- The paper introduces SWE-Shield, a benchmark that empirically reveals how test pass rates overestimate the quality of LLM-generated patches by overlooking design constraints.
- It employs a multi-stage, LLM-driven process to extract, associate, and verify implicit design constraints from code reviews and commit diffs.
- Empirical analysis shows that even high pass rate patches frequently violate critical design rules, highlighting the need for explicit design-aware refinement.
Evaluating Design Constraint Compliance in LLM-based Issue Resolution
Introduction
The standard evaluation of LLM-based issue resolution agents has predominantly relied on test pass rates, implicitly assuming that functional correctness (as indicated by passing tests) is a comprehensive indicator of patch quality. However, in software engineering practice, patch acceptance is also heavily governed by project-specific design constraints, encompassing architectural conventions, error-handling strategies, maintainability requirements, and community-defined best practices, typically only implicitly documented and enforced through code review processes. "Does Pass Rate Tell the Whole Story? Evaluating Design Constraint Compliance in LLM-based Issue Resolution" (2604.05955) critically challenges this paradigm. The authors introduce design-aware issue resolution and propose SWE-Shield, a benchmark constructed to surface, explicitly document, and provide measurable evaluation of latent design constraints, enabling an empirical and statistical investigation of the degree to which leading LLM-based agents can comply with such multidimensional requirements in realistic resolution scenarios.
Motivation and Problem Analysis
