AI Scientist via Synthetic Task Scaling
Abstract: With the advent of AI agents, automatic scientific discovery has become a tenable goal. Many recent works scaffold agentic systems that can perform machine learning research, but don't offer a principled way to train such agents -- and current LLMs often generate plausible-looking but ineffective ideas. To make progress on training agents that can learn from doing, we provide a novel synthetic environment generation pipeline targeting machine learning agents. Our pipeline automatically synthesizes machine learning challenges compatible with the SWE-agent framework, covering topic sampling, dataset proposal, and code generation. The resulting synthetic tasks are 1) grounded in real machine learning datasets, because the proposed datasets are verified against the Huggingface API and are 2) verified for higher quality with a self-debugging loop. To validate the effectiveness of our synthetic tasks, we tackle MLGym, a benchmark for machine learning tasks. From the synthetic tasks, we sample trajectories from a teacher model (GPT-5), then use the trajectories to train a student model (Qwen3-4B and Qwen3-8B). The student models trained with our synthetic tasks achieve improved performance on MLGym, raising the AUP metric by 9% for Qwen3-4B and 12% for Qwen3-8B.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What’s this paper about?
This paper is about teaching AI to do scientific work—specifically, to run machine learning experiments—by giving it lots of realistic “practice problems.” Instead of waiting for humans to write new tasks, the authors build a system that automatically creates hundreds of machine learning challenges, checks that they work, and then uses them to train smaller AI models to plan, code, test, and improve solutions step by step.
What questions are the authors trying to answer?
- Can we automatically generate many high‑quality, hands‑on machine learning tasks (like a big practice gym) without human supervision?
- If we collect “how an expert would solve it” step‑by‑step examples on these tasks, can we train smaller models to become better research agents?
- Do agents trained this way perform better on an independent benchmark of ML tasks?
How did they do it? (In everyday terms)
Think of this like building a training gym for AI:
- Creating the practice courses
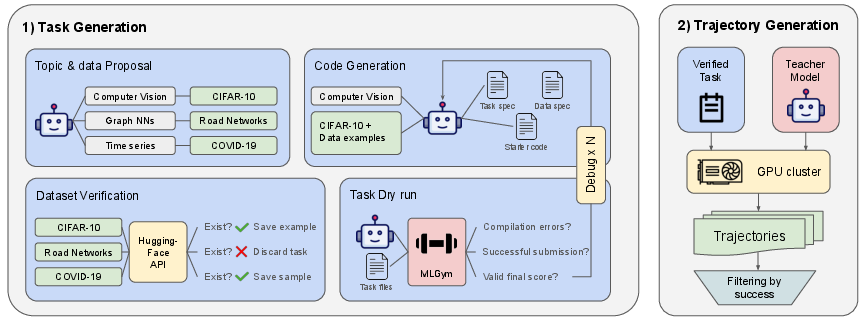
- Topic ideas: The system asks an AI to brainstorm many different machine learning topics (e.g., image classification, reinforcement learning, simple games).
- Real data: For each topic, it proposes a task and tries to link it to a real dataset from Hugging Face (a big public library of datasets). This keeps tasks grounded in real problems, not make‑believe ones.
- Starter code: It then writes the files needed to run the task—configs, starter code, and an evaluation script—so the task is fully runnable.
- Checking and fixing the tasks automatically
- Test run: A strong “teacher” AI (they use a powerful model) tries to run each new task once.
- Debug loop: If something breaks (e.g., a bug in the code), the system feeds the error back to the AI to fix it automatically, trying a few times before giving up.
- Result: Only tasks that run end‑to‑end make it into the gym.
- Collecting how‑to examples (“trajectories”)
- Many playthroughs: For each task, they run many attempts where the teacher AI solves the task step by step—reading files, editing code, running commands, and retrying.
- What is a trajectory? It’s like a complete “playthrough” showing the AI’s reasoning and actions across turns, including planning and debugging.
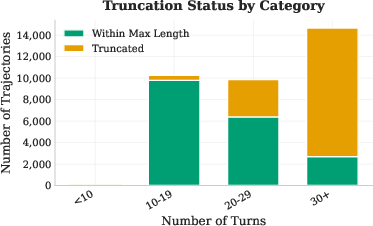
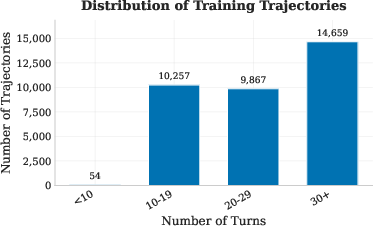
- Filtering: They keep the useful playthroughs (ones that actually submit at least one working solution and aren’t super long) and discard the rest.
