Think in Strokes, Not Pixels: Process-Driven Image Generation via Interleaved Reasoning
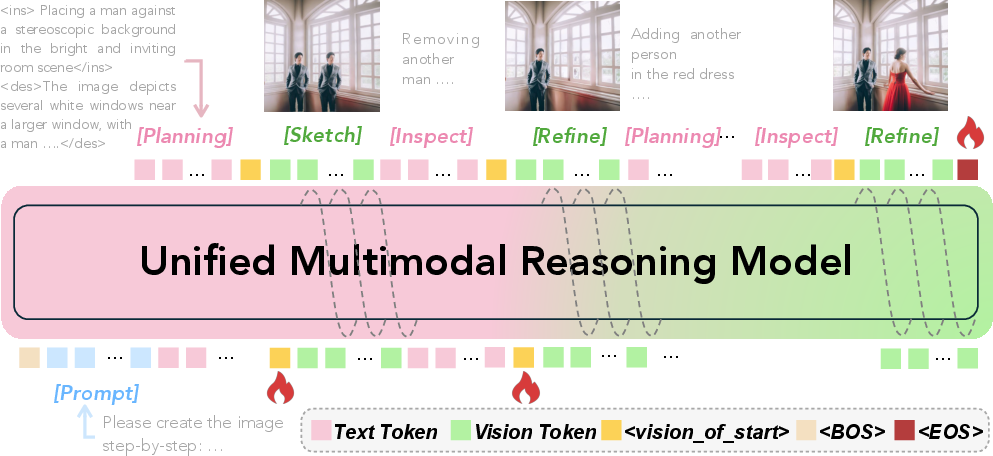
Abstract: Humans paint images incrementally: they plan a global layout, sketch a coarse draft, inspect, and refine details, and most importantly, each step is grounded in the evolving visual states. However, can unified multimodal models trained on text-image interleaved datasets also imagine the chain of intermediate states? In this paper, we introduce process-driven image generation, a multi-step paradigm that decomposes synthesis into an interleaved reasoning trajectory of thoughts and actions. Rather than generating images in a single step, our approach unfolds across multiple iterations, each consisting of 4 stages: textual planning, visual drafting, textual reflection, and visual refinement. The textual reasoning explicitly conditions how the visual state should evolve, while the generated visual intermediate in turn constrains and grounds the next round of textual reasoning. A core challenge of process-driven generation stems from the ambiguity of intermediate states: how can models evaluate each partially-complete image? We address this through dense, step-wise supervision that maintains two complementary constraints: for the visual intermediate states, we enforce the spatial and semantic consistency; for the textual intermediate states, we preserve the prior visual knowledge while enabling the model to identify and correct prompt-violating elements. This makes the generation process explicit, interpretable, and directly supervisable. To validate proposed method, we conduct experiments under various text-to-image generation benchmarks.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of “Think in Strokes, Not Pixels: Process-Driven Image Generation via Interleaved Reasoning”
1) What is this paper about?
This paper is about teaching an AI to make pictures the way people do: step by step. Instead of trying to draw a perfect image in one go, the AI plans what to add, makes a rough sketch, checks for mistakes, and then fixes them—repeating this loop until the picture matches the request. The authors call this “process-driven image generation,” and it helps the AI follow instructions more accurately and explain what it’s doing along the way.
2) What questions were the researchers trying to answer?
- Can an AI that understands both text and images (a “multimodal model”) make better pictures by thinking and drawing in steps, not all at once?
- How can we teach the AI to judge incomplete pictures (like half-finished sketches) so it knows what’s right, what’s wrong, and what’s missing?
- Will this step-by-step process make the AI’s images more faithful to the prompt, especially for tricky things like object positions, colors, and relationships?
3) How did they do it?
They designed a simple, repeatable 4-stage loop that the AI follows for each image:
- Plan: The AI writes a short plan about what to add or change and a brief description of the whole scene.
- Sketch: It draws a rough version of the update (like adding a bear above a spoon).
- Inspect: It checks whether the sketch and the plan match the original prompt (did the bear actually end up above the spoon?).
- Refine: It fixes anything off and improves the image.
