- The paper introduces PRIME-MCTs, a framework that integrates reflective memory modules with MCTS to boost reasoning efficiency and accuracy.
- It employs a dual-stage Process Reward Model with Heuristics and Fallacies Memory to prune errors and replicate robust reasoning paths.
- Empirical results on scientific fact verification and mathematical benchmarks show a significant reduction in search trajectories while maintaining high performance.
Motivation and Context
The increasing complexity of reasoning tasks has exposed the limitations of conventional LLM reasoning paradigms, particularly those relying on parametric fast thinking or linear Chain-of-Thought prompting. Existing MCTS-based reasoning systems suffer from computational inefficiency due to isolated rollouts and redundant exploration. PRIME-MCTs proposes a paradigm shift by integrating metacognitive processes—specifically, human-inspired mechanisms for parallelization, reflection, and memory augmentation—into the MCTS search, with the explicit goal of promoting search efficiency and robust logical accuracy.
PRIME-MCTs Framework Architecture
PRIME-MCTs extends the standard MCTS framework by incorporating global information sharing and reflective memory. It maintains two explicit and dynamically managed memories: Heuristics Memory, which archives verified reasoning sub-trajectories, and Fallacies Memory, which tracks error-prone subspaces. Both are mediated by a novel Process Reward Model (PRM) and a Memory Manager responsible for real-time curation of high-fidelity patterns.
After every rollout in the search tree, PRIME-MCTs assesses intermediate nodes using a few-shot trained PRM, classifies them into heuristics or fallacies based on value thresholds, and then shares these abstractions globally across all concurrent rollouts. This allows efficient pruning of erroneous paths and targeted replication of reliable reasoning maneuvers. Critically, the model supports parallel reasoning via state sharing, thereby overcoming the myopic and serial limitations of standard MCTS.
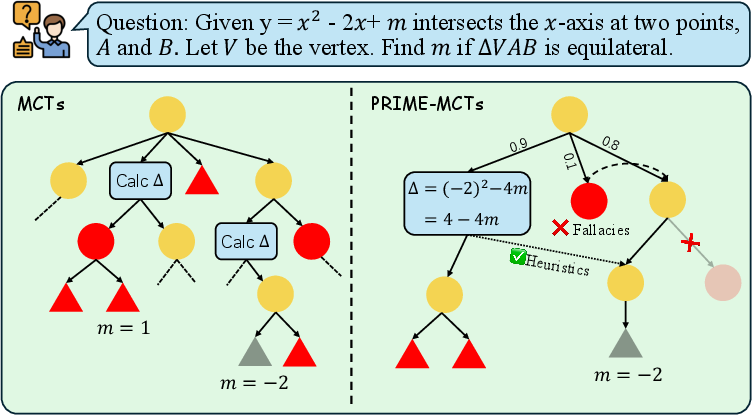
Figure 1: PRIME-MCTs augments MCTS by introducing global memory to prune errors and enable memory-guided expansion, as opposed to conventional isolated rollouts.
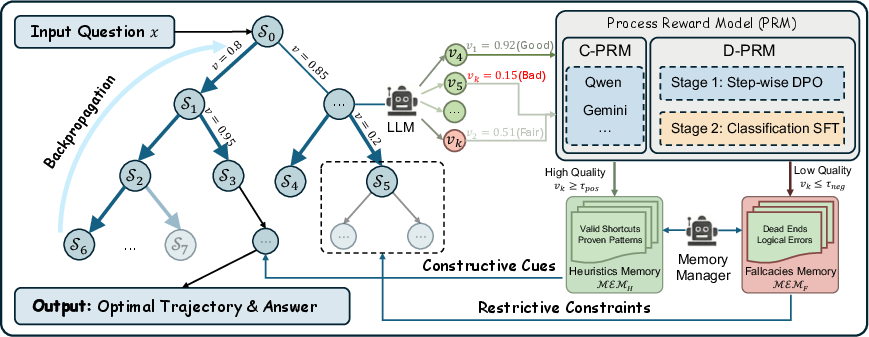
Figure 2: Schematic of PRIME-MCTs, showing the interaction between MCTS, PRM evaluation, and the two reflective memory modules for global guidance.
Process Reward Model: Data-Efficient Dual-Stage Training
The PRM is central for fine-grained reward estimation at every search node. Distinct from regression-based PRMs, PRIME-MCTs employs a dual-stage training strategy:
- Stage 1: Step-level Direct Preference Optimization (SDPO), aligning the PRM to prefer high-quality steps over less desirable ones.
- Stage 2: Discrete classification of reasoning step quality into categorical labels (Perfect–Bad), optimized via cross-entropy rather than regression, which improves sample efficiency and value calibration in few-shot scenarios.
This training regime allows PRIME-MCTs to perform robust process supervision and memory management even with limited annotated data, crucial for scalability across domains.
