SLAM-Former: Putting SLAM into One Transformer
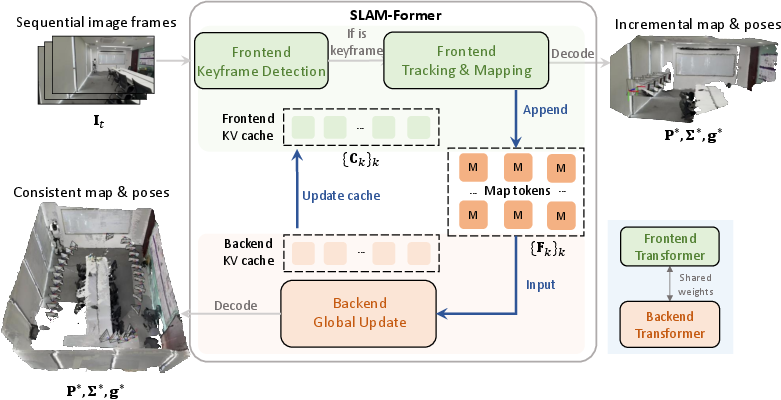
Abstract: We present SLAM-Former, a novel neural approach that integrates full SLAM capabilities into a single transformer. Similar to traditional SLAM systems, SLAM-Former comprises both a frontend and a backend that operate in tandem. The frontend processes sequential monocular images in real-time for incremental mapping and tracking, while the backend performs global refinement to ensure a geometrically consistent result. This alternating execution allows the frontend and backend to mutually promote one another, enhancing overall system performance. Comprehensive experimental results demonstrate that SLAM-Former achieves superior or highly competitive performance compared to state-of-the-art dense SLAM methods.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces SLAM-Former, a new AI model that helps a robot (or a phone, drone, or AR headset) build a 3D map of the world while figuring out where it is inside that world, using just a regular camera. This job is called SLAM, short for Simultaneous Localization and Mapping. The big idea is to put the entire SLAM system into one “Transformer” (a kind of neural network), so the model can both update the map as it sees new images and also fix mistakes by looking back at everything it has seen.
What are the goals or questions?
The paper sets out to solve a few clear problems:
- Can we make a single AI model that does all parts of SLAM, instead of stitching together many separate tools?
- Can it work in real time on a video stream (new frames coming in) and still stay globally consistent (not slowly drift off or misalign)?
- Can it beat or match the best existing methods on standard tests for tracking the camera and building a detailed 3D map?
How does SLAM-Former work?
Think of SLAM-Former like a smart traveler making a map while walking:
- The frontend is like scribbling notes quickly as you walk, marking important snapshots called “keyframes,” estimating where the camera is, and adding new pieces to the map.
- The backend is like stopping every so often to spread all your notes on a table, compare them carefully, and fix any mistakes so the map stays consistent.
Here are the key parts, explained in simple terms:
- Transformer: This is the AI “brain” that uses attention—a way to focus on the most important pieces of information across images. It processes image features broken into small patches (tokens), and also keeps a “memory” of past frames.
- Attention and KV cache: Attention lets the model look at relationships among frames. The KV cache is like a notebook of past important details (Keys and Values) the model reuses to process new frames faster and more accurately.
- Frontend (real-time):
- Decides if a new frame should be a “keyframe” (an important snapshot).
- Estimates the camera’s pose (its position and direction).
- Creates “map tokens,” which are tiny chunks of 3D info that together build a dense 3D map.
- Backend (periodic global cleanup):
- Looks at all the map tokens at once with full attention.
- Fixes drift (small mistakes that build up over time) and aligns everything so the map makes sense globally.
- Shares its improved “memory” back to the frontend so future frames are added more accurately.
