- The paper presents a detailed taxonomy of submitters and architectural paradigms in repository-level automated program repair systems using LLMs and agent-based methods.
- It demonstrates key performance trends, with industrial entrants and proprietary models driving a marked improvement in repair precision.
- It highlights evolving modular repair pipelines and open-source contributions that enhance reproducibility and accelerate the commercialization of repair tools.
Dissecting the SWE-Bench Leaderboards: An Architectural and Organizational Analysis of LLM- and Agent-Based Program Repair
Introduction and Scope
This paper presents a detailed empirical analysis of the SWE-Bench Lite and SWE-Bench Verified leaderboards, which benchmark the current landscape of repository-level automated program repair (APR) systems utilizing LLMs and agentic architectures. By systematically investigating 178 leaderboard entries representing 80 unique approaches, the authors profile submitter types, product accessibility, LLM/model deployment patterns, and the architectural paradigms driving state-of-the-art results. The analysis leverages artifact cross-correlation and pipeline decomposition to uncover which innovations contribute most significantly to repair efficacy on real-world Python projects.
Dataset Growth, Community Engagement, and Submission Patterns
The longitudinal evolution of submissions is captured by tracking the cumulative number and timing of entries on both leaderboards.
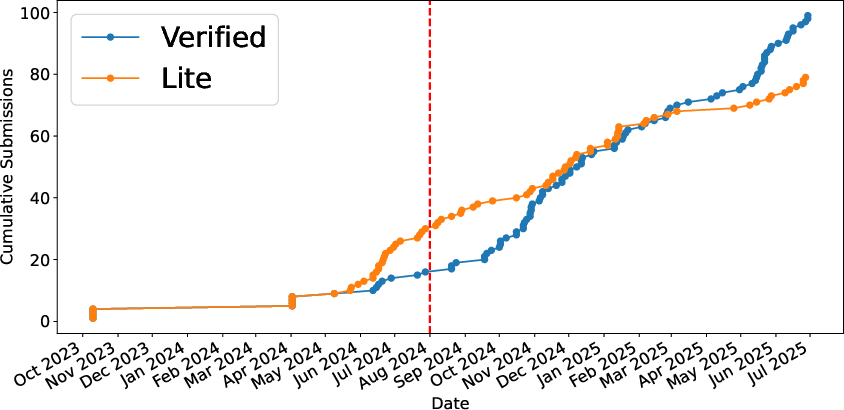
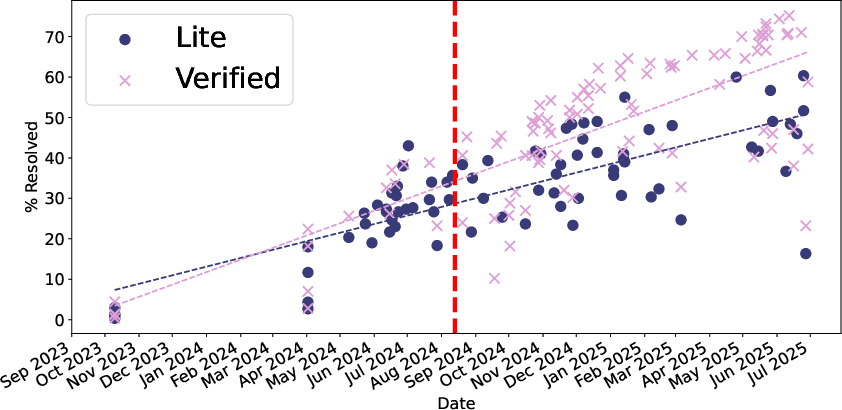
Figure 1: SWE-Bench leaderboard entry trajectory, with a marked inflection after the release of SWE-Bench Verified by OpenAI.
The data reveals several phases: initial academic and benchmark maintainer participation, rapid industry and startup engagement following the launch of SWE-Bench Verified, and a transition toward predominately industrial submissions. While SWE-Bench Lite historically featured a balanced representation of academic and small-company submitters, the Verified leaderboard rapidly became dominated by industry actors, notably large companies and venture-funded startups. Individual submitters and open-source collectives initially contributed, but their relative presence declined as the field matured.
Submitter Taxonomy and Commercialization Trajectory
A key contribution is the fine-grained taxonomy of submitter organizations. Categories include single-institution academia, collaborative academia, large/medium/small private and public companies, academic–industry collaborations, spin-offs, open-source communities, and independent individuals. The analysis demonstrates that:
- Small technology companies exhibit disproportionately high activity and often reach state-of-the-art leaderboard positions.
- Academia maintains a competitive presence, particularly in tool creation and open-source scaffolds.
- Large public companies entered aggressively after SWE-Bench Verified’s publicization, quickly adopting and extending high-performing agentic architectures.
