- The paper presents a hybrid VO framework that couples efficient KLT-based sparse tracking with VGGT deep models to yield dense, real-time 3D reconstructions.
- It introduces an adaptive hybrid frontend and hierarchical backend using uncertainty-aware fusion and trajectory-based scale alignment to mitigate scale drift.
- Empirical evaluations on EuRoC and KITTI demonstrate significant error reductions and real-time performance, confirming its robustness for robotics and AR/VR applications.
HyVGGT-VO: Tightly Coupled Hybrid Dense Visual Odometry with Feed-Forward Models
Introduction
The paper "HyVGGT-VO: Tightly Coupled Hybrid Dense Visual Odometry with Feed-Forward Models" (2604.02107) presents a hybrid visual odometry (VO) framework designed to reconcile the trade-off between the efficiency of sparse VO and the dense 3D reconstruction capabilities of recent feed-forward models such as VGGT. While traditional sparse VO methods maintain computational efficiency and high-frequency pose estimation, they fail to produce dense scene representations. Contemporary feed-forward models provide high-fidelity dense outputs, but their immense computational overhead restricts pose estimation to infrequent, sparse keyframes, precluding real-time operation. HyVGGT-VO is formulated to tightly couple these orthogonal advantages in a unified, extensible architecture, supporting real-time, dense, and globally consistent reconstructions suitable for a broad range of robotics and AR/VR applications.
Motivation and Limitations of Previous Approaches
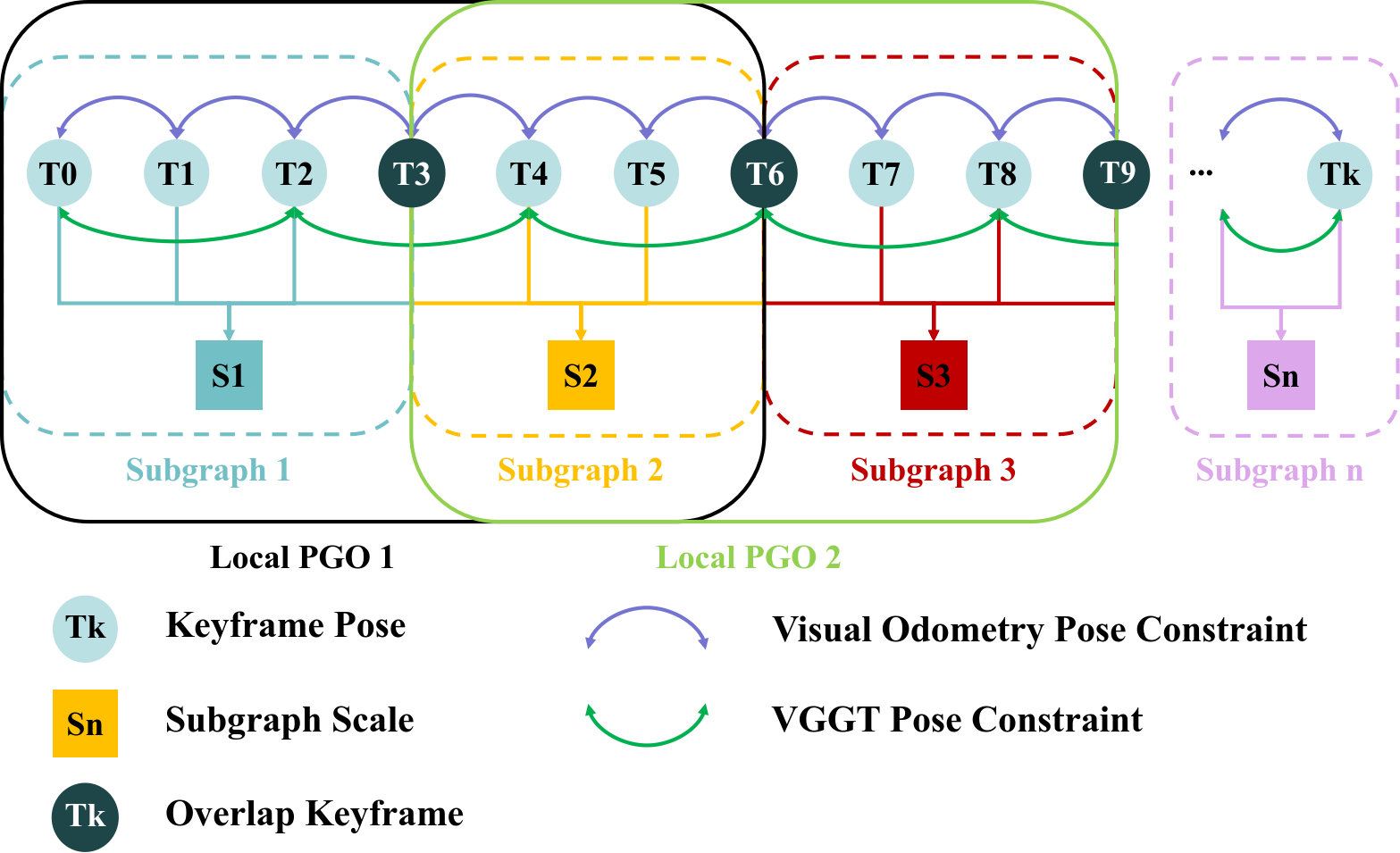
With the emergence of feed-forward prediction models for dense 3D reconstruction (e.g., VGGT, MASt3R), the potential for direct, unified SLAM pipelines has significantly expanded. However, the integration of these models into SLAM systems has been problematic. Existing methods such as VGGT-SLAM 2.0 rely on subdividing sequences into sub-graphs, each independently processed by a deep model, then aligned using noisy point cloud registration. This methodology results in