Infinity-RoPE: Action-Controllable Infinite Video Generation Emerges From Autoregressive Self-Rollout
Abstract: Current autoregressive video diffusion models are constrained by three core bottlenecks: (i) the finite temporal horizon imposed by the base model's 3D Rotary Positional Embedding (3D-RoPE), (ii) slow prompt responsiveness in maintaining fine-grained action control during long-form rollouts, and (iii) the inability to realize discontinuous cinematic transitions within a single generation stream. We introduce $\infty$-RoPE, a unified inference-time framework that addresses all three limitations through three interconnected components: Block-Relativistic RoPE, KV Flush, and RoPE Cut. Block-Relativistic RoPE reformulates temporal encoding as a moving local reference frame, where each newly generated latent block is rotated relative to the base model's maximum frame horizon while earlier blocks are rotated backward to preserve relative temporal geometry. This relativistic formulation eliminates fixed temporal positions, enabling continuous video generation far beyond the base positional limits. To obtain fine-grained action control without re-encoding, KV Flush renews the KV cache by retaining only two latent frames, the global sink and the last generated latent frame, thereby ensuring immediate prompt responsiveness. Finally, RoPE Cut introduces controlled discontinuities in temporal RoPE coordinates, enabling multi-cut scene transitions within a single continuous rollout. Together, these components establish $\infty$-RoPE as a training-free foundation for infinite-horizon, controllable, and cinematic video diffusion. Comprehensive experiments show that $\infty$-RoPE consistently surpasses previous autoregressive models in overall VBench scores.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper shows a new way to make AI create very long, smooth, and controllable videos without retraining the model. The authors call their method Infinity‑RoPE. It helps a video‑making AI keep going for minutes or even longer, respond instantly when you change the prompt (like telling a character to jump or sit), and even add movie‑style scene cuts—all in one continuous generation.
The big questions the paper asks
- Can we get today’s short‑video AIs to make much longer videos without training them again on long videos?
- Can we make the AI react right away when the user changes the instructions during generation?
- Can we add clean scene cuts (like in movies) without restarting or stitching together separate clips?
