- The paper introduces a novel transformer-driven SLAM system that leverages DEM representations to enhance spatial correction and reduce drift.
- It utilizes DINOv2 embeddings for efficient covisibility graph construction, achieving significant ATE reductions across datasets like KITTI and TUM.
- The high-frequency back-end performs local bundle adjustment in real-time, ensuring robust trajectory estimation in planar and repetitive environments.
System Overview and Core Contributions
VGGT-SLAM++ introduces a comprehensive visual SLAM system leveraging Visual Geometry Grounded Transformer (VGGT) outputs in conjunction with Digital Elevation Map (DEM)-augmented map representations and a high-cadence, spatially corrective back-end. The architectural design integrates a feed-forward transformer-based odometry front-end with a Sim(3) motion solver, a DEM-based covisibility graph synthesis exploiting DINOv2 embeddings for structure-aware spatial retrieval, and a back-end optimizer performing local bundle adjustment at rates commensurate with the front-end, affording superior drift suppression and global trajectory consistency.
Demonstrably, VGGT-SLAM++ addresses and outperforms prior transformer-based SLAM systems, notably rectifying their coarse inter-loop correction and drift accumulation, and extending robust spatial re-localization even in planar or repetitive environments. The methodology emphasizes three principal advances: compact DEM representations compatible with transformer-based encoders, efficient covisibility graph construction via structure-aware retrieval, and a back-end scheduling local optimization at high frequency.
Figure 1: Pipeline schematic for VGGT-SLAM++ depicting front-end odometry, DEM-based covisibility, and back-end spatial optimization.
DEM-Based Map Representation and Covisibility Graph Construction
DEMs constructed from VGGT submaps encode local geometry in a canonical 2.5D raster, discretized to fixed metric resolution, retaining affine structure critical for spatial matching. Each DEM tile is processed through a DINOv2 encoder, yielding geometry-aware descriptors with weighted aggregation based on local neighborhood salience and gradient visibility masks, maximizing central region reliability while attenuating boundary ambiguity.