several deficiencies: sparse and delayed pose outputs, cumulative global scale drift, loss of global scale consistency, and the inability to support real-time continuous tracking required for downstream robotic control.
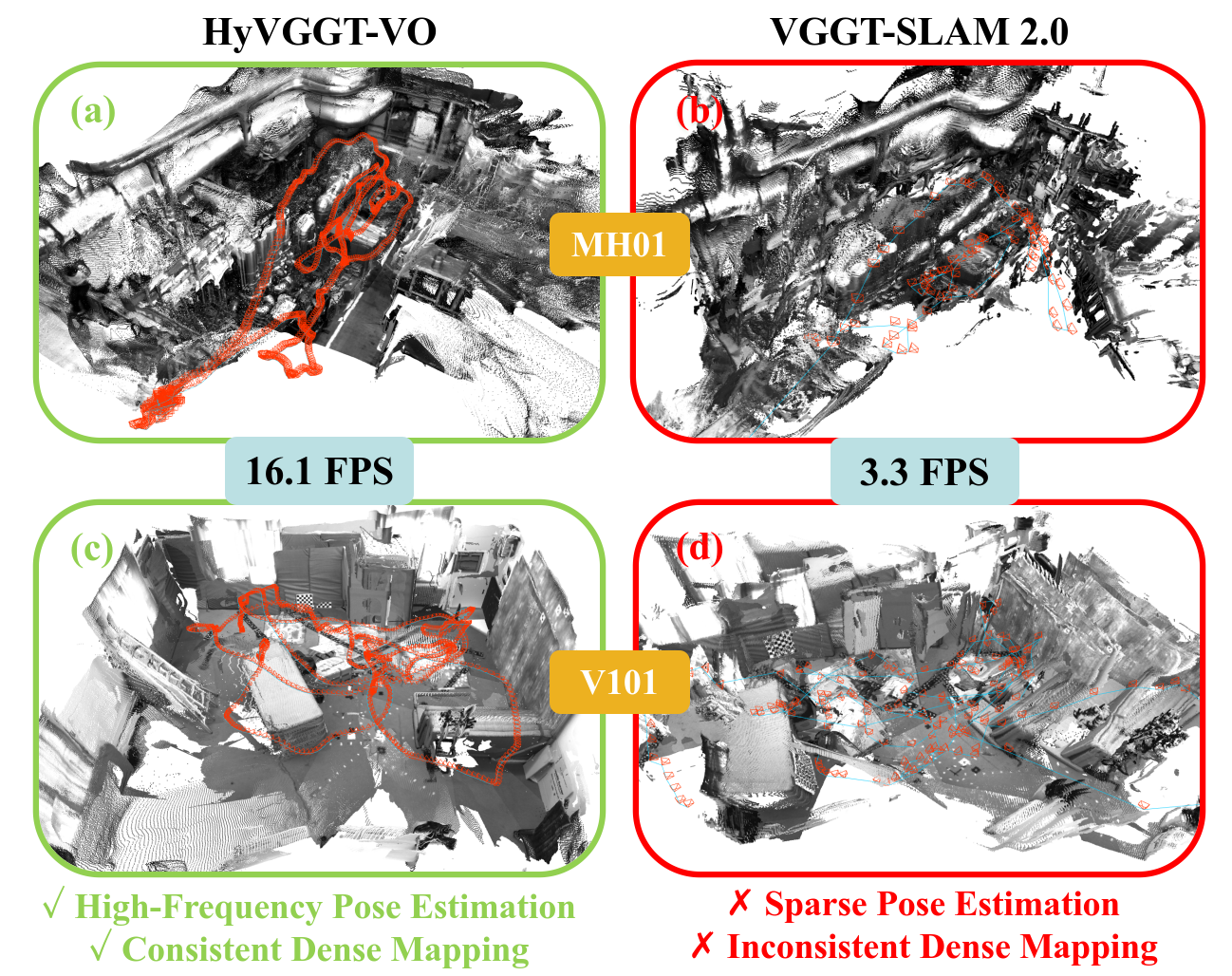
Figure 1: Dense 3D reconstructions from HyVGGT-VO achieve global scale consistency and high-frequency outputs, whereas previous methods yield sparse poses and scale drift.
Hybrid Architecture and System Design
HyVGGT-VO is structured around two principal components: (1) an adaptive, uncertainty-aware hybrid tracking frontend and (2) a hierarchical, asynchronous optimization backend. The system leverages a monocular image stream, feeding it through Kanade-Lucas-Tomasi (KLT) optical flow tracking for efficiency, but triggers a VGGT-based tracking head in scenarios of visual degradation, with dynamic uncertainty modeling using edge-aware confidence estimates from the network.
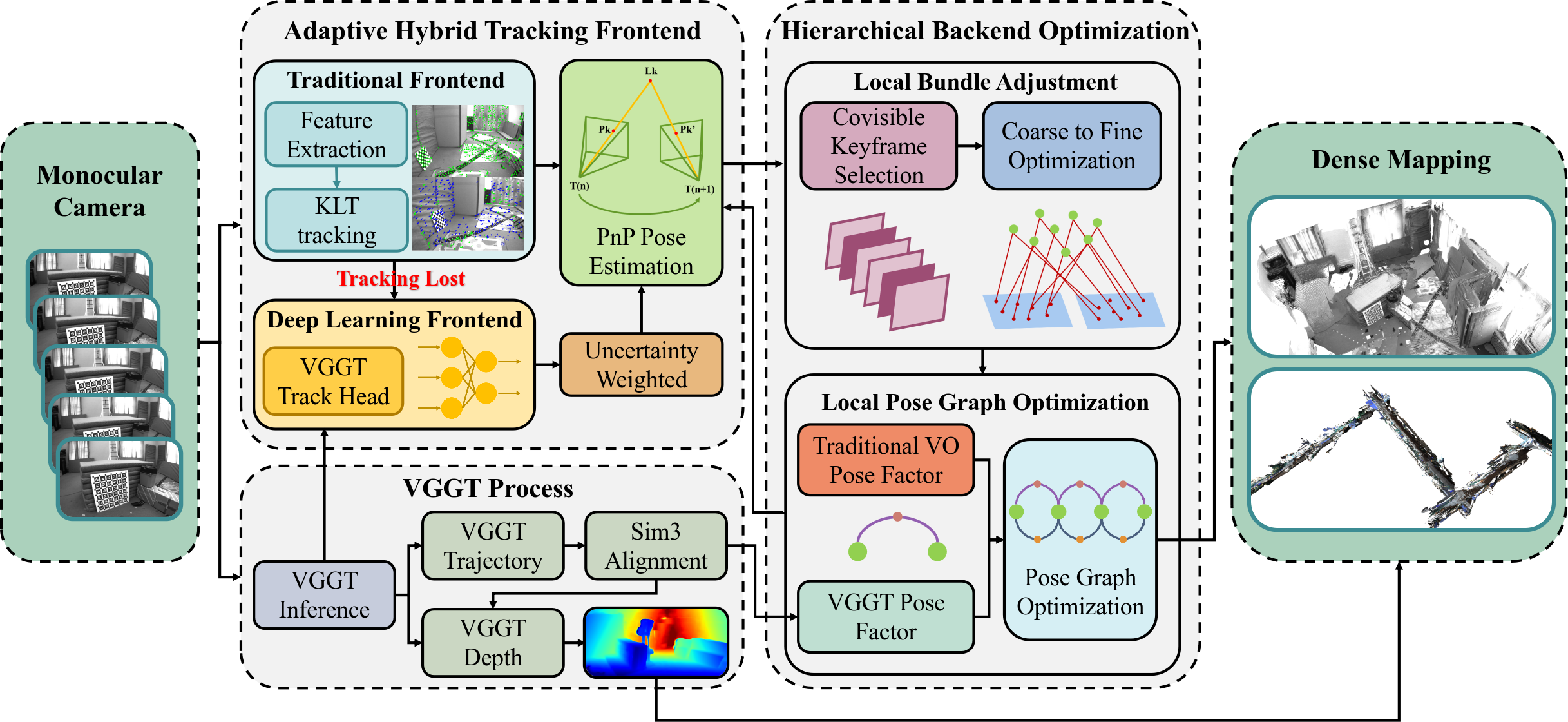
Figure 2: HyVGGT-VO architecture integrates a hybrid frontend with asynchronous hierarchical backend, enabling efficient, robust, and globally consistent dense VO.
The backend combines local bundle adjustment (BA) for metric precision with an asynchronous local pose graph optimization (PGO) layer, in which global scale is explicitly parameterized and refined using VGGT-inferred relative poses. This yields a formulation that is both computationally tractable and effective in eliminating scale drift.
Methodological Contributions
The framework introduces several technical novelties:
Empirical Evaluation
Indoor Environment (EuRoC MAV)
On the EuRoC MAV dataset, HyVGGT-VO achieves substantial gains: 85% reduction in average absolute trajectory error (ATE) compared to VGGT-SLAM 2.0, with the highest or second-highest accuracy across the majority of sequences, outperforming canonical learning-based and dense SLAM baselines. The qualitative 3D reconstructions (Fig. 4) reveal marked improvements in geometric consistency and resolution relative to both VGGT-SLAM and DROID-SLAM.