Then it repeats this loop until the image looks right.
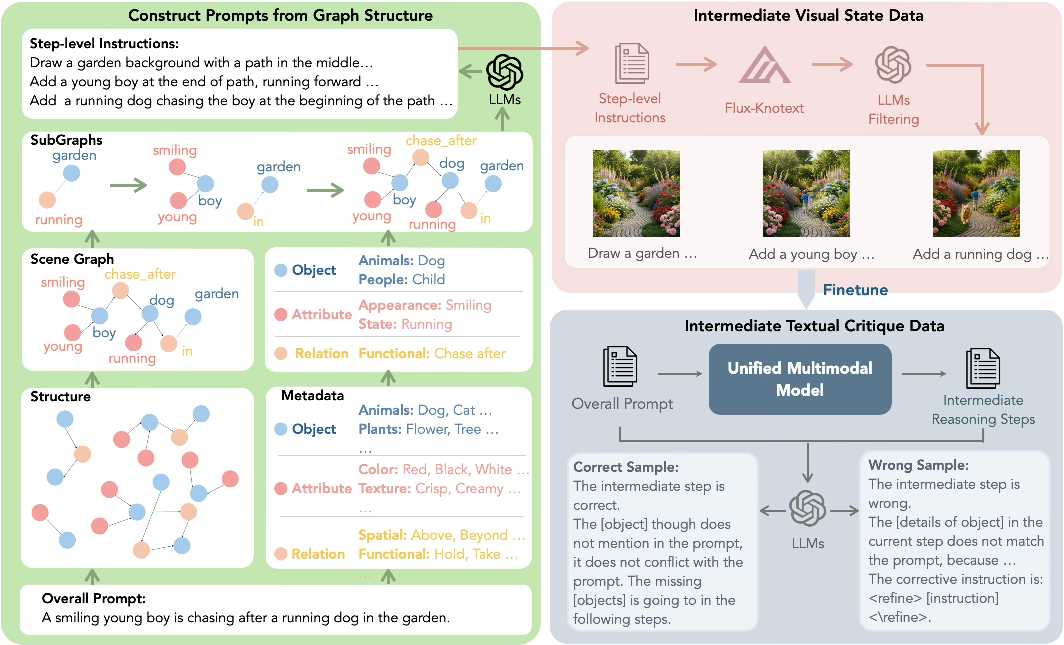
To teach the AI this process, they built special training data:
- A “scene graph” (think of it like a recipe or map of the scene) to split a big picture idea into small, step-by-step tasks that don’t contradict each other.
- Examples where the AI’s own drafts were checked by a judge (another AI) to point out mismatches between the plan, prompt, and picture. This helped the model learn the difference between “not drawn yet” and “drawn wrong.”
- Pairs of images and instructions showing when they do or don’t match, plus explanations for why.
They fine-tuned a single AI model that can both write the plans (text) and draw the pictures (images) in one continuous, back-and-forth sequence. In everyday terms: the model talks to itself while drawing, using each sketch to guide the next piece of thinking.
4) What did they find, and why is it important?
- More accurate images: On a benchmark that checks if images match the text description (GenEval), the model improved from about 79% to 83%. On another benchmark that requires “world knowledge” (WISE), it improved from about 70% to 76%.
- Better at tricky parts: It got notably better at spatial relationships (like “above,” “left of”) and detailed attributes (like “the small red ball”), which are common failure points for one-shot generators.
- Efficient and effective: Compared to another step-by-step method, their approach needed much less training data and ran faster, while also being more accurate.
- Understandable process: Because the model explains its plan and checks itself, you can see why it makes each change. That makes the process more transparent and easier to control.
Why it matters: This approach doesn’t just spit out a final image; it shows the “thinking” behind it. That leads to images that follow instructions more precisely and gives people better control over what the AI creates.
5) What’s the bigger impact?
This step-by-step, visually grounded way of creating images could:
- Make AI art tools more reliable and easier to guide, especially for complex scenes.
- Help users collaborate with the AI—like a back-and-forth conversation while drawing.
- Extend to videos and 3D scenes, where building things in stages is even more important.
- Encourage more trustworthy, explainable AI systems that show their reasoning, not just their results.
