DeepSearch: Overcome the Bottleneck of Reinforcement Learning with Verifiable Rewards via Monte Carlo Tree Search
Abstract: Although RLVR has become an essential component for developing advanced reasoning skills in LLMs, contemporary studies have documented training plateaus that emerge following thousands of optimization steps, demonstrating notable decreases in performance gains despite increased computational investment. This limitation stems from the sparse exploration patterns inherent in current RLVR practices, where models rely on limited rollouts that often miss critical reasoning paths and fail to provide systematic coverage of the solution space. We present DeepSearch, a framework that integrates Monte Carlo Tree Search directly into RLVR training. In contrast to existing methods that rely on tree search only at inference, DeepSearch embeds structured search into the training loop, enabling systematic exploration and fine-grained credit assignment across reasoning steps. Through training-time exploration, DeepSearch addresses the fundamental bottleneck of insufficient exploration, which leads to diminishing performance improvements over prolonged training steps. Our contributions include: (1) a global frontier selection strategy that prioritizes promising nodes across the search tree, (2) selection with entropy-based guidance that identifies confident paths for supervision, and (3) adaptive replay buffer training with solution caching for efficiency. Experiments on mathematical reasoning benchmarks show that DeepSearch achieves 62.95% average accuracy and establishes a new state-of-the-art for 1.5B reasoning models - using 5.7x fewer GPU hours than extended training approaches. These results highlight the importance of strategic exploration over brute-force scaling and demonstrate the promise of algorithmic innovation for advancing RLVR methodologies. DeepSearch establishes a new direction for scaling reasoning capabilities through systematic search rather than prolonged computation.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces DeepSearch, a new way to train LLMs to solve hard problems (like math) by using a smart search strategy during training, not just at the moment of answering. The key idea is to combine reinforcement learning with verifiable rewards (RLVR) and Monte Carlo Tree Search (MCTS) so the model can explore many possible solution paths and learn which steps are helpful. This approach aims to fix a common problem: after many training steps, models stop getting better because they don’t explore enough different ways to solve problems.
What questions does the paper try to answer?
- How can we help LLMs explore more promising solution paths during training instead of just guessing a few times?
- Can adding tree search to training improve reasoning skills more than simply training longer?
- How can we assign credit to specific steps in a solution, not just the final answer, so the model learns the process better?
How does DeepSearch work? (Explained simply)
Think of solving a tough math problem like finding your way through a maze:
- Each step in your reasoning is like choosing a path at a branching point.
- A “verifier” checks if you’ve reached the correct exit (answer).
- The model needs to learn not only which exit is correct, but which turns along the way are helpful.
DeepSearch uses three main ideas:
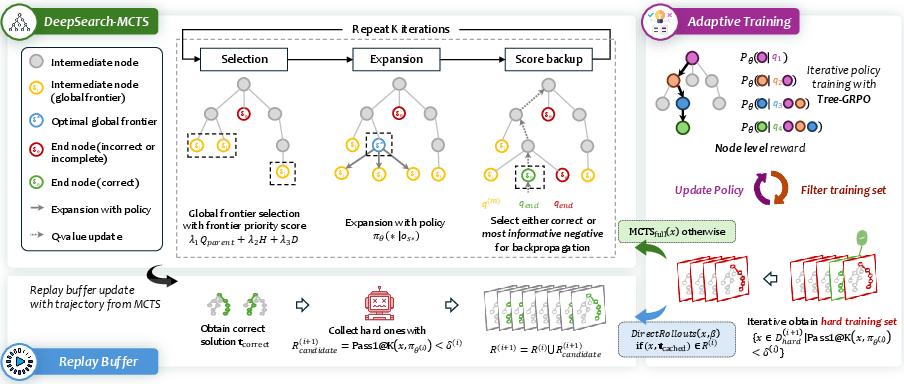
- Global frontier selection Instead of always walking from the maze’s entrance to one leaf using a fixed rule, DeepSearch looks at all the current frontier paths across the map and picks the most promising one to explore next. This avoids getting stuck in one part of the maze and makes exploration broader and smarter.
- Entropy-based guidance “Entropy” here measures how confident the model is when it chooses the next step: low entropy means “very sure,” high entropy means “unsure.” If the model doesn’t find any correct solution in one round, DeepSearch picks the most confidently wrong path and uses it as a lesson. In plain terms: if the model is sure but still wrong, that’s a great teaching moment.
