- The paper presents SandMLE, a synthetic sandbox that reduces per-step execution time from 200 to under 15 seconds, enabling trajectory-wise reinforcement learning in MLE.
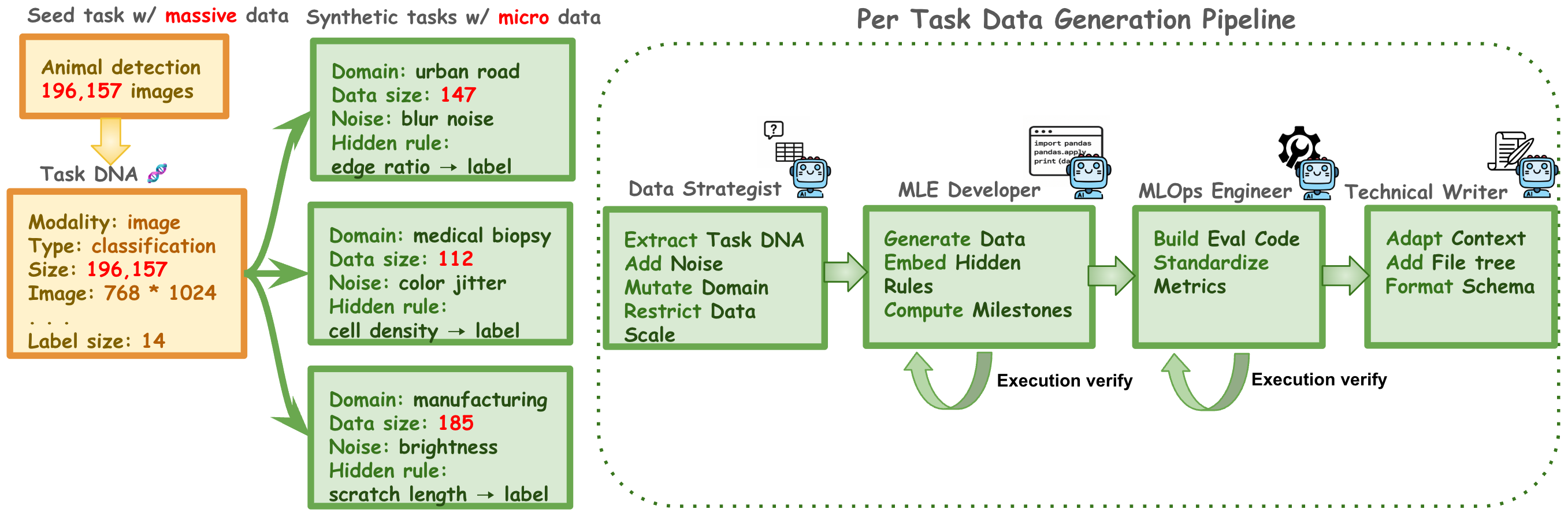
- The paper details a multi-agent pipeline that extracts structural task DNA and generates diverse micro-scale synthetic environments with robust evaluation metrics.
- The paper demonstrates substantial performance improvements across model scales, with up to 66.9% gains over SFT baselines and enhanced generalization on MLE tasks.
Synthetic Sandbox for Training Machine Learning Engineering Agents: An Expert Summary
Motivation and Challenge in MLE-Agent Optimization
The proliferation of LLM agents in machine learning engineering (MLE) tasks is accompanied by a persistent challenge: verifiable reward signals necessitate longitudinal execution of full ML pipelines on large datasets, resulting in excessive rollout latency. Unlike SWE tasks—verifiable within seconds via unit tests—MLE tasks demand iterative code generation, model training, and metric evaluation, with single code executions averaging nearly 200 seconds on standard datasets. This latency renders trajectory-wise on-policy RL, particularly with algorithms like GRPO, computationally intractable, relegating prior approaches to SFT or step-wise RL with proxy rewards, and forfeiting benefits in exploration and generalization.
