PRISM: Pushing the Frontier of Deep Think via Process Reward Model-Guided Inference
Abstract: DEEPTHINK methods improve reasoning by generating, refining, and aggregating populations of candidate solutions, which enables strong performance on complex mathematical and scientific tasks. However, existing frameworks often lack reliable correctness signals during inference, which creates a population-enhancement bottleneck where deeper deliberation amplifies errors, suppresses correct minority solutions, and yields weak returns to additional compute. In this paper, we introduce a functional decomposition of DEEPTHINK systems and propose PRISM, a Process Reward Model (PRM)-guided inference algorithm that uses step-level verification to guide both population refinement and solution aggregation. During refinement, PRISM treats candidate solutions as particles in a PRM-defined energy landscape and reshapes the population through score-guided resampling and stochastic refinement, which concentrates probability mass on higher-quality reasoning while preserving diversity. Across mathematics and science benchmarks, PRISM is competitive with or outperforms existing DEEPTHINK methods, reaching 90.0%, 75.4%, and 71.4% with gpt-oss-20b on AIME25, HMMT25, and GPQA Diamond, respectively, while matching or exceeding gpt-oss-120b. Additionally, our analysis shows that PRISM produces consistent net-directional correction during refinement, remains reliable when the initial population contains few correct candidates, and often lies on the compute-accuracy Pareto frontier.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to help AI models think more carefully and correctly when solving hard problems in math and science. The authors call their method PRISM. It uses a “process reward model” (PRM)—like a step-by-step checker—to guide the model while it is thinking, not just at the end. The goal is to turn long, complicated reasoning into a more reliable, step-by-step path toward correct answers.
What questions did the researchers ask?
They focused on three simple questions:
- When an AI tries many possible solutions, how can we improve those solutions over time instead of letting mistakes spread?
- Can we use a step-by-step correctness checker (the PRM) to steer the AI’s thinking in a better direction?
- Will this make the AI both more accurate and more efficient, especially on tough math and science problems?
How did they approach the problem?
Breaking down “DeepThink” systems
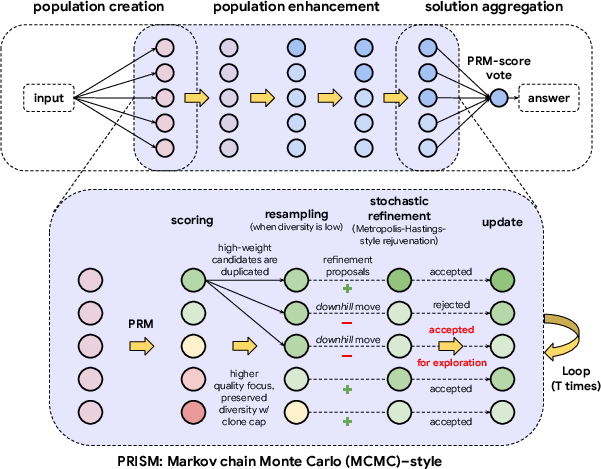
The paper looks at a family of methods called “DeepThink.” These methods spend extra compute (extra time and tokens) during inference to explore multiple solution attempts and then combine them. The authors split DeepThink into three stages:
- Population creation: Make a bunch of different solution attempts (like many students proposing different ways to solve the same problem).
- Population enhancement (refinement): Improve those attempts over several rounds (like students revising their work).
- Solution aggregation: Pick the final answer (like voting or choosing the best-written solution).
They found the biggest weakness is stage 2 (refinement). Without a good correctness signal, repeated revision often spreads errors or steers toward popular but wrong answers (they call this “majority dilution”). As a result, more compute doesn’t always mean better results.
The PRISM method in simple steps
PRISM adds a step-by-step checker (the PRM) into both refinement and final selection. Think of it like this:
- Each solution attempt is a “path” made of steps. The PRM scores each step, pointing out what makes sense and what doesn’t—like a teacher marking each line of work.
- PRISM treats all the solution attempts as “particles” moving on a landscape, where low “energy” means better reasoning. Good paths roll downhill; bad ones sit higher up.
