SWE-Universe: Scale Real-World Verifiable Environments to Millions
Abstract: We propose SWE-Universe, a scalable and efficient framework for automatically constructing real-world software engineering (SWE) verifiable environments from GitHub pull requests (PRs). To overcome the prevalent challenges of automatic building, such as low production yield, weak verifiers, and prohibitive cost, our framework utilizes a building agent powered by an efficient custom-trained model. This agent employs iterative self-verification and in-loop hacking detection to ensure the reliable generation of high-fidelity, verifiable tasks. Using this method, we scale the number of real-world multilingual SWE environments to a million scale (807,693). We demonstrate the profound value of our environments through large-scale agentic mid-training and reinforcement learning. Finally, we applied this technique to Qwen3-Max-Thinking and achieved a score of 75.3% on SWE-Bench Verified. Our work provides both a critical resource and a robust methodology to advance the next generation of coding agents.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
SWE‑Universe: A simple explanation
What is this paper about?
This paper is about building a huge, real, and reliable “practice world” for AI coding assistants. The authors created a framework called SWE‑Universe that automatically turns GitHub pull requests (PRs) into small, self-contained coding tasks that a computer can try to solve—each with a clear way to check if the solution actually works. They scaled this up to over 800,000 tasks across many programming languages.
What questions are the researchers trying to answer?
The team wanted to know how to:
- Collect tons of real coding problems from the wild (GitHub) and turn them into tasks that actually run.
- Make sure each task has a trustworthy “referee” (a test script) that checks whether a fix is really correct, not just faked.
- Do all of this fast and cheaply, so it can work at massive scale.
How did they do it? (Methods in everyday language)
Think of each GitHub PR as a “before and after” story:
- “Before” = the code with a bug.
- “After” = the code after a developer’s fix.
- Often, the PR also includes tests that show the bug is gone.
The authors’ system turns each PR into a small training gym for AI:
- Finding the right PRs
- They search GitHub for PRs that link to issues (the problem description) and include tests.
- They split the PR into a “test part” (what to run to check correctness) and a “fix part” (the code change).
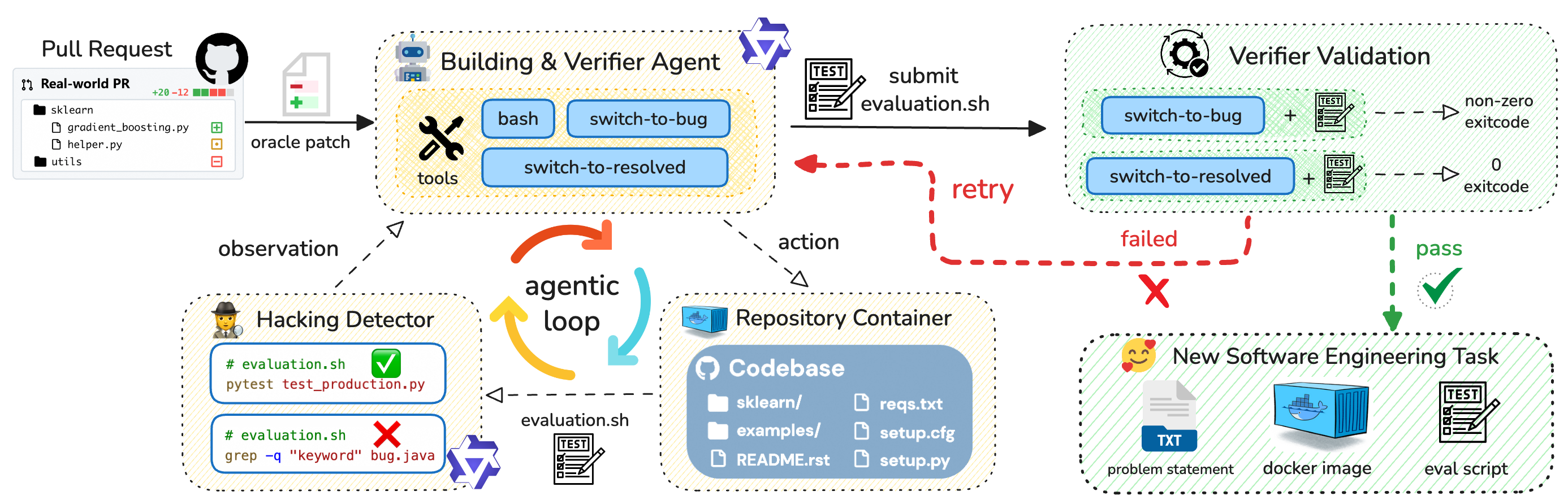
- Building a verifiable task
- An AI “building agent” creates a standard test script called evaluation.sh. This script is like a referee: it runs the code and returns:
- 0 (success) if the fixed code works,
- non‑zero (failure) if the buggy code fails.
