSpec's throughput gain over draft-model-based (EAGLE-3) speculative decoding across datasets and model configurations.
PillarAttn specifically demonstrates high acceptance rates for drafted tokens (average $6.16$ out of $8$ for k=8), exceeding both NGram and EAGLE3 under the same long-context, high-variance generation settings.
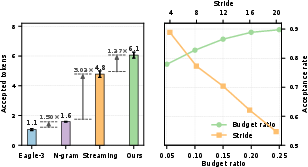
Figure 10: Average number of accepted tokens for various drafting methods when k=8; SparseSpec achieves substantially higher acceptance than alternatives.
Component-wise Contributions and Ablation
Through incremental ablation, SparseSpec's unified scheduler, dynamic KV-Cache management, and delayed verification are each shown to deliver substantial throughput improvements (1.23×, 1.61×, 1.12× respectively, compounded).
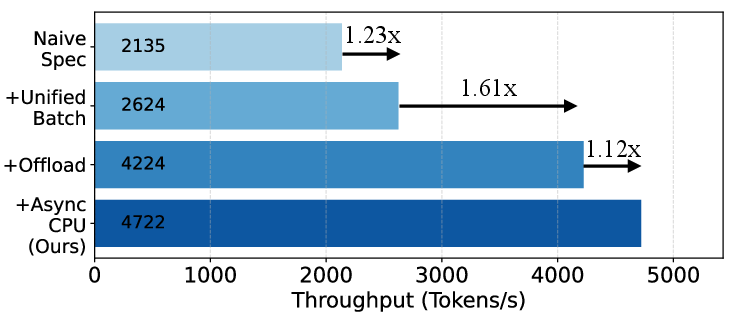
Figure 11: Ablation analysis quantifying the impact of each SparseSpec system optimization on throughput.
Stability in batch size and hardware utilization (GEMM input size, TFlops) is achieved only via unified scheduling.
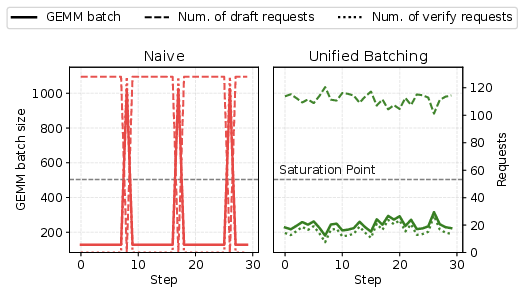
Figure 12: Stable batch size and compute utilization when unified scheduling is enabled, in contrast to conventional sequential phase scheduling.
The overhead for host offloading is negligible (<0.5% runtime impact), and the fused attention kernel offers a 1.3×–1.8× speedup (Figure 5).
Implications, Limitations, and Future Perspectives
SparseSpec delivers a training-free, lossless approach for accelerating RLM inference, focusing on the core bottleneck of KV-Cache memory bandwidth. The core insights—dynamic reuse of self-attention scores for context-adaptive sparsity, and extensive system-level integration—point toward a broader trend: for long-output, memory-bound LLM scenarios, efficient memory management and flexible batch scheduling are as crucial as improvements in core model architecture.
These ideas are readily extensible to MoE models and hierarchical speculation stacks, and could synergize further with quantized or block-sparse KV-cache strategies. For deployments dominated by short-sequence or compute-bound regimes, the marginal benefit of SparseSpec is diminished due to saturation of GPU compute.
In practice, the framework opens up new opportunities for cost-effective, scalable inference in both offline RL training regimes—with large batch long-sequence rollouts—and online deployment of agentic LLMs, particularly in domains requiring extensive CoT outputs.
Conclusion
SparseSpec provides a robust, theoretically-motivated framework for inference acceleration in reasoning LLMs, achieving strong empirical throughput improvements without reliance on auxiliary model training or system-level complexity. Through the co-design of dynamic sparse attention (PillarAttn), unified system scheduling, asynchronous verification, and high-efficiency KV-cache management, SparseSpec sets a new standard for memory-efficient, lossless inference in the era of large-scale, chain-of-thought LLMs (2512.01278).