How the method works (with simple analogies)
First, a bit of background:
- Video diffusion model: Imagine starting from TV static and cleaning it up step by step until a clear video appears. That’s roughly how diffusion models generate images and videos.
- Autoregressive generation: Like writing a story one paragraph at a time, using what you just wrote to guide the next part.
- Positional embedding (RoPE): The model needs to know “when” and “where” each pixel or frame is. RoPE is like putting time stamps and map coordinates on tokens so the model understands order and position.
- KV cache: A fast “short‑term memory” the model uses to remember past frames while generating the next ones.
The paper introduces three plug‑in tools you can use at inference time (no extra training required):
- Block‑Relativistic RoPE
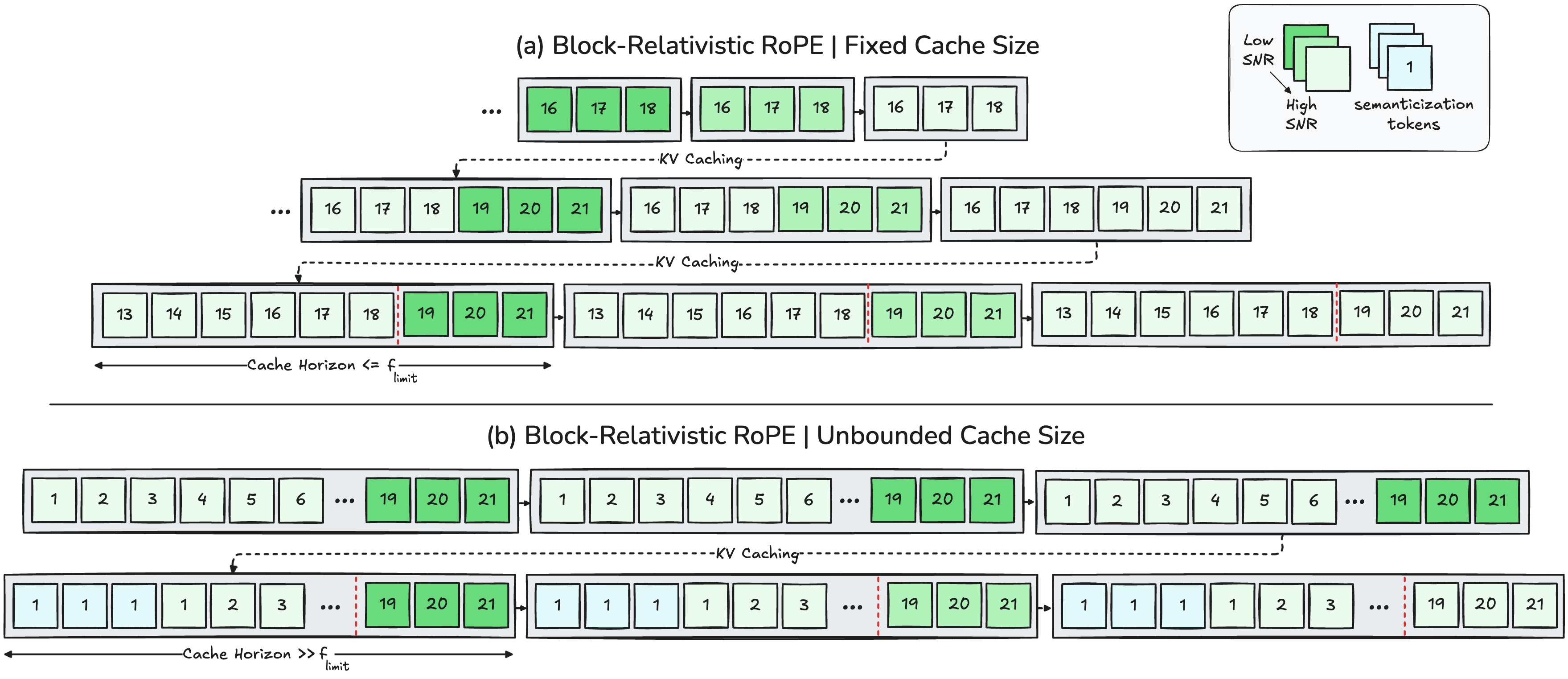
- Analogy: Imagine filming a long movie with a camera whose timer only goes up to 1024 seconds. Instead of letting the timer “overflow,” you keep using a moving window where the “clock” is always reset for the newest scene, and earlier scenes’ time stamps are shifted so their relative order stays correct.
- What it does: It changes how the model labels time positions so there’s no fixed, absolute “time slot.” The active part always has fresh, high‑precision time, and the past is re‑anchored so relative order is preserved.
- Why it matters: This removes the usual time limit that makes long videos fall apart, so the model can keep generating far beyond its original horizon.
- KV Flush
- Analogy: You’re telling an actor what to do. If you keep all the old directions in your head, the actor might hesitate to switch actions. KV Flush is like clearing your head except for two anchors: a global stabilizer and the very last thing that happened, so the action change is instant and smooth.
- What it does: It “flushes” the model’s short‑term memory and keeps only two frames: a global sink (a stabilizing reference) and the most recent frame. This makes the next prompt take effect immediately without weird leftovers from the past.
- Why it matters: You can change actions on the fly (stand → jump → sit → sing) and the video responds right away, with motion staying smooth.
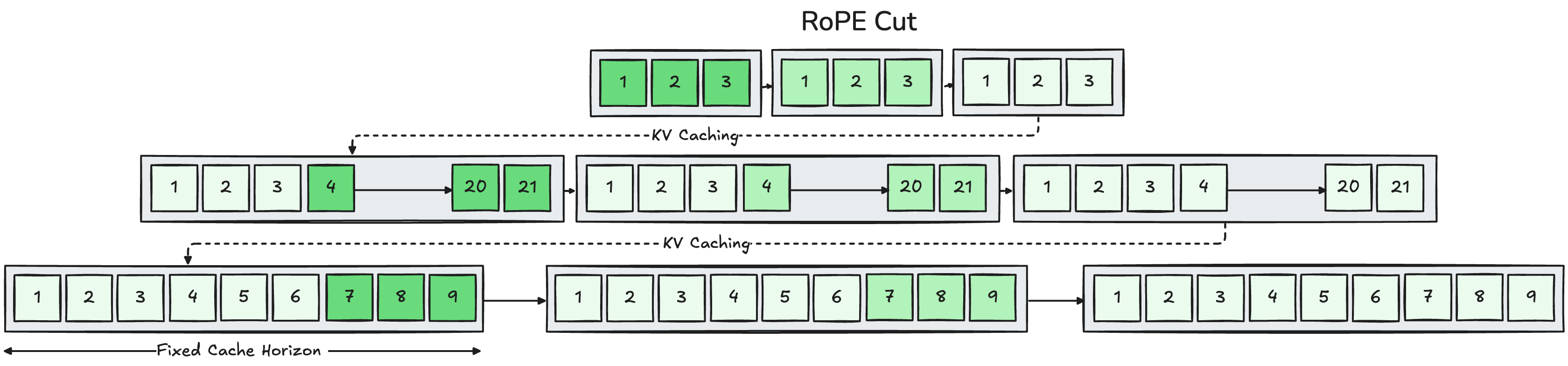
- RoPE Cut
- Analogy: Think of a movie scene cut—suddenly switching from a room to a beach. RoPE Cut performs a clean “jump” in the model’s time coordinates, so it acts like a new scene without breaking the generation stream.