- Every refinement round does three things:
- Scoring: The PRM scores each solution attempt based on its steps. Higher scores mean better internal logic.
- Resampling: If too many attempts are low-quality, PRISM keeps more of the higher-scoring ones and drops weaker ones—without letting one idea dominate completely (to keep diversity).
- Stochastic refinement: It suggests small changes to each attempt (sometimes a completely different approach), and only accepts those changes if they improve the PRM score often enough. This turns random rewrites into “directional correction,” nudging solutions toward being right.
For the final answer, PRISM doesn’t just count how many attempts say the same thing (majority vote). Instead, it sums up the PRM scores for each answer and picks the one backed by the highest-quality reasoning (PRM-score vote).
Here are a few key ideas in everyday terms:
- Process Reward Model (PRM): A step-by-step checker that gives feedback along the way, not just at the end.
- Energy landscape: Imagine hills and valleys where valleys are good reasoning; PRISM tries to move solutions downhill.
- Resampling: Keeping more of the good ideas and fewer of the bad ones, while still keeping variety.
- Stochastic refinement: Trying small edits and only keeping them when they improve the step-by-step score often enough.
- Majority dilution: When a wrong answer becomes popular and pushes out the right but less common one.
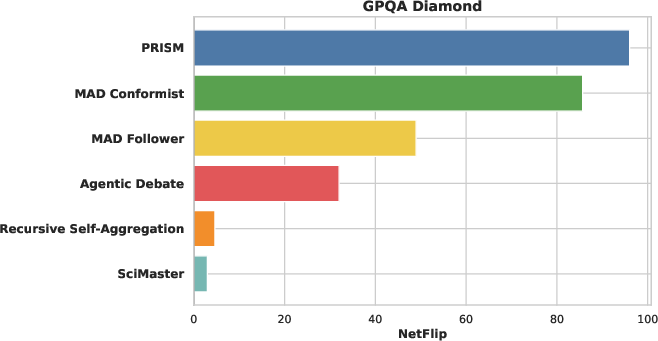
- NetFlip: A measure of whether revisions fix more wrong answers than they break correct ones. Positive NetFlip = overall improvement.
What did they find?
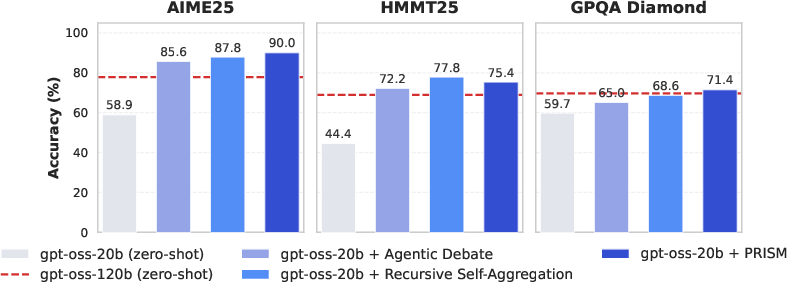
PRISM beat or matched other strong DeepThink methods on tough benchmarks:
- AIME25 (math): 90.0% accuracy
- HMMT25 (math): 75.4% accuracy
- GPQA Diamond (science): 71.4% accuracy
These results used a 20B model (gpt-oss-20b) and even matched or beat a larger 120B model in zero-shot mode. That means smarter inference can sometimes replace sheer model size.
Just as important, PRISM:
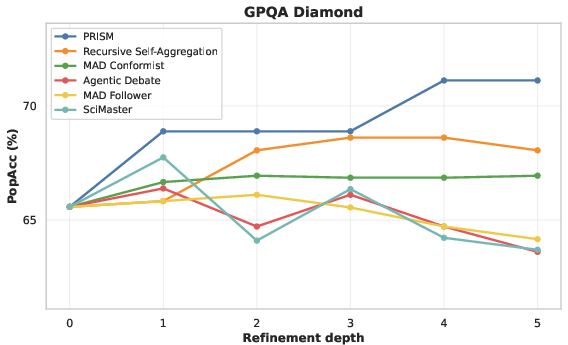
- Showed consistent “directional correction”: it fixed wrong solutions more often than it messed up correct ones (strong positive NetFlip).