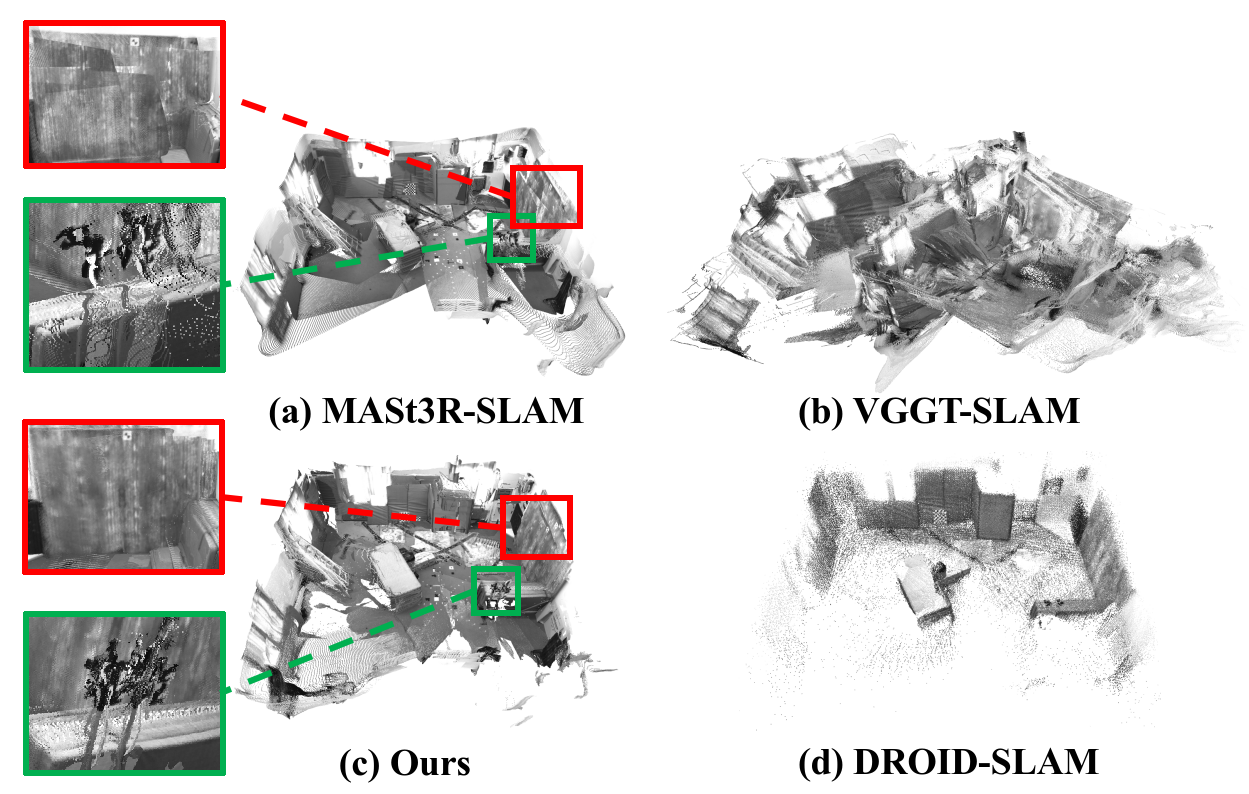
Figure 4: HyVGGT-VO preserves global structure and geometric details in dense reconstructions, avoiding the scale drift and sparsity of prior work.
Outdoor Environment (KITTI)
On the KITTI odometry dataset, which features extensive trajectories and challenging scale consistency requirements, HyVGGT-VO yields 12% lower ATE than VGGT-SLAM 2.0 and exhibits strong performance on medium and short sequences, nearly matching the computationally demanding DROID-SLAM, and significantly outperforming alternative feed-forward SLAM pipelines.