- Adaptive replay buffer with solution caching When the model solves a problem correctly, DeepSearch saves that solution. Later, if the same problem appears, it reuses the correct path instead of redoing heavy search. That saves time and ensures the model remembers good solutions while focusing effort on truly hard, unsolved problems.
What does “MCTS” do here?
MCTS builds a tree of possible reasoning steps:
- Root = the question.
- Branches = the model’s next-step ideas.
- Leaves = complete attempts that the verifier checks. DeepSearch updates “q-values” (scores) along the path: good endings give positive scores to the steps that led there, and bad endings give negative scores. There’s also a “decay” so steps closer to the final answer get more credit. These scores help the model learn which moves are useful.
Local vs global selection
- Local selection: When comparing siblings under the same parent (like choosing among several similar next steps), DeepSearch uses a classic rule called UCT to balance exploring new options and sticking with promising ones.
- Global frontier selection: Across the entire tree, DeepSearch computes a priority score for each frontier node that considers parent quality, model confidence (entropy), and depth (how far into the solution it is). This lets the algorithm allocate effort to the best places in the whole tree, not just one branch.
Tree-GRPO training objective (everyday explanation)
Training doesn’t just reward correct final answers—it also gives credit to helpful intermediate steps. DeepSearch:
- Softly limits q-values so they don’t explode to huge numbers.
- Uses a policy optimization objective that compares the current model to a slightly older version and nudges it toward steps that earned higher q-values.
- Normalizes rewards across a problem’s tree so longer answers don’t unfairly dominate, and advantages reflect true progress.
Progressive filtering
DeepSearch focuses search on the hardest problems:
- Start with the full dataset, then filter to keep only the problems that the model still struggles with.
- As training progresses, the “hard set” gets smaller and more challenging.
- Cached correct solutions are included automatically, saving compute and preventing forgetting.
What did the researchers find?
- DeepSearch set a new state-of-the-art for 1.5B-parameter reasoning models on math benchmarks, with an average accuracy of 62.95%.
- It beat the previous best by 1.25 percentage points, especially improving on AIME 2024 and AMC 2023.
- Most importantly, it did this efficiently: DeepSearch used about 5.7 times fewer GPU hours than approaches that simply kept training longer.
- Extended training without search hit a “plateau” where more hours gave tiny improvements. DeepSearch avoided this by improving exploration quality, not just training more.
Why is this important?
- Better exploration during training helps the model learn how to reason, not just memorize answers.
- Teaching the model to search while it learns makes its problem-solving more robust and efficient.
- This approach suggests a shift in strategy: instead of “train deeper and longer,” we should “train smarter and broader,” exploring more solution paths and assigning credit to each step.
What’s the potential impact?
- Stronger math and reasoning skills in smaller models can make powerful tools more accessible and less expensive to train.
- Using fewer GPU hours is better for cost and the environment.
- The idea of integrating search into training could help beyond math—any domain where you can verify answers step by step (like logic puzzles, programming tasks, or structured planning) could benefit.
- Overall, DeepSearch points to a future where algorithmic innovations—like smarter exploration and better step-by-step teaching—matter more than simply throwing more compute at the problem.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to be directly actionable for future research.
- Lack of theoretical guarantees: no convergence, regret, or sample-complexity analysis for the proposed hybrid MCTS (global frontier + local UCT) integrated with RLVR training.
- Unclear optimality of the constrained q-value backup rule: no formal analysis of bias introduced by enforcing nonnegative intermediate q-values on correct paths or of its effect on credit assignment and learning stability.
- Sensitivity to hyperparameters is unstudied: no systematic tuning or robustness analysis for
λ1,λ2,λ3in the frontier score, the sign of the uncertainty bonus, rollout budgetB, direct rollout ratioβ, candidate branching factorn, tree depthd_𝒯, UCTλ, and decayγ(i, l). - Entropy-based negative selection is not validated against alternatives: no comparison to heuristics such as highest-log-prob incorrect path, margin-based confidence, trajectory-length–normalized log-probability, or diversity-aware selection; impact on error entrenchment is unknown.
- Frontier scoring function design is largely empirical: no ablation on the functional forms for the quality term (other than
tanh), uncertainty term (other than entropy), or depth term (beyond log/linear/sqrt) across tasks and model scales. - Computational scalability of global frontier selection is not characterized: no complexity or memory bounds for maintaining and scoring all frontier nodes; no discussion of batching, pruning, or approximate selection for large trees.