- What it does: It introduces a controlled “discontinuity” in time indexing so you can insert scene cuts, flashbacks, or location changes mid‑generation.
- Why it matters: You can build multi‑scene, cinematic videos in one go, while still preserving important things like character identity.
A note on very long memory:
- When videos get extremely long, the method lets older parts of the video turn into a “summary memory” of what happened (the gist), rather than storing the exact frame‑by‑frame timing. This is similar to how people remember the story of an event but not every exact second.
What they did to test it
- They applied Infinity‑RoPE to a strong video generator that was originally trained only on short, 5‑second clips.
- They did not retrain the model. They only changed how positions and memory are handled during inference.
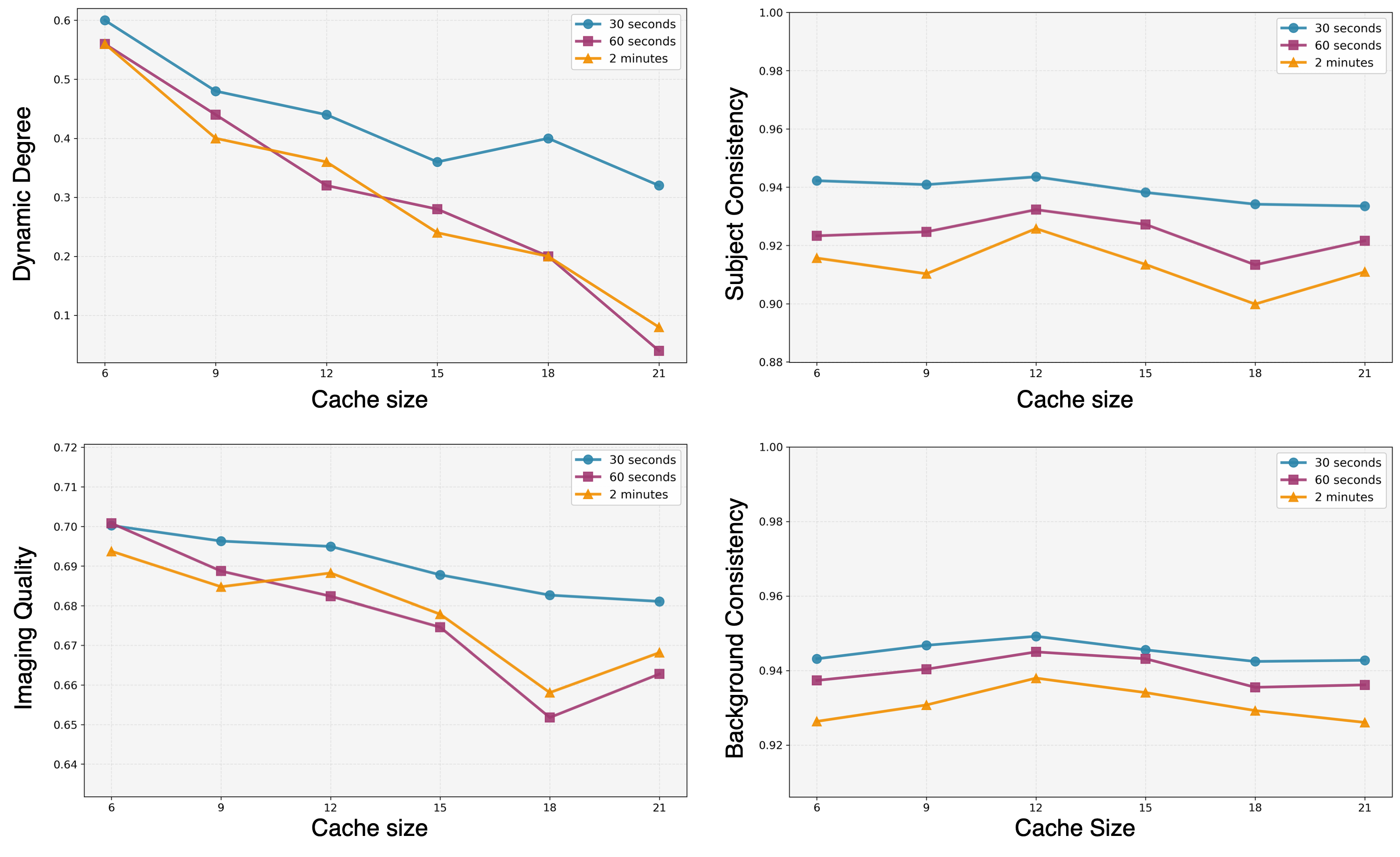
- They measured quality using VBench (an automatic video quality benchmark), checking things like:
- Subject consistency (does the main character stay the same?)