In short: “Think in strokes, not pixels” means building pictures the way people do—plan, draw, check, fix—so the final image truly matches what was asked.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of the key gaps and unresolved questions that future work could address:
- Data supervision and bias: Intermediate states and critiques are largely synthesized (Flux-Kontext for images, GPT-based judges for labels) with no human-verified ground truth; the impact of annotator/judge bias and label noise on model behavior and evaluation remains unquantified.
- Faithfulness of the “process”: The paper assumes the generated textual plans/inspections are faithful reflections of visual reasoning, but does not evaluate whether these intermediate texts are causally linked to, and necessary for, the resulting visual updates (risk of post-hoc rationalization).
- Inspect/Refine reliability: There is no metricized evaluation of the model’s ability to detect and correct errors at intermediate steps (e.g., precision/recall of error detection, false positive/negative rates), nor calibration of confidence in its own critiques.
- Exposure bias in SFT: Training uses supervised trajectories while inference relies on self-generated steps; the mismatch between teacher-forced training and free-running inference is not addressed (e.g., with scheduled sampling, DAGGER, RL/DPO).
- Scene-graph parsing and coverage: The method depends on scene-graph subsampling of prompts, but the prompt-to-graph conversion process, its coverage of complex relations (e.g., nested/conditional relations, non-spatial semantics), and robustness to parsing errors are not analyzed.
- Action diversity and completeness: Although instruction diversity (add/modify/swap/remove) is augmented via GPT rewrites, there is no systematic coverage analysis of the action space (e.g., occlusion handling, lighting, style, pose transforms), nor a taxonomy of edits that remain difficult.
- Generalization across backbones: Results are shown primarily on BAGEL-7B; it is unclear whether gains transfer to other unified architectures (e.g., Janus, Emu3, LlamaFusion) or scale similarly with model size.
- Inference-time efficiency trade-offs: While compared against PARM, the overhead versus a single-pass baseline (latency, GPU memory, wall-clock time) is not quantified; how reasoning length affects quality and cost (and how to control/limit it) remains open.
- Termination policy and step-length control: The model “autonomously determines” trajectory length, but stopping criteria, failure to converge, and safeguards against redundant loops are not characterized; mechanisms for user- or budget-controlled step caps are missing.
- Robustness to prompt pathologies: Performance under ambiguous, contradictory, very long, or adversarial prompts is untested; how the Inspect stage handles conflicts inherent in the prompt (as opposed to intermediate drafts) is unclear.
- Counting and compositional scaling: Counting improves but remains challenging; scaling behavior to scenes with many objects (>5) and complex relational webs is not reported (dataset max steps/images per sample is limited).
- Editing use cases: Although the framework accepts an optional input image, there is no evaluation on standard image-editing benchmarks (e.g., InstructPix2Pix, MagicBrush); robustness to preserving content outside edited regions is not assessed.
- Aesthetic/photorealism quality: Beyond GenEval/WISE, standard generative quality metrics (e.g., FID, HPSv2, PickScore, human MOS) are absent; trade-offs between structural fidelity and visual appeal are not measured.
- Metric overfitting and evaluator circularity: Training uses GPT/VLM-based supervision and evaluation uses VLM-based benchmarks (GenEval/WISE); potential overfitting or circular agreement with evaluator distributions is not mitigated or cross-validated with human studies.
- Safety, misuse, and bias: The iterative process may introduce new safety risks (e.g., gradual evolution to unsafe content); there is no audit of demographic, cultural, or content biases, nor alignment/safety mechanisms for intermediate steps.
- Multilingual generalization: All data/evaluation appear to be English-centric; performance and process fidelity for non-English prompts (and code-mixing) are unexplored.
- Domain and style coverage: Reliance on Flux-Kontext and synthetic prompts may bias style/content; generalization to photographs vs. illustrations, specialized domains (medical, architectural), and rare concepts is not assessed.
- High-resolution and multi-resolution support: The approach does not analyze performance or stability at higher resolutions or variable aspect ratios commonly required in production.
- Process-level objectives: Training uses CE for text and MSE/flow for images; there are no explicit consistency or alignment losses that tie textual plans to visual updates (e.g., cycle consistency, contrastive plan–image alignment), nor analysis of their potential benefits.
