- The paper introduces MetaStone-S1, a reflective generative model that unifies the policy and process reward models to enable label-free test-time scaling.
- It employs a self-supervised process reward model (SPRM) with a shared backbone to select optimal reasoning trajectories without extensive annotations.
- Experiments on mathematical and out-of-distribution benchmarks demonstrate competitive performance and reveal insightful scaling laws for reflective models.
Test-Time Scaling with Reflective Generative Models
This paper introduces MetaStone-S1, a reflective generative model designed for efficient high-quality reasoning trajectory selection during test-time scaling (TTS). The core innovation lies in a novel Reflective Generative Form that unifies the policy model and process reward model (PRM), coupled with a self-supervised training approach to eliminate the need for process-level annotations. MetaStone-S1 demonstrates performance comparable to OpenAI's o3-mini series with a 32B parameter model.
The paper begins by categorizing TTS approaches into internal and external methods. Internal TTS, exemplified by models like DeepSeek R1, extends the Chain-of-Thought (CoT) process, while external TTS, such as Best-of-N sampling, employs a PRM to score and select the optimal reasoning trajectory. The Reflective Generative Form addresses limitations of external TTS, specifically the computational overhead of separate PRMs and the need for extensive annotations.
The proposed form shares the backbone network between the policy model and the PRM, enabling joint training and reducing parameter redundancy. A self-supervised process reward model (SPRM) is introduced to learn high-quality reasoning trajectory selection from outcome rewards, removing the reliance on process-level annotations. The inference process involves generating multiple reasoning trajectories, scoring them using the SPRM, and selecting the highest-scoring trajectory to guide the final answer generation. This is shown in the Reflective Generative Form equation:
$\text{answer} =
\underbrace{LLM_{\text{answer}_{\text{share backbone}
\Big(
\underset{i \in [1,k]}{\arg\max} \;
\underbrace{LLM_{SPRM}_{\text{share backbone}
\Big( [\underbrace{LLM_{\text{thinking}_{\text{share backbone}(\text{query})]_i \Big)
\Big)
\end{equation}
(Figure 2)
*Figure 2: The training and inference framework of Reflective Generative Models.*
## Implementation Details
The unified interface for the policy model and PRM is implemented by using reasoning LLMs delineated by '<think>' and '</think>' tokens. The SPRM shares the backbone with the policy model and includes a lightweight SPRM head consisting of two linear layers and a dropout layer. The reasoning trajectory is segmented into discrete steps using existing tokens in the policy model's tokenizer. The hidden representations from the second-to-last layer of the policy model are fed into the SPRM head to predict process scores for each step, and the final trajectory score is computed as the geometric mean of the individual step scores.
During optimization, the policy model is trained using Group Relative Policy Optimization (GRPO). The SPRM head is optimized using a Self-supervised Process Reward Loss (SPR Loss), which enables learning process discrimination only from outcome reward. The SPR Loss is formulated as:$\mathcal{L}{\text{SPR} = \frac{1}{N}\sum{i=1}{N} w_i * BCELoss(\text{Score}{i},y_i), \quad
\text{where} \ w{i} =
\begin{cases}
1, & \text{if} \ y_i=1 \ {content} \ \text{Score}{i}>0.5 \
1, & \text{if} \ y_i=0 \ {content} \ \text{Score}{i}<0.5 \
0, & \text{others}
\end{cases} mitigates supervision noise by using the SPRM head's own prediction as a pseudo-label.
Experimental Results
The proposed models, MetaStone-S1-1.5B, 7B, and 32B, are initialized from DeepSeek-R1-Distill-Qwen-1.5B/7B and QWQ-32B, respectively. The training dataset comprises publicly available math-related sources, resulting in 40k high-quality examples. The models are evaluated on mathematical benchmarks (AIME2024 and AIME2025) and out-of-distribution benchmarks (LivecodeBench and C-Eval). The results demonstrate that the Reflective Generative Form consistently enhances the baseline, particularly on mathematical reasoning benchmarks.