- Off-policy training with cached solutions lacks correction analysis: replay buffer uses trajectories from past policies, yet there is no study of importance sampling bias, stale-policy effects, or when
θ_oldmismatches stored trajectories. - Replay buffer management is unspecified: no capacity limits, eviction strategies, prioritization criteria (e.g., TD-error or difficulty), or analyses of buffer-induced overfitting and distribution shift.
- Catastrophic forgetting prevention is asserted but not measured: no experiments quantifying retention on previously solved problems over long training horizons or under varying buffer policies.
- Verifier reliability is assumed: no stress-tests of reward noise, verifier errors, or adversarial exploitation; robustness to imperfect verifiable rewards remains unknown.
- Terminal-only reward design limits process supervision: no experiments with step-level verifiers (e.g., equation-checking, unit consistency) to assess whether intermediate verification improves credit assignment and learning dynamics.
- Removal of KL regularization is not safety- or stability-tested: no analysis of collapse risks, divergence behavior, or interactions with length penalties and advantage scaling under Tree-GRPO.
- Length penalty trade-offs are unquantified: the overlong buffer penalty is introduced without measuring its effect on solution completeness, reasoning quality, or the tendency to truncate correct but lengthy reasoning.
- Exploration coverage is not directly measured: claims of broader coverage lack quantitative diversity metrics (e.g., unique trajectories, solution-path entropy, subtree visitation distributions) and do not connect coverage to performance gains.
- Generalization beyond math is untested: no experiments on other verifiable domains (e.g., program synthesis, formal proofs) or semi-verifiable settings (rubrics), despite positioning as a general RLVR methodology.
- No comparison with alternative training-time search algorithms: beam search, best-first search, A* variants, or learned search policies are not evaluated against MCTS for training-time exploration.
- Limited model-scale and base-model diversity: results are confined to a single 1.5B base (Nemotron-Research-Reasoning-Qwen-1.5B v2); transferability to other architectures and scales (smaller/larger) is undocumented.
- Inference-time compute scaling not contrasted: the paper does not benchmark DeepSearch-trained models under stronger test-time search/sampling budgets (e.g., n>32, tree search at inference) versus baselines to isolate training-time search benefits.
- Statistical rigor of benchmark results is limited: no multiple-seed evaluations, confidence intervals, or significance tests for the reported gains; sensitivity to evaluation randomness and sample size (n=32) is unknown.
- Dataset filtering threshold (
δ≈25%) is arbitrary: no sensitivity analysis showing how progressive filtering thresholds affect training efficiency, difficulty distribution, and final performance. - Hard-sample selection could bias learning: focusing MCTS on “hard” subsets may distort the data distribution; effects on generalization and calibration are not measured.
- Handling of degenerate samples (garbled text/repetitions) is ad hoc: detection criteria, false positive/negative rates, and impact on stability and data quality are not described or evaluated.
- Efficiency claims need broader accounting: GPU-hour comparisons do not include end-to-end costs (e.g., data preprocessing, tree construction overheads, verifier latency); scalability across different hardware and software stacks is not assessed.
- Frontier selection’s uncertainty bonus sign is underexplored: although the sign can steer toward high-confidence or high-uncertainty regions, there is no systematic study of its regimes, transitions, or adaptive scheduling.
- Decay function
γ(i, l)is arbitrary: no justification or alternatives (e.g., exponential, inverse-depth, learned decay) tested for temporal credit weighting along trajectories. - Advantage normalization variants need deeper study: mean-only normalization improves calibration, but interactions with q-clipping, removal of KL, and token-level PPO clipping require more extensive diagnostics (e.g., gradient norms, variance).
- Reward scale and normalization across trees are under-specified: how variability in terminal rewards across problems affects advantage computation and training stability is not analyzed.
- Memory and latency trade-offs of tree construction are not profiled across sequence lengths: with a max sequence length of 4096, scaling behavior for longer problems or multi-hop tasks is unclear.
- Failure-case analysis is missing: no qualitative studies of where DeepSearch fails (e.g., long-horizon proofs, combinatorial traps, misleading confident negatives), limiting targeted method improvements.