- Training student models
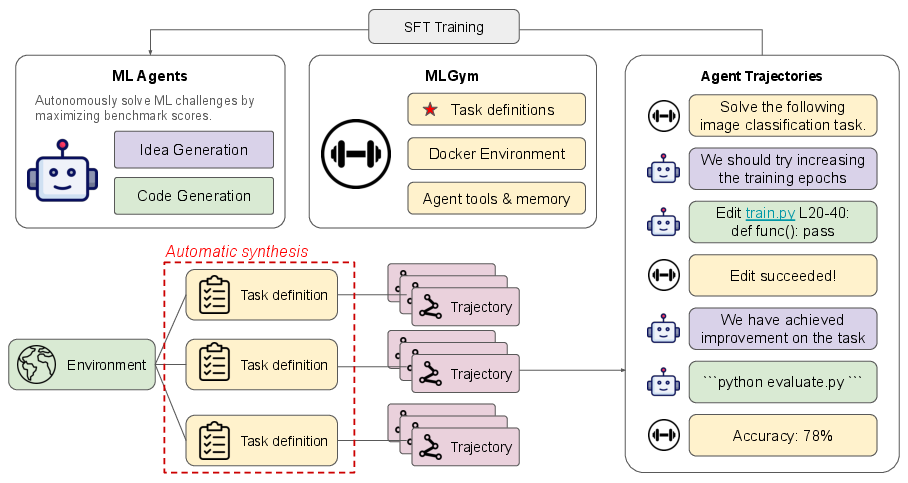
- Teacher → student: These collected playthroughs are used to fine‑tune smaller open models (Qwen3‑4B and Qwen3‑8B), teaching them how to think and act like the teacher during real tasks.
- Platform: Tasks run in an agent framework (SWE‑agent style), where each round the AI writes its reasoning and takes an action (like editing code or running a command).
- Testing on a benchmark
- Benchmark (MLGym): A set of 13 diverse machine learning challenges (e.g., simple games, vision, language, RL). The goal is to improve the baseline code and get a better final score.
- Scoring: Because each task uses different metrics, they use an overall measure called AUP (area under the performance curve)—higher is better and it fairly combines different tasks.
What did they find, and why does it matter?
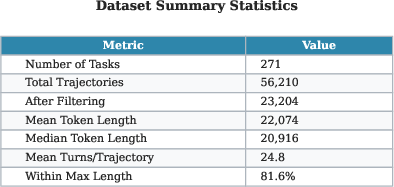
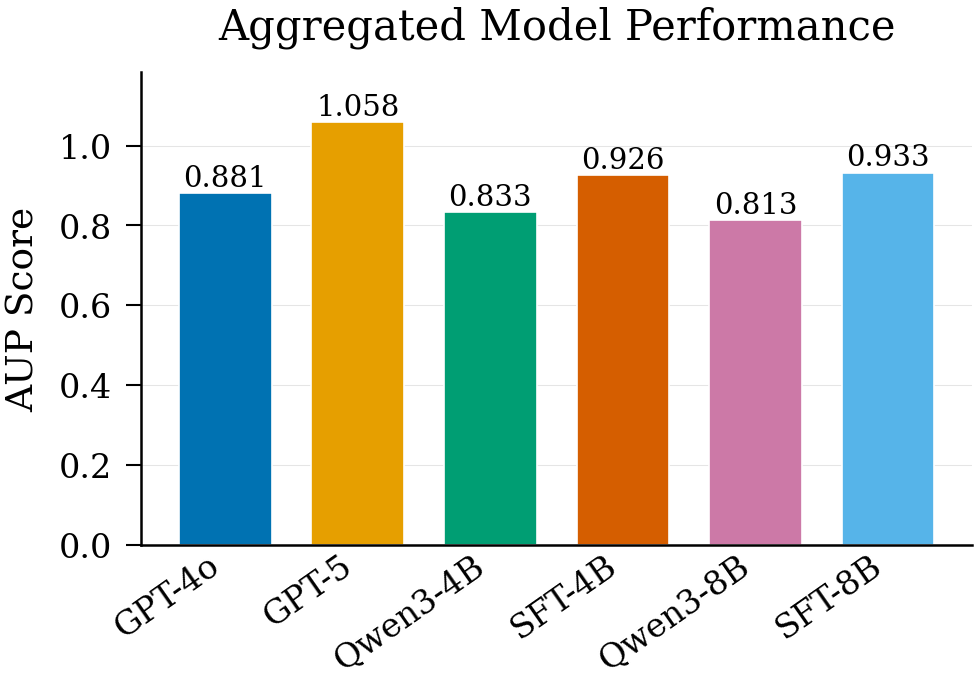
- Scale: Their pipeline created about 500 runnable ML tasks and roughly 30,000–34,000 useful step‑by‑step examples.