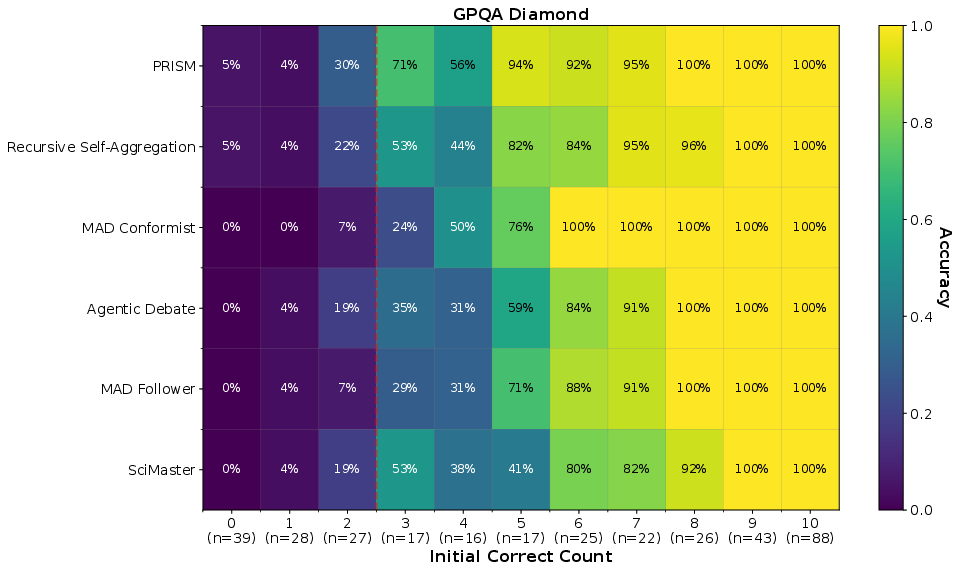
- Worked well even when few initial solutions were correct (it preserved rare good ideas and built them up instead of letting the wrong majority take over).
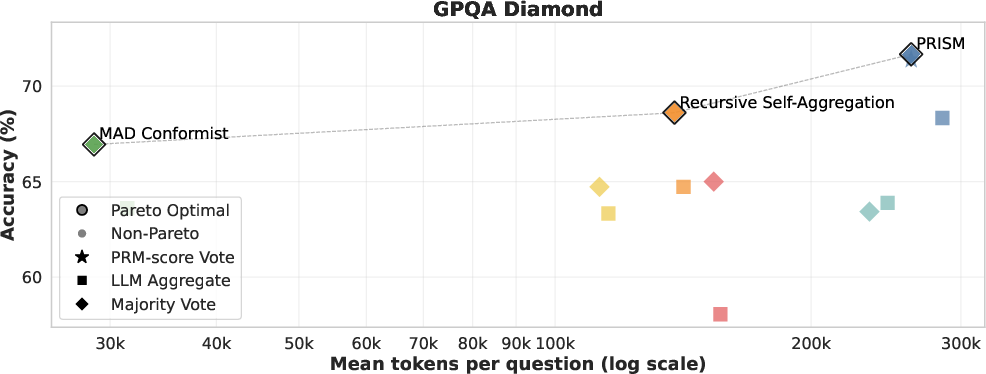
- Often sat on the “compute–accuracy Pareto frontier”: it used extra compute efficiently, giving better accuracy without wasting tokens.
Why does this matter?
When AI models solve hard problems, they often produce many possible solutions and need to refine them. If they don’t know which steps are correct, they waste compute and can end up confidently wrong. PRISM shows that:
- Step-by-step checking during inference makes revision smarter, not just longer.
- Good guidance (PRM) helps keep correct minority ideas alive and grow them—even when most attempts are wrong.
- Better inference can reduce the need for much bigger models, saving cost and compute.
In short, PRISM is a practical way to make AI reasoning both more reliable and more efficient, which could help in school-level math, advanced competitions, and scientific research where careful, step-by-step thinking matters.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable follow-up work.