The paper establishes, through concrete case studies, the inadequacy of test-centric evaluation in approximating real-world patch acceptability. The motivating example draws from Django's project history, where a patch that passed all tests was subsequently reverted due to violation of implicit, repository-specific design constraints (e.g., portability across database backends and adherence to preferred error-handling idioms). Such constraints, as the discussion demonstrates, are often non-executable, contextually conditional, and maintained as an implicit social contract in code review threads and historical discussions, not encoded in automated tests.
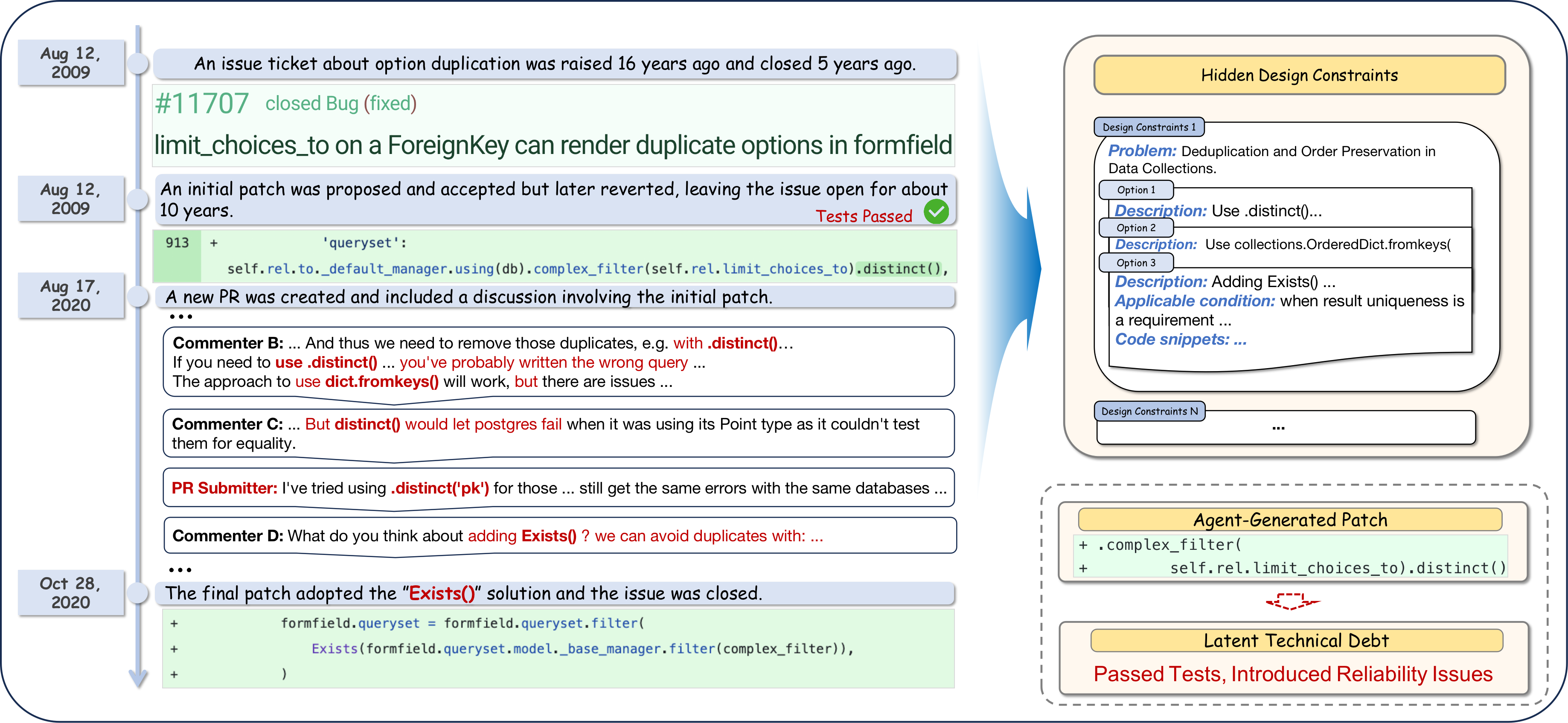
Figure 1: Example of realistic issue resolution with embedded design constraint rationale.
The analysis identifies two principal challenges:
- Extraction and Association: Design constraints are implicitly scattered and entangled with other discussions in pull requests; automatic extraction and contextual association to concrete issue instances are technically non-trivial.
- Verification: Compliance checking cannot be performed via simple test oracles and requires semantic reasoning to match code modifications against nuanced, often conditional, design rules.
SWE-Shield Benchmark Construction
SWE-Shield is realized through a multi-stage pipeline:
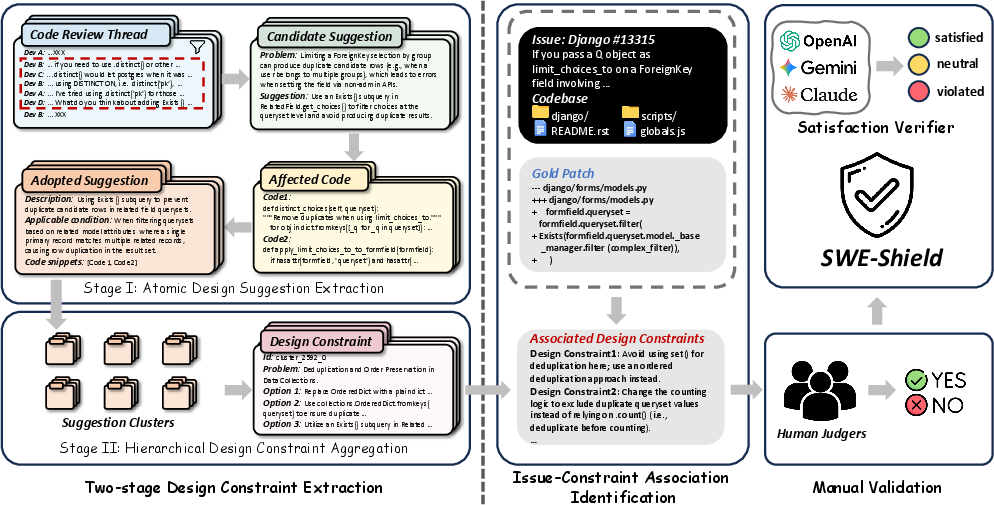
Figure 2: Pipeline for extracting, validating, and associating design constraints with issue instances.
- Design Constraint Extraction (DesignHunter):
- Stage I: A sliding-window LLM-driven process decomposes code review threads into atomic, semantically-validated design suggestions, cross-referenced with commit diffs to confirm adoption.
- Stage II: Hierarchical semantic clustering and LLM synthesis aggregate related suggestions into structured design constraints, capturing problem descriptions, alternative options, applicability conditions, and traceable rationale linked to concrete code regions.