- Uncertainty and calibration: The model provides no uncertainty estimates for its plans/inspections; decision-theoretic criteria for when to refine versus accept a draft are not studied.
- Tool-augmented variants: The framework avoids external tools by design; whether integrating lightweight tools (e.g., layout planners, segmenters) could further improve alignment/efficiency remains unexplored.
- Video and 3D extension: The method’s applicability to temporal coherence (video) and 3D spatial consistency is left to future work; specific challenges (accumulated drift across frames/views) and needed supervision remain unspecified.
- Reproducibility and release: It is unclear whether the curated datasets (especially GPT-judged traces) and code will be released; replication barriers (data licensing for Flux-Kontext outputs, GPT annotation costs) are not discussed.
- Fairness of baseline comparisons: Details for GPT-4o planner/inspector baselines (prompting, decoding, resource budgets) are sparse, making it hard to assess whether baselines are optimally configured.
- Failure-mode taxonomy: Beyond a few illustrative cases, there is no systematic categorization of common process failures (e.g., instruction drift, compounding spatial errors), nor ablations that map failures to specific training deficiencies.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with current capabilities, leveraging the paper’s process-driven, interleaved Plan → Sketch → Inspect → Refine paradigm and its demonstrated performance/efficiency gains.
- Creative/design software co-pilot (sector: software, media/entertainment)
- Use case: A plugin for Photoshop/Figma/Blender that shows the model’s stepwise “plan” and intermediate drafts, lets designers nudge instructions at each step, and auto-spot misalignments (e.g., incorrect positions/colors).
- Tools/workflows: “Process panel” revealing <ins>/<des>/<refine> text and intermediate images; clickable scene-graph constraints.
- Assumptions/dependencies: Requires integrated unified multimodal model (e.g., BAGEL-like backend), GPU inference; UI integration to expose intermediate states.
- Marketing and brand compliance QA (sector: advertising, retail)
- Use case: Generate campaign assets while the Inspect stage enforces brand rules (logo placement, brand color hex codes, forbidden elements) and flags violations proactively.
- Tools/products: Brand-guideline validator built on the Inspect step; approval dashboard with process logs for audit.
- Assumptions: Reliable text/visual alignment checks for brand rules; organizational workflow to accept process logs as QC evidence.
- E-commerce catalog image generation with attribute fidelity (sector: retail/e-commerce)
- Use case: Create product variant photos (correct count, color, size, accessories) with stepwise checks to avoid misrepresentation.
- Tools/workflows: Scene-graph–driven “variant generator”; bulk generation pipeline that logs reasons and intermediates for each SKU.
- Dependencies: Accurate structured product metadata; compute for batch generation; integration with PIM/DAM systems.
- Layout-aware publishing and marketing collateral (sector: publishing, marketing)
- Use case: Poster/brochure generation where spatial constraints (e.g., “logo top-right”, “two icons below headline”) are enforced through intermediate inspection.
- Tools: “Layout-constrained T2I” template builder that converts layout specs into scene graphs and monitors adherence during generation.
- Dependencies: Template authoring UI; evaluation rules mapped to scene-graph constraints.
- Storyboarding and shot planning (sector: film, gaming, media)
- Use case: Generate storyboards frame-by-frame with interpretable reasoning about character placement, props, and scene continuity.
- Tools: Storyboard assistant exposing plan/inspect notes per frame; export of process logs for director review.
- Dependencies: Consistency mechanisms across multiple images (naming and reusing entities), scheduling compute for batches.
- Synthetic data generation with labeled relations (sector: autonomy, robotics, CV/ML)
- Use case: Produce datasets with precise object relations, counts, and attributes (and associated scene-graph labels) to train detectors/relational reasoning models.
- Tools: Scene-graph authoring and sampling UI; automated generation with intermediate states and ground-truth at each step.
- Dependencies: Domain-appropriate prompts and filtering; licensing of synthetic outputs; quality control for long-tail scenes.