- The agent can either run existing tests (like pytest or Jest) or write a small new test when needed.
- An AI “building agent” creates a standard test script called evaluation.sh. This script is like a referee: it runs the code and returns:
- Trying, checking, and trying again (Iterative Validation)
- The agent flips the code between “buggy” and “fixed” states (like a light switch) and runs the script in both states.
- The script only counts as good if it fails on the buggy code and passes on the fixed code.
- If it doesn’t, the agent adjusts the setup and tries again. This loop boosts reliability a lot.
- Catching cheats (In‑loop Hacking Detector)
- Some scripts might try to “cheat,” for example by using simple text searches (like grep) to spot the fix instead of actually running tests.
- A built‑in “cheat detector” flags and rejects these shortcuts right away, forcing the agent to produce real, executable tests.
- Doing this at scale and speed
- They trained a fast, efficient AI model (called Qwen‑Next‑80A3) to power the building agent. You can think of it like a “team of specialists” (a Mixture‑of‑Experts model) that chooses the right expert for each job, making the process both strong and efficient.
- They deployed the system across many machines in the cloud, packaged results in Docker (so tasks run the same everywhere), and ran millions of builds in parallel.
- Measuring quality (Benchmark and Quality Judge)
- They built a benchmark to test how well different models create valid tasks across languages (Python, JS/TS, Java, Go, Rust, C/C++, C#, etc.).
- They also built a “quality judge” agent to rate task quality and filter out confusing or unreliable ones.
What did they find, and why does it matter?
Here are the main results and their importance:
- Massive scale, real data
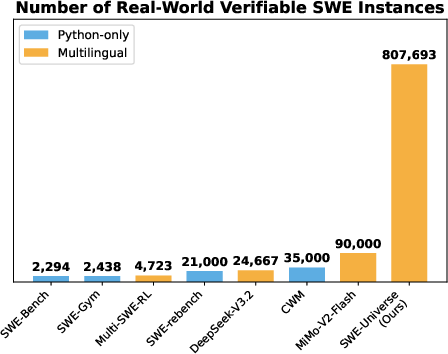
- They built 807,693 runnable, verifiable tasks from 52,960 GitHub repositories, covering many languages—not just Python. This is far larger and more diverse than prior datasets.
- Why it matters: AI coding assistants learn better when trained on lots of real, varied problems.
- Stronger, more reliable building
- Their iterative validation raised environment build success from 82.6% to 94% on a test set.
- Their cheat detector stopped fake “tests” that don’t actually run the code.
- Their builder model (Qwen‑Next‑80A3) achieved the highest “non‑cheating” success rate (78.44%) on their benchmark, outperforming strong competitors.
- Why it matters: Reliable tests prevent AI from learning bad habits and make evaluations trustworthy.
- Better training for coding AIs
- Mid‑training (continued training on the new data) improved performance on well-known benchmarks:
- On SWE‑Bench Verified, scores climbed from about 50% to over 61% during training.
- On a multilingual version, scores jumped from ~31% to over 46%.
- Reinforcement learning (RL) with these tasks gave another big boost:
- A 30B model improved from ~32% to 42% on SWE‑Bench Multilingual.
- Their top model (Qwen3‑Max‑Thinking) reached 75.3% on SWE‑Bench Verified.
- Why it matters: These gains show the dataset provides clean, strong feedback that helps AI agents actually get better at real-world coding.
