Empirical-MCTS: Continuous Agent Evolution via Dual-Experience Monte Carlo Tree Search
Abstract: Inference-time scaling strategies, particularly Monte Carlo Tree Search (MCTS), have significantly enhanced the reasoning capabilities of LLMs. However, current approaches remain predominantly stateless, discarding successful reasoning patterns after each problem instance and failing to mimic the empirical accumulation of wisdom characteristic of human problem-solving. To bridge this gap, we introduce Empirical-MCTS, a dual-loop framework that transforms stateless search into a continuous, non-parametric learning process. The framework unifies local exploration with global memory optimization through two novel mechanisms: Pairwise-Experience-Evolutionary Meta-Prompting (PE-EMP) and a Memory Optimization Agent. PE-EMP functions as a reflexive optimizer within the local search, utilizing pairwise feedback to dynamically synthesize adaptive criteria and evolve meta-prompts (system prompts) in real-time. Simultaneously, the Memory Optimization Agent manages a global repository as a dynamic policy prior, employing atomic operations to distill high-quality insights across problems. Extensive evaluations on complex reasoning benchmarks, including AIME25, ARC-AGI-2, and MathArena Apex, demonstrate that Empirical-MCTS significantly outperforms both stateless MCTS strategies and standalone experience-driven agents. These results underscore the critical necessity of coupling structured search with empirical accumulation for mastering complex, open-ended reasoning tasks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a new way to make AI systems better at step-by-step thinking without retraining them. The idea is to let the AI “remember” what worked before and use that memory to guide future problem solving. The method combines a classic planning tool called Monte Carlo Tree Search (MCTS) with a smart memory system and a self-improving “meta-prompt” (the AI’s high-level instructions). The authors call this whole setup Empirical-MCTS.
What questions did the researchers ask?
- Can we turn stateless search (where the AI forgets everything after each problem) into a stateful process that keeps useful lessons and gets better over time?
- Can the AI learn two kinds of experience at once:
- Short-term: Learn during the current problem, using immediate feedback.
- Long-term: Keep and refine good ideas across many problems.
- Will this “remember-and-evolve” approach beat strong methods that only search or only store experiences?
How does their method work?
Think of solving hard problems like playing a strategy game.
- You explore different moves (paths of reasoning).
- You compare a few options head-to-head to see which is better.
- You write down what worked so you can do better next time.
- You keep your notes tidy so you don’t repeat the same mistakes.
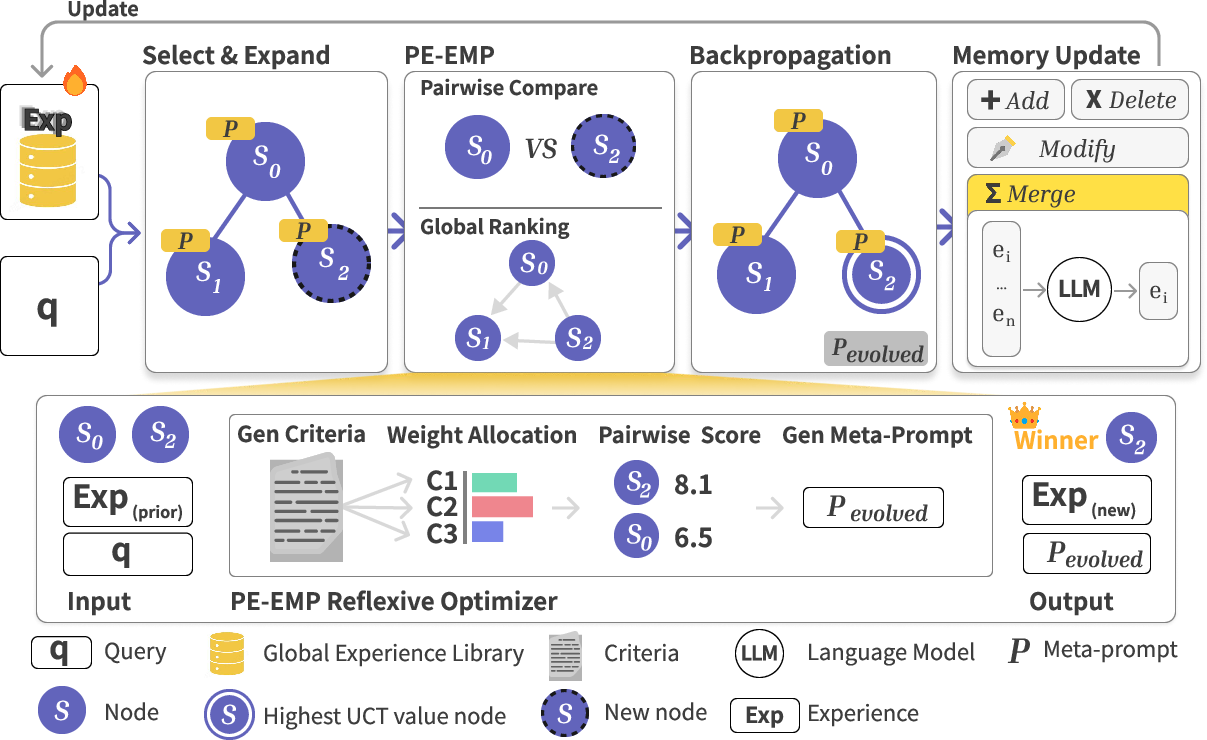
Empirical-MCTS does all of that using four key pieces working in two loops.