Incoming query submaps generate DEM chips, subjected to identical DINOv2-based embedding, facilitating direct comparison against global DEM tiles indexed in a FAISS-HNSW structure. Chip-to-tile matching employs cosine similarity, aggregated via voting to identify covisible neighbors for loop detection. This yields a sparse covisibility graph where each edge encodes strong geometric compatibility, dramatically reducing the search space and retrieval latency.

Figure 2: DEM visualizations across datasets and trajectories, illustrating geometric fidelity and global loop closure.
Spatially Corrective Back-End: High-Frequency Local Bundle Adjustment
Edges identified in the DEM-based covisibility graph are further refined using AnyLoc for visual place recognition in the DEM domain, exploiting DINOv2 descriptors for robust loop detection under diverse viewing conditions. These edges form the constraint set for the spatially corrective back-end, which minimizes weighted geodesic error over Sim(3) similarity transformations, stabilizing submap poses via tangent-space residuals and Gauss–Newton optimization. Critically, this optimization operates at a frequency matching the front-end odometry, suppressing drift before global loop closure events and maintaining bounded trajectory error.
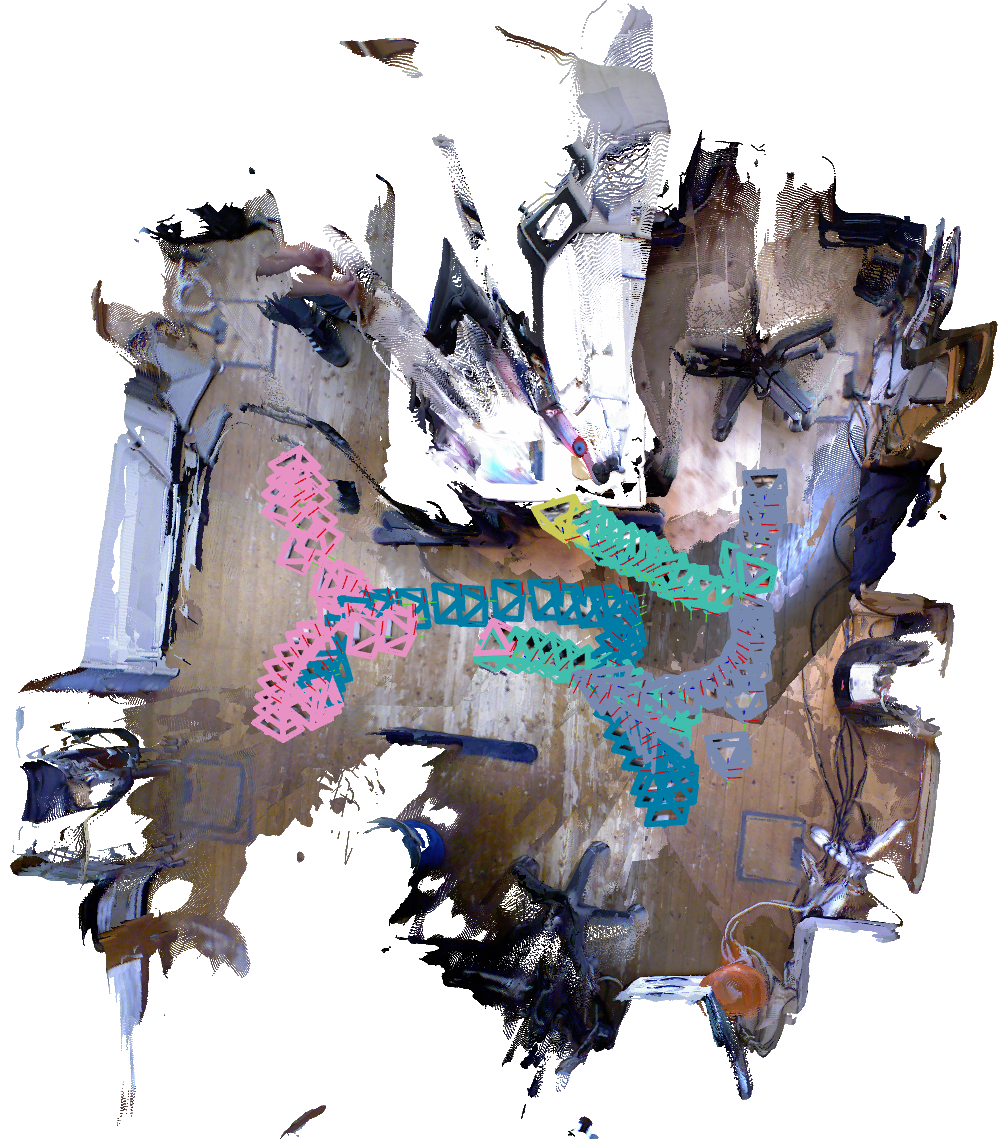
Figure 3: Preservation of geometric cues via DEMs leading to robust trajectory estimation in planar environments.
VGGT-SLAM++ is extensively evaluated on KITTI, TUM RGB-D, 7-Scenes, Virtual KITTI, and EuRoC, as well as custom datasets with groundtruth from GPS and robot kinematics. Results are reported via root mean squared Absolute Trajectory Error (ATE RMSE), with the system achieving SOTA performance on multiple RGB datasets with both calibrated and uncalibrated inputs. VGGT-SLAM++ demonstrates a 20% reduction in ATE on KITTI, 45% on TUM, 5% on 7-Scenes, and 14% on Virtual KITTI, compared to VGGT-SLAM baseline, alongside robust operation in long-horizon and planar trajectories.
Memory profile reveals efficient operation with constant VRAM and RAM usage per submap; front-end throughput is ~16 FPS and back-end optimization at 1.89 FPS. Ablative studies on DEM construction establish optimal aggregation settings—softmax reducer and a trade-off in DEM resolution producing the best trajectory error.

Figure 4: Quantitative results for RGB-D and GPS-annotated custom datasets, demonstrating low ATE RMSE across diverse conditions.