- PRM provenance and calibration: The verifier is instantiated via prompting the same backbone used for generation, with no description of PRM training, calibration to ground-truth step labels, or robustness to noise. How does PRISM perform with a genuinely trained PRM (with labeled step-level rewards) versus an prompted verifier?
- Verifier–generator coupling: Using the same model family (often the same checkpoint) for generator, verifier, iterator, and comparator risks correlated errors and self-consistency bias. What are the gains when the verifier is architecturally different, trained separately, or tool-augmented?
- Reward hacking and adversarial behavior: The paper does not test whether models can inflate PRM scores by producing superficially “PRM-friendly” steps (e.g., formulaic language or step granularity manipulation) without improving correctness. How robust is PRISM to intentional or accidental reward exploitation?
- Step parsing fragility: The StepwiseNormalize heuristic (blank-line splits, <step> tags) is unvalidated. How sensitive are PRM scores and PRISM outcomes to step segmentation, formatting styles, or deliberate step inflation/splitting?
- PRM-score mapping: The deterministic rule that maps step feedback to a scalar score in [0,1] is pivotal but unspecified in detail and not ablated. Which scoring rules, normalizations, or calibrations correlate best with ground-truth correctness?
- Theoretical guarantees: The method is “MH-inspired” but does not correct for proposal asymmetry or intractable proposal densities. Are there any convergence guarantees, mixing-time analyses, or characterizations of stationary distributions under realistic PRM noise?
- Hyperparameter sensitivity: Key knobs (population width N=10, depth T=5, T_smc, ESS threshold α, noise η, clamp c, clone cap κ) lack sensitivity analyses. What hyperparameter regimes optimize accuracy/compute, and how stable are results across seeds and tasks?
- Scaling laws for N and T: Returns to larger populations or deeper refinement are unquantified. How do accuracy, NetFlip, and Pareto efficiency scale with N and T, and where are the diminishing returns or instability thresholds?
- Comparator/arbitration effects: Conflict arbitration and score clamping can materially shape dynamics, but there are no ablations of the comparator C, clamp c, or arbitration frequency. When does arbitration help versus suppress valid minority lines?
- Diversity vs. collapse: Resampling with clone caps limits collapse, but diversity is only tracked via ESS and dominance rates. What diversity metrics (e.g., semantic, proof-structure distances) best predict recovery and aggregation reliability?
- Aggregation design: PRM-score voting is compared only to majority and LLM aggregation. Are better PRM-aware aggregators possible (e.g., soft Bayesian pooling, per-step agreement weighting, cross-candidate step alignment, or proof-checking aggregation)?
- Cross-domain generalization: Evaluations focus on math/science (AIME25, HMMT25, partial GPQA). Does PRISM transfer to coding (with unit tests), symbolic reasoning, commonsense, long-form scientific writing, or multi-modal problems?
- External verifiers and tools: The method does not integrate formal solvers, unit tests, theorem provers, or calculators. How does PRISM behave when the PRM is augmented by tool-grounded checks or programmatic constraints?
- Low-correctness regimes with zero correct seeds: The analysis bins by initial correctness but does not isolate the extreme case where no initial candidate is correct. Can PRISM reliably bootstrap from zero-correct populations?
- Local vs. global reasoning myopia: Step-level PRM rewards may favor locally plausible but globally inconsistent reasoning. Can PRISM incorporate global-structure rewards (e.g., invariant checks, plan consistency, or proof-object verification)?
- Data contamination and benchmark coverage: GPQA Diamond is truncated to 120 items; no statistical tests or variance estimates are provided. Are results robust on the full dataset and additional held-out benchmarks with confidence intervals?
- Cost/latency realism: Compute is measured in tokens with assumed pricing, but wall-clock latency, parallelization overhead, and memory constraints for larger N/T are not reported. How do throughput and latency compare under realistic deployment settings?
- Robustness under distribution shift and adversarial prompts: Behavior under out-of-domain problems, noisy statements, adversarially phrased tasks, or ambiguous/multi-answer questions remains untested.
- Fair baseline tuning: Several baselines underperform Majority Vote; it is unclear if aggregation prompts or refinement settings were optimized equally. Do stronger, PRM-aware versions of baselines close the gap?