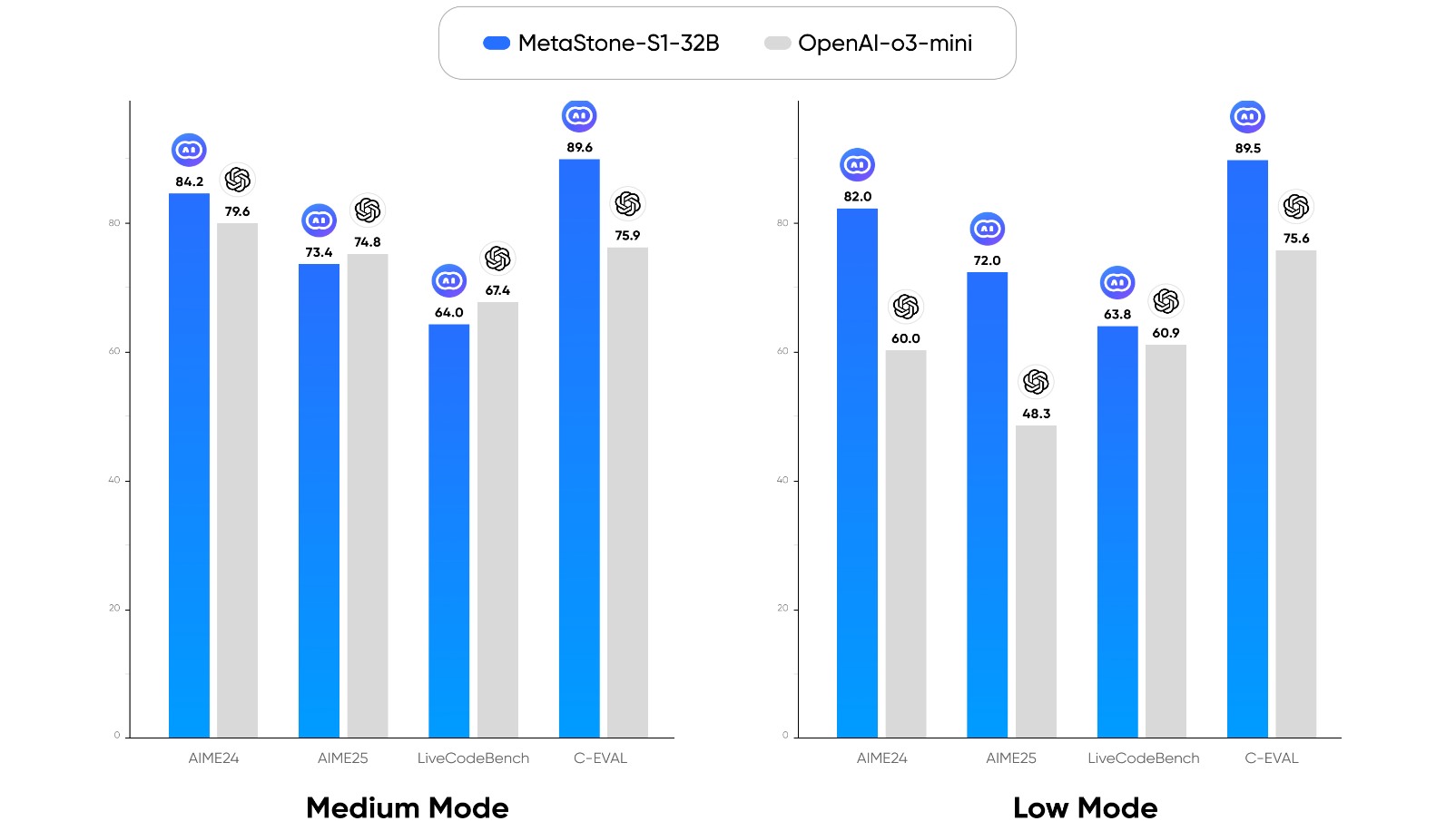
Figure 1: Benchmark performance of MetaStone-S1.
The paper also presents a scaling law for reflective generative models, showing a positive correlation between performance and the logarithm of the computation budget, defined as the product of model parameters and reasoning tokens (Figure 2).