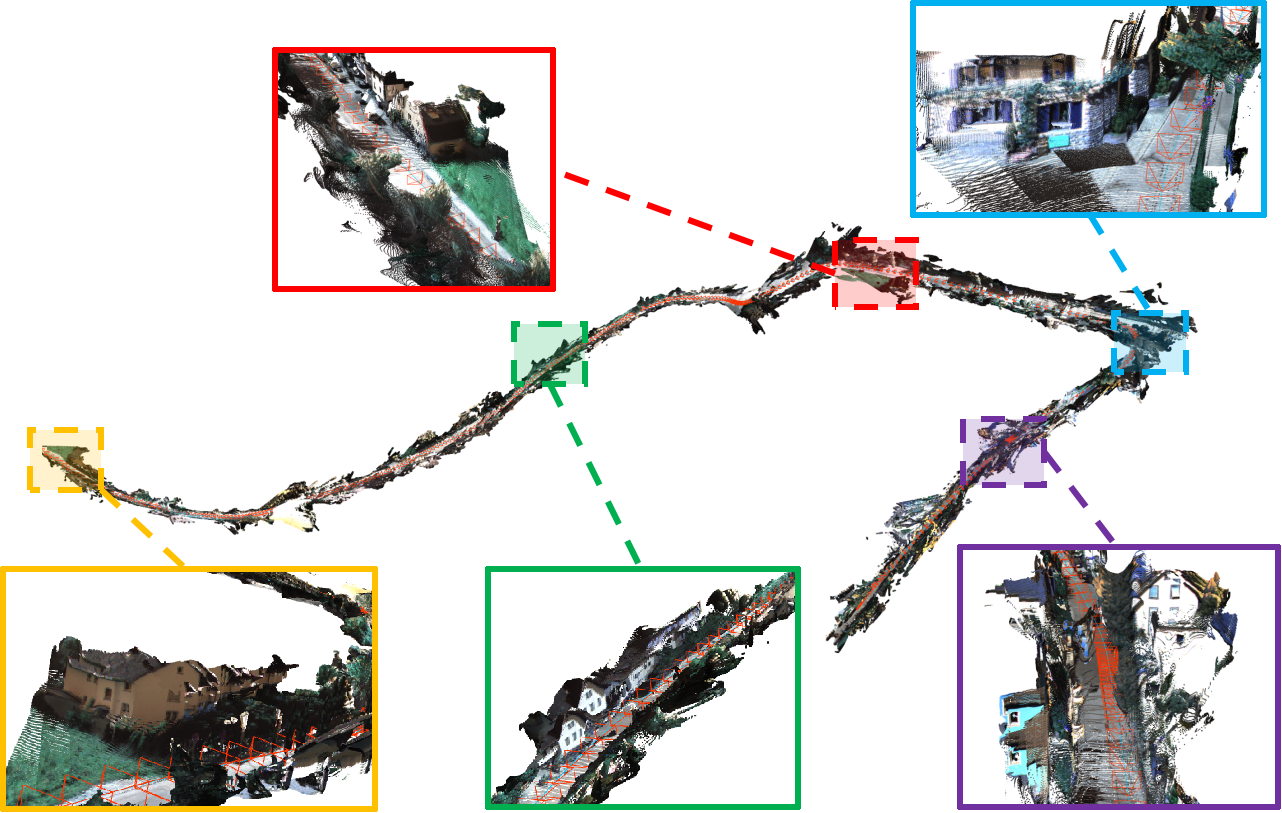
Figure 5: High-fidelity, large-scale street scene reconstruction with over 20 million points, visualizing scene geometry and colorfulness preserved by HyVGGT-VO.
Ablation Studies
Disabling the hybrid frontend (KLT-only) results in catastrophic failures on challenging sequences (e.g., rapid FOV changes, low-texture environments). The local PGO module is found to be essential for trajectory accuracy and scale drift suppression.
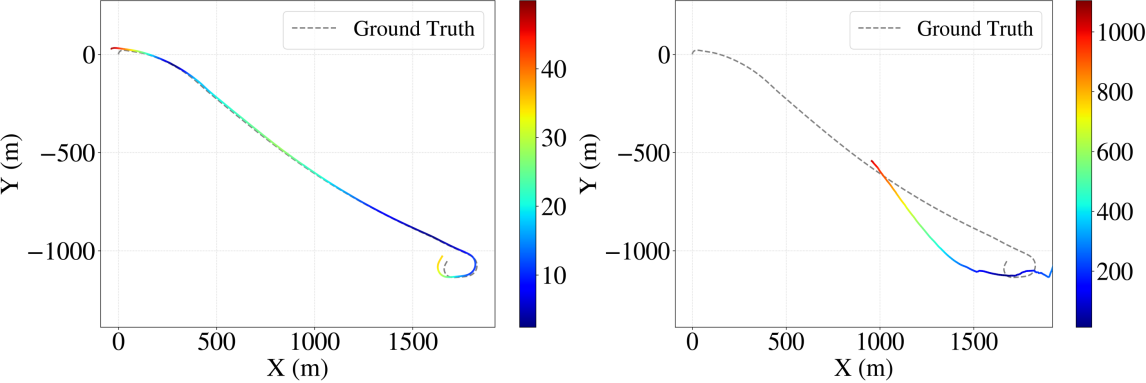
Figure 6: Qualitative trajectory accuracy comparison on KITTI 01; hybrid frontend ensures robust odometry where KLT fails.