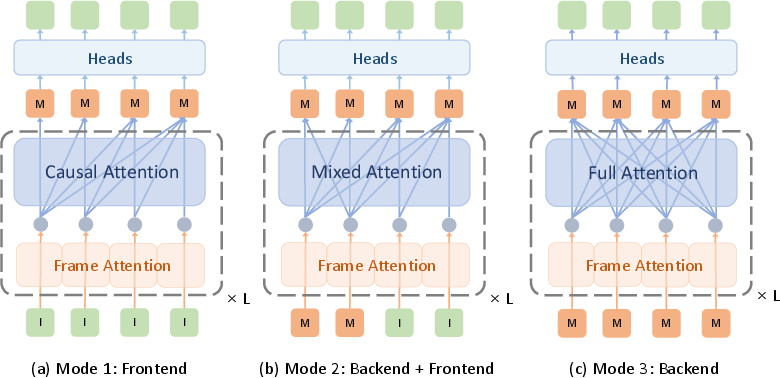
- Training in three modes:
- Frontend mode: Teaches the model to process frames as they arrive (mostly looking forward in time).
- Backend mode: Teaches the model to refine the entire map by looking at all frames together.
- Cooperation mode: Trains the frontend and backend to work in the same pass, so memory-sharing and refinement are learned together.
Analogy: Imagine writing a story in a notebook as you go (frontend), then every few pages you reread and edit the whole chapter (backend), and you keep the edited version in mind as you write the next pages (cache sharing).
What did they find, and why does it matter?
On standard datasets used to test SLAM systems (TUM RGB-D, 7-Scenes, Replica), SLAM-Former:
- Tracks the camera position very accurately, especially in the “uncalibrated” setting (where the camera’s internal settings aren’t known). This is harder, so strong performance here is impressive.
- Builds very detailed, high-quality 3D maps (“dense maps”) that are more accurate and complete than many top methods.
- Runs in real time, at over 10 frames per second in their tests.
- Handles tricky situations better, like returning to a place you’ve seen before (“loop closure”), where many systems drift or create misaligned layers. SLAM-Former’s backend attention helps fix those problems.
Why it matters: Better SLAM means more reliable navigation and mapping from simple cameras—useful for robots, AR/VR, phones scanning rooms, and drones exploring spaces—without needing special depth sensors. Doing it all inside one Transformer is cleaner, more unified, and easier to improve end-to-end.
What’s the potential impact?
SLAM-Former shows that one neural network can handle the full SLAM pipeline: quick updates as new images arrive and smarter global fixes to keep the map consistent. This could:
- Make SLAM systems simpler and more robust, improving apps in robotics, AR, and 3D scanning.
- Reduce the need for multiple modules (like separate loop-closure detectors and graph optimizers), because the backend’s full attention can learn to do that job.
- Inspire future designs that mix streaming (fast, incremental) and global refinement (consistent, stable) in one model.
A few limitations and future directions:
- The backend uses full attention, which can be slow for very long sequences because it compares everything to everything. Future work could use sparse attention or smarter selections to speed this up.
- The frontend currently depends on the shared memory (KV cache) of past keyframes; adding more local flexibility could help in some scenarios.
In short, SLAM-Former is a big step toward smarter, single-model SLAM that’s both fast and globally consistent, making camera-only 3D mapping more practical and reliable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what the paper leaves unresolved or insufficiently explored, aimed to guide future research:
- Scalability of the backend’s full attention: O(n²) complexity over all map tokens is acknowledged but unquantified; no analysis of memory footprint, token counts per frame, or behavior on sequences with thousands of keyframes. Explore sparse/graph attention, hierarchical memory, and token pruning/merging with quantitative trade-offs.
- KV cache growth and locality: The frontend requires “all previous KV caches” during inference, precluding sliding-window operation. Develop and evaluate windowed caches, cache pruning policies, hierarchical/segment caches, and mechanisms to bound memory while preserving global consistency.
- Backend triggering policy: The choice of backend frequency T is fixed and not analyzed. Study adaptive scheduling policies (based on drift/confidence/loop likelihood), their latency impacts, and the accuracy–compute trade-off across sequences of varying length and difficulty.