- Background consistency
- Motion smoothness
- Dynamic degree (how lively and non‑stagnant the motion is)
- Aesthetic and imaging quality
- They also ran user studies where people rated videos for overall quality and temporal consistency.
Main results and why they matter
- Much longer videos: The method produces 60s, 120s, and 240s videos with strong coherence. It is designed to scale to “infinite” length in principle.
- Better control: With KV Flush, the model responds instantly to new prompts mid‑video, without laggy or messy transitions.
- Cinematic cuts: With RoPE Cut, it can make clean scene changes in one continuous generation, while keeping character identity.
- Strong metrics and preferences: On standard benchmarks, Infinity‑RoPE often scores best or near‑best in long‑video quality, subject/background consistency, and motion smoothness. In user studies, people preferred these long videos for quality and stability.
Why this matters:
- Long, controllable, and cinematic videos are key for storytelling, streaming, live directing, and creative tools.
- Doing this without retraining saves huge amounts of time and compute, making powerful video generation more accessible.
What this could lead to
- Practical tools for creators to “live direct” AI videos: change actions on the spot, insert scene cuts, and keep characters consistent over long stories.
- Better streaming and interactive experiences, where the AI adapts instantly to user instructions.
- A path to scale current models to very long content without needing massive new datasets or training runs.
Limitations to keep in mind
- Since the method doesn’t retrain the base model, it inherits the base model’s flaws (like occasional flicker or unrealistic physics).
- Very large scene jumps can show mild artifacts at the cut, especially if the jump goes beyond what the base model saw during training.
In short
Infinity‑RoPE is a clever set of “time and memory tricks” that lets existing video AIs go long, react fast, and cut like a movie—without retraining. It turns short‑clip models into long‑form, action‑controllable, cinematic video generators.
Knowledge Gaps
Below is a single, focused list of concrete knowledge gaps, limitations, and open questions that remain unresolved and could guide future research.
- Formalization and proofs: The paper lacks a rigorous mathematical specification and analysis of Block-Relativistic RoPE (exact rotation formulas, invariance properties, stability conditions), making it unclear why and when the re-anchoring preserves attention geometry at long horizons.
- Semanticization trigger and schedule: The “semanticization” step (collapsing earliest tokens to a shared minimal index like
{1,1,1}wheni > f_limit) is not formally defined (criteria, thresholds, schedule) nor empirically ablated, leaving uncertainty about when and how to switch from episodic to semantic memory. - Global sink token definition: The “global sink latent frame” retained during KV Flush is not precisely described (how it is constructed, which layer/feature it corresponds to, how it’s updated), making replication and transfer to other models difficult.
- Action-change latency quantification: Claims of “instant” responsiveness under KV Flush are not backed by a quantitative latency metric (e.g., frames-to-action-change), nor compared rigorously to KV-Recache across varied cache sizes and prompt-change frequencies.
- Memory and compute profiling: The work asserts constant memory with KV Flush but provides no detailed memory/compute breakdown (e.g., GPU RAM, bandwidth, per-step FLOPs), nor head-to-head profiling against alternatives like KV-Recache under identical conditions.
- Horizon beyond 1024 latent frames: Although the paper claims generation “far beyond” the 3D-RoPE limit (1024 latent frames), experiments only reach 240 seconds at 16 FPS with 4× temporal compression (~960 latent frames), leaving performance beyond 1024 latent frames empirically unverified.
- Robustness at extreme durations: No evaluation of multi-hour or day-scale rollouts (or higher FPS/resolution scenarios) is provided; degradation patterns, failure modes, and recovery strategies at truly “infinite” horizons remain unknown.
- Hyperparameter sensitivity: There is no systematic study of sensitivity to
f0, cache size, block size, classifier-free guidance, timestep shift, or RoPE Cut offsets; practitioners lack guidance for tuning across tasks and models. - Block size choice: Generation proceeds in blocks of three latent frames; the impact of different block sizes on temporal coherence, responsiveness, and throughput is not ablated.