- Constraint-Issue Association:
- Explicit traceability is established via direct links within the resolutive PR context.
- When explicit links are absent, semantic matching retrieves relevant design constraints from the broader repository history by measuring embedding similarity between change intents and constraint descriptions.
- Design-Aware Patch Verification:
- Patch compliance with constraints is assessed by an LLM ensemble (with majority-voting), systematically distinguishing between Satisfied, Violated, and Neutral (non-applicable) outcomes by reference to the problem, options, and applicability conditions.
The resulting SWE-Shield benchmark encompasses 495 issue resolution tasks (from six repositories), with 1,787 manually validated, contextually associated design constraints.
Empirical Analysis: Evaluation of SOTA Agents
RQ1: Effectiveness in Design-Aware Issue Resolution
Despite high pass rates (SWE-Shield: 70.25%–75.95%; SWE-Shield-Pro: up to 42.69%), all major LLM-based agents exhibit markedly lower rates of full design satisfaction (DSR: 32.6%–50.2%) with frequent, widespread violations (DVR up to 45.85%).
- Even the best-performing agent, SWE-agent (Claude-Sonnet-4.5), displays a ~50% DSR, indicating that approximately half the patches violate at least one critical design constraint.
- Categorization along functional and design dimensions reveals a significant population of patches that pass tests yet violate design rules—demonstrating a persistent gap between correctness as measured by tests and design-compliant acceptability.
RQ2: Statistical Relationship Between Correctness and Satisfaction
Quantitative association tests (chi-squared and Cramér’s V) confirm a negligible relationship between functional correctness and design satisfaction (V≤0.11 across agents). Many patches that pass all tests still actively introduce design violations, often undermining security, maintainability, or system architecture.