- Equivalence to loop closure: The claim that full attention is “equivalent” to loop detection on a dense factor graph is not formalized or evaluated. Provide theoretical justification and direct empirical comparisons to classic loop detectors and pose graph optimization (e.g., recall/precision on loop closures, optimization convergence vs. transformer refinement).
- Convergence and stability of alternating refinement: No guarantees or analysis of whether repeated frontend–backend alternation converges, oscillates, or overfits. Investigate conditions for convergence, stopping criteria, and safeguards against oscillatory or brittle updates.
- Cache consistency after global refinement: How backend-refined map tokens and KV caches remain consistent with previously stored caches is not examined. Analyze potential staleness/misalignment, propose cache re-synchronization strategies, and quantify their effect on tracking.
- Uncertainty use at inference: Confidence predictions (Σ*) inform training losses but are not explicitly used to weight attention, pose updates, or token trust during inference. Explore uncertainty-aware attention, robust weighting, and confidence-driven scheduling.
- Scale consistency: Local pointmaps aligned via a learned scale factor s* may accumulate scale drift over long sequences. Quantify inter-frame scale stability, investigate explicit scale constraints or global scale heads, and evaluate on datasets with known scale.
- Keyframe detection policy: A fixed translation threshold τ is used without sensitivity analysis or learned alternatives. Evaluate adaptive or learned keyframe selection (e.g., based on motion, overlap, uncertainty) and its impact on accuracy, compute, and memory.
- Robustness to dynamics and non-rigid scenes: Evaluations target mostly static indoor sequences. Test performance under dynamic objects, non-rigid motion, partial occlusions, and scene changes; develop mechanisms for motion segmentation or dynamics-aware tokens.
- Outdoor and large-scale generalization: No results on outdoor/large-scale datasets (e.g., KITTI, EuRoC) or long trajectories. Assess performance under varying lighting, weather, texture repetitiveness, and GPS-denied loops; study scaling limits and mitigation.
- Camera model variability: The method’s handling of unknown or changing intrinsics (zoom), rolling shutter, and lens distortion is unclear. Benchmark across diverse intrinsics and camera models; integrate intrinsics estimation or rolling-shutter-aware attention.
- Real-time scheduling and latency spikes: Backend runs introduce variable latency; worst-case delays and frame drops are not characterized. Develop scheduling strategies (e.g., background refinement, time-budgeted attention) and measure control-friendly latency under load.
- Map representation for robotics: Outputs are per-frame pointmaps; pipelines to construct globally consistent meshes/TSDF/occupancy maps for navigation/planning are not described. Design map fusion/compression, consistent meshing, and standard map exports.
- Failure modes and recovery: No systematic analysis of failures (textureless/specular surfaces, repetitive patterns, severe blur) or recovery strategies. Implement re-localization, place recognition, and cache bootstrapping after tracking loss.
- Training supervision and domain shift: Heavy reliance on supervised depth/pose datasets; feasibility of self-/weakly supervised training and robustness to domain shift are untested. Explore unsupervised objectives, data-efficient training, and cross-domain adaptation.
- Attention structure ablations: Only full attention is considered for backend; effects of learned sparsity, graph-structured attention (neighbor/loop candidates), or locality-aware kernels are not studied. Provide ablations linking attention structure to drift correction and loop closure.
- Parameter sensitivity: No study of sensitivity to λ, β, number of layers, token counts, patch sizes, or attention masks. Perform controlled ablations to identify dominant contributors and robust defaults.
- Quantitative cooperation analysis: Ablations (MB vs. EB) are limited; no time-resolved metrics (drift vs. time, loop closure recall, consistency gains per backend pass). Introduce temporal diagnostics and per-stage accuracy contributions.
- Mixed-attention multi-task training: Mode 2 trains frontend and backend together; potential task interference, curriculum needs, and stability are not examined. Investigate alternate training schedules, loss balancing, and decoupling strategies.
- Re-initialization and mid-sequence start: Handling of starting mid-sequence or after failure is not described. Develop re-initialization protocols, cache warm-start via place recognition, and safe reset mechanisms.