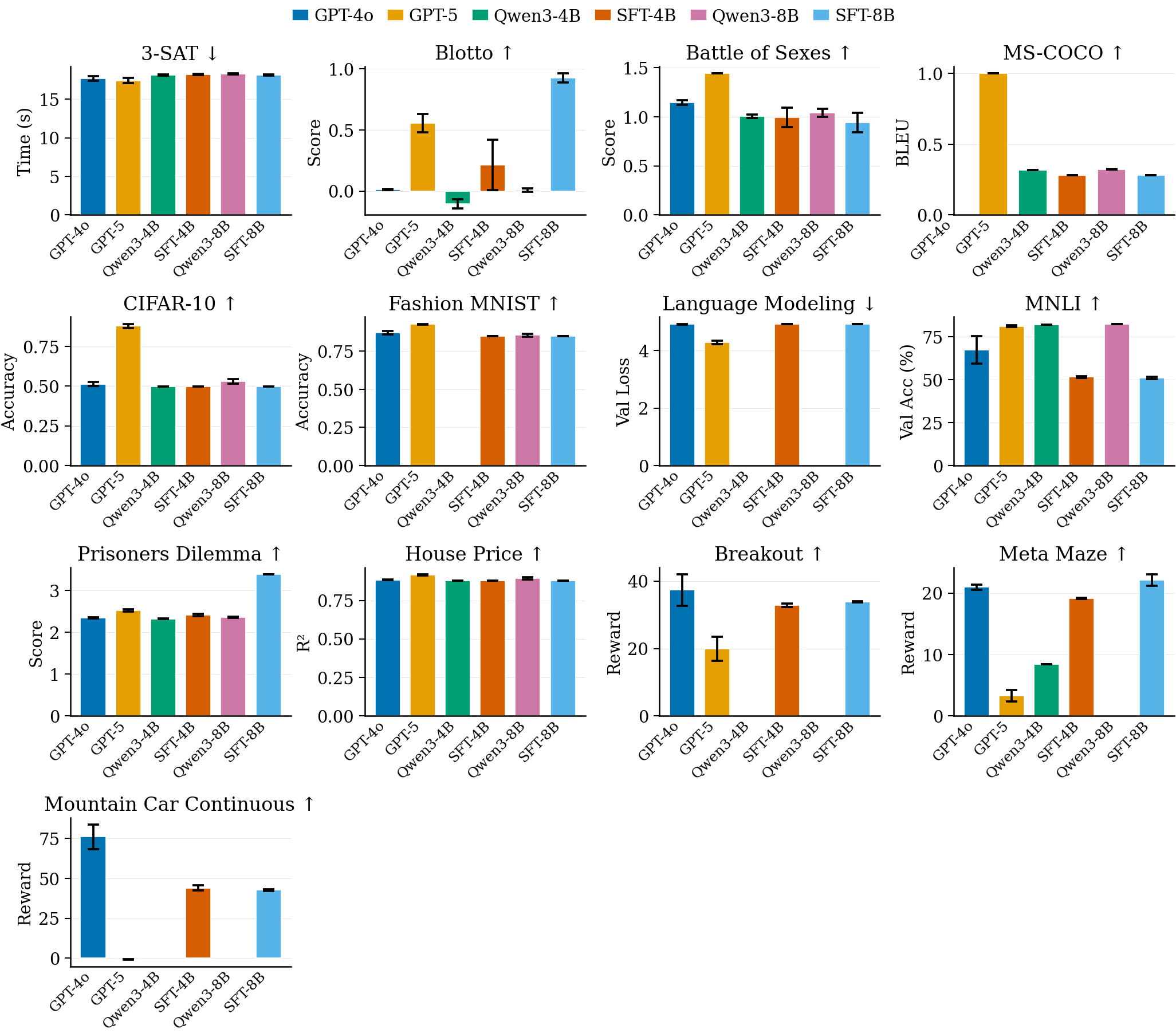
- Better students: After training on these examples, the smaller student models did noticeably better on the MLGym benchmark:
- Qwen3‑4B improved its overall AUP by about 9%.
- Qwen3‑8B improved by about 12%.
- Why it matters:
- Practice beats theory alone: LLMs know a lot, but research needs doing, not just knowing. Training on real, executable tasks helps models learn to plan, code, debug, and iterate—like real researchers.
- No human bottleneck: The whole task creation and debugging process is automatic, so you can scale up training without needing people to hand‑craft tasks.
Key ideas explained simply
- Synthetic task: A new, automatically created challenge that looks and behaves like a real ML problem, complete with real datasets and runnable code.
- Trajectory: A full step‑by‑step record of how an AI solved a task—its thoughts, file edits, commands, and results—like a detailed tutorial from start to finish.