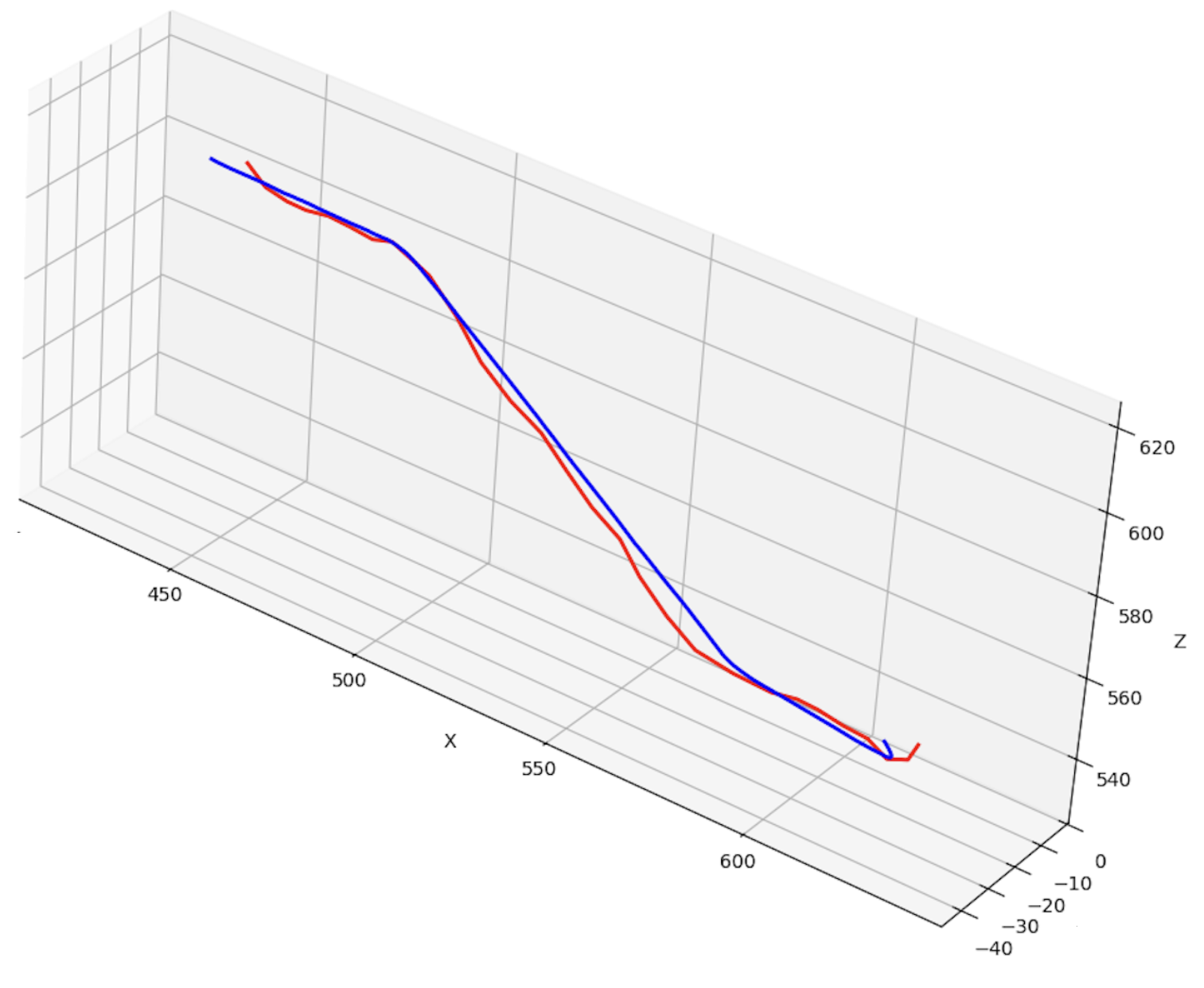
Figure 5: VGGT-SLAM++ trajectory estimation (blue) vs. GPS groundtruth (red) for custom GoPro camera datasets, reflecting high-fidelity localization.
Structural and Semantic Consistency: Zero-Shot Object Detection and Loop Closure Robustness
DEMs prove effective for scene augmentation, enabling zero-shot object detection via Grounded DINO, for objects such as parked vehicles, toys, and chessboards, underscoring the structural cue preservation in both indoor and outdoor contexts. DEM-based loop detection is shown to be viewpoint invariant, robust to traversal from opposite directions, as the height map encodes canonical geometry independent of front-view appearance.