- Multi-sensor fusion: The approach is monocular RGB; integration with IMU, stereo, depth, or LiDAR to improve robustness and scale is unexplored. Propose fusion interfaces at token level and evaluate benefits.
- Resource and energy profiling: Compute/energy costs per frame and backend pass are absent; embedded deployment feasibility is unclear. Provide detailed profiling on commodity and edge hardware, and energy-aware variants.
- Semantic augmentation: No use of semantic labels or instance/room context to guide attention and map consistency. Explore semantic tokens, joint geometric-semantic training, and semantic loop proposals.
- Initialization dependency: The method is initialized from Pi3; the contribution of pretraining vs. training from scratch is not quantified. Assess dependence on the init weights and potential for purely SLAM-focused pretraining.
Practical Applications
Immediate Applications
Below is a focused set of deployable use cases that leverage SLAM-Former’s unified transformer SLAM, real-time frontend, and periodic global backend refinement. Each item notes sectors, potential tools/products/workflows, and key assumptions or dependencies.
- Autonomous indoor navigation for mobile robots in GPS-denied environments
- Sector: robotics, logistics, smart buildings
- Tools/products/workflows: ROS2 node for SLAM-Former; “KV-cache–aware navigator” that runs the causal frontend (>10 Hz) and triggers backend refinement every T keyframes; drop-in replacement for ORB/DROID pipelines in AMRs, warehouse robots, and cleaning robots
- Assumptions/dependencies: monocular camera quality, lighting stability, compute on edge (e.g., Jetson Orin or equivalent), careful tuning of keyframe thresholds and backend cadence; backend’s current O(n²) attention limits batch size
- Real-time AR interior design and home scanning on consumer devices
- Sector: software, consumer AR/VR, retail
- Tools/products/workflows: mobile SDK that runs the frontend on-device and offloads backend refinement to cloud; “RoomScan” app producing dense, globally consistent meshes for furniture placement and measurement
- Assumptions/dependencies: device NPU/GPU acceleration; intermittent connectivity for cloud backend; privacy safeguards for indoor mapping
- Visual Positioning System (VPS) for indoor wayfinding
- Sector: healthcare facilities, retail, campuses
- Tools/products/workflows: “Indoor VPS” service that builds consistent dense maps with SLAM-Former; routing and positioning middleware that consumes backend-refined map tokens
- Assumptions/dependencies: frequent map updates to handle layout changes; signage/visual features; compute footprint for backend refinement on the server side
- Drone-based inspection in confined spaces (warehouses, tunnels, plants)
- Sector: industrial inspection, energy, utilities
- Tools/products/workflows: monocular SLAM payload for small drones with “frontend-on-edge, backend-on-ground-station” workflow; mission planner that schedules backend passes post-flight
- Assumptions/dependencies: lighting and texture-rich surfaces; motion blur reduction; regulatory/safety constraints
- Rapid site documentation for AEC (Architecture, Engineering, Construction)
- Sector: AEC, facilities management
- Tools/products/workflows: “BIM-Link” pipeline that turns smartphone walkthroughs into dense, consistent maps; export to IFC/OBJ; periodic backend runs to correct drift before BIM synchronization
- Assumptions/dependencies: scene coverage, sufficient viewpoints, cloud refinement; measurement tolerances acceptable for as-built documentation
- Insurance claims and property assessment capture
- Sector: finance/insurance, real estate
- Tools/products/workflows: “ClaimScan” workflow—agents record monocular videos; frontend produces immediate preview; backend refines maps for accurate volumetrics and damage evaluation
- Assumptions/dependencies: accuracy thresholds defined by regulators; chain-of-custody and metadata standards; compute availability for periodic refinement
- Assistive navigation for visually impaired users in familiar indoor environments
- Sector: healthcare, accessibility, consumer apps
- Tools/products/workflows: smartphone app that builds consistent home/office maps; audio/haptic guidance powered by frontend tracking; backend refinement scheduled during charging
- Assumptions/dependencies: on-device compute and battery constraints; stable environments; robust handling of occlusions and low-light conditions
- Robotics research and education “one-model SLAM” baseline
- Sector: academia, edtech
- Tools/products/workflows: “SLAM-Former Playground” with notebooks and ROS2 demos; ablation-ready frontend/backend toggles for coursework; benchmark kits using TUM/7-Scenes/Replica
- Assumptions/dependencies: GPU availability; reproducible datasets; versioned model weights
- Game engine and digital content capture
- Sector: software, media/entertainment
- Tools/products/workflows: Unity/Unreal plugin to turn handheld camera paths into consistent level geometry; frontend for live previews; backend for final asset refinement