- Reproducibility gaps: key implementation details (e.g., batching of frontier scoring, verifier interfaces, rollout stopping criteria, seed management) are deferred to the appendix or not provided; code availability is referenced but not present here.
Glossary
- Advantage function: A quantity in policy optimization representing how much better an action or token is than a baseline; used to weight updates. "The advantage function for node in trajectory is computed using sequence-level normalization~\citep{chu2025gpg}:"
- Catastrophic forgetting: The tendency of a model to lose previously learned knowledge when trained further on new data. "To prevent catastrophic forgetting and efficiently leverage previously discovered solutions, we maintain a replay buffer that stores correct reasoning trajectories from earlier training phases."
- Clip-Higher strategy: A clipping scheme for importance ratios that allows larger-than-one ratios within a controlled range, improving stability. "The parameters $\epsilon_{\text {high}$ and $\epsilon_{\text {low}$ follow the Clip-Higher strategy of DAPO~\citep{yu2025dapo}, while we also remove the KL regularization term $\mathbb{D}_{\mathrm{KL}$ to naturally diverge~\citep{luo2025deepcoder,he2025skywork}."
- Credit assignment: The process of attributing outcomes (rewards) to specific intermediate decisions or steps during learning. "providing fine-grained credit assignment to intermediate reasoning steps through tree-structured backpropagation,"
- DAPO: A reinforcement learning objective (Direct Advantage Policy Optimization) used in reasoning model training with specific clipping strategies. "The parameters $\epsilon_{\text {high}$ and $\epsilon_{\text {low}$ follow the Clip-Higher strategy of DAPO~\citep{yu2025dapo}, while we also remove the KL regularization term $\mathbb{D}_{\mathrm{KL}$ to naturally diverge~\citep{luo2025deepcoder,he2025skywork}."
- Decontamination: The removal of overlap between training data and evaluation benchmarks to avoid leakage and inflated scores. "DeepMath-103K is a large-scale mathematical dataset designed with high difficulty, rigorous decontamination against numerous benchmarks."
- Depth bonus: A heuristic that increases priority for expanding deeper nodes in a search tree to encourage exploration at greater depths. "The depth bonus term encourages deeper exploration by providing additional priority to nodes at greater depths, where we empirically find $D(d(s)) = \sqrt{d(s)/d_\mathcal{T}$ to be most effective among other variants including and ."
- Entropy-based guidance: A selection strategy that uses model entropy to prioritize trajectories or nodes with certain confidence characteristics. "selection with entropy-based guidance that identifies confident paths for supervision,"
- Exploration-exploitation tradeoff: The balance between trying new actions (exploration) and leveraging known high-value actions (exploitation). "and balances exploitation and exploration."
- Frontier node: A leaf node eligible for further expansion in the search tree. "For each frontier node , we compute a frontier priority score:"
- Frontier priority score: A composite heuristic score used to rank frontier nodes for expansion based on quality, uncertainty, and depth. "we compute a frontier priority score:"
- Global frontier selection: A search strategy that compares all frontier nodes across the tree to select the next expansion point, avoiding myopic traversals. "This is where our novel global frontier selection mechanism operates."
- Heuristic Score Backup: A backup procedure that updates node values along a selected trajectory using heuristic rules and decay. "Heuristic Score Backup"
- Importance ratio: The ratio of current policy probability to the old policy probability for the same token/action, used in off-policy updates. "where $\rho_{j,k}(\theta)=\frac{\pi_\theta\left(a_{j,k} \mid o_j, a_{j,<k}\right)}{\pi_{\theta_{\text {old }\left(a_{j,k} \mid o_j, a_{j, <k}\right)}$ is the importance ratio."
- KL regularization: A penalty term based on Kullback–Leibler divergence to constrain the policy from drifting too far from a reference. "while we also remove the KL regularization term $\mathbb{D}_{\mathrm{KL}$ to naturally diverge~\citep{luo2025deepcoder,he2025skywork}."
- Mean-only normalization: Advantage normalization using only the mean (not variance), intended to improve stability and calibration. "We adopt mean-only normalization (Eq.~\ref{equ:adv_norm})."
- Monte Carlo Tree Search (MCTS): A search algorithm that builds and explores a tree via stochastic rollouts and value backups to guide decision-making. "We present DeepSearch, a framework that integrates Monte Carlo Tree Search (MCTS) directly into RLVR training."