RQ3: Comparative Analysis of Foundation Models and Constraint Failure Patterns
Different foundation models (Kimi-K2, GPT-5, Claude-Sonnet-4.5, Gemini-2.5/3.0-Pro) demonstrate only modest DSR variation (~12 percentage points), whereas pass rates can differ substantially. A Venn analysis highlights a "core" of design constraints systematically violated by all major models, typically involving deeply project-specific or contextually conditioned rules absent from general training data.
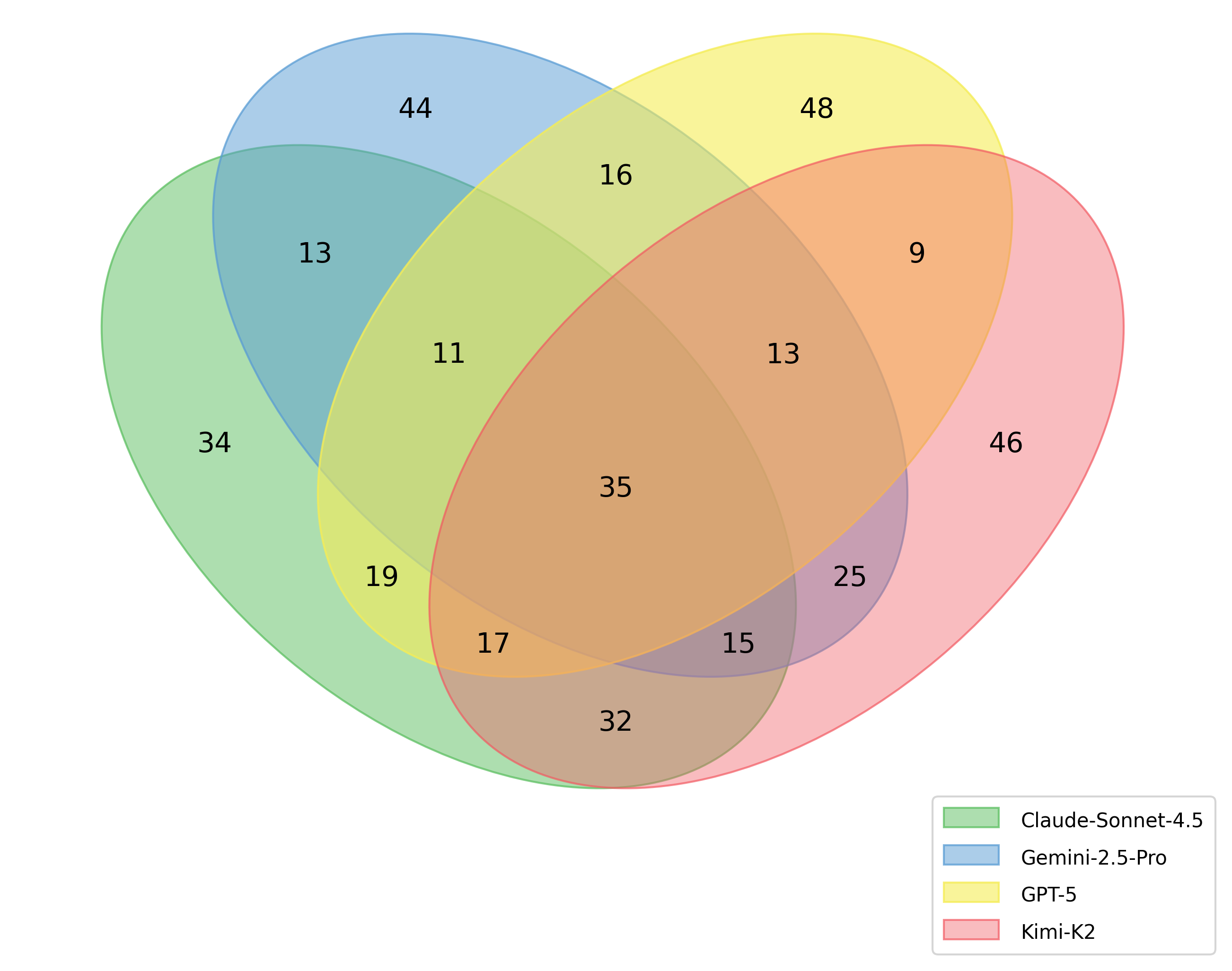
Figure 3: Intersection of violated design constraints across major LLMs; core set missed by all.
Case studies illustrate that even with explicit constraints (e.g., avoid broad OSError in favor of BlockingIOError in Django lock logic), agent-generated patches frequently fail to comply, reflecting insufficient context integration and inability to internalize nuanced repository conventions.
RQ4: Impact of Design Constraint Guidance and Iterative Refinement
Providing explicit, issue-specific design constraint guidance for patch refinement consistently reduces violation rates for all agents (DVR drop up to 6.35 pp).
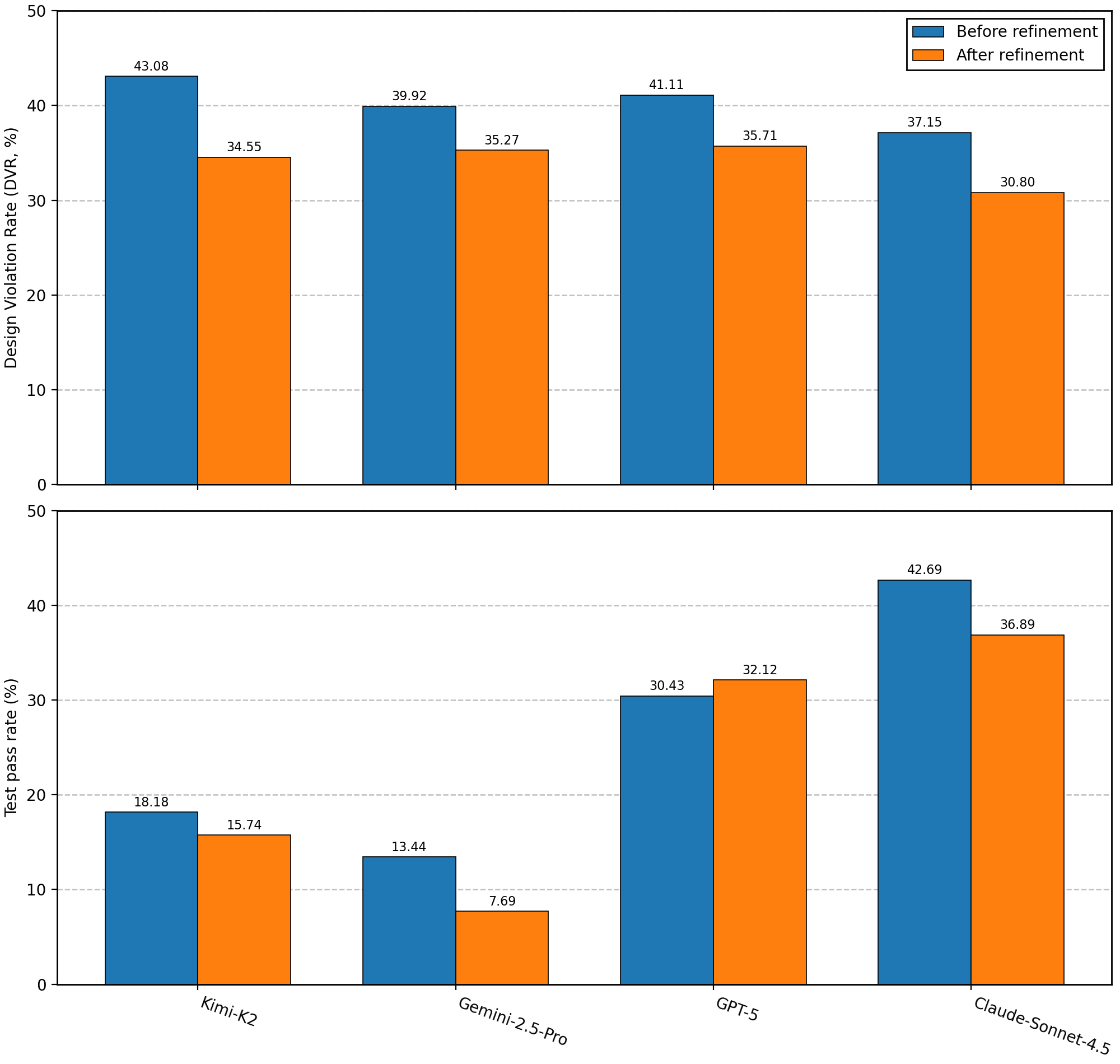
Figure 4: Comparison of DVR for agent-generated patches before and after constraint-guided refinement.
However, even after guidance, residual design violation rates remain above 30%. Qualitative failure analysis indicates partial, inconsistent integration of guidance (e.g., patch reuses preferred idioms only in some code paths), suggesting limitations in model reasoning over conditional and prioritized constraint sets.
Implications and Theoretical Significance
This work demonstrates, with strong empirical and statistical evidence, that:
- Test-based metrics overestimate agent patch quality in realistic SE contexts.