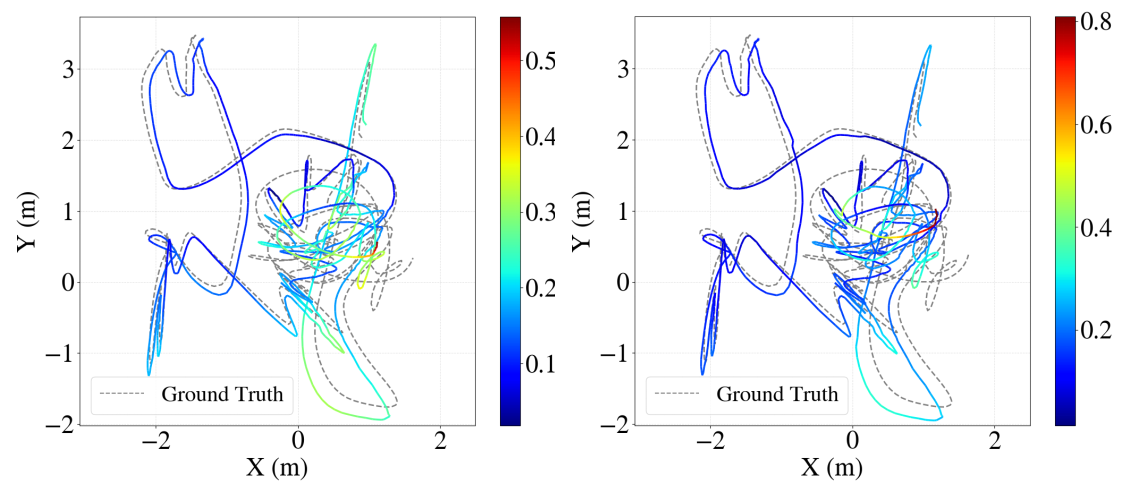
Figure 7: Local PGO ablation on EuRoC; error accumulation is visually mitigated by the inclusion of the PGO module.
Efficiency
HyVGGT-VO achieves real-time performance (16 FPS) with low GPU memory use (6.5 GB), compared to frequent out-of-memory failures with DROID-SLAM, VGGT-SLAM, and MASt3R-SLAM under the same memory constraints. The modular, asynchronous threading of the VGGT inference layer allows continuous, high-frequency pose output, thus supporting online robotics and AR/VR requirements.
Theoretical and Practical Implications
The results demonstrate that tightly coupled architectures, which integrate the geometrical stability of traditional sparse VO with the deep priors available from feed-forward models, can realize the benefits of both paradigms. Scale ambiguity and drift—longstanding issues in monocular SLAM—are addressed through factor-graph-based scale alignment and explicit scale optimization, challenging the dogma that high-fidelity dense mapping is incompatible with real-time operation on mainstream hardware.
For downstream applications such as autonomous robotics, AR/VR, and embodied AI, HyVGGT-VO provides a dense, real-time, high-frequency state estimator compatible with existing motion planning and control stacks. The extensible design suggests that the hybrid formulation is broadly generalizable to future feed-forward scene understanding models, including those enabling joint semantic or VLM-driven mapping.
Conclusion
HyVGGT-VO (2604.02107) sets a new standard for real-time, dense, and globally consistent visual odometry through principled integration of sparse VO and feed-forward deep models. Its hierarchical backend and hybrid frontend formulation eliminate the major pitfalls of preceding feed-forward SLAM systems, specifically scale drift and operational latency. The framework offers a scalable and extensible foundation for further research in dense reconstruction, robust SLAM, and closed-loop robotic systems, with clear pathways for extension to more generic 3D perception pipelines and multi-sensor fusion.