- Generalization across architectures: The method is evaluated only on Wan2.1-T2V-1.3B (Self-Forcing). It remains unclear how Infinity-RoPE transfers to other autoregressive frameworks (e.g., MAGI-1, NOVA), bidirectional DiTs, U-Net-based videos, or models without 3D-RoPE.
- Positional encoding alternatives: The approach targets 3D-RoPE; compatibility with other positional strategies (ALiBi, learned positional embeddings, relative attention) and whether “relativistic” reparameterization generalizes are not explored.
- Camera motion and occlusions: Robustness to challenging spatiotemporal conditions (rapid camera motion, occlusions, large-scale scene changes, fast actions) is not evaluated; failure cases are not cataloged.
- Multi-subject, multi-agent behavior: While examples of multi-subject streaming are shown, there is no targeted benchmark quantifying identity consistency, interaction fidelity, or role retention across long horizons and multiple scene cuts.
- Identity preservation metrics across cuts: RoPE Cut’s identity preservation is asserted qualitatively; a dedicated quantitative metric tracking identity across discontinuities (e.g., face embeddings before/after cuts) is absent.
- Transition artifacts for large Δ: Out-of-horizon RoPE Cut offsets (
Δ=45,90) introduce visible “transition edges”; mitigation strategies (e.g., cross-fade blending, adaptive Δ scheduling, attention regularization) are not proposed or evaluated. - Long-context reliance and forgetting: The trade-off between aggressive KV Flush (for responsiveness) and potential loss of long-range context is not quantified; when and how to flush optimally remains an open scheduling problem.
- Mechanistic attention analysis depth: Attention visualizations focus on a single layer (13th) and head-averaged maps; a comprehensive, layer-wise and head-wise analysis, plus causal attribution (e.g., probing effects of the sink token), is missing.
- Resolution and frame rate scaling: Experiments are at 832×480 and 16 FPS; impacts of higher resolutions and frame rates on stability, memory, and responsiveness are not studied.
- VAE temporal compression effects: The base 3D VAE compresses time by 4×; the influence of this compression ratio on long-horizon coherence and artifact accumulation is not ablated.
- Dataset diversity and evaluation scope: Evaluations rely on MovieGenBench and VBench; broader benchmarks with rich, compositional prompts, long narrative structures, and harder action choreography are needed to stress-test capabilities.
- Objective metrics beyond VBench: Standard generative video metrics (e.g., FVD, perceptual quality, motion realism) and task-specific metrics (e.g., physics plausibility, object permanence) are not reported for long horizons.
- Real-time streaming constraints: End-to-end latency (prompt→frame), jitter, and throughput stability under streaming constraints are not measured, despite the method’s intended streaming/interactive use case.
- Training-time integration: It is unknown whether incorporating Block-Relativistic RoPE, KV Flush, and RoPE Cut into training (distillation or fine-tuning) would further improve stability, reduce artifacts, or extend horizons beyond 1024 latent frames.
- Safety and content alignment: There is no analysis of content safety, bias, or controllability under adversarial prompts, and no mechanisms for constraint-aware long-form generation (e.g., ensuring consistency with safety policies across cuts).
- Reproducibility details: Hardware specs, seed control, and implementation specifics (e.g., cache management APIs, precise RoPE index remapping pseudocode) are incomplete, hindering exact reproduction and adoption.
Practical Applications
Overview
Based on the paper’s findings and methods—Block-Relativistic RoPE (infinite temporal horizon via relativistic positional encoding), KV Flush (instant, prompt-responsive action control at constant memory), and RoPE Cut (controlled, cinematic discontinuities within a single autoregressive rollout)—the following practical applications can be realized across industry, academia, policy, and daily life. The applications are grouped into immediate (deployable now) and long-term (requiring further research, scaling, or development), with sector mappings, potential tools/workflows, and key assumptions or dependencies noted.
Immediate Applications
These can be built and deployed now as they rely on training-free, inference-time reparameterizations applied on top of existing Self-Forcing/DiT video generators.
- Creative media and entertainment (Industry: film/VFX, advertising, social content)
- Long-form generative video production without retraining
- Tools/workflows: A “Generative Timeline Editor” that schedules
KV_Flush()at prompt changes andRoPE_Cut(Δ)at scene transitions; plugin for existing T2V engines (e.g., Wan-based) to support hour-long streams with consistent identity and motion. - Assumptions/dependencies: Access to a compatible Self-Forcing T2V model; GPU throughput sufficient for extended rollouts; acceptance of current visual limits (occasional flicker, imperfect physics).