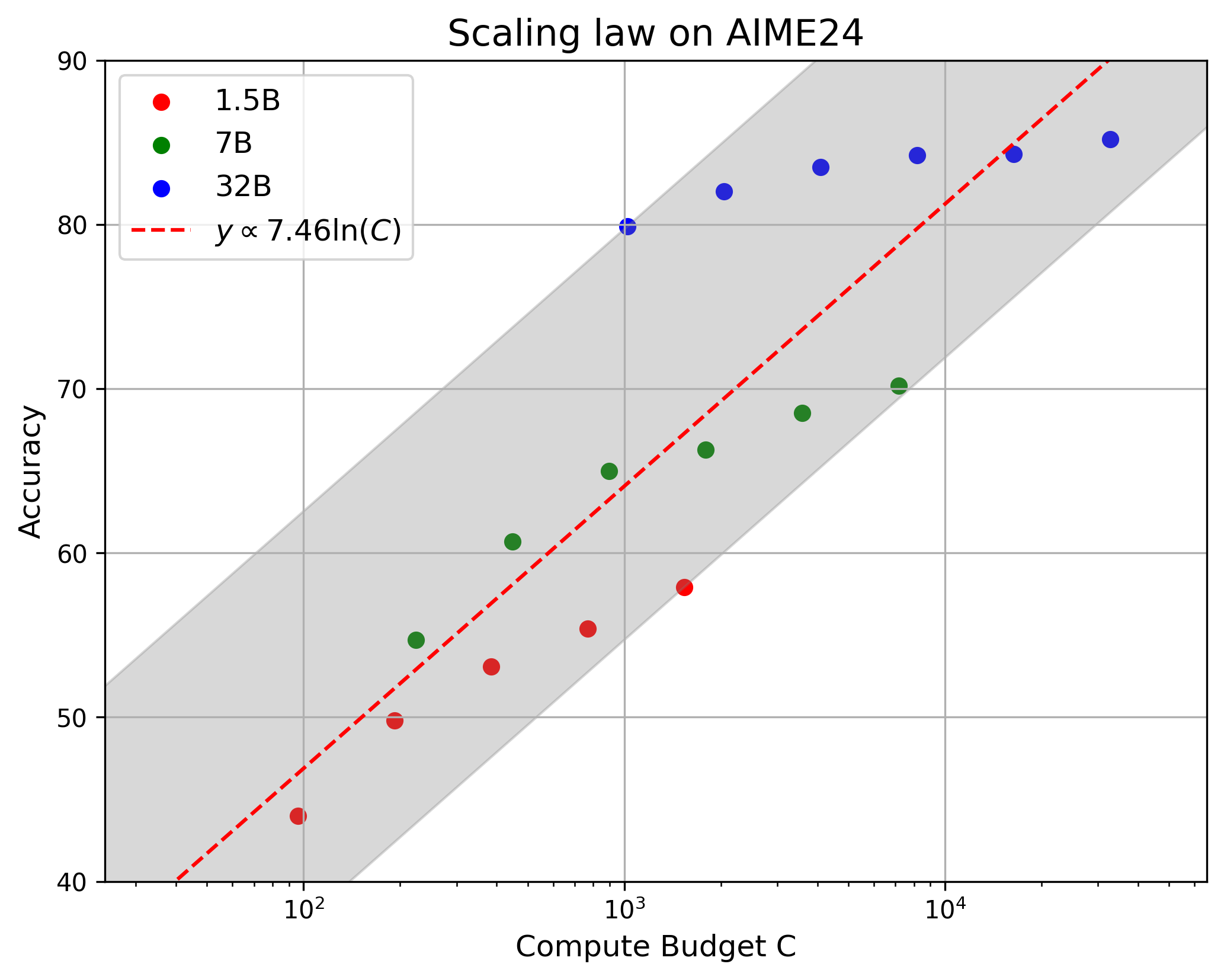
Figure 2: The scaling law of Reflective Generative Models.
The "aha moment" phenomenon is observed during training, where the optimization trends of correct and incorrect reasoning trajectories begin to diverge, indicating that the model is learning to discriminate based on reasoning content (Figure 3).