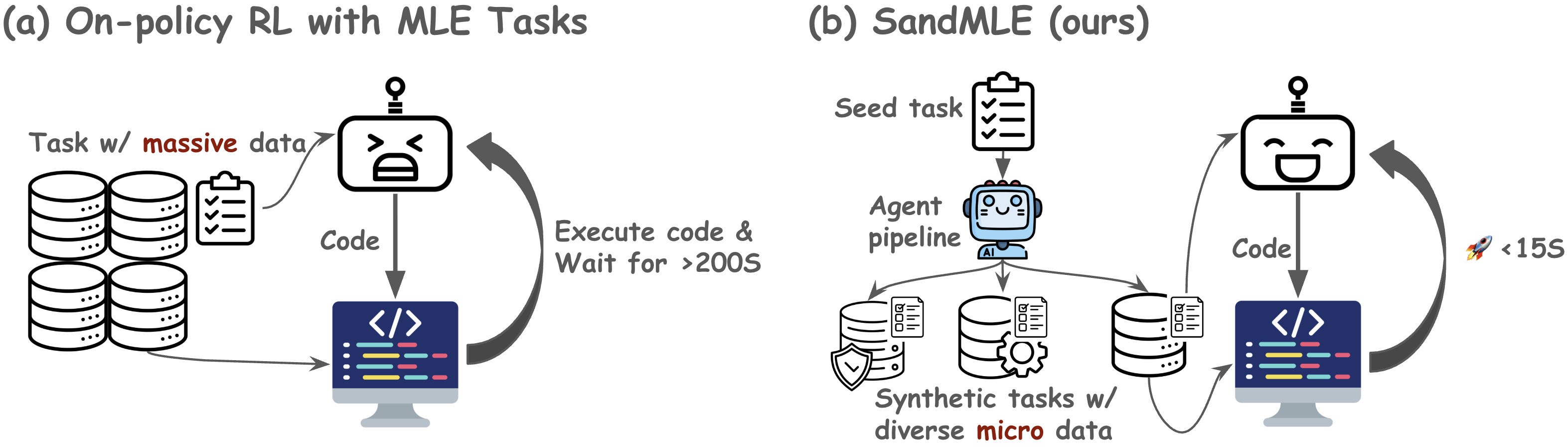
Figure 1: Standard on-policy RL for MLE is bottlenecked by execution latency; SandMLE enables practical trajectory-wise RL by transforming real tasks into micro-scale environments.
SandMLE Framework and Synthetic Environment Generation
SandMLE operationalizes a paradigm shift by constraining datasets for synthetic tasks to a micro-scale regime (50-200 samples), effectively reducing per-step execution time from over 200 seconds to under 15 seconds. The multi-agent pipeline extracts and amplifies structural task DNA from seed tasks, generates procedurally verifiable synthetic environments, and maintains fidelity in structural and technical complexity. This enables thousands of on-policy rollout updates within feasible wall-clock constraints.
The pipeline orchestrates specialized agent roles:
SandMLE enables computationally feasible, trajectory-wise RL for MLE agents. Rollouts leverage the ReAct framework, supporting multi-turn action-observation exchanges. To address reward sparsity, SandMLE deploys a dense, milestone-based reward function. Formative rewards account for both format compliance and progressive milestone achievements (valid output generation, execution, and tiered performance thresholds), facilitating effective credit assignment and stable policy optimization. This hierarchical reward design is empirically validated: ablation against sparse reward regimes confirms the necessity for granular feedback to stabilize learning and enable meaningful exploration in high-dimensional agentic spaces.