1) Exploring choices with a tree (MCTS)
- MCTS is like a choose-your-own-adventure map. The AI tries different reasoning steps, branches when there are promising ideas, and backs up rewards to decide which paths are best to follow next.
- A selection rule (similar to “try the winner, but sometimes explore something new”) keeps the search balanced.
2) A smart judge that creates its own rules (PE-EMP)
- PE-EMP stands for Pairwise-Experience-Evolutionary Meta-Prompting.
- Imagine a judge comparing two answers: it first writes custom “criteria” (rules) for this specific problem, then scores both answers using those criteria.
- Based on what wins and why, it immediately upgrades the meta-prompt—the high-level instructions the AI uses to think—so the next steps follow better strategy.
- In simple terms: the judge doesn’t just pick a winner; it learns why it won, writes that down as principles, and updates the AI’s instructions on the spot.
3) A memory coach that tidies and updates knowledge (Memory Optimization Agent)
- The system keeps a global “experience library,” like a well-organized notebook of tips and patterns that worked.
- After each problem, new insights are:
- Added (new good ideas),
- Modified (fix or sharpen existing tips),
- Merged (combine duplicates into a clearer rule),
- Deleted (remove bad or outdated advice).
- This turns the library into a strong “prior” (a helpful starting guide) for future problems, without retraining the AI’s weights.
4) Fair scoring that mixes local duels and global rankings
- When the judge compares two answers, it assigns scores (local preferences).
- But pairwise wins can be messy (A beats B, B beats C, yet C beats A).
- So the system blends:
- Local scores from the judge, and
- A global ranking (like a season leaderboard) built from all matchups,
- to get a stable reward signal for the tree search.
The two loops working together
- Local loop (within one problem): try steps → compare answers → learn criteria → evolve the meta-prompt → steer the next steps better.
- Global loop (across many problems): distill new insights → update the memory library → start the next problem with stronger guidance.
What did they find?
The authors tested Empirical-MCTS on tough benchmarks that require careful reasoning:
- AIME25 (contest-style math): Their method reached 73.3%, beating strong search-based baselines (e.g., LLaMA-Berry at 63.3%) and experience-only agents (e.g., FLEX at 66.6%).