- SWE‑agent framework: A standardized “workbench” where an AI can read files, modify code, run commands, and submit solutions in turns—similar to a turn‑based game for coding.
- AUP metric: A fair way to combine different task scores into one number; bigger AUP means better overall performance across tasks.
What are the limits and what’s next?
- Limits:
- Tested mainly on one benchmark (MLGym), so we don’t yet know how well these gains transfer to very different setups.
- Some tasks (especially more complex ones) didn’t improve as much—suggesting the auto‑generated tasks might not cover every kind of challenge well.
- The pipeline depends on the teacher model’s strengths and weaknesses; if the teacher can’t solve a type of task, the students won’t learn it either.
- What’s next:
- Try other benchmarks to check general skills (not just getting used to one format).
- Add literature search to encourage new ideas, not just improvements.
- Use reinforcement learning so the model gets direct rewards for better results, which could push it toward more creative strategies.
Bottom line
The authors show a practical way to train AI “research assistants” by giving them a huge, automatically built gym of real ML practice tasks and letting them learn from expert step‑by‑step solutions. This makes smaller models better at planning, coding, and iterating on experiments—moving us a step closer to AI that can help discover new ideas, not just summarize old ones.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a single, concrete, and actionable list of what remains missing, uncertain, or unexplored in the paper.
- [Evaluation] Generalization beyond MLGym is untested; evaluate on heterogeneous harnesses (e.g., MLE-Bench, MLRC-Bench, SWE-bench variants) and real repositories to quantify transfer.
- [Evaluation] Format-alignment vs. capability remains entangled; test with different interaction scaffolds (non–SWE-agent toolsets, altered round limits, different submission conventions) to isolate structural overfitting.
- [Evaluation] Reliance on AUP alone obscures nuances; report time-to-improvement, best-score-per-token, number of successful submissions, and per-step success rates with confidence intervals.
- [Evaluation] Statistical rigor is unclear; include multiple seeds, per-task significance tests, and bootstrap CIs for both aggregate and task-level metrics.
- [Evaluation] Data leakage and contamination are not audited; de-duplicate synthetic tasks against MLGym and model pretraining corpora (code and datasets), and run leakage checks.
- [Evaluation] Human-centered validation is absent; add expert judgments of code quality, experimental soundness, and research novelty to complement automatic scores.
- [Pipeline] Topic sampling lacks diversity controls; quantify coverage across ML subfields, difficulty strata, and redundancy, and introduce stratified/entropy-regularized sampling.
- [Pipeline] HuggingFace dataset matching is under-specified; define and ablate the similarity metric, handle deprecated/large datasets, and enforce license compliance checks.
- [Pipeline] Starter code generation skews simple; condition on real, complex repos (e.g., NanoGPT, HuggingFace Transformers) and measure gains on tasks with multi-file, framework-heavy codebases.
- [Pipeline] Self-debug loop hyperparameters (p_debug, k) are unablated; evaluate how debug depth and restart policy affect task validity, diversity, and downstream model gains.
- [Pipeline] Verification uses a single teacher (GPT-5); incorporate multiple teachers or adversarial verifiers to avoid filtering out hard-but-valuable tasks the teacher fails to solve.
- [Pipeline] Task validity is only compile/run-checked; add semantic checks (metric correctness, non-exploitable evals, baseline sanity) to prevent reward hacking or degenerate solutions.
- [Pipeline] Difficulty is not calibrated; introduce task difficulty estimation (e.g., teacher success/variance, resource demands) and ensure a balanced curriculum.
- [Pipeline] System robustness issues (FS/container instability) degrade data; quantify their impact and harden the harness (deterministic containers, pinned dependencies, retries).
- [Pipeline] Security and safety of code execution are unspecified; document sandboxing, network isolation, dependency provenance, and supply-chain protections.
- [Training] Success-only trajectory filtering may discard valuable learning-from-failure signals; test including curated failure segments, contrastive/DPO setups, or step-level rewards.
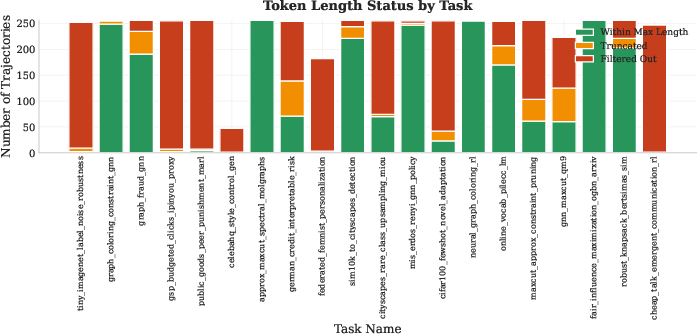
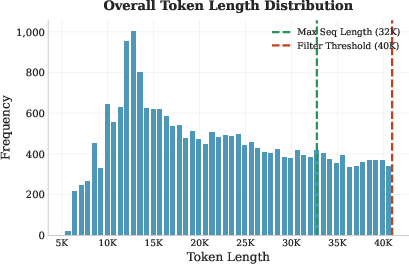
- [Training] Token truncation to 32k may cut long-horizon reasoning; ablate longer context windows or hierarchical memory to quantify truncation effects on performance.