- Overlong buffer penalty: A training penalty applied when model outputs exceed a specified maximum length to discourage overly long responses. "An overlong buffer penalty is imposed to penalize responses that exceed a predefined maximum value of 4096."
- Pass@1 accuracy: The probability that the top (first) sampled solution is correct; a common evaluation metric in generative reasoning. "We report Pass@1 accuracy with samples."
- Pass1@K: The success rate of obtaining at least one correct solution among K sampled attempts for a given problem. "where represents the success rate when sampling solutions for problem using policy "
- Policy model: The parameterized model that defines a probability distribution over next-step actions or tokens given a state. "Given a problem and a policy model , we adopt a modified MCTS framework to build a search tree for incremental step-by-step solution exploration."
- Progressive filtering: An iterative training procedure that repeatedly filters out solved or easy problems to focus computation on hard ones. "Iterative Training with Progressive Filtering"
- Q-value: The expected cumulative reward (value) associated with a node or action, used to guide selection and training updates. "Let denote the q-value for node after the -th rollout backpropagation."
- Q-Value Soft Clipping: A technique using smooth functions (like tanh) to bound q-values and prevent explosion while preserving gradients. "Q-Value Soft Clipping."
- Quality potential: A heuristic component that favors nodes whose parents have high average value, often via a smooth transformation. "Here, the quality potential term $\tanh(Q_{\text{parent}(s))$ encourages the selection of nodes whose parents have demonstrated high value, using the tanh transformation to smoothly handle negative Q-values and map them to the range ."
- Replay buffer: A memory of trajectories or experiences used to stabilize training and reuse solutions without re-searching. "To prevent catastrophic forgetting and efficiently leverage previously discovered solutions, we maintain a replay buffer that stores correct reasoning trajectories from earlier training phases."
- Reinforcement Learning with Verifiable Rewards (RLVR): A reinforcement learning setup where reward signals are automatically verifiable (e.g., correctness checks). "Although Reinforcement Learning with Verifiable Rewards (RLVR) has become an essential component for developing advanced reasoning skills in LLMs,"
- Root-to-leaf traversal: A search procedure that follows a path from the root to a leaf node, often using UCT at each step. "moving beyond traditional root-to-leaf UCT traversals that can be computationally wasteful and myopic."
- Sequence-level normalization: Advantage normalization performed at the sequence level (e.g., per trajectory) to stabilize updates. "computed using sequence-level normalization~\citep{chu2025gpg}:"
- Shannon entropy: A measure of uncertainty in a probability distribution; here computed from the policy’s token probabilities. "being the Monte Carlo estimation of the Shannon entropy of the policy distribution at step ."
- Temporal decay function: A function that scales backup contributions based on position along the trajectory (e.g., closer to terminal gets higher weight). "where is the temporal decay function that assigns higher weights to nodes closer to the terminal node:"
- Terminal node: A node representing a completed solution or maximum depth, ending a trajectory in the search tree. "A root-to-leaf path ending at a terminal node forms a trajectory ,"
- Test-time computation scaling: Strategies that increase compute during inference (e.g., multiple samples or search) to improve performance. "driven in part by test-time computation scaling strategies~\citep{li2023making,yao2023tree,bi2024forest,zhang2024rest,guan2025rstar} such as tree search with process-level evaluation."
- Tree-GRPO: A variant of GRPO adapted to tree-structured data, combining q-value regularization with policy optimization. "After constructing a search tree for a sample question in the dataset $\mathcal{D}_{\text{train}$, we develop our Tree-GRPO training objective."
- Tree-structured backpropagation: A backup mechanism that propagates rewards or values along tree trajectories to assign credit to intermediate steps. "providing fine-grained credit assignment to intermediate reasoning steps through tree-structured backpropagation,"
- Upper Confidence Bounds for Trees (UCT): A selection rule that balances exploitation and exploration in MCTS using visit counts and value estimates. "For this local sibling comparison, we follow the traditional MCTS protocol and employ the Upper Confidence Bounds for Trees (UCT) algorithm~\citep{kocsis2006bandit}:"
- Uncertainty bonus: A heuristic term (often using entropy) that increases priority for nodes in uncertain regions to encourage exploration. "The uncertainty bonus term provides exploration guidance by adjusting priority according to the policyâs entropy;"
- Verification function: A function that checks whether a terminal node’s solution is correct (e.g., returns 1 for correct, 0 otherwise). "We evaluate the correctness of each terminal node using a verification function "
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, leveraging DeepSearch’s integration of MCTS into RLVR, its global frontier selection, entropy-guided negative mining, replay buffer with cached solutions, and the Tree-GRPO objective. Each bullet identifies sectors and potential tools/workflows, with key assumptions noted.