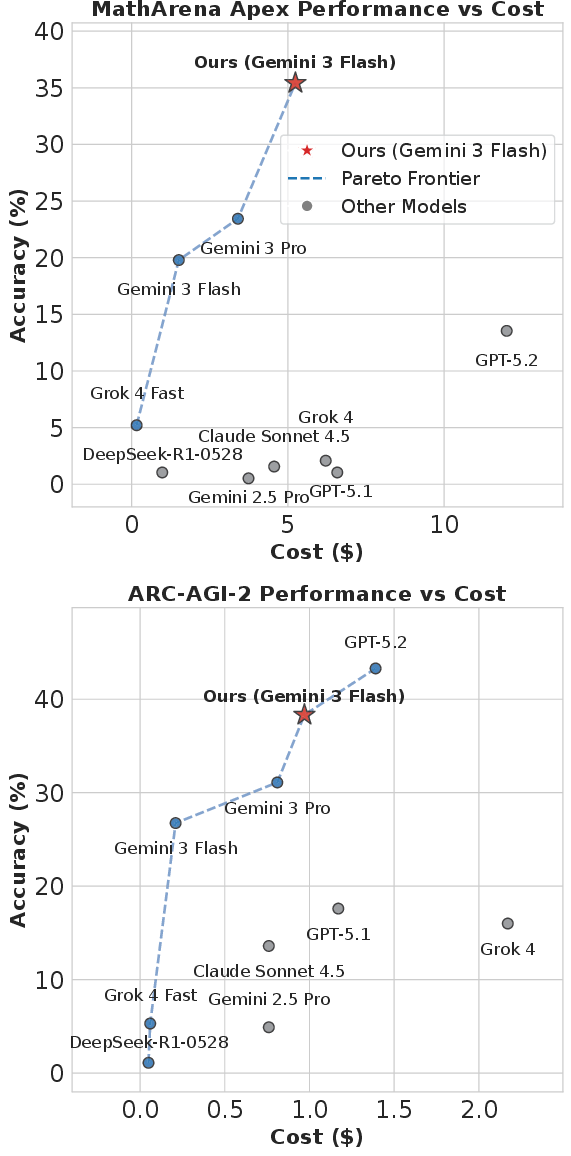
- MathArena Apex (very hard, proof-focused math): Where the base model and repeated sampling often scored 0, Empirical-MCTS found nonzero solutions and improved results (e.g., 4.17% in one setting where others got 0–2.08%). On another setup with a cost-efficient model, their method reached 35.42%.
- ARC-AGI-2 (general reasoning): Their approach achieved strong accuracy while staying low cost, even surpassing more expensive models in some comparisons.
They also ran ablation studies (turning pieces off) and found:
- Removing the evolving meta-prompt or the memory library hurts performance.
- Standard search without the “pairwise judge” and evolution falls back to much lower scores.
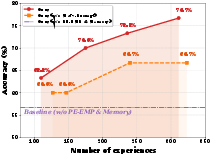
- As the experience library grows, performance improves—showing that “remembering” really helps.
Why is this important?
- It shows that AIs can get better at reasoning during use, without retraining their internal weights, by:
- Learning rules from immediate comparisons,
- Updating their strategy prompts in real time, and
- Keeping a curated memory of what works.
- This can make smaller, cheaper models compete with or even outperform bigger, more expensive ones on hard tasks—great for making advanced reasoning more accessible.
What could this change in the real world?
- Smarter study helpers: Tutoring systems that learn better problem-solving strategies across sessions.
- More reliable coding assistants: They can remember which debugging steps tend to fix certain bugs.
- Scientific and engineering tools: Systems that refine their reasoning playbook as they encounter new challenges.
- Lower costs: Organizations could get strong reasoning performance without constantly retraining huge models.
Any limits or next steps?
- Risk of “bad lessons”: If the model misjudges a solution, it might store “fake wisdom” and drift in the wrong direction.
- The authors suggest adding stronger checks for consistency and uncertainty to filter questionable insights.
- They also want to extend this to longer, multi-turn tasks where memory and strategy matter even more.
In short: Empirical-MCTS turns search into learning. By comparing answers, writing down good rules, updating instructions on the fly, and keeping a clean memory, the AI steadily improves—much like a person who practices, reflects, and keeps a great notebook.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper. These items are framed to enable concrete follow-up research.
- Lack of theoretical guarantees: no analysis of convergence, monotonic improvement, stability, or regret for MCTS under dynamic, evolving prompts and non-parametric memory updates.
- Uncertain reliability of the LLM-as-judge: no calibration, inter-judge agreement, or robustness checks for the self-principled pairwise scores used as rewards.
- Sensitivity of adaptive criteria generation: no study of how noisy or suboptimal criteria generation affects downstream ranking, search guidance, and prompt evolution.
- Potential reward hacking/Goodharting: no safeguards or diagnostics to detect when the generator optimizes the judge’s preferences rather than task correctness.
- Hybrid reward fusion design: no ablation on the weighting scheme between local Bradley–Terry probabilities and global Enhanced Borda Count, nor sensitivity to rank cycles or graph sparsity.
- Memory quality control: beyond a high-level mention, there is no concrete uncertainty quantification, verification protocol, or external validator (e.g., symbolic proof checkers, unit tests) to filter “toxic” experiences.