- Assumptions/dependencies: adequate texture; post-processing decimation; export formats for pipelines
- Quality assurance for visual pipelines (optics, camera placement)
- Sector: hardware QA, manufacturing
- Tools/products/workflows: “SLAM QA harness” that flags drift or inconsistencies across production lines using SLAM-Former’s ATE metrics; automated test routes with backend checks
- Assumptions/dependencies: repeatable trajectories; controlled lighting; metric baselines per product line
Long-Term Applications
Below are use cases that are promising but need further research, scaling, or development—often due to backend O(n²) complexity, multi-agent coordination, regulatory validation, or robustness requirements.
- City-scale collaborative mapping with multi-session/multi-device fusion
- Sector: smart cities, infrastructure, mapping platforms
- Tools/products/workflows: “Collaborative SLAM Cloud” that aggregates KV caches and map tokens across users/devices; sparse/dynamic attention or token merging for scalable backend
- Assumptions/dependencies: scalable sparse attention; data governance, privacy/consent frameworks; robust loop closure equivalents via attention over very large graphs
- Multi-robot SLAM with distributed KV-cache sharing
- Sector: robotics, logistics, defense
- Tools/products/workflows: distributed memory and cache synchronization; backend running on an edge server that refines global map, pushes updated caches to robots
- Assumptions/dependencies: low-latency networking; conflict resolution for concurrent mapping; resilience to communication dropouts
- Surgical and endoscopic navigation using monocular cameras
- Sector: healthcare/medtech
- Tools/products/workflows: “Med-SLAM-Former” tuned for texture-poor, specular, and deforming tissues; sterile, real-time guidance; backend refinement post-procedure for audit and training
- Assumptions/dependencies: rigorous clinical validation; regulatory approval (FDA/CE); domain-specific pretraining; handling soft-body motion and fluid occlusions
- Autonomous driving augmentation from monocular dashcams
- Sector: automotive
- Tools/products/workflows: on-vehicle frontend for real-time localization; backend map refinement across fleets; HD map updates using dense monocular reconstructions
- Assumptions/dependencies: multimodal fusion (LiDAR/radar/GNSS); very large-scale attention sparsification; stringent safety/ISO standards
- Semantic SLAM with scene understanding and task conditioning
- Sector: robotics, inspection, AEC, retail
- Tools/products/workflows: “SemSLAM-Former” where map tokens carry semantics (rooms, assets, hazards); workflows for inventory auditing or code compliance
- Assumptions/dependencies: multi-task training with segmentation/detection; label quality; on-device memory constraints
- Continuous digital twins with scheduled global refinement
- Sector: AEC, manufacturing, facilities
- Tools/products/workflows: “TwinRefine” service—devices capture over weeks; backend periodically enforces global consistency across evolving environments
- Assumptions/dependencies: change detection; map versioning and diffing; scalable backend; data lifecycle governance
- Disaster response mapping in degraded conditions
- Sector: public safety, defense
- Tools/products/workflows: rugged monocular kits for first responders; frontend-only operation under smoke/dust; backend refinement post-mission
- Assumptions/dependencies: robustness to extreme blur/noise; minimal light; domain-adapted training; offline operation
- Subsea/underwater monocular SLAM for ROVs
- Sector: energy, marine robotics
- Tools/products/workflows: adapted optics and image enhancement; workflow where backend runs topside after missions to produce consistent inspection maps
- Assumptions/dependencies: water turbidity, lighting; domain-specific models; pressure/temperature resilience
- Privacy-preserving mapping and policy frameworks
- Sector: policy/regulatory, consumer software
- Tools/products/workflows: on-device encryption of tokens/KV caches; consent management; map redaction for sensitive areas; compliance toolkits
- Assumptions/dependencies: legal standards (GDPR/CCPA); developer tooling for privacy-by-design; interoperable schemas
- Standardization and certification of SLAM safety for robotic deployments
- Sector: policy/regulatory, robotics
- Tools/products/workflows: test suites and conformance reports around ATE thresholds, failure modes, drift recovery; certification processes for hospital/warehouse use
- Assumptions/dependencies: consensus standards; reproducible benchmarks; traceability of model versions and training data
Notes on feasibility assumptions and dependencies (common across applications)
- Compute: Real-time frontend (>10 Hz) demonstrated on high-end GPUs; practical deployment may require optimization, quantization, or edge accelerators; backend’s full attention is O(n²) and needs sparse attention/token merging for large-scale or multi-session use.