- Software engineering: search-augmented code generation and repair with unit tests as verifiable rewards
- Sectors: software, DevOps, data engineering
- Tools/workflows: “Search-Augmented RLVR Trainer” for program synthesis; CI pipelines that auto-generate patches based on failing tests; step-wise code repair where intermediate reasoning steps are credited based on the Tree-GRPO objective
- Assumptions/dependencies: high-quality, comprehensive test suites; deterministic environments; guardrails to avoid gaming tests; sufficient GPU capacity for training-time MCTS
- Data analytics and SQL: verifiable query construction with deterministic checks (schema validation, row counts, constraint satisfaction)
- Sectors: software, finance, business intelligence
- Tools/workflows: analytics copilot that explores query plans during training; global frontier selection to prioritize promising query branches; entropy-based selection to correct confident but wrong queries
- Assumptions/dependencies: clear verification functions (e.g., expected outputs, integrity constraints); representative data samples; robust handling of non-deterministic data sources
- ETL/automation: pipeline generation with verifiable transformations (checksums, invariants, schema compliance)
- Sectors: software, data engineering
- Tools/workflows: pipeline builders that learn via MCTS-backed training to satisfy invariants; replay buffer caches for known-good transformations to avoid recomputation
- Assumptions/dependencies: explicit invariants and validators; stable data contracts; safe sandboxing of transformations
- Math tutoring and assessment: reasoning tutors that learn to explore diverse solution paths and provide fine-grained feedback
- Sectors: education, edtech
- Tools/workflows: “DeepSearch Math Tutor” for step-by-step reasoning supervision; progressive filtering to focus on harder problems; cached solution reuse to prevent forgetting
- Assumptions/dependencies: reliable verification of answers/steps; decontaminated datasets; safeguards against exposure to training data from test sets
- Research workflows in mathematical domains: improved sample/compute efficiency for small models (≈1.5B) achieving SOTA on math benchmarks
- Sectors: academia, AI labs
- Tools/workflows: integration into RLHF/RLVR frameworks (e.g., TRL-like toolkits) with Tree-GRPO; global frontier selection to reduce redundant root-to-leaf traversals
- Assumptions/dependencies: availability of verifiable rewards; reproducible evaluation protocols; careful hyperparameter tuning (e.g., depth bonus, entropy coefficients)
- Low-compute model development: efficiency-first training strategies for teams with limited budgets
- Sectors: startups, non-profits, public labs
- Tools/workflows: replay-buffer caching + progressive filtering to minimize GPU hours; entropy-guided mining of confident negatives to accelerate learning
- Assumptions/dependencies: tasks with verifiable rewards; access to modest GPU resources; avoidance of pathological samples (garbled or repetitive text)
- Operations research tasks with direct verification: constrained scheduling, routing, and timetabling with constraint checks
- Sectors: logistics, transportation, manufacturing
- Tools/workflows: search-augmented RLVR for generating candidate schedules and verifying constraints; frontier selection to allocate search budget across subproblems
- Assumptions/dependencies: formal constraint validators; realistic simulators; careful metric design to prevent reward hacking
- Policy and governance: compute-aware training guidelines emphasizing breadth (exploration) over depth (steps)
- Sectors: policy, research governance
- Tools/workflows: evaluation checklists prioritizing exploration quality and reproducibility; reporting standards for GPU hours vs. accuracy gains
- Assumptions/dependencies: standardized benchmarks; community adoption of transparent reporting; recognition of environmental benefits from reduced compute
- Personal productivity: spreadsheet formula synthesis with unit tests (e.g., expected outputs for given inputs)
- Sectors: daily life, SMB productivity
- Tools/workflows: assistants that train on verifiable formula correctness and intermediate reasoning; cached solutions for common tasks
- Assumptions/dependencies: well-specified verification cases; sandboxed data; guardrails against overfitting to narrow cases
Long-Term Applications
These use cases require further research, domain adaptation, scaling, or safety validation. They extend DeepSearch’s principles (systematic training-time exploration with MCTS, fine-grained credit assignment) to more complex or less-verifiable domains.