- Memory operations specification: “add/modify/merge/delete” are described conceptually, but the precise algorithms, conflict resolution rules, versioning, and provenance tracking are not specified or evaluated.
- Catastrophic interference and forgetting: no analysis of how edits or merges may degrade existing high-value experiences or induce instability (stability–plasticity trade-off).
- Memory scaling behavior: no measurements of repository growth vs. retrieval latency, memory footprint, and compute overhead; no strategies for compaction, hierarchical indexing, or curriculum-aware memory sharding.
- Prompt evolution control: no mechanisms to prevent prompt bloat, semantic drift, or loss of safety constraints; no regularization, pruning, or complexity budgets for the meta-prompt.
- Safety and integrity of memory: no defenses against prompt injection, adversarial or poisoned experiences entering the library, or cross-task propagation of unsafe heuristics.
- Task taxonomy reliability: the zero-shot classifier that gates memory retrieval is not validated; no error analysis on misclassification and its impact on performance or drift.
- Cold-start behavior: no study of performance when the experience library is empty or poorly initialized; unclear bootstrapping strategies and their cost-effectiveness.
- Cross-task interference: no investigation of negative transfer when a shared memory serves heterogeneous domains; no gating or compartmentalization policies beyond coarse taxonomy tags.
- Compute accounting parity: unclear whether all baselines were given matched compute (rollouts, tokens, judge calls); memory update and judging overheads may not be fully costed in the comparisons.
- Statistical rigor: results on some benchmarks are reported over few runs (e.g., 4), without confidence intervals or significance tests; reproducibility across seeds is unreported.
- Ablation scope: ablations are limited to AIME25 with one model; missing cross-benchmark (ARC-AGI-2, MathArena) and cross-model ablations to generalize component contributions.
- Hyperparameter sensitivity: no systematic study of k (retrieval size), UCB constants, decay γ, local/global reward fusion weights, temperature, and thresholds for “high-value” insights.
- Scheduler design: no investigation of when to commit experiences to memory, how frequently to evolve prompts, or how to adapt rollout budgets and compute across problem difficulty.
- Parallelism and consistency: no analysis of concurrent trees or agents updating a shared memory (race conditions, eventual consistency, conflict resolution).
- External verification integration: for math and ARC tasks, no use of formal proof checkers, SMT solvers, or program validators to ground the reward and memory updates.
- Upper bounds and diminishing returns: unclear at what memory size or base-model capability the gains saturate; no scaling law relating rollouts, memory size, and accuracy.
- Generalization beyond evaluated domains: limited evidence for applicability to multi-turn dialogues, tool-augmented settings, longer-horizon planning, or non-math/non-ARC tasks.
- Safety–performance trade-offs: evolving prompts may improve accuracy but degrade helpfulness/harmlessness; no alignment metrics or safety audits are reported.
- Negative results characterization: no taxonomy of typical failure modes (e.g., arithmetic vs. planning vs. verification errors) to guide targeted memory curation.
- Memory provenance and IP/privacy: no discussion of privacy-preserving logging, personal data risks, or governance when experiences persist across sessions or users.
- Benchmark contamination and leakage: while MathArena aims to be uncontaminated, there is no explicit auditing for memory-induced leakage or overfitting due to persistent experience accumulation.
- Baseline selection and fairness: unclear if baselines (e.g., LLaMA-Berry, FLEX) were strengthened with equivalent retrieval, judge, or memory capacities for strictly fair comparisons.
- Prompt/judge coupling: if the same (or similar) model family acts as both generator and judge, circular biases may inflate gains; no experiments with independent judges or human audits.
- Alternative search policies: only UCB is explored; no comparison with PUCT/AlphaZero-style policies or learned priors, nor interaction effects with memory-guided priors.
- Stopping criteria and termination: no adaptive stopping rules (e.g., confidence thresholds) that trade off cost and accuracy under the evolving reward signal.
- Long-horizon persistence: no longitudinal study of memory drift and performance over extended deployments, including strategies for decay, archiving, or periodic revalidation of experiences.
- Comparison to lightweight finetuning: no head-to-head cost–quality analysis versus small-scale finetuning or LoRA adapters to contextualize the value of purely non-parametric updates.
- Quantifying prompt quality: beyond qualitative examples, no metrics or automated diagnostics to assess prompt evolution quality, compressibility, or transferability across tasks and models.