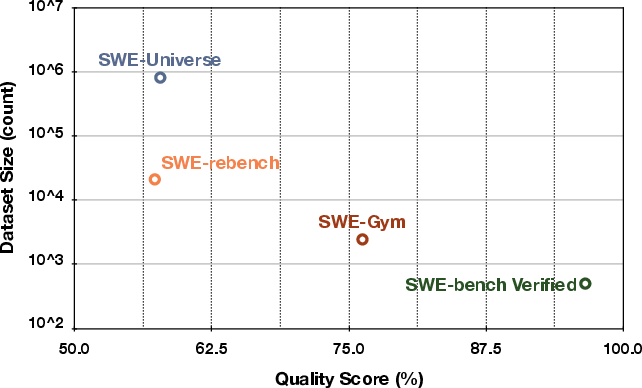
- High quality at large size
- A “quality judge” agent reached ~78.7% accuracy in checking task quality, and the dataset’s overall quality matches smaller, well-known datasets—even though this one is much bigger.
- Why it matters: You get both breadth and reliability, which is rare.
What’s the bigger impact?
- More capable coding assistants
- Because the tasks are real and span many languages, future AI coding tools can generalize better and handle more varied projects.
- Fairer, safer evaluation
- With robust “referee” scripts that truly run code, researchers can trust pass/fail signals and avoid misleading shortcuts.
- Faster progress for AI + software engineering
- A huge, verifiable training ground accelerates research in both supervised learning and RL for coding agents.
- The efficient, low-cost pipeline means others can build and iterate at scale.
In short, SWE‑Universe provides both the “stadium” (millions of realistic, runnable tasks) and the “referees” (reliable tests) that AI coding agents need to practice, improve, and be measured fairly—pushing the field toward smarter, more trustworthy coding tools.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, written to be concrete and actionable for future work:
- Dataset availability and reproducibility: The paper does not specify whether the 807,693 environments, Docker images, and evaluation scripts will be publicly released (with licensing) or reproducible outside Alibaba Cloud ACR. Action: Clarify release plans, licensing, and provide reproducible build artifacts and registry mirrors for non-Alibaba users.
- Verifier robustness criteria lack formalization: “Genuine execution” is enforced via an LLM-based hacking detector, but no formal, reproducible criteria are defined. Action: Specify rule-based constraints (e.g., mandatory compile and test execution, banned commands, allowed paths) and publish a standardized static/dynamic policy for verifier validation.
- Hacking detector reliability and coverage: The LLM detector’s false-positive/false-negative rates are unreported, and evasive patterns beyond grep (e.g., calling
switch-to-resolvedfrom evaluation.sh, git-diff checks, stubbing/mocking to force success) are not quantified. Action: Build a labeled corpus of hack patterns, benchmark the detector, and introduce runtime guards (sandbox policies, syscall auditing) to block common evasion classes. - Evaluation.sh permissiveness: It is unclear whether evaluation.sh is permitted to mutate repo state (e.g., toggling patches or editing tests). Action: Enforce a strict contract on evaluation.sh forbidding state toggling and write operations outside test artifacts; verify via filesystem change auditing.
- Lack of test coverage guarantees: There is no measurement ensuring verifiers execute the modified code paths (e.g., line/branch coverage of changed files). Action: Incorporate coverage tooling and require minimum coverage thresholds on lines touched by the fix patch.
- Flakiness and nondeterminism: The paper does not analyze test stability across reruns, machines, time, or network conditions. Action: Track flakiness rates, enforce hermetic builds (no external network), pin seeds and dependencies, and re-run verifiers multiple times to certify determinism.
- Patch-splitting accuracy: The LLM-based split of test vs. fix patches lacks error-rate estimates across languages and repository structures. Action: Provide a gold-standard benchmark for patch splitting, report accuracy by language/toolchain, and publish failure cases and fallbacks.
- Bias from discarding PRs without test changes: Rejecting PRs without a discernible test patch may skew the dataset toward projects with strong testing cultures, reducing representativeness of “real” maintenance workflows. Action: Quantify how filtering changes language/project distributions and introduce methods to synthesize high-quality verifiers for PRs lacking tests.
- Quality-judge agent validity: With 78.72% accuracy, this filter may admit or reject many tasks incorrectly, and its criteria are not fully defined. Action: Publish the rubric, per-language accuracy, confusion analysis, and human validation at scale; consider multi-judge consensus or hybrid rule+LLM adjudication.
- Sparse binary reward design for RL: The pass/fail signal is binary and may be sparse, yet no ablation on shaping (e.g., intermediate compile success, partial test pass) is provided. Action: Evaluate multi-signal reward shaping and its impact on RL sample efficiency and generalization.