- Safety-critical healthcare decision support with constrained reasoning
- Sectors: healthcare
- Tools/workflows: clinical guideline adherence checks; multi-step reasoning with verifiable intermediate constraints (drug interactions, dosing ranges); entropy-guided identification of confidently wrong rationales for focused retraining
- Assumptions/dependencies: high-fidelity verification functions; regulatory compliance; robust interpretability and audit trails; clinical validation
- Financial modeling and strategy design via backtesting as verifiable reward
- Sectors: finance
- Tools/workflows: quantitative research assistants that explore strategy spaces under simulation; frontier selection to allocate exploration across regimes; replay buffers caching validated strategies
- Assumptions/dependencies: realistic market simulators; prevention of overfitting; compliance and risk controls; domain shift handling
- Robotics and embodied AI: task planning with physics-informed verification (sim-to-real)
- Sectors: robotics, manufacturing
- Tools/workflows: MCTS-augmented policy learning where steps are verified in simulation; transfer learning with cached solutions; depth bonuses tuned for long-horizon tasks
- Assumptions/dependencies: accurate simulators; real-world validation; safety constraints; domain adaptation for perception and actuation noise
- Energy and grid optimization: verifiable power flow and stability constraints
- Sectors: energy
- Tools/workflows: planning assistants that explore operation schedules while verifying constraint satisfaction; Tree-GRPO credit assignment for intermediate constraint checks
- Assumptions/dependencies: reliable solvers and validators; scenario coverage; resilience/safety validation; integration with legacy systems
- Legal and policy drafting with structured verifiability (compliance checklists, citation correctness)
- Sectors: legal, public policy
- Tools/workflows: drafting assistants trained with verifiable subgoals (citation validity, compliance criteria met); entropy-based selection to find confidently incorrect claims for retraining
- Assumptions/dependencies: formalized verification rules; high-quality, up-to-date legal databases; safeguards against hallucinated references
- Scientific discovery assistants: symbolic math, proof assistants, and theorem proving with step-verification
- Sectors: academia, software for science
- Tools/workflows: proof-search training with frontier selection to prioritize promising lemmas; replay buffers preserving proved subtheorems; integration with formal proof systems
- Assumptions/dependencies: high-quality formal verification environments; scalable search; robustness to sparse reward landscapes
- Multimodal reasoning (vision-language) with verifiable tasks (e.g., VQA with ground truth, diagram reasoning)
- Sectors: education, robotics, accessibility tools
- Tools/workflows: extend entropy-guided selection and frontier scoring to multimodal policies; verifiable subtasks (object counts, measurements, structured outputs)
- Assumptions/dependencies: reliable multimodal validators; standardized datasets; handling of perceptual uncertainty
- Generalized RLVR beyond purely verifiable domains via rubric or self-reward mechanisms
- Sectors: creative tools, customer service, communication
- Tools/workflows: hybrid reward functions blending verifiable checks with rubrics (quality, empathy); adapt Tree-GRPO to handle soft, noisy rewards
- Assumptions/dependencies: robust rubric design; mitigation of reward hacking; inter-rater reliability; calibration of entropy-guided negatives in subjective settings
- Model distillation and deployment workflows: train with DeepSearch, then distill into efficient inference-only models
- Sectors: software, edge AI
- Tools/workflows: pipeline that learns with MCTS during training but deploys a compact model without search; progressive filtering to focus distillation on hard cases
- Assumptions/dependencies: effective distillation procedures; retention of reasoning gains; task-specific generalization
- Community benchmarks and governance for search-augmented RLVR
- Sectors: academia, standards bodies
- Tools/workflows: reproducible protocols capturing exploration quality (global frontier metrics, entropy profiles); compute-to-gain reporting; public leaderboards that reward efficiency and transparency
- Assumptions/dependencies: shared tooling; consensus on metrics; sustained community participation
In summary, DeepSearch’s core innovations—training-time MCTS, global frontier selection, entropy-guided supervision, cached solution replay, and Tree-GRPO—make it immediately valuable for tasks with clear verifiable rewards (math, code, SQL/ETL) and open strong long-term pathways into safety-critical, multimodal, and partially verifiable domains, provided domain-specific validators, safety controls, and robust evaluation practices are in place.
Collections
Sign up for free to add this paper to one or more collections.