- Verification accuracy vs. strength trade-offs: Section on Qwen suggests gains when the verifier > generator, but does not map the frontier. What is the verifier–generator size/quality ratio that maximizes accuracy per token?
- Proposal operator design: The iterator I’s prompt and proposal strategy are fixed. Which proposal operators (local edits, plan-first edits, counterfactual branches, retrieval-augmented proposals) most improve acceptance and NetFlip?
- Annealing and schedules: Static T_smc and η may be suboptimal. Do annealing schedules (temperature, noise, resampling frequency) improve exploration early and exploitation late?
- Deduplication and paraphrase handling: The population may contain near-duplicates that inflate PRM-weighted evidence. How does explicit semantic deduplication affect diversity, PRM-score voting, and calibration?
- Multi-solution tasks: The framework assumes a single correct answer. How should PRISM arbitrate when multiple answers are valid or when tasks require set-valued or probabilistic outputs?
- Interpretability of corrections: While NetFlip indicates directional correction, the paper lacks qualitative error taxonomies. Which error types are actually corrected (algebraic slips, misapplied theorems, plan inconsistencies)?
- Safety and alignment: The paper flags safety concerns but provides no safety evals (e.g., overconfidence on wrong answers, deceptive rationales). How does PRISM affect harmful reasoning, and can PRM signals be aligned with safety objectives?
- Cross-lingual and multi-lingual settings: No evaluation outside English. How do step parsing, PRM scoring, and aggregation behave in other languages or code-switched contexts?
- Reproducibility details: Critical components (exact PRM feedback schema, Score(·) mapping, prompts for V/I/C, arbitration criteria) need full release and versioning; without them, reproducing results and ablations is difficult.
- Integration with training-time methods: The bridge between PRISM-style inference and training (e.g., RL with PRM, supervised finetuning on PRISM-curated traces) is unexplored. Can training incorporate PRISM’s population dynamics to reduce inference cost?
- Combining with tree search: PRISM is population-based but not tree-structured. How does it compare or combine with MCTS/beam search guided by PRMs, and can hybrid methods capture complementary benefits?
- Long-context and memory limits: Behavior with very long chains-of-thought or multi-stage problems is not assessed. How do context-window constraints and memory management affect PRM feedback quality and refinement stability?
- Failure case analyses: The paper reports average gains but provides limited quantitative or qualitative analyses of where PRISM fails (e.g., specific GPQA categories). What systematic failure modes remain and how can they be mitigated?
Practical Applications
Immediate Applications
These applications can be deployed with current LLMs and standard tooling by adapting PRISM’s PRM-guided refinement, PRM-score voting, and compute-aware orchestration to existing workflows.
- PRM-score voting to replace majority vote in multi-sample LLM inference — sectors: software, education, research, enterprise analytics
- Tools/workflows: drop-in “PRM-score Vote” aggregator in sampling pipelines (Sample-N → PRM scoring → sum-by-answer → argmax); prompt-based verifiers for math/science/coding tasks; integrate with LangChain/LlamaIndex/agent frameworks.
- Assumptions/dependencies: stepwise normalization of outputs; a reliable verifier prompt (or lightweight PRM) for the domain; robust answer extraction.
- Directional refinement plugin for agent frameworks — sectors: software, enterprise AI, research tooling
- Tools/workflows: add PRISM’s ESS-based resampling, clone capping, and Metropolis-style acceptance to debate/critic agents to counter majority dilution; expose NetFlip and PopAcc as runtime metrics.
- Assumptions/dependencies: access to underlying candidate population; iterator prompts that can propose local or alternate reasoning; verifier with deterministic decoding.
- Cost optimization by “small-model + PRISM” — sectors: SaaS, startups, ML platforms
- Tools/workflows: replace calls to large models with smaller backbones augmented by PRISM; tune population width/depth to sit on the accuracy–compute Pareto frontier; monitor token budgets.
- Assumptions/dependencies: availability of a verifier at least as strong as (ideally stronger than) the generator or task-specific rubric; budget for additional inference steps.