- [Training] SFT-only optimization under-explores exploration/credit assignment; prototype offline RL (from trajectories), on-policy RL with reward normalization, and hybrid SFT+RLHF.
- [Training] Teacher-style overfitting is unmeasured; diversify teachers, randomize prompting styles, and evaluate distillation temperature/augmentation strategies.
- [Training] Scaling laws are unknown; systematically vary number of tasks, trajectories per task, and trajectory length to map returns and saturation regimes.
- [Training] Trajectory quality control is coarse; add filters for rationale coherence, tool-use correctness, and hallucination detection to improve supervision signal.
- [Training] Tool-use supervision is implicit; log and supervise action success/failure at the step level to strengthen action grounding and reduce spurious reasoning.
- [Generalization] Poor performance on complex tasks (e.g., MS-COCO) indicates coverage gaps; explicitly synthesize tasks requiring large data pipelines, multi-GPU training, and framework-specific patterns.
- [Generalization] Robustness to harness variations (different round caps, tool availability, execution latencies) is untested; evaluate and train under distributional shifts in execution conditions.
- [Compute] Rollout cost and carbon footprint are not reported; quantify compute/energy per task and trajectory and explore cost-aware task selection or early stopping.
- [Reproducibility] Prompts, seeds, task artifacts, and filtering criteria are not fully specified; release them (or detailed pseudocode) to enable independent replication.
- [Ethics/Legal] Dataset/code licensing and redistribution compliance for synthesized environments are unaddressed; add automated license checks and usage policies.
- [Safety] No assessment of harmful/unsafe code behaviors (e.g., exfiltration, misuse of network access); introduce guardrails and red-teaming for generated tasks and trajectories.
- [Analysis] No component-level ablations (dataset grounding, self-debug, success filter, truncation, teacher choice); perform factorial ablations to identify key contributors to gains.
- [Discovery] The system does not measure or encourage genuine novelty; integrate retrieval-augmented literature search and define novelty/feasibility metrics for idea-generation steps.
- [Task design] Open-ended research tasks are limited; design tasks that require conceptual changes (not just hyperparameter/code tweaks) and build evaluators for method-level innovation.
- [Memory/Planning] Long-term hypothesis tracking and experiment planning are unsupported; evaluate external memory, experiment logs, and multi-episode curricula.
- [Credit assignment] Which trajectory steps cause score improvements is unknown; instrument evaluations to label improvement-causing edits for step-level supervision or rewards.
Practical Applications
Practical applications derived from the paper
This paper introduces a scalable, fully automated pipeline for generating executable ML tasks, verifying them via a self-debug loop, sampling agent trajectories with a strong “teacher” model, and fine-tuning smaller “student” models to improve long-horizon, agentic ML capabilities. The following lists map these contributions to concrete, real-world applications across industry, academia, policy, and daily life.
Immediate Applications
The items below can be deployed with today’s tools and infrastructure, given modest engineering integration.
- Bold: Enterprise “ML Agent Gym” for internal upskilling and model fine-tuning
- Sectors: software, cloud, MLOps
- What it is: Deploy the paper’s synthetic-task pipeline to create a private catalog of ML tasks tied to real datasets (via Hugging Face), then collect “teacher” trajectories to fine-tune smaller, cheaper in-house agents (e.g., 4B–8B models) for iterative debugging, experiment setup, and code improvements.
- Tools/products/workflows: Internal “Agent Gym” service; dataset-backed task packs; SFT (or DPO) pipelines; SWE-agent-compatible harness; evaluation dashboards (AUP-style aggregates).
- Assumptions/dependencies: Access to a strong teacher model; GPU/CPU orchestration for parallel trajectory collection; secure sandboxed code execution; dataset licenses and HF API availability.
- Bold: Courseware and auto-graded labs for ML education
- Sectors: education, edtech
- What it is: Automatically generate hands-on ML exercises (with starter code and evaluation scripts) grounded in real datasets; capture reasoning/action traces for formative feedback; auto-grade via the harness.
- Tools/products/workflows: “LeetCode for ML” curricula; LMS plugins; task difficulty scaffolding; plagiarism-safe task variants.