- Safety and content moderation during generation (sector: platform safety, policy)
- Use case: Re-purpose Inspect to detect policy-violating elements (e.g., weapons, logos/IP, unsafe content) before final render; auto-refine or block.
- Tools: Policy rule sets compiled to textual/visual checks; in-process guardrails rather than post-hoc filters.
- Dependencies: Up-to-date policy rules; human review loop for ambiguous cases; logging for audits.
- Accessibility co-creation (sector: accessibility, education)
- Use case: Narrated step-by-step image creation for blind/low-vision users (from <des>/<ins> text), allowing voice-driven refinements.
- Tools: Screen-reader–friendly “process feed”; voice command mapping to <refine> instructions.
- Dependencies: Robust natural language control; careful UX for non-visual feedback on visual intermediates.
- Provenance and transparency for synthetic media (sector: policy, trust & safety, legal)
- Use case: Export process logs (text steps + intermediate images) and bind them to assets via C2PA-style manifests for audit and disclosure requirements.
- Tools: “Process ledger” embedded in image metadata; verification services for regulators/clients.
- Dependencies: Adoption of provenance standards; storage and privacy policies for logs.
- Developer API for process-driven T2I (sector: software/platforms)
- Use case: Offer an API that returns intermediate states and rationales, enabling external apps to steer generation programmatically and reduce retries.
- Tools: Endpoints for stepping, branching, and injecting human edits at <ins>/<refine> points.
- Dependencies: Stable inference latencies; quota/pricing aligned with multi-step generation.
- Academic research tooling for explainable generation (sector: academia)
- Use case: Study interpretable, stepwise multimodal reasoning with provided training recipe—scene-graph subsampling and self-sampled critiques.
- Tools: Data pipeline templates; evaluation harnesses (GenEval, WISE) integrated with process logging.
- Dependencies: Availability of unified models; computing resources for SFT; licensing for any data synthesis used.
Long-Term Applications
These use cases require further research, scaling, or new infrastructure (e.g., video/3D support, domain validation, or regulatory alignment).
- Video and 3D content generation with process-level constraints (sector: media/VFX, AR/VR, CAD)
- Use case: Extend Plan–Sketch–Inspect–Refine to temporal and spatial (3D) domains for physically consistent animations and scene assemblies.
- Potential products: 3D-aware storyboarders, CAD-aware constraint solvers, animation controllers exposing stepwise reasoning.
- Dependencies: 3D/video-capable unified models; temporal/physical consistency checks; new datasets and metrics.
- Robotics and embodied AI planning (sector: robotics, industrial automation)
- Use case: Generalize interleaved reasoning to plan–act–inspect–refine loops in physical tasks (e.g., assembling parts with spatial constraints).
- Products: Visual reasoning controllers that simulate and correct task steps using intermediate perceptual feedback.
- Dependencies: Real-world perception–action integration; safety certification; robustness to sensor noise.
- Constraint-aware CAD/BIM assistants (sector: architecture, engineering, construction)
- Use case: Assist drafting by translating building/program requirements into plan steps, visualizing intermediate states, and enforcing design rules.
- Products: “Process-driven BIM co-pilot” with interpretable constraints and audit trails.
- Dependencies: Deep integration with CAD/BIM data formats; geometric/structural validity checks; domain-specific training.
- Healthcare synthetic imagery with auditability (sector: healthcare)
- Use case: Generate controlled, anonymized medical images with stepwise interpretability for training and bias mitigation.
- Products: Data augmentation pipelines with process logs for IRB/regulatory review.
- Dependencies: Strong domain validation and clinical oversight; bias and safety audits; strict data governance.
- Regulatory compliance and standards for process transparency (sector: policy, legal)
- Use case: Establish norms requiring generative systems to retain and disclose process logs for accountability (e.g., in advertising, political media).
- Products: Compliance reporting services; standardized “process certificates.”
- Dependencies: Policymaker adoption; interoperability across vendors; privacy-preserving logging.
- Multi-agent or microservice orchestration around Planner/Inspector roles (sector: software infrastructure)
- Use case: Scale via specialized services (Planner, Sketcher, Inspector, Refiner) or ensembles for higher reliability and throughput.
- Products: Orchestrators that route cases between modules based on difficulty; fallback to human-in-the-loop.