- Test-driven code generation with PRM-as-tests — sectors: software engineering, DevOps
- Tools/workflows: treat unit/integration test pass rates as the PRM score; run N candidate patches, resample by pass-rate, refine via targeted edits, accept proposals by score ratio; choose highest PRM-score solution.
- Assumptions/dependencies: existing executable tests or static analyzers; fast sandboxing; deterministic scoring; careful handling of flaky tests.
- AI tutoring with stepwise verification — sectors: education
- Tools/workflows: math/science tutors that provide step-by-step feedback using PRM scoring; refine hints/solutions directionally; select final answer by PRM-score vote rather than frequency.
- Assumptions/dependencies: clear step tagging and rubrics; calibrated verifier prompts for the curriculum; safeguards to avoid leaking final answers when formative feedback is desired.
- Scientific problem solving and peer review assistance — sectors: academia, R&D
- Tools/workflows: use PRM to score intermediate derivations (e.g., unit checks, dimensional analysis, definitional consistency), resample/refine candidate proofs/calculations, and aggregate by PRM score.
- Assumptions/dependencies: domain templates for step validation; parsers for equations/units; human-in-the-loop oversight.
- Reasoning QA dashboards for ML/Ops — sectors: ML platform teams, reliability/safety
- Tools/workflows: adopt NetFlip, PopAcc vs. depth, ESS, and resampling rates as monitoring KPIs during inference A/B tests; auto-stop when marginal gains flatten; detect population collapse with clone-cap counters.
- Assumptions/dependencies: access to candidate-level traces; logging/telemetry pipeline; privacy controls for stored traces.
- Safer aggregation for RAG and enterprise QA — sectors: enterprise search, knowledge management
- Tools/workflows: condition PRM scoring on citations/checklists (e.g., source consistency, date validity); aggregate answers by PRM score; avoid rationalizing incorrect majorities.
- Assumptions/dependencies: retrieval provenance available for scoring; verifier prompts tuned for fact consistency; robust answer deduplication.
- Robust majority-dilution mitigation in debate-style systems — sectors: agent platforms
- Tools/workflows: incorporate PRM-weighted resampling/acceptance between debate rounds; clamp conflicting high-scoring candidates; cap clones to prevent collapse.
- Assumptions/dependencies: debate agents expose intermediate steps; comparator prompt for arbitration; careful temperature settings to balance exploration.
- Personal assistants for structured tasks (checklist PRM) — sectors: daily life
- Tools/workflows: encode checklists (budget constraints, scheduling rules, dietary restrictions) as PRM scoring; generate/refine multiple plans; pick the plan with highest rule adherence.
- Assumptions/dependencies: high-quality checklists; clear step formatting; user confirmation loop for preferences/constraints.
Long-Term Applications
These require further research, domain-specific PRMs, validation, and/or scaling to high-stakes settings.
- Clinical decision support with process-based oversight — sectors: healthcare
- Tools/products: PRMs trained on clinical guidelines, diagnostic pathways, and safety checklists; PRISM-guided refinement of differential diagnoses and care plans; PRM-score aggregation across candidate plans.
- Assumptions/dependencies: clinically validated PRMs; regulatory approval (e.g., FDA/CE); robust EHR integration and privacy; human oversight.
- Model risk and compliance analysis — sectors: finance
- Tools/products: PRMs derived from policy/risk rules (e.g., capital adequacy, stress test logic); PRISM to explore/refine scenarios and controls; dashboards with NetFlip/PopAcc for auditability.
- Assumptions/dependencies: codified regulations; explainability requirements; governance for false positives/negatives; secure data environments.
- Autonomous robotic/task planning with physics-aware PRMs — sectors: robotics, manufacturing, logistics
- Tools/products: PRMs using simulators/constraint checkers to score plan steps (feasibility, safety margins); PRISM-guided plan refinement; real-to-sim validation loops.
- Assumptions/dependencies: fast, trustworthy simulators; reliable state estimation; domain-specific proposal operators; safety certification.