- Sensors: Monocular RGB only; performance depends on texture, lighting, motion blur; uncalibrated mode reduces setup friction but may need tuning for specific lenses and rolling-shutter effects.
- Data/Models: Pretraining (Pi3) and large-scale training data drive generalization; domain adaptation may be necessary for medical, underwater, or extreme environments.
- Workflows: Alternating frontend/backend execution and KV-cache sharing are core; backend cadence (every T keyframes) must be tuned to balance latency and consistency.
- Governance and safety: Indoor mapping raises privacy considerations; industrial/medical use cases require compliance, validation, and, in some cases, certification.
Glossary
- Absolute Trajectory Error (ATE): A metric that quantifies the difference between estimated and ground-truth camera trajectories. "We compute the Root Mean Square Error (RMSE) of Absolute Trajectory Error (ATE) for various methods under both calibrated and uncalibrated settings."
- AdamW: An optimization algorithm that decouples weight decay from gradient updates to improve training stability. "we utilize the AdamW optimizer with a learning rate of $1e-5$, and a cosine learning rate scheduler."
- Attention key-value cache (KV cache): Stored key and value tensors from attention layers used to efficiently process sequences incrementally. "Their streaming variants, StreamVGGT and Stream3R, by carefully leveraging the attention key-value cache (KV cache), enable the model to process incremental visual inputs."
- Backend: The SLAM module that periodically performs global updates to correct drift and enforce consistency. "the backend performs global refinement to ensure a geometrically consistent result."
- Bundle adjustment: A joint optimization of camera poses and 3D structure to minimize reprojection error across multiple frames. "incorporate deep optical flow model into the pipeline and co-optimize both with a speed-dense bundle adjustment."
- Causal attention: An attention mechanism that restricts dependencies to past inputs for online, sequential processing. "StreamVGGT and STream3R further incorporate causal attention, drawing inspiration from modern LLMs to enable real-time streaming reconstruction."
- Chamfer distance: A bidirectional geometric distance metric between point sets used to evaluate reconstruction quality. "In terms of completeness and chamfer distance, our method achieves $0.037$m and $0.027$m, respectively"
- Dense factor graph: A graph where variables (e.g., poses) are connected by many constraints (factors), enabling robust global optimization. "is equivalent to processing loop detection on a dense factor graph."
- Dense mapping: Reconstruction that aims for detailed, continuous 3D representations rather than sparse points. "In contrast, dense mapping techniques aim to create a more detailed and continuous representation of the environment, mainly relying on LiDAR and RGB-D"
- Depth latent: A compact latent representation of depth used to reduce computation when estimating depth maps. "optimize the depth latent as an alternative."
- Drift: Accumulated error in pose or map estimates over time that leads to global inconsistency. "leading to drift and limited global consistency."
- Full attention: Attention that allows all tokens to attend to all others, providing global receptive fields for refinement. "the backend refines map tokens with full attention"
- Gaussian Splatting: A rendering-based 3D scene representation using anisotropic Gaussian primitives for fast novel view synthesis. "Gaussian Splatting based methods have emerged as a trend to reshape Dense SLAM."