- Data contamination controls with downstream benchmarks: Overlap filtering is claimed but not operationalized (no method for dedup across repos/issues/tests). Action: Release a transparent contamination audit pipeline that detects overlap via hashes, commit IDs, issue IDs, and test signatures.
- Cost, throughput, and energy metrics: Efficiency claims lack quantitative measures (cost per build, time per environment, energy/carbon). Action: Report standardized cost/latency/energy metrics for the pipeline and compare against baselines on identical hardware.
- Security, safety, and licensing: Running arbitrary PR code in cloud VMs poses supply-chain and security risks; licensing and redistribution of derived Docker images are unaddressed. Action: Document sandboxing, scanning (SBOM, CVE checks), license compliance, and responsible release policies.
- Long-term reproducibility and bitrot: The paper does not address dependency pinning, image longevity, or re-buildability as ecosystems evolve. Action: Pin dependencies, version base images, implement periodic rebuilds, and publish reproducibility checks over time.
- Cross-platform and OS coverage: The pipeline appears Linux/bash-centric; Windows/macOS build ecosystems are not evaluated. Action: Extend to multi-OS environments, measure success rates, and adapt tools for platform-specific builds (e.g., MSBuild, Xcode).
- Language/toolchain granularity: “Others” aggregates many ecosystems; the per-language difficulty and failure modes (e.g., Swift, Kotlin, PHP, Ruby) are not analyzed. Action: Provide fine-grained language-level breakdowns and tailor build heuristics per ecosystem.
- Verifier semantics limited to exit codes: Non-functional requirements (performance, memory, concurrency, latency) and partial credit (subset of tests pass) are unsupported. Action: Expand verifier semantics to capture non-functional metrics and weighted test outcomes.
- Component ablations are missing: The impact of iterative validation vs. hacking detector vs. model choice is not isolated with controlled experiments. Action: Run ablations by toggling components and report deltas in yield, quality, and build time per language.
- Scale-up failure analysis: ~24% of candidates fail to become non-hacked environments at scale, but causes and remedies are not detailed. Action: Categorize failures (dependency resolution, timeouts, missing build entry points, flakiness) and prioritize targeted fixes.
- LLM-generated custom tests vs. existing tests: The fraction of environments relying on newly authored tests (and their correctness/brittleness) is unknown. Action: Measure proportions, validate generated tests with human review, and assess stability and coverage.
- Benchmark representativeness and size: The 320-PR benchmark may be too small for robust cross-language conclusions; selection criteria and public release are not detailed. Action: Expand and release the benchmark with stratified sampling, ground-truth annotations, and reproducible harnesses.
- RL filtering of “too easy/too hard” tasks: Pre-filtering may bias training and evaluation results; criteria and effects are not reported. Action: Describe filtering thresholds, analyze bias, and compare RL performance with/without filtering.
- Generalization beyond the pipeline’s verifier style: Gains may overfit to evaluation.sh conventions rather than true task solving across unseen evaluation protocols. Action: Evaluate models on benchmarks with different verification paradigms (native CI, maintainers’ tests) and measure transfer.
- Ethical and governance considerations: The paper does not discuss notifications to maintainers/contributors, consent, or governance for large-scale PR mining. Action: Define ethical guidelines and governance for data curation from public repos, including opt-outs.