- Grid and energy system optimization — sectors: energy
- Tools/products: PRMs encoding power flow constraints, market rules, and reliability criteria; PRISM to refine dispatch/maintenance plans under uncertainty; PRM-score aggregation for final schedules.
- Assumptions/dependencies: high-fidelity system models; operator approval processes; real-time compute constraints; robust telemetry.
- Legal and policy analysis assistants — sectors: public policy, legal tech
- Tools/products: PRMs trained on procedural doctrines, citation chains, and jurisdictional rules; PRISM to refine arguments and surface compliant minority positions; PRM-score-based consensus.
- Assumptions/dependencies: curated, up-to-date legal corpora; jurisdictional nuance; human expert review; liability frameworks.
- Process-Reward Model training and standardization — sectors: AI infrastructure, academia
- Tools/products: datasets and benchmarks for step-level supervision across domains (math, code, science, law, medicine); protocols for PRM calibration and robustness testing; open PRM hubs.
- Assumptions/dependencies: labeled process data; agreement on scoring schemas; data licensing/ethics; reproducibility standards.
- Multi-modal PRMs for vision–language reasoning — sectors: autonomous systems, medical imaging, scientific discovery
- Tools/products: PRMs that score intermediate visual/graphical steps (e.g., diagram interpretation, plots, scans); PRISM for multi-modal reasoning pipelines.
- Assumptions/dependencies: aligned multi-modal datasets; interpretable intermediate representations; evaluation harnesses.
- Training–inference synergy (process RL and distillation) — sectors: core AI research, platform vendors
- Tools/products: use PRISM traces and PRM scores to train models (e.g., RL from process feedback, distill PRISM behaviors into base models); curriculum schedules based on NetFlip trends.
- Assumptions/dependencies: scalable training pipelines; stability of process rewards; prevention of reward hacking; generalization checks.
- Adaptive compute controllers — sectors: ML platforms
- Tools/products: controllers that adjust population width/depth, T_smc, and resampling thresholds online based on PopAcc/ESS signals to hit SLAs; auto-terminate on diminishing returns.
- Assumptions/dependencies: accurate online metrics; latency budgets; policy for high-stakes vs. low-stakes tasks.
- Safety and governance standards for process-based inference — sectors: policy, industry consortia
- Tools/products: guidelines that require step-level verification, NetFlip/PopAcc reporting, and majority-dilution safeguards for high-stakes deployments; certification checklists for PRM/PRISM pipelines.
- Assumptions/dependencies: multi-stakeholder agreement; third-party audits; mappings from metrics to risk levels; mechanisms for continuous monitoring.
- Collaborative scientific discovery platforms — sectors: academia, pharma, materials
- Tools/products: PRISM-enabled co-reasoning with domain tools (symbolic solvers, cheminformatics), with PRMs scoring mechanistic plausibility and constraint satisfaction; hypothesis triage by PRM-score.
- Assumptions/dependencies: integration with domain simulators and databases; reproducibility pipelines; IP/data-sharing frameworks.
Glossary
- Agentic Debate: A multi-agent refinement framework where candidates iteratively challenge and update each other's reasoning. "A multi-agent framework in which each candidate revises itself using information from other candidates in the population, enabling peer-to-peer information flow."
- Boltzmann (Gibbs) distribution: A probability distribution from statistical mechanics used to model energy-based systems; here it maps PRM scores to weights via an energy interpretation. "corresponds to a Boltzmann (Gibbs) distribution with energy ."
- budget forcing: A test-time technique that controls reasoning length by constraining or extending chains to manage compute. "~\citet{muennighoff-etal-2025-s1} rely on budget forcing, which artificially truncates or extends reasoning chains to control compute allocation."