- Rapid previsualization and storyboarding with multi-cut scenes
- Tools/products: “Cinematic Cut Composer” that uses RoPE Cut to emulate editorial cuts, flashbacks, and cross-location jumps in a single generation pass; timeline-aware prompt scripting.
- Assumptions/dependencies: Editors accept training-free artifacts at large Δ values; production uses human curation for QC.
- Real-time action-controlled avatar or character sequences for live events and streams
- Tools/products: “Prompt-Responsive Performer” driven by KV Flush for instant action updates (e.g., standing → jumping → sitting → singing) in live shows or VTuber pipelines.
- Assumptions/dependencies: Low-latency I/O; compliant content moderation and watermarking.
- Marketing and digital signage (Industry: retail, sports/venues)
- Endless in-store visuals and event displays with scheduled action changes and scene cuts
- Tools/workflows: Generative signage orchestrator that loops content indefinitely via Block-Relativistic RoPE and uses KV Flush for time-of-day changes and RoPE Cut for thematic transitions.
- Assumptions/dependencies: Operational guardrails (brand safety); compute provisioning for 24/7 generation.
- Education and training (Sector: education, corporate training)
- Long instructional videos with on-the-fly action transitions and scene changes
- Tools/products: “Lesson Generator” that injects new examples (KV Flush) and moves between modules (RoPE Cut) without re-encoding; storyboard-to-video scripts.
- Assumptions/dependencies: Human-in-the-loop validation for accuracy; alignment with accessibility requirements (e.g., captions).
- Software/AI tooling (Sector: software, developer platforms)
- Inference SDKs and APIs that expose controllable generation primitives
- Tools/products: “Infinity-RoPE SDK” with endpoints:
flush_cache(global_sink=True, keep_last_frame=True),rope_cut(delta),set_onset_index(f0),set_cache_size(n); integration for popular Python/JS video-gen frameworks. - Assumptions/dependencies: Base model supports 3D-RoPE and KV caching; licensing permits third-party integration.
- Social media and creator economy (Daily life, prosumer tools)
- Auto-generated vlogs, ambient loops, and multi-scene reels
- Tools/products: Mobile/desktop app featuring timelines and prompt markers; presets for travel montages or music-reactive visuals using KV Flush and RoPE Cut.
- Assumptions/dependencies: Device or cloud compute; safety filters; IP compliance (e.g., likeness, music rights).
- Research and academic use (Sector: academia)
- Benchmarking and analysis of long-horizon attention and positional encoding
- Tools/workflows: Instrumented rollouts to study attention maps, identity preservation, drift suppression, and VBench metrics under cache/onset/Δ ablations.
- Assumptions/dependencies: Reproducible environments; datasets and prompts aligned with evaluation frameworks.
- Operations and support content (Sector: enterprise)
- Procedural “how-to” and troubleshooting videos with scene cuts for workflow branches
- Tools/products: Generative SOP builder; timeline scripting with conditional prompts to reflect decision points.
- Assumptions/dependencies: Domain review to avoid hallucinated steps; clear disclaimer and QC pipeline.
Long-Term Applications
These require further research, scaling, or engineering to enhance fidelity, speed, multi-agent consistency, physics realism, and compliance.
- Real-time broadcast and interactive media (Industry: live TV, sports, news)
- Live augmentation and synthetic B-roll that reacts to operator prompts
- Potential products: Broadcast-grade generative overlay systems; control-room UIs combining KV Flush for immediate updates and RoPE Cut for narrative jumps.
- Assumptions/dependencies: Low-latency high-res generation; robust quality gates; strong brand and safety controls.
- Game development and virtual worlds (Sector: gaming, XR/VR)
- Generative cutscenes and dynamic storylines with identity consistency over hours
- Potential products: “Generative Director” for NPC cinematic arcs; XR experiences with live scene transitions.
- Assumptions/dependencies: Audio/dialogue alignment, multi-character control, physics-aware realism; engine integrations (Unity/Unreal).
- Robotics and autonomy (Sector: robotics)
- Synthetic, long-horizon video corpora for perception and policy learning
- Potential workflows: Domain-randomized scenarios with scene cuts to cover edge cases and KV Flush to trigger task phases (e.g., pick → place → navigate).
- Assumptions/dependencies: Bridging the sim-to-real gap; annotation pipelines; physics and kinematics fidelity beyond current generators.
- Healthcare and safety training (Sector: healthcare, energy/industrial safety)
- Extended scenario simulations (e.g., emergency response drills) with controlled transitions
- Potential products: “Scenario Generator” that sequences realistic phases (arrival → triage → intervention) via KV Flush and RoPE Cut; long-form safety drills for hazardous operations.