Glossary
- Agentic reinforcement learning: Reinforcement learning applied to interactive coding agents, where an agent receives a reward (e.g., pass/fail from tests) while iteratively acting in an environment. "agentic reinforcement learning"
- Agentic scaffold: A prebuilt framework that equips an LLM with tools and interaction patterns to operate as a coding agent. "agentic scaffolds"
- Agentic trajectory: A sequence of agent interactions (observations, tool uses, actions) collected during task rollouts, often used as training data. "agentic trajectories"
- Asynchronous RL framework: A reinforcement learning system that collects and processes experience in parallel and out of lockstep to accelerate multi-turn agent training. "asynchronous RL framework"
- Best-Fit packing: A batching technique for long-context training that packs variable-length sequences into fixed-size blocks to maximize utilization. "Best-Fit packing"
- Coding world model: An internalized representation learned by a model about codebases, tools, and interactions that aids planning and problem-solving. "``coding world model''"
- Container Registry (ACR): A cloud service for storing and managing Docker images (here, Alibaba Cloud’s registry). "Container Registry (ACR)"
- Docker layer caching: A mechanism to reuse prebuilt Docker image layers to reduce storage and rebuild time. "Docker's layer caching"
- Elastic Compute Service (ECS): Alibaba Cloud’s virtual machine service used to run isolated build jobs at scale. "Elastic Compute Service (ECS)"
- gym: In RL, a task environment exposing a standardized interface for agents to interact with and learn from. "``gym''"
- Hacking Detector: An in-loop module that flags verification scripts that “cheat” (e.g., grep-based checks) instead of executing code/tests. "Hacking Detector"
- Hybrid attentions: A model architecture that combines different attention mechanisms (e.g., linear and full attention) to balance efficiency and capacity. "hybrid attentions including linear attentions and full attentions"
- Iterative self-verification: The process where an agent repeatedly tests its own verifier on buggy vs. fixed states to diagnose and correct failures. "iterative self-verification"
- Iterative validation loop: A repeated cycle of generating, executing, and revising the evaluation script until it reliably distinguishes buggy and fixed states. "iterative validation loop"
- Mid-training: An intermediate training stage between pretraining and downstream finetuning that adapts a model using large-scale agent interaction data. "``mid-training'' phase"
- Mixture-of-Experts (MoE): A neural architecture that routes inputs to specialized expert subnetworks to increase capacity without proportional compute cost. "mixture-of-experts (MoE) model"
- Rejection sampling: A data curation method that samples multiple candidates (e.g., build plans or trajectories) and retains only those meeting quality criteria. "rejection sampling"
- State-switching tools: Utilities that atomically toggle a repository between buggy and fixed states to enable self-testing of verifiers. "state-switching tools"
- Verifiable environment: A coding task setup that includes an executable checker providing a reliable pass/fail signal for proposed fixes. "verifiable environments"
- Verifier: The executable evaluation script (e.g., evaluation.sh) that determines task success by running builds/tests and returning a status code. "verifier"
- Verified Docker image: A Docker image produced at the end of a successful build that encapsulates a runnable, validated task environment. "verified Docker image"
Practical Applications
Immediate Applications
Below is a concise list of near-term, actionable use cases that can be deployed with current tooling and infrastructure described in the paper.
- PR-to-Environment GitHub Action for reproducible bug reproduction and verification
- Sector: Software/DevOps
- Description: Automatically generate a Dockerized, runnable environment (evaluation.sh + container) for each PR that links to an issue, enabling reviewers and CI to reproduce the bug and verify fixes reliably across languages.
- Tools/Products: “PR2Env” GitHub Action; Docker image artifacts; evaluation.sh verifier
- Dependencies/Assumptions: Safe sandboxing of untrusted code (containers/VMs), access to test patches, network/compute budgets, repository licensing compliance.
- Hacking-detector linter for test quality
- Sector: Software QA/Security
- Description: Integrate the in-loop hacking detector to flag superficial verification scripts (e.g., grep-based checks) in CI, ensuring tests genuinely execute code paths.
- Tools/Products: Test-verifier linter; policy rules in CI (e.g., GitHub Actions, GitLab CI)
- Dependencies/Assumptions: Model access for detection; organizational policy to enforce non-hacked tests; false-positive management.
- Enterprise fine-tuning of coding assistants on internal PR-derived tasks
- Sector: Software/AI Platforms
- Description: Use the SWE-Universe pipeline internally to convert corporate PRs into training environments and trajectories, then mid-train or RL-train enterprise coding assistants for company-specific stacks.
- Tools/Products: Internal dataset builder; mid-training scripts; asynchronous agentic RL framework
- Dependencies/Assumptions: Compute resources; code and data governance; privacy safeguards; sufficient internal test coverage.
- CI/CD release gating with universal verifiers
- Sector: Regulated software (Healthcare, Finance), General DevOps
- Description: Treat evaluation.sh as an acceptance gate in release pipelines to ensure changes pass executable tests (and are non-hacked), improving auditability and compliance.
- Tools/Products: Release gates in Jenkins/GitHub/GitLab; audit logs; policy templates
- Dependencies/Assumptions: Policy buy-in; traceability to linked issues; container registry availability; reproducibility of toolchains.
- Automated bug triage and reproduction artifacts attached to issues
- Sector: IT Operations/Support
- Description: Auto-create and attach runnable Docker images plus evaluation.sh to tickets, reducing manual reproduction time and improving handoffs between QA and engineering.