- Assumptions/dependencies: Classroom-compliant compute; content moderation for datasets; alignment of tasks to learning outcomes.
- Bold: Hiring and skills assessment for ML engineers
- Sectors: software, HR/TA
- What it is: Dynamic, dataset-grounded coding challenges that test iterative improvement, debugging, and end-to-end ML pipelines—not just final code.
- Tools/products/workflows: Candidate task packs; SWE-agent harness for replay and grading; trajectory-based rubrics (reasoning quality, tool use efficacy).
- Assumptions/dependencies: Legal/ethical use of applicant data; tamper-resistant sandbox; reliable scoring to reduce false negatives/positives.
- Bold: MLOps regression tests for training pipelines
- Sectors: MLOps, platform engineering
- What it is: Run synthetic tasks as routine CI to catch performance regressions (training scripts, config changes, dependency bumps) and auto-propose fixes via agents.
- Tools/products/workflows: CI/CD hooks; performance baselines; auto-PRs generated by agent trajectories; canary tasks mirroring production workloads.
- Assumptions/dependencies: Stable containerization; resource quotas; benchmark-format alignment may bias toward harness-specific gains.
- Bold: Rapid prototyping assistant for data/product teams
- Sectors: software, analytics, finance, retail
- What it is: Given a topic, propose a plausible real dataset (HF-backed), generate starter code and evaluation; accelerate POCs for forecasting, classification, or RL toy environments.
- Tools/products/workflows: Task/dataset proposal CLI; one-click scaffolding for notebooks/repos; baseline metrics and A/B comparisons.
- Assumptions/dependencies: Dataset license/compliance; dataset drift/availability; careful scoping to avoid misuse of non-permissive data.
- Bold: Process distillation from expert agents to small in-house models
- Sectors: software, cloud, regulated industries
- What it is: Capture high-quality trajectories from powerful models (teacher) and fine-tune smaller models to reproduce stepwise research behaviors under enterprise constraints.
- Tools/products/workflows: Knowledge capture workflows; trajectory filtering/truncation; SFT pipelines; long-context tuning.
- Assumptions/dependencies: Access to teacher; long-context student inference; governance for model/trajectory data.
- Bold: Benchmark generation and extension (e.g., MLE-Bench-like)
- Sectors: evaluation, research tooling, cloud
- What it is: Use the pipeline to spin up new, diverse, runnable evaluation tasks across domains to broaden agent testing beyond a single harness.
- Tools/products/workflows: Cross-harness task exporters; AUP-like normalization; hosted eval-as-a-service.
- Assumptions/dependencies: Harmonizing different execution formats; avoidance of overfitting to a single scaffold.
- Bold: Agent-in-the-loop code maintenance for ML repos
- Sectors: software, MLOps
- What it is: Pretrain agents on synthetic trajectories so they can fix CI failures, refactor training scripts, and improve baseline performance with minimal human intervention.
- Tools/products/workflows: Bots integrated with GitHub/GitLab; guardrails and human review queues; safe command whitelists.
- Assumptions/dependencies: Strong sandboxing; approval workflows; audit logs.
- Bold: Public “LeetCode for ML” upskilling platform
- Sectors: education, individual developers
- What it is: A consumer-facing platform offering daily dataset-backed tasks, auto-executed in a sandbox with feedback on reasoning and actions.
- Tools/products/workflows: Tiered tasks; leaderboards; trajectory replays; spaced repetition on weak skills.
- Assumptions/dependencies: Cloud cost control; content moderation; fair-use of datasets.
- Bold: Cloud/HPC capacity utilization via trajectory generation
- Sectors: cloud, HPC providers
- What it is: Backfill idle GPU capacity with trajectory sampling jobs that produce valuable training data products (task packs + trajectories).
- Tools/products/workflows: Spot-capacity schedulers; data bookkeeping and dedup; B2B licensing of curated task datasets.
- Assumptions/dependencies: Data quality gates; customer privacy (no leakage of proprietary code/data); consistent container stacks to reduce flakiness.
Long-Term Applications
These concepts require additional research, scaling, cross-domain validation, or policy frameworks before broad deployment.
- Bold: General-purpose “AI Scientist” for automated research
- Sectors: academia, pharma, materials, energy, software
- What it is: Pretrain agents on scaled synthetic tasks, then integrate literature search, planning, experimentation, and reporting for end-to-end discovery.
- Tools/products/workflows: Multi-agent orchestration; paper-to-experiment pipelines; automated reporting and replication packages.
- Assumptions/dependencies: Robust cross-harness generalization; validated simulators/benchmarks; human-in-the-loop for novelty and ethics.