- The rapid translation from academic prototypes (e.g., AutoCodeRover, Agentless, SWE-Agent) to commercial productization is evidenced by the rate at which academic tools become the basis for commercial offerings or spinoffs.
Product availability analysis reveals that both commercial IDE plugins and cloud platforms, as well as open non-commercial research artifacts, are regularly evaluated on the benchmark. Whereas commercial closed-source systems tend to edge out open-source competitors on average performance, recent open-source agents achieve parity or better in several instances.
LLM Adoption Patterns and Model Combinatorics
The empirical data indicate a strong performance correlation with adoption of recently released proprietary LLMs, most notably Anthropic’s Claude 3.5/4 models, followed by OpenAI GPT-4o/o1 and, to a lesser extent, Google Gemini series. Open-weight models such as Qwen2.5, Llama 3, and DeepSeek are employed both as generators and as fine-tuned “judges” or selectors. However, approaches relying strictly on open LLMs tend to attain lower precision compared to those leveraging closed, frontier models or hybrid configurations.
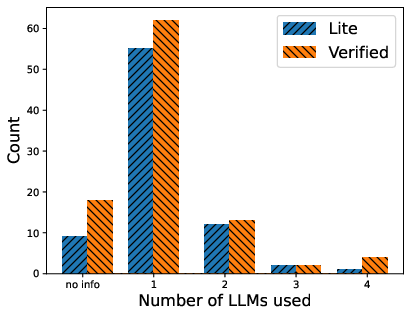
Figure 2: Empirical distribution of LLM model families used across all leaderboard entries, indicating heavy dominance by proprietary models (Anthropic/OpenAI) and a minor but persistent open-model participation.
A notable engineering trend is architectural diversity in model usage. Top-performing solutions frequently orchestrate multiple LLMs, allocating orchestration to a high-end proprietary LLM and offloading generation, filtering, or review to secondary models. Example strategies include model ensembles, parallel candidate generation with hybrid inference, and fine-tuned small LLMs performing patch judgment, often referred to as “LLM-as-a-judge.”
Architectural Paradigms: Workflow Authoring, Autonomy, and Agent Multiplicity
The authors articulate a taxonomy along three axes: (a) explicit workflow authoring (human-authored vs. emergent), (b) control flow autonomy (fixed, scaffolded, or unrestricted agent-driven), and (c) number of autonomous agents (none, single, multi-agent). Salient findings include:
- All architectural categories except pure fixed, non-agent approaches have achieved strong performance, but the highest precision is observed among scaffolded, multi-agent systems or scaffolded single-agent systems with local autonomy.
- Recent “plannerless” or fully agentic (emergent workflow) systems empowered by state-of-the-art LLMs have started to match more scaffolded solutions, suggesting that LLM capabilities may obviate the need for elaborate human-engineered workflows.
- No strictly superior architectural paradigm emerges; both monolithic and modular agent ecosystems are competitive, contingent on model power, pipeline flexibility, and engineering robustness.
- Closed-source and hybrid approaches dominate the high-precision strata, but open-source systems are rapidly converging, especially when leveraging composite model strategies and public fine-tuning data.
SWE-Bench Lite Versus SWE-Bench Verified
Comparison of performance and participation reveals that the transition from SWE-Bench Lite to SWE-Bench Verified marked a decisive shift in both score ceiling and industrial participation.
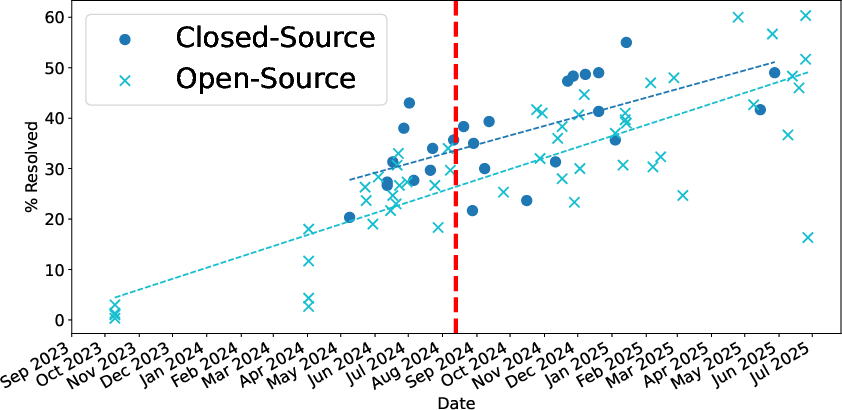
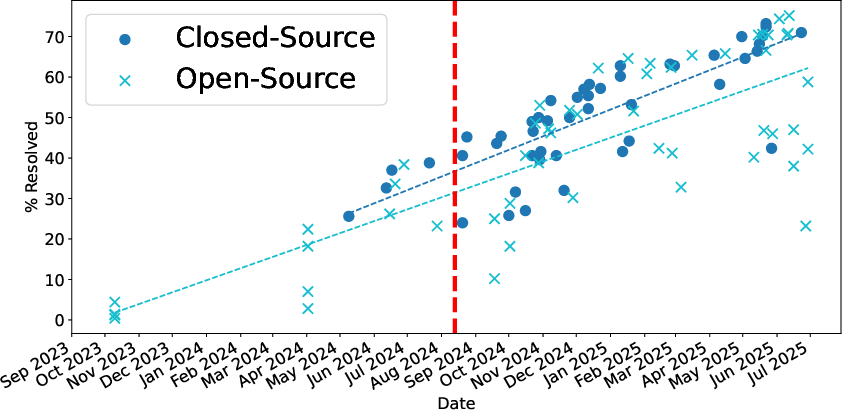
Figure 3: Distribution and evolution of submission precision on SWE-Bench Lite, highlighting the rise of agent-powered approaches and the competitive closing of open-source agents.