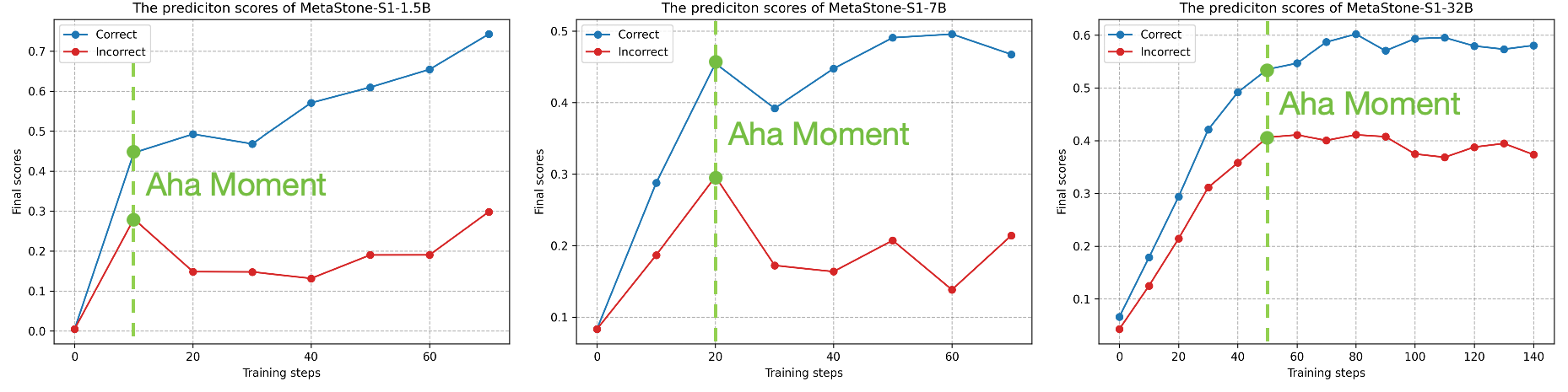
Figure 3: The training process of SPRM. The blue and red curves denote the final score on correct and incorrect reasoning trajectories. The green dashed line indicates the "aha moment".
Further ablation studies demonstrate the effectiveness of the SPRM and the self-supervised optimization approach. The SPRM achieves higher performance with fewer parameters compared to larger outcome reward models (ORMs) and PRMs, and the SPRLoss demonstrates stronger discriminative capability with a larger score gap between correct and incorrect solutions.

Figure 4: Comparison of SPRM's predictions before and after the aha moment. Only key steps are listed. The error steps are marked in red.
MCTS Extension
The paper explores extending the Reflective Generative Form with Monte Carlo Tree Search (MCTS), using SPRM to estimate node values during the search. Results show improved performance with increasing numbers of searching tokens, validating the potential for integration with advanced search-based inference methods.
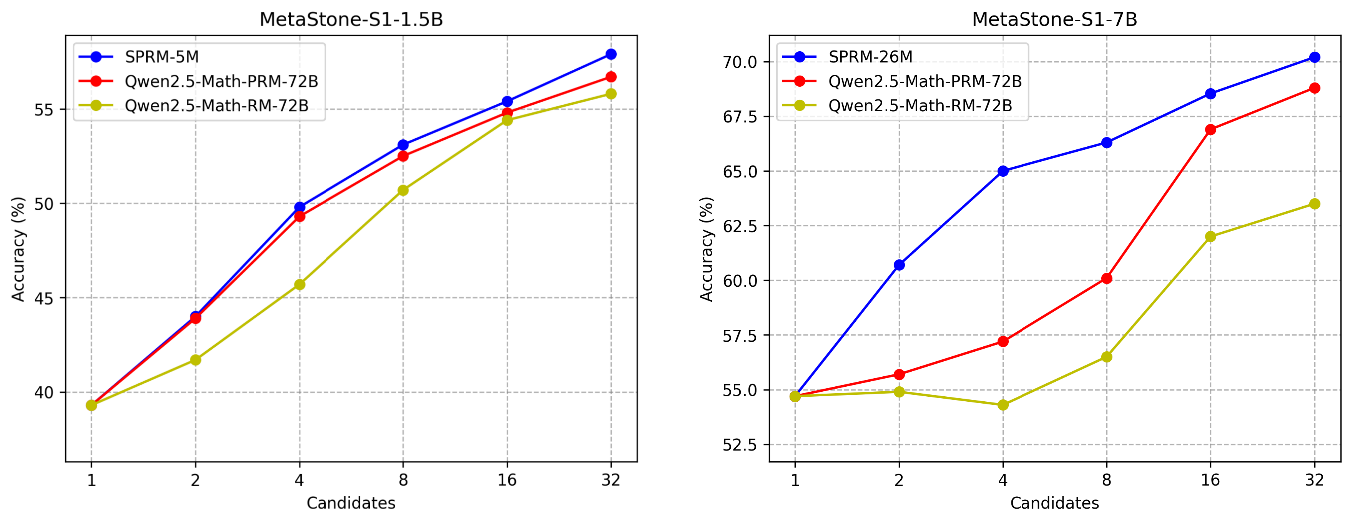
Figure 5: Evaluation of varying numbers of candidate reasoning trajectories on AIME24.