Practical Applications
Below is a distilled set of practical applications that build on the paper’s findings and mechanisms (Empirical-MCTS, PE-EMP, dynamic experience memory, hybrid preference integration). Each item indicates likely sectors, prospective tools/products/workflows, and key assumptions or dependencies.
Immediate Applications
- Organizational reasoning co‑pilot for cost‑efficient inference
- Sectors: software, enterprise AI platforms
- Tools/products/workflows: middleware that wraps existing LLMs with Empirical-MCTS to boost reasoning using cheaper models; a “compute budget router” that selects small models + Empirical-MCTS over larger models for certain tasks
- Assumptions/dependencies: access to a competent base LLM; latency/compute budget for MCTS rollouts; observability for cost/performance trade-offs
- PromptOps/MemoryOps layer for enterprise LLM apps
- Sectors: software, DevOps/MLOps
- Tools/products/workflows: “Experience Library Manager” that supports add/modify/merge/delete updates; versioned memory with diffs/rollback; task taxonomy tagging for retrieval
- Assumptions/dependencies: secure vector/document store; governance for memory curation; PII scrubbing
- Customer support agent with evolving SOPs and KB
- Sectors: customer support, BPO, SaaS
- Tools/products/workflows: ticket resolution assistant whose meta-prompt and SOPs evolve via PE-EMP; Memory Agent merges duplicates and refines macros/playbooks
- Assumptions/dependencies: human-in-the-loop quality gates; redaction/policy compliance; guardrails against “hallucinated wisdom”
- Code generation, review, and bug-fixing assistant with learned org patterns
- Sectors: software engineering, DevTools
- Tools/products/workflows: Empirical-MCTS agent that evolves meta-prompts per repository; pairwise evaluation of candidate patches; memory stores effective fix patterns and anti-patterns
- Assumptions/dependencies: test harness/CI for automatic verification; repository and issue tracker access; style/security policy tagging
- Data/ETL transformation from examples (ARC-like reasoning for ops)
- Sectors: data engineering, analytics/BI
- Tools/products/workflows: program-synthesis helper that infers transformations from examples; PE-EMP to generate and refine transformation criteria; library of reusable transformation principles
- Assumptions/dependencies: sandboxed data execution; golden examples/tests; schema-aware retrieval
- Math/proof tutoring with adaptive rubrics
- Sectors: education, EdTech
- Tools/products/workflows: PE-EMP-generated “self-principled” grading rubrics that evolve per topic; MCTS to explore multiple solution paths; memory of common misconceptions and targeted hints
- Assumptions/dependencies: teacher oversight and rubric audit; alignment with curriculum; constraints on hallucination
- Document QA and summarization with preference-ranked answers
- Sectors: legal, finance, research, enterprise knowledge management
- Tools/products/workflows: Enhanced Borda Count + PE-EMP judge to rank multiple candidate answers/summaries and distill domain-specific critique principles into memory
- Assumptions/dependencies: accurate retrieval (RAG); human review for high-stakes use; consistency checks
- Incident response/runbook curator
- Sectors: SecOps, ITOps, SRE
- Tools/products/workflows: post-incident assistant that distills new learnings; Memory Agent merges/edits runbooks; meta-prompt evolves to prioritize high-fidelity diagnostics
- Assumptions/dependencies: access-controlled logs; change management approvals; audit trails for runbook edits
- Analytics/SQL co‑pilot with evolving schema and metric knowledge
- Sectors: analytics, data science
- Tools/products/workflows: query assistant that learns dataset quirks/metrics definitions; PE-EMP to enforce query quality criteria; memory of reusable query templates
- Assumptions/dependencies: DB connectivity with read-only sandbox; query validation; metric governance
- Sales outreach/proposal optimizer using pairwise evaluation
- Sectors: sales/marketing
- Tools/products/workflows: A/B generation + PE-EMP judge to evolve messaging criteria (tone, clarity, compliance); memory of winning patterns by segment
- Assumptions/dependencies: CRM/email integration; compliance filters; privacy policies
- Cost-optimized reasoning router for platform teams
- Sectors: AI infrastructure/platform
- Tools/products/workflows: scheduler that assigns tasks to small models augmented by Empirical-MCTS vs. large models; live Pareto tracking of cost vs. accuracy
- Assumptions/dependencies: monitoring/telemetry; SLAs for latency; budget constraints
- Hiring and review rubric assistant (with safeguards)
- Sectors: HR, academia (peer assessment), procurement
- Tools/products/workflows: PE-EMP to synthesize and evolve explicit evaluation criteria and weights; pairwise ranking for consistency
- Assumptions/dependencies: bias/fairness audits; legal/compliance review; opt-in usage with transparency
- Literature review assistant with evolving domain critique principles
- Sectors: academia, R&D, pharma
- Tools/products/workflows: multi-draft summaries ranked by hybrid preference; memory of methodological red flags and domain-specific assessment criteria