- Dependencies: Reliable interface contracts; latency management; cost control.
- Education at scale: intelligent art and spatial reasoning tutors (sector: education/edtech)
- Use case: Personalized feedback on students’ sketches versus assignment instructions; visualize stepwise corrections.
- Products: Curriculum-aligned tutor agents with interpretable reasoning feedback and rubrics.
- Dependencies: Pedagogical validation; bias fairness; classroom deployment considerations.
- Cultural and temporal localization at enterprise scale (sector: global marketing, localization)
- Use case: Generate culturally/temporally appropriate imagery with explicit reasoning (leveraging WISE-style knowledge) and explainable checks.
- Products: “Cultural fit” inspectors and adaptation planners integrated into global campaign tooling.
- Dependencies: Local cultural expertise; continuous updating of knowledge; safeguards against stereotyping.
- Digital twin/simulation content with ground-truth constraints (sector: smart cities, manufacturing)
- Use case: Create synthetic but constraint-faithful imagery for validating perception systems in digital twins, with intermediate labels.
- Products: Scenario libraries with stepwise provenance and ground truth for benchmarking.
- Dependencies: Alignment with physical simulation engines; coverage of edge cases; validation protocols.
- Energy-efficient, edge-capable process generation (sector: green AI, mobile/edge)
- Use case: Distill process-driven reasoning into smaller models or adaptive-step controllers to cut energy and latency.
- Products: Edge-ready “process-aware” generators for on-device content creation; adaptive-step schedulers.
- Dependencies: Model compression/distillation techniques for multimodal generation; hardware acceleration; quality retention.
Notes on feasibility across applications:
- Model availability and compute: Current results rely on a unified 7B multimodal generator with rectified-flow image synthesis; deployment may need GPU/accelerator access and careful latency management.
- Data pipelines: Scene-graph authoring and self-sampled critique generation are key; domain-specific applications will need curated prompts, rule sets, and validators.
- Safety and bias: Inspect-stage judgments can inherit biases from judges and training data; sensitive domains (healthcare, public policy) require rigorous evaluation and oversight.
- Integration complexity: Decoupled LLM+diffusion stacks may need bridging layers to emulate interleaved token generation and modality switching present in integrated backbones like BAGEL.
- Legal/IP/provenance: Organizations should align generated content and process logs with licensing, copyright, and privacy requirements.
Glossary
- Autoregressive modeling: A generative approach that predicts each next token conditioned on previously generated tokens. "We propose to train a unified multimodal sequencer, such as BAGEL~\cite{bagel}, to autoregressively generate interleaved multi-modal tokens."
- Best-of-20 search strategy: An inference-time technique that samples many candidates and selects the best according to a criterion. "While PARM relies on a Best-of-20 search strategy that incurs a cumulative cost of 1000 sampling steps, our model synthesizes high-quality images in just 131 steps (averaging 2.62 reasoning steps per image)."
- Chain-of-thought (CoT): A prompting/training method that elicits intermediate reasoning steps in text to improve problem solving. "Although step-wise reasoning has been proposed through textual chain-of-thought (CoT)~\cite{cot,cot-2,cot-3,mvot}, but it remains visually blind, unable to dynamically perceive spatial misalignments~\cite{spatial-cot} or evolve object states~\cite{object-relation-cot,embodiedgpt}."
- Complexity-adaptive reasoning: A mechanism where the model adjusts the number of reasoning steps based on task difficulty. "This inference cost is calculated based on our model's complexity-adaptive reasoning, where it autonomously determines the trajectory length based on task difficulty."
- Cross-Entropy (CE) Loss: A standard loss for next-token prediction that penalizes divergence between predicted and true token distributions. "We train our model to generate text tokens autoregressively, optimizing the process with a Cross-Entropy (CE) Loss."
- Diffusion latent space: The internal continuous representation space used by diffusion models during generation. "PARM supervises the diffusion latent space, where intermediate states are often fuzzy or lack clear human-interpretable meaning."