Empirical Analysis
Main Results: Reasoning Performance and Search Efficiency
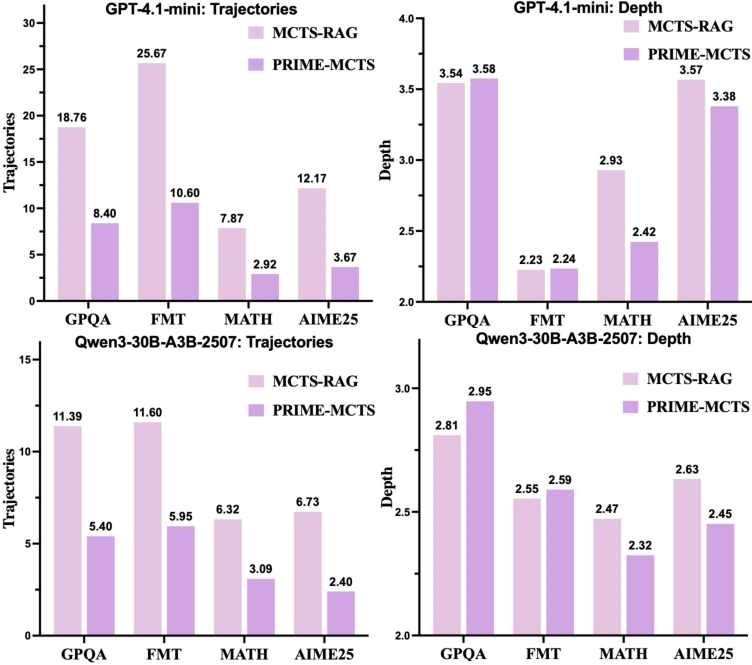
Strong empirical results are presented on benchmarks spanning scientific fact verification (GPQA-Diamond, FMT) and advanced mathematical reasoning (MATH500, AIME25), with consistent improvements over Zero-Shot CoT, ReAct, Search-o1, ReST-MCTS*, and MCTS-RAG.
Notable highlights include:
Memory Mechanisms: Ablation and Impact
Ablation studies demonstrate that both Heuristics and Fallacies Memory modules are indispensable for maintaining high accuracy with minimal search breadth. The removal of either memory, especially Heuristics Memory, leads to marked degradation in both performance and search compactness. The synergy between positive reinforcement and negative constraints is essential for optimal policy learning under MCTS.
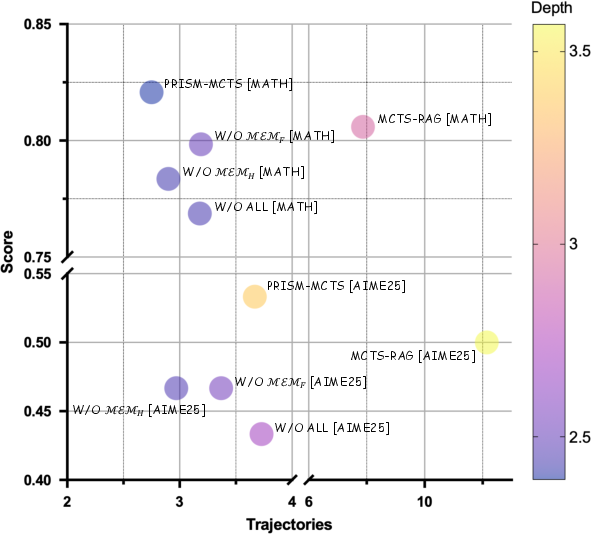
Figure 4: Ablation on MATH500/AIME25 reveals prime importance of the dual-memory mechanism, as disabling either component reduces both search efficiency and accuracy.
Process Reward Model: Local vs. Oracle Capability
Comparisons between a locally fine-tuned PRM (Qwen3-4B) and an Oracle PRM (Gemini-2.5-Pro) show that the dual-stage, data-efficient PRM nearly matches the oracle's performance on EM and F1 across tasks while maintaining comparable reasoning depth. Minor increases in search breadth with the local model indicate a slight loss in discriminative sharpness, but the performance gap is minimal. This finding supports flexible deployment, including data-private and compute-conservative environments.
Implications and Future Directions
The PRIME-MCTs framework formalizes a systematic approach to integrating structured metacognition—especially memory-based reflection and parallel reasoning—into MCTS-guided LLM reasoning. Its contributions lie in both efficient test-time compute and robust process supervision, applicable to agentic reasoning, scientific QA, and mathematical theorem proving.
Practical implications include:
- Test-time inference scalability: By eliminating redundant exploration and focusing search, PRIME-MCTs enables practical deployment of slow-thinking strategies in latency/constrained environments.
- Self-improving systems: The structured recording of heuristics and fallacies facilitates life-long learning, potentially enabling autonomous correction and improvement over time.
- Broader applicability: The dual-memory architecture and data-efficient PRMs can be extended to multi-modal domains or agentic workflows.
Theoretical implications involve the possibility of integrating richer forms of episodic, semantic, or hierarchical memory, as well as the combination with retrieval-augmented or execution-driven paradigms. Limitations noted include the current lack of multi-modal support and restricted PRM training scale; these suggest future work in process supervision for vision-language and planning tasks.
Conclusion
PRIME-MCTs demonstrates that reflection-inspired architectures, when coupled with MCTS, can substantially improve the efficiency and reliability of LLM-based reasoning under computational constraints. The proposed dual-memory mechanism and data-efficient PRM deliver strong results across both fact verification and mathematical reasoning, halving search requirements while sustaining or improving accuracy. PRIME-MCTs thus represents a significant advance toward scalable, metacognitively guided machine reasoning systems (2604.05424).