Figure 6: SPRM's predictions on reasoning trajectories. Only key steps are listed. Correct and error steps are marked in green and red.
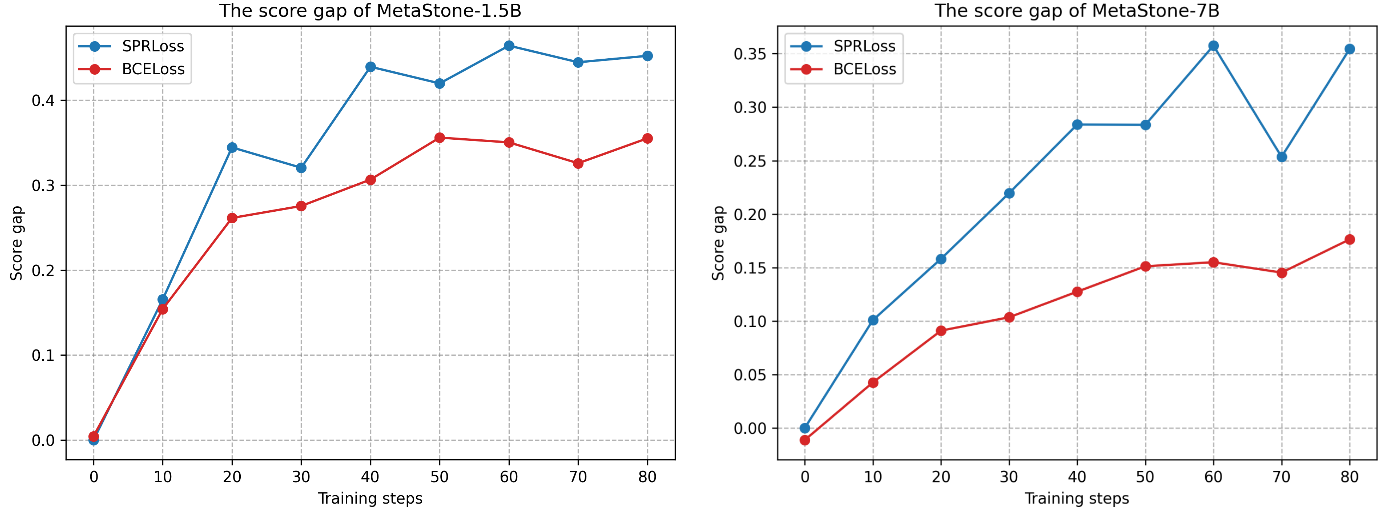
Figure 7: The prediction score gap between correct and incorrect solutions. The blue curve shows the SPRLoss. The red curve shows the BCELoss.
Conclusion
This paper introduces a novel Reflective Generative Form for efficient and label-free reasoning trajectory selection in LLMs. MetaStone-S1 achieves competitive performance on various benchmarks, demonstrating the effectiveness of the unified policy model and PRM architecture, as well as the self-supervised training approach. The analyses of the "aha moment" and scaling law provide valuable insights into the behavior of reflective generative models. Future work may explore more efficient step-level search-based TTS methods for real-time reasoning enhancement.