- Tools/Products: Issue trackers integration; artifact storage (ACR/ECR/GCR)
- Dependencies/Assumptions: Issue–PR linking; secure storage; cost controls.
- Cross-lingual test execution standardization via a universal bash interface
- Sector: Multi-language DevOps/Platform Engineering
- Description: Adopt evaluation.sh return-code semantics to unify test execution across Python, JS/TS, Go, Rust, Java, C/C++, C# in heterogeneous monorepos.
- Tools/Products: Template generators; language-agnostic runners
- Dependencies/Assumptions: Team willingness to standardize; mapping from language-specific test runners to bash conventions.
- Vendor-neutral benchmarking of coding agents “without hack” criteria
- Sector: Procurement/Model Evaluation (Industry & Academia)
- Description: Use Success Rate (w/o Hack) as a procurement-grade metric when comparing code agents; deploy the paper’s benchmark methodology internally.
- Tools/Products: Benchmark suites; scorecards; evaluation harnesses
- Dependencies/Assumptions: Curated test sets; reproducible environments; standardized scoring.
- Quality-judge agent as part of data acceptance checks
- Sector: Data Engineering/QA
- Description: Integrate the quality-judge agent to automatically score task quality and filter out ambiguous or misaligned verification tasks in data pipelines.
- Tools/Products: Data QA workflows; dashboards with quality distributions
- Dependencies/Assumptions: Adequate judge accuracy (≈78.7% reported); human-in-the-loop for edge cases.
- Developer training “bug gyms” powered by real PRs
- Sector: Education/Workforce Development
- Description: Create hands-on, multi-language exercises from real-world PRs for onboarding, bootcamps, and university courses; autograde via evaluation.sh.
- Tools/Products: LMS plug-ins; course modules; sandbox runners
- Dependencies/Assumptions: Licensing for educational reuse; resource limits per cohort; safety in running external code.
- Code review augmentation with one-click runnable environments
- Sector: DevTools
- Description: Embed links to containerized environments and verifiers in PR UI, enabling reviewers to run tests locally/in the cloud before approving.
- Tools/Products: Browser extensions; PR UI integrations; ephemeral cloud runners
- Dependencies/Assumptions: Cloud credits; developer machine compatibility; secure secrets handling.
- Multi-cloud orchestration of long-running agentic jobs
- Sector: Cloud/SRE
- Description: Use MegaFlow-like orchestration to distribute environment builds or agentic rollouts across cloud instances for throughput and cost control.
- Tools/Products: Job schedulers; autoscaling policies; layer-cached registries
- Dependencies/Assumptions: Cloud vendor support; observability; preemption tolerance.
- RL training of code agents using pass/fail rewards
- Sector: Model Training (Industry & Academia)
- Description: Apply the dataset and evaluation.sh signals to train code agents via asynchronous RL for measurable performance gains on standard benchmarks.
- Tools/Products: Asynchronous agentic RL frameworks; curriculum filters
- Dependencies/Assumptions: Reliable reward signals; careful difficulty selection to avoid skew; compute budgets.
Long-Term Applications
These applications require additional research, scaling, standardization, or ecosystem readiness before widespread deployment.
- End-to-end autonomous coding agents that close issues across languages
- Sector: Software Development
- Description: Agents trained on million-scale, verifiable environments autonomously triage, implement, and validate multi-language fixes.
- Tools/Products: Full-stack repair agents; repository-aware “coding world models”
- Dependencies/Assumptions: Advanced planning across large contexts (128k–256k), robust verifier coverage, organizational trust/safety controls.
- Standards for PR verification (evaluation.sh and non-hacked tests)
- Sector: Policy/Standards
- Description: Establish industry norms requiring executable, non-hacked verifiers tied to PRs and issues, improving reproducibility and compliance across ecosystems.
- Tools/Products: Standards documents; compliance checkers; certification programs
- Dependencies/Assumptions: Consensus among foundations (e.g., OpenSSF), buy-in from major platforms.
- Regulatory change management with auditable, reproducible environments
- Sector: Healthcare, Finance, GovTech
- Description: Mandate “verifiers-as-code” and containerized reproductions for all production changes; maintain audit trails for AI-assisted code.
- Tools/Products: Compliance dashboards; immutable artifact registries; evidence packs
- Dependencies/Assumptions: Regulator acceptance; integration with GRC tools; secure artifact long-term storage.