- Bold: Cross-domain task generation (healthcare, climate, materials)
- Sectors: healthcare (non-clinical R&D), climate modeling, materials science
- What it is: Extend task synthesis beyond ML engineering by grounding in domain datasets and simulators (e.g., molecular, grid, or climate models).
- Tools/products/workflows: Domain task packs with verifiable evaluation; specialized tool adapters; compliance-aware data filters.
- Assumptions/dependencies: Regulatory and ethical constraints; availability/quality of simulators and datasets; domain SME supervision.
- Bold: Reinforcement learning over research tasks
- Sectors: AI/ML, cloud
- What it is: Treat task scores as rewards and apply RL to encourage exploration, long-horizon planning, and robust optimization across diverse tasks.
- Tools/products/workflows: Reward shaping/normalization; inexpensive proxies for long training jobs; curriculum learning.
- Assumptions/dependencies: Efficient rollouts (cost/time); stable, comparable reward scales; safety guarantees for autonomous optimization.
- Bold: Autonomous Kaggle/AutoML competitor
- Sectors: software, analytics
- What it is: Continuous self-play over generated tasks to produce agents that transfer to public competitions and real analytics problems.
- Tools/products/workflows: Self-play task schedulers; leaderboard-driven curricula; generalization tests across datasets and metrics.
- Assumptions/dependencies: Avoiding overfitting to synthetic distributions; compute budgets; community acceptance.
- Bold: Government/enterprise AI evaluation and procurement standards
- Sectors: policy, public sector, regulated industries
- What it is: Standardized, dataset-grounded, runnable task suites for vendor evaluation, capability audits, and compliance testing.
- Tools/products/workflows: Open task repositories; third-party assessors; reproducible scoring with signed artifacts.
- Assumptions/dependencies: Agreement on task coverage and fairness; legal frameworks for executing vendor models in sandboxes.
- Bold: Continuous integration for scientific codebases
- Sectors: academia, R&D
- What it is: Agents monitor research repos, rerun baselines as dependencies/data shift, propose improvements, and flag irreproducibility.
- Tools/products/workflows: CI bots; reproducibility badges; change-impact analyses; experiment versioning.
- Assumptions/dependencies: Reliable and deterministic evaluation; compute funding; community governance.
- Bold: Safety, compliance, and secure agent sandboxes
- Sectors: policy, enterprise IT, security
- What it is: Hardened execution environments and audit tooling for agents that read/modify code and access datasets at scale.
- Tools/products/workflows: Network isolation, command whitelists, data loss prevention, provenance tracking for actions and outputs.
- Assumptions/dependencies: Security certifications; integration with enterprise IAM and data governance.
- Bold: Marketplace for domain task packs and trajectories
- Sectors: software, education, verticals (finance, bio, robotics)
- What it is: Curated, licensed catalogs of synthetic tasks and teacher trajectories for training/evaluating domain-specific agents.
- Tools/products/workflows: Quality tiers, dataset license checks, benchmark alignment disclosures, update cadence SLAs.
- Assumptions/dependencies: IP clarity; standardized metadata; demand-side validation that synthetic tasks improve downstream ROI.
- Bold: Low-cost lab tooling for small institutions
- Sectors: academia, startups, NGOs
- What it is: Distill expert trajectories into small open models that can run locally to assist with ML experiments and code management.
- Tools/products/workflows: Lightweight harnesses; offline task packs; edge deployment patterns.
- Assumptions/dependencies: Sufficient local compute; careful curation to prevent training on biased or low-quality trajectories.
- Bold: Meta-learning of research strategies
- Sectors: AI/ML research
- What it is: Use diverse synthetic tasks to learn transferable planning, debugging, and experimentation heuristics that generalize to new execution formats.
- Tools/products/workflows: Cross-harness adapters; ablations to measure “format vs skill” transfer; meta-controllers for tool selection.
- Assumptions/dependencies: Broader evaluations beyond a single scaffold; rich task diversity; methodologically sound transfer tests.
Cross-cutting assumptions and risks impacting feasibility
- Dependence on powerful teacher models and long-context students; costs and API access may limit scale.
- Dataset availability and licenses; Hugging Face API stability; content moderation requirements.
- Execution security and sandboxing for agent-issued commands; organizational risk appetite.
- Benchmark-format alignment may inflate apparent gains; cross-harness validation needed to evidence general capability.
- Compute cost, environmental footprint, and engineering overhead of parallel trajectory generation.
- Biases and blind spots inherited from the teacher model; missing tasks the teacher cannot solve.
Glossary
- AUP (Area Under the Performance curve): An aggregate, scale-normalized metric used in MLGym to compare model performance across tasks. Example: "Here we report the AUP score of each of the models."