- Design constraint satisfaction is a largely independent, unsolved problem for LLM-based agents, requiring new mechanisms beyond functional testing.
- Current models, even with guidance, struggle with full operationalization and prioritization of complex, context-dependent design requirements, reflecting a fundamental limitation in practical repository- and organization-aligned agent deployment.
From a benchmarking perspective, SWE-Shield offers a systematic, automatable, and scalable methodology for surfacing latent design constraints, setting a new standard for design-aware evaluation and fine-grained diagnosis of alignment failures in code LLMs and agents.
Future Directions
- Integrating formal verification for classes of design constraints amenable to static or symbolic methods, complementing LLM-based semantic judgments.
- Structured, reasoning-augmented architectures capable of multi-step design rationale integration and trade-off handling.
- Repository- and organization-adaptive agent finetuning/grounding to encode project-specific conventions not captured in general corpora.
- Evaluation extensions encompassing additional non-functional dimensions (security, documentation alignment, performance), leveraging the constraint mining paradigm.
Conclusion
The analysis in "Does Pass Rate Tell the Whole Story? Evaluating Design Constraint Compliance in LLM-based Issue Resolution" (2604.05955) substantiates that reliance on test pass rates alone is insufficient and frequently misleading for issue resolution evaluation in LLM-based agents. SWE-Shield empirically reveals orthogonal failure modes associated with design constraint non-compliance and motivates the adoption of design-aware benchmarks, toolchains, and agent architectures as prerequisites for the credible advancement of agentic software engineering systems.