- Assumptions/dependencies: access to corpora; citation checking; human validation
- Plug-in for agent frameworks (LangChain/LlamaIndex, internal tools)
- Sectors: software, enterprise AI
- Tools/products/workflows: drop-in Empirical-MCTS module (tree search + PE-EMP + Memory Agent + hybrid ranking); task-type tagging and retrieval filters
- Assumptions/dependencies: framework compatibility; prompt length/latency constraints; logging for memory evolution
Long-Term Applications
- Clinical decision support with self-improving reasoning priors
- Sectors: healthcare
- Tools/products/workflows: Empirical-MCTS layer over guideline-based CDSS; memory of verified reasoning patterns across cases; uncertainty gating and multi-expert checks
- Assumptions/dependencies: rigorous validation and regulatory approval; integration with EHR; robust consistency/quality filters
- Autonomous robotics task planning with empirical memory
- Sectors: robotics, manufacturing, logistics
- Tools/products/workflows: planning agent that accumulates task-specific “experience atoms” (e.g., failure modes, success heuristics); meta-prompt evolves safety/efficiency rules
- Assumptions/dependencies: perception/action integration; safety certification; real-time constraints
- Multi-turn project and policy planning assistants
- Sectors: government, enterprise PMO, consulting
- Tools/products/workflows: long-horizon planners that persist memory across sessions; PE-EMP to evolve governance/feasibility criteria; cross-episode consistency checks
- Assumptions/dependencies: memory lifecycle governance; auditability; stakeholder sign-off and change controls
- Automated theorem proving and formal verification co‑pilot
- Sectors: academia, critical systems engineering
- Tools/products/workflows: proof search with PE-EMP evolving proof strategies; memory of lemmas and proof schemas; integration with formal checkers
- Assumptions/dependencies: reliable proof/constraint checkers; curated theorem libraries; high compute for deep search
- Policy drafting and evaluation workbench
- Sectors: public policy, compliance
- Tools/products/workflows: PE-EMP to generate explicit evaluative principles; preference-ranked draft alternatives; memory of precedents and impact heuristics
- Assumptions/dependencies: transparency, explainability, bias controls; public consultation workflows; legal review
- Continuous-learning financial research and risk analysis
- Sectors: finance
- Tools/products/workflows: analyst co‑pilot that evolves valuation/risk criteria; pairwise ranking of theses; memory of backtested patterns
- Assumptions/dependencies: data licenses; compliance; human-in-the-loop signoff; robust backtesting/guardrails
- General program synthesis for process automation (ARC-AGI style)
- Sectors: RPA, IT automation, embedded systems
- Tools/products/workflows: empirical accumulation of transformation/programming idioms across domains; PE-EMP to adapt synthesis criteria per task family
- Assumptions/dependencies: safe execution sandboxes; verifiable specs/test suites; domain adapters
- Federated or privacy-preserving experience marketplaces
- Sectors: cross-industry consortia, SaaS ecosystems
- Tools/products/workflows: shareable experience “primitives” learned across clients with differential privacy; Memory Agent supports federated add/merge updates
- Assumptions/dependencies: privacy tech (DP, secure aggregation); IP governance; standard task taxonomies
- Autonomous experimentation in R&D labs
- Sectors: materials, biotech, chemistry
- Tools/products/workflows: hypothesis generation and protocol design co‑pilot; memory of successful/failed experiment patterns; adaptive meta-prompts for experimental constraints
- Assumptions/dependencies: instrument integration; strict lab safety; data quality and reproducibility checks
- Safety-critical incident response automation (L2/L3)
- Sectors: cybersecurity, industrial ops
- Tools/products/workflows: Empirical-MCTS that crystallizes high-fidelity playbooks; PE-EMP to evolve detection/containment criteria; rigorous audit trails
- Assumptions/dependencies: certified detection pipelines; red team validation; escalation to human responders
- Platform-wide meta-judging and evaluation services
- Sectors: AI evaluation, marketplaces, model hubs
- Tools/products/workflows: PE-EMP-based judge with global ranking (EBC) for consistent pairwise evaluation across tasks; evolving cross-domain rubrics
- Assumptions/dependencies: calibration/benchmarking; bias mitigation; dispute resolution mechanisms
- Personalized curriculum engines for lifelong learning
- Sectors: education, corporate training
- Tools/products/workflows: long-horizon, multi-turn adaptation of teaching strategies; memory of learner-specific misconceptions and effective interventions
- Assumptions/dependencies: privacy-preserving learner models; pedagogy review; content alignment
Notes on feasibility across applications:
- The framework assumes base models can verify intermediate reasoning sufficiently; for high-stakes domains, add external verifiers, simulations, or human review.