- agentic systems: AI setups that autonomously plan and act through multi-step tool use to achieve goals. Example: "Many recent works scaffold agentic systems that can perform machine learning research"
- agentic trajectories: Recorded sequences of an agent’s reasoning and actions while solving tasks. Example: "produces rich, agentic trajectories with minimal manual effort."
- Benchmark-format alignment: Performance gains stemming from familiarity with a benchmark’s interaction/execution format rather than general ability. Example: "Benchmark-format alignment vs.\ general capability"
- containerization instabilities: Unreliable behavior when running code inside containers in shared compute environments. Example: "The cluster environment further impacts trajectory generation through file system and containerization instabilities."
- dataset grounding (via HuggingFace validation): Anchoring tasks to real datasets by verifying and enriching them using the HuggingFace index/API. Example: "dataset grounding via HuggingFace validation"
- execution harnesses: Standardized run-time scaffolds that execute and evaluate agents on tasks. Example: "benchmarks with different execution harnesses (e.g., MLE-Bench~\cite{chan2025mlebenchevaluatingmachinelearning}, MLRC-Bench~\cite{zhang2025mlrcbenchlanguageagentssolve}, NanoGPT Speedrunning~\cite{zhao2025automatedllmspeedrunningbenchmark})"
- HPC cluster: A high-performance computing cluster used to run many tasks or trajectories in parallel. Example: "we run the synthetic tasks in parallel in a HPC cluster."
- HuggingFace search API: Programmatic interface to search datasets hosted on the HuggingFace Hub. Example: "We use the HuggingFace search API to find the closest match with the model's proposal."
- Kaggle challenges: Competition-style machine learning tasks used as benchmarks for ML engineering. Example: "which uses Kaggle challenges."
- MLE-Bench: A benchmark evaluating machine learning engineering tasks by agents. Example: "One good fit is MLE-Bench~\cite{chan2025mlebenchevaluatingmachinelearning}, which uses Kaggle challenges."
- MLGym: A framework and benchmark of machine learning challenges for research agents. Example: "We specifically tackle the MLGym~\citep{nathani2025mlgymnewframeworkbenchmark} benchmark"
- MLRC-Bench: A benchmark testing whether language agents can solve machine learning research challenges. Example: "MLRC-Bench~\cite{zhang2025mlrcbenchlanguageagentssolve}"
- NanoGPT Speedrunning: A benchmark on reproducing and improving NanoGPT training optimizations under speed constraints. Example: "NanoGPT Speedrunning~\cite{zhao2025automatedllmspeedrunningbenchmark}"
- reward shaping: Modifying rewards to guide and stabilize reinforcement learning training. Example: "reinforcement learning with appropriate reward shaping could yield further improvements"
- roll-out: A single episode/trajectory sampled by an RL agent interacting with an environment. Example: "each roll-out may include long GPU training jobs,"
- self-debugging loop: An automated process that feeds execution errors back into generation to fix tasks. Example: "verified for higher quality with a self-debugging loop."
- SFT (Supervised Fine-Tuning): Fine-tuning a model on labeled demonstrations/trajectories to imitate desired behavior. Example: "which forms our SFT training set."
- student model: A model trained on teacher-generated trajectories to learn task-solving behavior. Example: "then use the trajectories to train a student model (Qwen3-4B and Qwen3-8B~\cite{yang2025qwen3technicalreport})."
- SWE-agent framework: An agent environment/tooling to browse, edit, and execute code while solving tasks. Example: "Based on SWE-agent framework, there is a set number of 50 rounds,"
- SWE-bench Verified: A benchmark of real GitHub issues with verified tests for agent evaluation. Example: "and improves performance on SWE-bench Verified \cite{yang2025swesmithscalingdatasoftware}."
- synthetic environment generation pipeline: A multistage process that automatically creates runnable ML tasks, datasets, configs, and starter code. Example: "novel synthetic environment generation pipeline targeting machine learning agents."
- teacher model: A stronger model that generates supervision trajectories for training a student model. Example: "we sample trajectories from a teacher model (GPT-5~\cite{singh2025openaigpt5card})"
- trajectory filtering: Selecting only certain trajectories (e.g., successful or length-limited) before training. Example: "Trajectory filtering"
- trajectory length truncation: Cutting trajectories to a maximum token budget for storage or training. Example: "trajectory length truncation"
- turn-based reasoning-action loops: An interaction protocol where the agent alternates between explaining reasoning and issuing actions. Example: "turn-based reasoning-action loops"
- violin plots: Distribution visualizations combining summary statistics with kernel density. Example: "displayed as violin plots"
- zero-shot performance gains: Improvements on a benchmark without any task-specific training or fine-tuning. Example: "we expect to zero-shot performance gains on MLE-Bench."
Collections
Sign up for free to add this paper to one or more collections.