- clone cap: A safeguard that limits how much of the population can be taken over by duplicated high-weight candidates after resampling. "clone capping limits the fraction of the population that can be occupied by duplicated traces during resampling"
- conflict arbitration: A stabilizer that resolves ties between high-scoring but conflicting answers by clamping their scores using a comparator. "conflict arbitration resolves cases where distinct answers receive similarly high PRM scores by using a comparator model and clamping conflicting candidates to a minimum score "
- DeepThink: A reasoning paradigm that leverages extra inference-time compute to explore and combine multiple candidate solutions before answering. "a reasoning paradigm that allocates additional inference-time compute to simultaneously explore and combine multiple candidate solutions"
- Effective Sample Size (ESS): A measure of weight concentration in particle methods indicating diversity of the weighted population. "we quantify by computing the effective sample size (ESS)"
- energy-based acceptance filter: A Metropolis-inspired rule that accepts or rejects proposed refinements based on score-derived energy ratios. "we use a Metropolis-inspired energy-based acceptance filter (via weight ratios) rather than claiming an exact Metropolis--Hastings correction."
- energy landscape: An energy-function view of solution space where lower energy corresponds to higher-quality reasoning, guiding population evolution. "PRISM treats candidate reasoning traces as a population evolving under an energy landscape defined by the PRM"
- importance weight: A weight assigned to each candidate proportional to its quality score, used to bias selection in resampling. "convert this score into an unnormalized importance weight"
- majority dilution: A failure mode where correct minority reasoning is suppressed by more frequent incorrect trajectories. "infrequent yet logically correct reasoning traces are suppressed by more frequent but incorrect trajectories, a phenomenon we refer to as majority dilution."
- Markov chain Monte Carlo (MCMC): A class of sampling algorithms that explore complex distributions via Markovian transitions; here used as a refinement analogy. "These Markov chain Monte Carlo ({MCMC})-style transitions balance exploitation of promising solutions with continued exploration"
- Metropolis-Hastings: A specific MCMC method providing acceptance rules for proposed moves; here used as a style for rejuvenation in refinement. "Stochastic refinement (Metropolis-Hastings-style rejuvenation)"
- Monte Carlo Tree Search: A search algorithm that explores decision trees by randomized simulation and selection, used for structured reasoning. "tree-based inference methods such as Monte Carlo Tree Search"
- NetFlip: A directional metric counting net incorrect→correct minus correct→incorrect transitions during refinement. "exhibiting a strongly positive NetFlip"
- nucleus sampling: A stochastic decoding technique that samples tokens from the smallest set whose cumulative probability exceeds a threshold. "stochastic decoding (e.g., temperature or nucleus sampling~\citep{Holtzman2020The})"
- Pareto frontier: The set of non-dominated trade-offs between compute and accuracy where improving one requires worsening the other. "often lies on or near the computeâaccuracy Pareto frontier"
- PRISM: A PRM-guided inference algorithm that injects step-level correctness signals into refinement and aggregation for directional error correction. "we propose PRISM, a PRM-guided inference algorithm that uses step-level correctness signals to transform iterative refinement into directional error correction and inform final solution aggregation."
- PRM-score Vote: An aggregation method that selects the final answer supported by the highest sum of PRM scores across candidates. "PRM-score Vote), which selects the candidate with the highest aggregate PRM score."
- Process Reward Model (PRM): A model that evaluates intermediate reasoning steps to provide process-level correctness signals. "PRISM uses a Process Reward Model (PRM) to evaluate reasoning trajectories based on their internal steps"
- resampling: A particle-filter operation that reallocates population mass by duplicating high-weight candidates and discarding low-weight ones. "we resample: high-weight candidates are duplicated and low-weight candidates discarded."
- Sample-N: A population creation strategy that generates multiple independent candidates via stochastic decoding. "we refer to this strategy as Sample-N."
- Sequential Monte Carlo (SMC): A class of particle methods that evolve weighted samples over iterations; here controls exploration via a temperature. "(smc stands for Sequential Monte Carlo)"
- stochastic refinement: Proposal-based updates to candidate traces that are probabilistically accepted, enabling exploration and correction. "proposes stochastic refinements that are accepted probabilistically based on PRM scores"
- step-level verification: Fine-grained checking of intermediate reasoning steps to provide correctness signals during inference. "uses step-level verification to guide both population refinement and solution aggregation"
- verbalized sampling: A generation technique where the model produces multiple solutions with self-reported plausibility signals. "verbalized sampling~\citep{zhang2025verbalized}"
Collections
Sign up for free to add this paper to one or more collections.