Recent submissions on SWE-Bench Verified reach up to 75% precision, a 20+ percentage point increase relative to the prior year and a substantial increase over the median Lite scores. This leap is tightly coupled with the proliferation of Claude 4 variants and ensemble/hybrid agentic frameworks.
The analysis also emphasizes the benchmark tailoring of Verified: rigorous filtering of highly ambiguous or unsolvable issues, enhanced test robustness, and explicit incentive for scalable agentic workflows. This has attracted greater industry investment and made Verified “the” canonical comparison point for model and agent claims.
End-to-End Repair Pipelines and Modularization Trends
A detailed cross-sectional survey of pipeline implementations (preprocessing, issue reproduction, localization, task decomposition, patch generation, patch validation, and ranking) highlights the following converging trends:
- Increasing adoption of codebase-wide knowledge graph representations to augment LLM context and inform agent action.
- Sophisticated hybrid static/dynamic localization, often leveraging BM25, function/entity graphs, or neural search; some submissions employ explicit simulation and planning agents drawing on knowledge graph traversals.
- Diverse candidate patch sampling with parallelization across multiple LLMs, temperature scaling, and iterative feedback amplification; selection frequently combines automatic majority voting, syntactic equivalence clustering, and LLM-based ranking.
- Integrated patch validation with dataset-specific dynamic tests, fine-tuned patch quality assessors, and post-processing using static analyzers and custom linters.
- Widespread use of “patch selection agents” or “reward models,” trained or fine-tuned on trajectory datasets, to select among plausible candidates generated by diversified sampling or multiple LLMs.
Empirical Observations on Open Sourcing and Productization
Notably, open-sourcing of both agent frameworks (e.g., Moatless, OpenHands, Agentless, PatchPilot) and fine-tuned open-weight LLMs has dramatically increased experimentation velocity, reproducibility, and downstream tool builder participation. Single-developer and community-driven submissions have excelled when built atop these open frameworks. Industrial actors are also observed to selectively open-source core agent infrastructure—particularly for intellectual property protection and ecosystem catalysis—while reserving the latest model weights for proprietary APIs and products.
Implications, Limitations, and Future Research
The study identifies no architectural or organizational monoculture. Precision saturates as a function of LLM advancement, with frontier proprietary models overwhelmingly responsible for the current best results, but the field remains dynamic with new strategies exploiting hybridization and modular pipelines. The benchmark appears to be nearing a saturation point; 80%+ precision on Verified is feasible in the near future absent substantial increases in the difficulty floor or improvements in the test oracle.
The authors also surface the following critical open issues:
- Overfitting remains a significant threat to reported precision due to insufficient validation oracles (limited test sets, semantic misalignment); additional techniques such as behavioral clustering and LLM-based critical review are advocated but not universally implemented.
- Data contamination and repository familiarity pose external validity risks; leaders on SWE-Bench may have trained on some issues present in the benchmark.
- While openness promotes rapid research, the commercial value differential of closed versus open-source models limits the speed of convergence between academic and industrial state-of-the-art.
Conclusion
This comprehensive analysis uncovers the complex interplay between community dynamics, LLM/model selection, architectural choice, engineering scaffolds, and repair pipeline modularity in driving advances on SWE-Bench leaderboards. While performance skews toward closed, agent-powered hybridity, the vibrant diversity of solutions, powered by standardized benchmarks and open-source scaffolds, has produced rapid progress and practical productization. The next challenges are robust generalization, trustworthy correctness validation, continuous benchmark evolution, and rigorous assessments of the trade-offs between autonomy, modularity, and model selection in automated software repair.