- Retrieval quality and task taxonomy tagging materially affect outcomes; invest in domain ontologies and tagging pipelines.
- Memory curation (add/modify/merge/delete) should be governed like code or data: version control, audits, rollbacks.
- Cost/latency must be budgeted; MCTS rollouts can be tuned per task criticality.
- For regulated sectors, rigorous validation, monitoring for drift, and compliance approvals are prerequisites.
Glossary
- Adaptive branching: A tree search strategy that dynamically adjusts the number of children expanded per node based on context or utility. "AB-MCTS \cite{inoue2025wider} introduces adaptive branching"
- ARC-AGI-2: A benchmark derived from the Abstraction and Reasoning Corpus for evaluating general reasoning in AI systems. "Extensive evaluations on complex reasoning benchmarks, including AIME25, ARC-AGI-2, and MathArena Apex, demonstrate that Empirical-MCTS significantly outperforms both stateless MCTS strategies and standalone experience-driven agents."
- Bradley–Terry model: A probabilistic model for pairwise comparisons that converts scores into win probabilities. "We map the raw score vector from PE-EMP to a transition probability via the Bradley-Terry model: ."
- Chain-of-Thought: A step-by-step reasoning process used to explain or compare solutions. "Comparative Chain-of-Thought (Critique Phase): A step-by-step critical analysis is performed, contrasting the candidate and baseline responses against the generated criteria."
- Decay-based update rule: An exponential moving-average style backpropagation of value estimates in MCTS with a decay factor. "For value backpropagation, we adopt the decay-based update rule from Self-Refine MCTS \cite{zhang2024llamaberrypairwiseoptimizationo1like}: ."
- Enhanced Borda Count (EBC): An aggregation method extending Borda count to construct a global ranking from pairwise preferences. "To address the non-transitivity inherent in pairwise LLM preferences, we employ the Enhanced Borda Count (EBC) method \cite{zhang2024llamaberrypairwiseoptimizationo1like} to construct a global ranking from the pairwise transition graph."
- Empirical-MCTS: The paper’s dual-loop framework that couples MCTS with continuous, non-parametric experience accumulation and prompt evolution. "To bridge this gap, we introduce Empirical-MCTS, a dual-loop framework that transforms stateless search into a continuous, non-parametric learning process."
- Experience library: A persistent repository of distilled experiences used to guide future reasoning. "Systems like FLEX \cite{cai2025flexcontinuousagentevolution} maintain an experience library but treat retrieval and reasoning as separate steps, preventing the model from evolving its search strategy dynamically."
- Inference-time scaling: Improving model performance by allocating more compute at generation time rather than training time. "Inference-time scaling strategies, particularly Monte Carlo Tree Search (MCTS), have significantly enhanced the reasoning capabilities of LLMs."
- Memory Optimization Agent: A component that treats the experience repository as an optimizable policy prior and updates it via atomic operations. "Long-term Experience (Memory Optimization): To sustain learning across problems, we implement a Memory Optimization Agent."
- Meta-prompt (system prompt): High-level instructions that steer an LLM’s reasoning behavior across steps. "PE-EMP functions as a reflexive optimizer within the local search, utilizing pairwise feedback to dynamically synthesize adaptive criteria and evolve meta-prompts (system prompts) in real-time."
- Monte Carlo Tree Search (MCTS): A search algorithm that explores a decision tree by stochastic sampling and value propagation. "Inference-time scaling strategies, particularly Monte Carlo Tree Search (MCTS), have significantly enhanced the reasoning capabilities of LLMs."