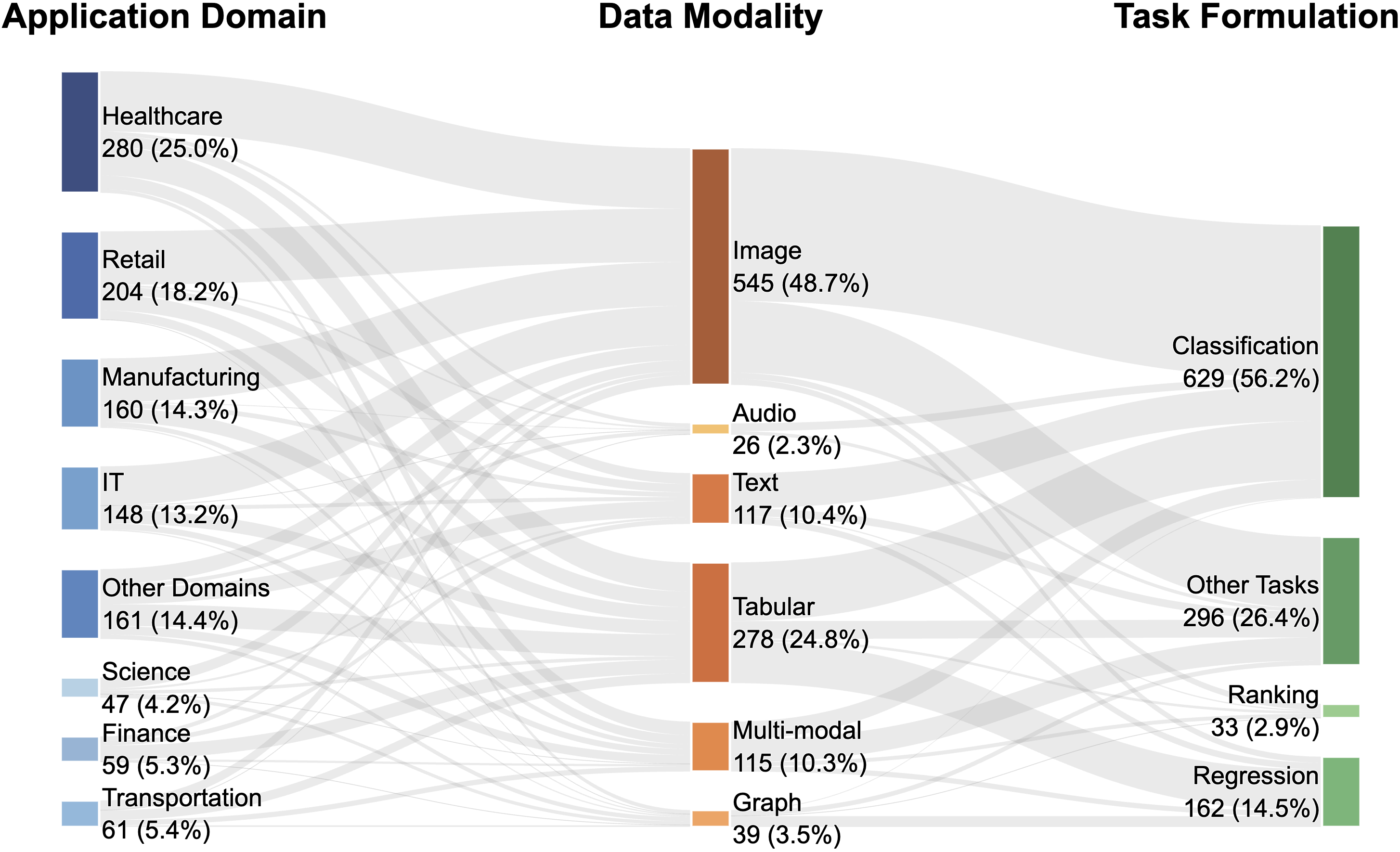
Statistical Characterization of Synthetic Training Data
From 60 seed tasks, the pipeline generates 848 synthetic training tasks (with 64 held out), spanning diverse domains and modalities:
Reliability filtering and calibration ensure synthetic tasks are non-trivial, properly separated by model capability, and challenging enough to serve as a robust training signal. Dataset sizes are intentionally constrained—majority between 120 and 150 samples per task—enabling throughput amplification.
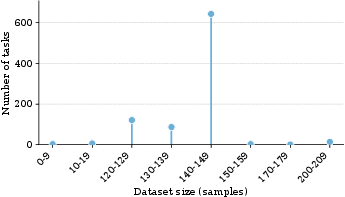
Figure 4: Dataset size distribution reveals synthetic tasks clustered within the micro-scale regime critical for RL feasibility.
SandMLE demonstrates strong operational performance across three Qwen3 model scales (8B, 14B, 30B-A3B), achieving:
- Any Medal Rate Improvements: 20.3% to 66.9% relative gains over SFT baselines.
- Valid Submission Scaling: For pure SandMLE, from 63.6% (8B) to 100% (30B).
- Generalization: Up to 32.4% improvement in HumanRank score on MLE-Dojo; robust transfer across alternative agentic scaffolds (ReAct, AIRA, AIDE, MLE-Agent).
SandMLE models approach or surpass the performance of larger closed-source baselines (Deepseek-V3.1, Gemini-2.5-flash, Claude-4.5-Sonnet), and operational robustness is further enhanced when initializing GRPO from Seed-SFT checkpoints (SFT-SandMLE). Test-time scaling reveals sustained improvement across increased interaction turns—performance peaks at context length limits, beyond which bottlenecks emerge.