- Secure software supply chain verification at scale
- Sector: Security/DevSecOps
- Description: Combine SBOMs with PR-derived verifiers to continuously validate that dependency changes and patches produce expected runtime behavior.
- Tools/Products: SBOM + verifier linkage; runtime validation services
- Dependencies/Assumptions: SBOM completeness; reproducible builds; hardened runners for untrusted code.
- Marketplace of real-world “bug gyms” and task subscriptions
- Sector: Platforms/Education/Training
- Description: Curated subscription services offering fresh, multi-language tasks for model training, hiring assessments, and developer upskilling.
- Tools/Products: Task marketplaces; leaderboards; cohort analytics
- Dependencies/Assumptions: Licensing of public PRs; curation and quality control; fair-use policies.
- Automated cross-language test synthesis and repair
- Sector: QA/Testing Tools
- Description: Extend the building agent to generate, repair, and evolve tests for legacy repos lacking coverage, beyond unit to integration and system tests.
- Tools/Products: Test synthesizers; coverage-aware verifiers; flakiness detectors
- Dependencies/Assumptions: Stable test oracles; mitigation of confidently incorrect assertions; multi-service orchestration.
- Robotics/embedded code verification with hardware-in-the-loop
- Sector: Robotics/IoT/Automotive
- Description: Adapt verifiers to simulate or interface with real hardware, enabling safe, reproducible validation of low-level code changes.
- Tools/Products: HIL simulators; device emulators; cross-compilation pipelines
- Dependencies/Assumptions: Accurate simulators; deterministic hardware interfaces; safety envelopes.
- Organizational risk scoring and release governance from verifier outcomes
- Sector: FinOps/Engineering Management
- Description: Build risk models that factor task difficulty, verifier robustness, and model/engineer success rates to gate releases and allocate resources.
- Tools/Products: Risk dashboards; policy engines; cost/performance trade-off planners
- Dependencies/Assumptions: High-quality meta-data; stable scoring frameworks; alignment with business SLAs.
- Codebase digital twins for planning and refactoring at scale
- Sector: Software Architecture/Platform Engineering
- Description: Use “coding world models” trained on agentic trajectories to simulate the impact of refactors, dependency upgrades, and architectural changes before execution.
- Tools/Products: Planning simulators; refactor recommender agents
- Dependencies/Assumptions: Accurate repository-scale modeling; long-context reasoning; up-to-date code graphs.
- Privacy-preserving on-prem agentic training
- Sector: Defense/Enterprise
- Description: Run the full PR-to-environment pipeline and agent training entirely on-prem for sensitive codebases, leveraging pass/fail rewards without data egress.
- Tools/Products: On-prem orchestration; private registries; air-gapped runners
- Dependencies/Assumptions: Hardware provisioning; strict access controls; licensing for model weights.
- Education curricula built from real-world multilingual PRs
- Sector: Education
- Description: Scaffold progression from beginner to advanced tasks across languages, teaching debugging, test design, and secure verification practices.
- Tools/Products: Curriculum generators; adaptive difficulty; competency badges
- Dependencies/Assumptions: Content curation; safe execution; institutional adoption.
- Multi-cloud, cost-aware orchestration for million-scale environment builds
- Sector: Cloud/Platform
- Description: Generalize MegaFlow-like systems for diverse clouds with spot/preemptible instances and layer-cached registries to minimize cost and latency.
- Tools/Products: Cross-cloud schedulers; caching layers; auto-retry/resume
- Dependencies/Assumptions: Cloud heterogeneity; robust fault tolerance; strong observability.
Notes on overarching assumptions and dependencies relevant across applications:
- Legal and licensing: Proper reuse of public PRs, issues, and tests; compliance with repository licenses.
- Security: Strict sandboxing of untrusted code (containers/VMs), secret scrubbing, and egress controls.
- Compute and storage: Sufficient budget and orchestration to handle long-running builds; use of layer caching for cost-efficiency.
- Data quality: Presence and clarity of test patches; avoidance of weak or hacked verifiers; ongoing quality scoring and human-in-the-loop review for edge cases.
- Generalization limits: Performance varies by language (C/C++ notably harder); verifiers may require ecosystem-specific tooling and careful maintenance.
Collections
Sign up for free to add this paper to one or more collections.