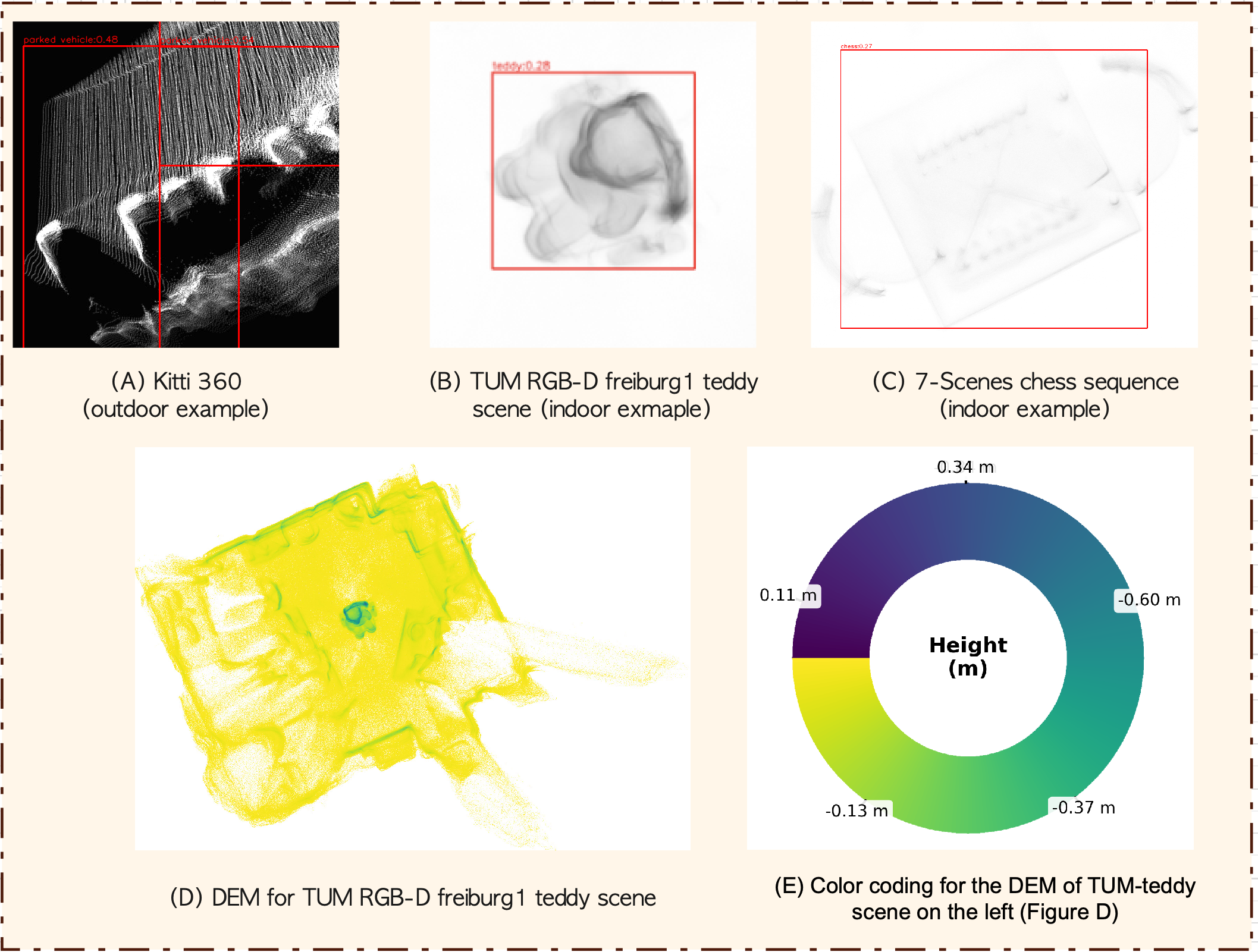
Figure 6: Zero-shot object detection from DEMs, highlighting structure retention and semantic augmentation.

Figure 7: DEM rendered from aligned odometry over KITTI sequence, colored for human visualization of geometric consistency.
Theoretical and Practical Implications
VGGT-SLAM++ demonstrates the efficacy of integrating transformer-derived semantics with geometry-preserving DEMs, enabling scalable, compact spatial reasoning and drift correction at high cadence. The use of DINOv2 embeddings in DEM domain bridges structure and appearance, augmenting retrieval performance and covisibility discovery. The adoption of Sim(3) back-end optimization yields robust pose alignment, outperforming SL(4)-based projective methods, notably in long trajectories and non-planar scenes.
Results indicate the transferability of DEM-based retrieval for robust visual place recognition, and highlight the system's adaptability to uncalibrated, monocular, and RGB-D inputs. Limitations persist in monochrome sequences, attributed to transformer training data biases, but the corrective back-end consistently improves overall trajectory accuracy.
Future Directions
Potential future research avenues include model compression for edge deployment, multi-modal map augmentation (e.g., integrating LiDAR or radar data), and development of hybrid encoding strategies that further improve generalization across modality and environment. Extension of DEM-based retrieval to multi-agent and collaborative SLAM scenarios, as well as adaptive tile resolution strategies for hierarchical maps, are promising directions for efficient large-scale mapping.
Conclusion
VGGT-SLAM++ establishes a robust transformer-based SLAM pipeline with DEM-augmented compact map representations, structure-aware spatial retrieval, and high-frequency bundle adjustment. The system achieves state-of-the-art accuracy and efficiency in both trajectory estimation and map consistency, substantiating the role of geometric structure in transformer-driven SLAM architectures. Its compactness and real-time feasibility on edge devices underscore its practical applicability, and its methodology lays groundwork for future advances in large-scale, transformer-augmented spatial intelligence.