- Assumptions/dependencies: Clinical/industrial validation; ethical safeguards; risk of misleading visuals if used without expert oversight.
- Finance and enterprise communications (Sector: finance, enterprise)
- Compliance, product explainer, and investor relations videos with multi-scene workflows
- Potential tools: Policy-aware script-to-video pipelines; template libraries for disclosures; audit logs of prompt scheduling and cache operations.
- Assumptions/dependencies: Legal review, regulated content governance, traceability/watermarking.
- Multi-agent narratives and identity persistence (Sector: research/creative tech)
- Coordinated multi-subject control with consistent identities across long timelines
- Potential products: Multi-character controllers; identity locks; timeline graph editors that bind characters to semantic memory across cuts.
- Assumptions/dependencies: Advances in multi-subject consistency and occlusion handling; better cross-frame identity anchoring.
- Content integrity, safety, and policy (Sector: policy/regulation)
- Standards and governance for infinite generative video
- Potential tools: Watermarking, provenance (C2PA), automatic content filters; audit trails for prompt changes and cuts; “safety rails” that constrain KV Flush/Cut usage to approved templates.
- Assumptions/dependencies: Cross-industry agreement; regulatory clarity; integration into production toolchains.
- High-resolution, low-latency streaming (Sector: software/infrastructure)
- Mobile and edge deployment of long-horizon generation
- Potential products: GPU/ASIC-optimized inference; memory-aware caching strategies; adaptive quality modes for variable bandwidth.
- Assumptions/dependencies: Hardware acceleration; model compression and distillation to maintain quality at scale.
- Cross-modal alignment and production readiness (Sector: media tech)
- Audio, dialogue, and motion synchronization over long rollouts
- Potential tools: Prompt schedulers tied to audio beats; lip-sync control; timeline-based multi-modal editors that drive KV Flush/Cut from script markers.
- Assumptions/dependencies: Reliable audio-visual alignment; improved motion physics; robust editing APIs.
Notes on Assumptions and Dependencies
- Technical dependencies: Access to compatible base models (e.g., Self-Forcing Wan variants with 3D-RoPE and KV cache); GPU resources; VAE-based latent video pipelines; quality tolerance for current limitations (flicker, imperfect physics).
- Scalability constraints: Throughput and latency for high-res, long-duration content; memory strategies for cache size; effects of onset index and Δ on transitions.
- Legal and ethical considerations: Content authenticity, watermarking/provenance, model licensing, data rights, likeness/IP concerns, and appropriate content moderation.
- Reliability and QA: Human-in-the-loop review for educational, healthcare, and safety-critical content; scripted timelines and guardrails to prevent unintended semantics during KV Flush or RoPE Cut.
- Integration readiness: SDK/APIs for
flush_cache,rope_cut, cache/onset management; editors/timeline UIs; logging for auditability and reproducibility.
Glossary
- 3D Rotary Positional Embedding (3D-RoPE): A 3-axis rotary positional encoding used in transformers to encode temporal and spatial positions of tokens. "the finite temporal horizon imposed by the base model's 3D Rotary Positional Embedding (3D-RoPE)"
- 3D Variational Auto-Encoder (VAE): A video-specific VAE that compresses frames into a spatiotemporal latent tensor. "The model operates in a latent space encoded by a 3D Variational Auto-Encoder (VAE)"
- Action-controllable video generation: Inference-time control of actions via prompt changes while maintaining temporal continuity. "In autoregressive video diffusion, transitioning between prompts during inference, known as action-controllable video generation, requires balancing immediate semantic responsiveness with temporal continuity."
- Attention normalization: The normalization behavior within attention that can be stabilized via special sink tokens. "which respectively stabilize attention normalization and preserve local temporal continuity."
- Attention-sink cache: A persistent cache location (sink) that aggregates global context to stabilize attention over long sequences. "maintains a persistent attention-sink cache for global consistency."
- Autoregressive self-rollout: Training by conditioning on the model’s own generated frames to match inference behavior. "performing autoregressive self-rollout during training"
- Autoregressive video diffusion: Sequential diffusion-based generation where each frame conditions on previously generated frames. "In autoregressive video diffusion, transitioning between prompts during inference"
- Block-causal attention: Attention constrained to local blocks in time to respect causality and enable streaming generation. "converting dense bidirectional attention into block-causal attention."