- Global refinement: Periodic optimization across all frames/tokens to correct accumulated errors and produce consistent reconstructions. "the backend performs global refinement to ensure a geometrically consistent result."
- Huber loss: A robust loss function that is less sensitive to outliers, often used for pose consistency. "For camera loss, relative pose consistency is supervised using a scaled Huber loss:"
- Incremental mapping: Updating the map continuously as new frames arrive during online operation. "the frontend processes sequential monocular images in real-time for incremental mapping and tracking"
- Keyframe: A selected frame that is stored and used as a reference for tracking and mapping. "The frontend operates in real-time on the sequential RGB images for keyframe selection and incremental map and pose updates."
- LiDAR: A sensor that measures distances via laser pulses, used for accurate dense mapping. "mainly relying on LiDAR and RGB-D"
- Loop closure detection: Identifying previously visited locations to reduce drift via global optimization. "traditional SLAM pipelines typically rely on loop closure detection and graph optimization for this purpose."
- Map tokens: Transformer tokens that serve as implicit representations of scene geometry for each frame. "The backend is responsible for refining the map tokens to enforce global consistency."
- Monocular SLAM: SLAM performed using a single camera, estimating depth and motion without additional sensors. "dense monocular SLAM using only images as input"
- NeRF: A neural radiance field representation for photorealistic novel view synthesis optimized from images. "NeRF-SLAM methods optimize the scene as a whole for a highly realistic novel view synthesis objective."
- Optical flow: Pixel-level motion estimation between images used to aid tracking and reconstruction. "incorporate deep optical flow model into the pipeline"
- Permutation-equivariant: A model property that ensures outputs are consistent regardless of input ordering. "introduces a permutation-equivariant design that removes the dependence on a fixed reference view, enhancing robustness to input ordering and scalability."
- Pointmap: A per-frame set of 3D points predicted by the model for reconstruction and alignment. "Transformer-based models for multi-view pointmap estimation."
- Pose drift: Gradual deviation of estimated camera poses from the true trajectory over time. "Both VGGT and Pi3 suffer from pose drift, leading to geometric inaccuracies, while our method demonstrates consistent and accurate reconstruction."
- Pose graph: A graph where nodes are camera poses and edges impose relative pose constraints; used for global optimization. "requires an additional loop detection module to close its pose graph"
- Register tokens: Learnable tokens shared across frames in transformers to stabilize and unify representation without a fixed reference. "we employ shared register tokens across all frames, thereby eliminating the need to designate a reference frame."
- RGB-D: Color images paired with per-pixel depth, commonly used for dense mapping. "mainly relying on LiDAR and RGB-D"
- RMSE: Root Mean Square Error, a standard deviation measure of error magnitudes used for trajectory evaluation. "We compute the Root Mean Square Error (RMSE) of Absolute Trajectory Error (ATE)"
- Scale factor: A multiplicative term used to align predicted depths/pointmaps with ground truth scale. "and a scale factor estimated following Pi3:"
- SL(4) manifold: A mathematical group/manifold used to model and correct geometric distortions in transformations. "connects them using a novel SL(4) manifold, modeling the geometry distortion in foundational geometry for the first time."
- Spatial memory: A persistent structured memory that stores and updates scene information during streaming reconstruction. "Spann3R extends Dust3R to streaming by maintaining and interacting with a spatial memory."
- Streaming reconstruction: Online 3D reconstruction that processes frames sequentially with minimal latency. "enable real-time streaming reconstruction."
- TSDF-fusion: A volumetric integration method using Truncated Signed Distance Functions to merge depth observations. "TSDF-fusion could only fix small mismatches."
- Visual SLAM: SLAM performed using visual data (images), estimating both camera poses and maps. "we introduce a visual SLAM framework implemented within a single unified transformer architecture"
Collections
Sign up for free to add this paper to one or more collections.