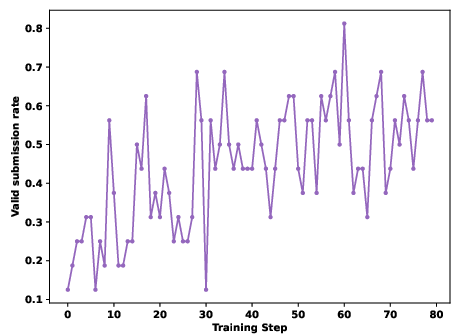
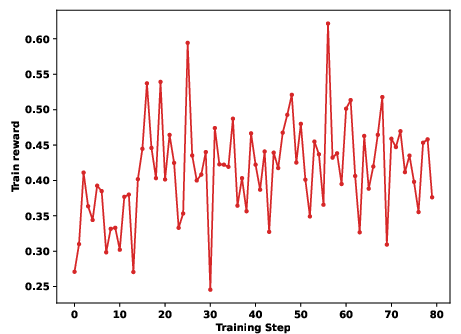
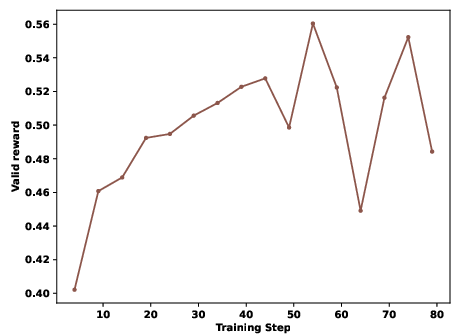
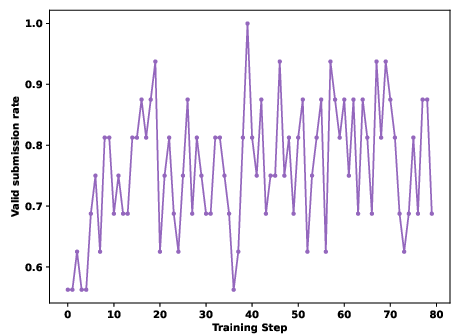
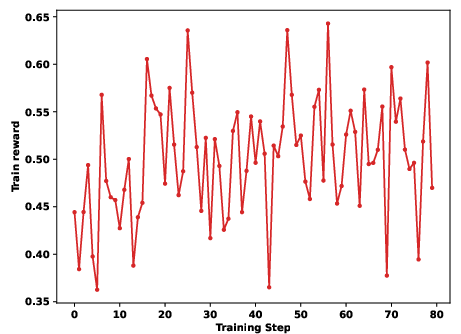
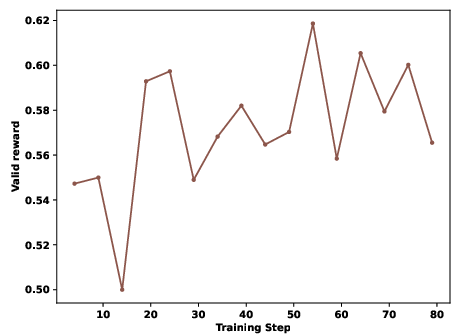
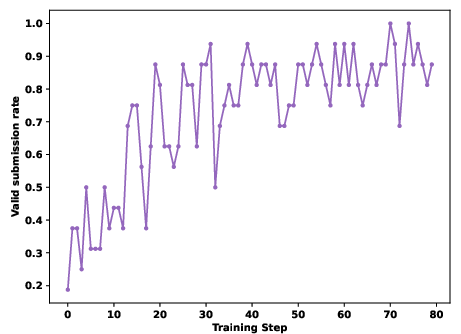
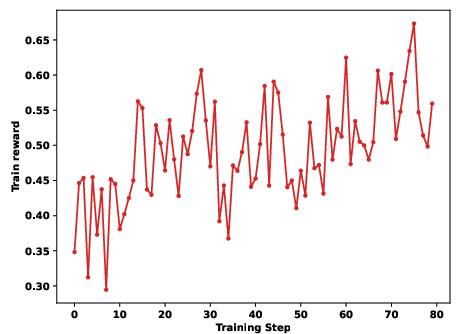
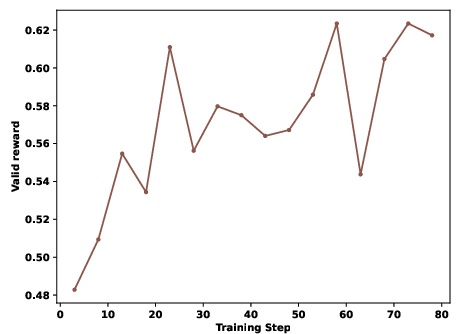
Figure 5: Qwen3-8B Valid Submission Rate during RL reveals superior learning dynamics with SandMLE.
Implications and Future Directions
SandMLE operationalizes scalable, on-policy RL for MLE agents by leveraging synthetic, micro-scale task environments as proxies for real-world tasks. This approach enables intrinsic, framework-agnostic improvement in engineering reasoning, supplementing scaffold-based test-time gains. The hierarchical reward landscape is critical for stabilizing optimization, supporting efficient credit assignment, and scaffolding progression toward state-of-the-art engineering competencies.
Practically, SandMLE offers a path toward scalable training of generalist MLE agents that improve through direct environment interaction rather than imitation. Theoretically, it uncovers avenues for procedural environment generation, reward densification, and domain amplification as core levers for advancing agentic intelligence. The synthetic sandbox paradigm can be extended to other agentic and long-horizon domains where real-world latency precludes large-scale RL.
Conclusion
SandMLE makes trajectory-wise RL feasible in the MLE domain by creating diverse synthetic environments with micro-scale datasets. The framework achieves substantial reductions in execution latency, enables dense reward-driven optimization, and delivers robust improvements in medal rate and generalization across scaffolds and domains. This synthetic sandbox paradigm represents a scalable methodology for training LLM agents capable of complex engineering reasoning, proposing future developments in procedural environment synthesis, scalable reward assignment, and long-horizon agentic learning (2604.04872).