- Block-Relativistic RoPE: A relativistic positional encoding that re-anchors temporal indices within a moving local reference frame to enable infinite horizons. "Block-Relativistic RoPE reformulates temporal encoding as a moving local reference frame"
- Classifier-free guidance: A technique that combines conditional and unconditional predictions to control adherence to the prompt. "a classifier-free guidance scale of 3.0"
- Chunk-wise autoregressive denoising: Generating in parallel by denoising chunks while maintaining autoregressive dependencies. "adopts chunk-wise autoregressive denoising with block-causal attention and parallel chunk generation"
- Diffusion forcing: A training strategy to steer diffusion models (often with RL and specific schedules) for long-form generation. "integrates diffusion forcing with reinforcement learning and a non-decreasing noise schedule for infinite-length synthesis"
- Diffusion Transformer (DiT): A transformer architecture adapted for diffusion modeling across space and time. "The introduction of Diffusion Transformers (DiTs) has further shifted the scaling frontier of generative video modeling"
- Distribution Matching Distillation (DMD): Distillation that aligns the student’s output distribution to a teacher’s distribution. "through Distribution Matching Distillation (DMD)"
- Euler discretization: A numerical method for solving ODEs during diffusion inference by stepping over time. "During inference, Euler discretization is applied over t to iteratively solve the ODE"
- Frame-level autoregression: Autoregressive generation at the granularity of individual frames. "LongLive complements this with frame-level autoregression and KV re-cache tuning"
- Global sink latent frame: A special cached frame acting as a sink to stabilize global attention across long rollouts. "the global sink latent frame and the last generated latent frame"
- High-SNR tokens: Tokens with a high signal-to-noise ratio that retain precise geometry and details. "recent high-SNR tokens retain precise temporal geometry."
- KV cache: The transformer’s key–value memory that stores past token representations for attention. "KV Flush renews the KV cache by retaining only two latent frames"
- KV Flush: An inference-time operator that resets the KV cache to minimal anchors to ensure immediate prompt responsiveness. "KV Flush renews the KV cache by retaining only two latent frames, the global sink and the last generated latent frame"
- KV-Recache: A cache-rebuilding mechanism that reconditions stored tokens under a new prompt. "LongLive introduces KV-Recache, a cache management mechanism designed to enable prompt-dependent action transitions in autoregressive models."
- MovieGenBench: A benchmark of cinematic prompts used for evaluating generative video systems. "We randomly sample prompts from MovieGenBench"
- Non-decreasing noise schedule: A noise scheduling strategy that does not decrease, used to facilitate long-form diffusion synthesis. "integrates diffusion forcing with reinforcement learning and a non-decreasing noise schedule for infinite-length synthesis"
- Rectified Flow: A diffusion formulation that parameterizes generation with a neural velocity field and solves an ODE from noise to data. "The model follows the Rectified Flow formulation"
- RoPE (Rotary Positional Embedding): A method for encoding positions via rotations in embedding space to support attention with relative phase. "adapting the temporal 3D RoPE ~\cite{su2024roformer}"
- RoPE Cut: An inference-time operation that introduces controlled discontinuities in temporal RoPE coordinates to realize scene cuts. "Finally, RoPE Cut introduces controlled discontinuities in temporal RoPE coordinates"
- Rolling KV cache: A moving window of KV memory that updates as new frames are generated. "using its own generated frames and a rolling KV cache"
- Semanticization: The process where distant temporal tokens collapse into abstract semantic memory rather than precise episodic detail. "Drawing inspiration from the semanticization process in cognitive neuroscience"
- Self-Forcing: A training paradigm that conditions on self-generated frames to reduce train–test mismatch. "Self-Forcing addressed this issue by performing autoregressive self-rollout during training"
- Self-Forcing++: An extension of Self-Forcing that supports long rollouts and distills over extended horizons. "Self-Forcing++ extended the framework to minute-scale horizons through long rollouts and extended DMD"
- Temporal Extrapolation Limit: The limit beyond which positional indices (e.g., RoPE) are outside training distribution, causing degradation. "Temporal Extrapolation Limit."
- Timestep shift: An inference hyperparameter that offsets diffusion timesteps to adjust generation dynamics. "a timestep shift of 5.0"
- Vector quantization: Discrete encoding of latents that some autoregressive methods remove for continuous prediction. "removing vector quantization for continuous latent autoregression"
- Velocity field: The neural field vθ that drives the ODE from noise to data in Rectified Flow. "the reverse process is parameterized by a neural velocity field v_{\theta} as an ordinary differential equation (ODE)"
- VBench: A benchmark suite measuring video quality, consistency, motion smoothness, and dynamics. "Comprehensive experiments show that $ consistently surpasses previous autoregressive models in overall VBench scores."
Collections
Sign up for free to add this paper to one or more collections.