- Non-parametric policy update: Adjusting the agent’s behavior through memory or context changes rather than modifying model weights. "Formally, this step represents a non-parametric policy update:"
- Non-transitivity: A property of preferences where pairwise comparisons can be cyclic and inconsistent globally. "By mapping the explicit 'self-principled' scores generated by PE-EMP into a globally consistent ranking via Enhanced Borda Count, we address the non-transitivity inherent in LLM preferences."
- Pairwise-Experience-Evolutionary Meta-Prompting (PE-EMP): A mechanism that uses pairwise comparisons to synthesize criteria, generate insights, and evolve system prompts during search. "Within the local search process, we introduce Pairwise-Experience-Evolutionary Meta-Prompting (PE-EMP)."
- Pairwise Preference Reward Model (PPRM): A reward modeling approach that uses pairwise comparisons to learn preferences over outputs. "To transform the discrete insights from PE-EMP into a continuous reward signal, we adapt the robust Pairwise Preference Reward Model (PPRM) architecture from LLaMA-Berry \cite{zhang2024llamaberrypairwiseoptimizationo1like}."
- Pareto frontier: The set of cost-performance trade-offs where no dimension can improve without degrading another. "Figure~\ref{fig:pareto_frontier_analysis} visualizes the Pareto frontier of reasoning efficiency."
- Policy prior (dynamic policy prior): A prior over actions or generation policies induced by stored experiences that bias future decisions. "Rather than a static retrieval database, our repository is treated as a dynamic policy prior."
- Proximal Policy Optimization (PPO): An on-policy reinforcement learning algorithm that stabilizes policy updates with clipping. "Training-Free GRPO posits that LLM agents can achieve alignment effects analogous to parametric reinforcement learning (e.g., PPO \cite{schulman2017proximalpolicyoptimizationalgorithms}) by iteratively refining experiential knowledge as a 'token prior' rather than updating model weights."
- RAG (Retrieval-Augmented Generation): A technique that retrieves external knowledge to condition and improve generation. "Building upon the prior experiences retrieved from the RAG repository, the model synthesizes the immediate feedback with historical wisdom."
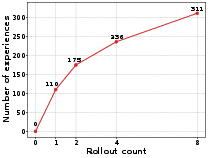
- Rollout: A complete simulated traversal or iteration in tree search used for evaluation and learning. "Starting from zero experiences at initialization, the repository grows monotonically with each rollout (110 311 experiences after 8 rollouts), demonstrating the framework's capacity for continuous knowledge accumulation without parameter updates."
- Self-Consistency: An inference-time approach that samples multiple solutions and selects the most consistent or frequent one. "Early methods, such as Self-Consistency \cite{wang2023selfconsistencyimproveschainthought}, generate multiple independent answers and select the most frequent one."
- Self-Principled Critique Tuning (SPCT): A method where models generate task-specific principles to guide critiques, improving reward estimation. "Drawing inspiration from the Self-Principled Critique Tuning (SPCT) framework proposed for inference-time scaling of generalist reward models \cite{liu2025inferencetimescalinggeneralistreward}, we introduce a unified mechanism termed Pairwise-Experience-Evolutionary Meta-Prompting (PE-EMP)."
- Tree of Thoughts (ToT): A reasoning framework that structures problem solving as a tree of intermediate thoughts and decisions. "To handle more complex tasks, tree-search algorithms like Tree of Thoughts (ToT) \cite{NEURIPS2023_271db992} and MCTS applied to LLMs \cite{zhou2024languageagenttreesearch,...} were developed to structure the reasoning process into steps."
- Upper Confidence Bound (UCB) applied to Trees: A selection strategy balancing exploration and exploitation in MCTS by using confidence bounds. "We employ a standard Upper Confidence Bound (UCB) applied to Trees for node selection."
- Value backpropagation: The process of propagating estimated values from child nodes back up to their ancestors in a search tree. "For value backpropagation, we adopt the decay-based update rule from Self-Refine MCTS \cite{zhang2024llamaberrypairwiseoptimizationo1like}: ."
- Zero-shot classification: Classifying inputs into categories without task-specific training, often via prompting. "Only experiences sharing the same task type as (determined via zero-shot classification with the base LLM) are included in ."
Collections
Sign up for free to add this paper to one or more collections.