- Diffusion-based generation: Image synthesis via iterative denoising (diffusion) processes, often conditioned on text. "More recent integrated transformer frameworks, such as the Janus series \cite{janusflow, janus-pro}, LlamaFusion \cite{llamafusion}, and BAGEL \cite{bagel}, directly combine autoregressive text modeling with diffusion-based generation to better align representation spaces and support large-scale interleaved textâimage pretraining."
- Discrete visual tokenizers: Models (e.g., vector quantizers) that convert images into sequences of discrete tokens for autoregressive modeling. "Early autoregressive approach, e.g., Chameleon \cite{chameleon}, Emu3 \cite{emu3}, and Show-o \cite{showo}, rely on discrete visual tokenizers such as VQ-VAE \cite{vq-vae} to model images as token sequences, achieving unified model but suffering from constrained fine-grained visual understanding."
- Gen-Ref dataset: A dataset used for evaluating and training image–instruction alignment and reflection-based refinement. "We extend and refine the Gen-Ref dataset \cite{from-reflection-to-perfection} into two annotated categories: positive samples, where the image is consistent with the instruction, ... and negative samples, where the image mis-aligns with the instruction, ..."
- GenEval: A benchmark that evaluates compositional text-to-image generation on attributes like objects, relations, and colors. "Table \ref{tab:quantitative-result}. demonstrates the quantitative results on the GenEval benchmark \cite{geneval}, which evaluates compositional text-to-image in various object-centric attributes."
- Image–Instruction Alignment (subset): A dataset subset designed to assess and supervise consistency between an image draft and a step-level instruction. "Finally, the imageâinstruction alignment subset includes 15K imageâtext pairs (10K negative and 5K positive) to enforce fine-grained consistency between editing instructions and resulting visual modifications."
- Interleaved reasoning: A process where textual reasoning and visual generation alternate and inform each other step-by-step. "In this paper, we introduce process-driven image generation, a multi-step paradigm that decomposes synthesis into an interleaved reasoning trajectory of thoughts and actions."
- Interleaved text–image pretraining: Joint training on sequences that mix textual and visual tokens to align modalities. "...directly combine autoregressive text modeling with diffusion-based generation to better align representation spaces and support large-scale interleaved textâimage pretraining."
- Instruction-Intermediate Conflict (subset): A dataset subset targeting inconsistencies between the current textual plan and the original prompt. "we further collect 15K samples by self-sampling intermediate trajectories as the instruction-intermediate conflict set."
- Multimodal Chain-of-Thought (Multimodal CoT): Chain-of-thought reasoning extended to inputs/outputs across modalities (e.g., text and vision). "However, multimodal CoT~\cite{mcot,mcot-2} and tool-augmented sketching~\cite{sketchvisual,image-of-thought} decouple reasoning from generation; post-hoc refinement~\cite{unicot} remains outcome-based, where interleaving is limited to repairing after generation rather than reasoning during generation."
- Multimodal LLM (MLLM): A large model that processes and reasons over multiple modalities (e.g., text and images). "Unified multimodal models aim to unify visual understanding and generation within a single framework, building on the strong perceptual abilities of modern multimodal LLMs."
- Post-hoc refinement: An approach that attempts to fix outputs after generation rather than during the generation process. "post-hoc refinement~\cite{unicot} remains outcome-based, where interleaving is limited to repairing after generation rather than reasoning during generation."
- Rectified Flow paradigm: A flow-based generative training objective that predicts velocity fields between data and noise for image generation. "On the visual side, we followed \cite{bagel} and employ Rectified Flow paradigm \cite{flow} to generate images, following:"
- Scene graph: A structured representation of a scene with objects (nodes), attributes, and relations (edges). "Specifically, we represent each prompt using a scene graph, where object nodes, attribute nodes, and relation edges define the target composition."
- Scene-graph subsampling: Constructing incremental prompts by sampling subgraphs to expand a scene without contradictions. "We tackle this by generating multi-turn trajectories of intermediate states via scene graph subsampling, yielding logically ordered incremental prompts that expand the composition without contradictions."
- Self-sampling: Generating a model’s own trajectories to mine errors and provide supervision aligned with its distribution. "To this purpose, we adopt a self-sampling strategy: from a fine-tuned model on Multi-Turn generation Subset, we sample generated intermediate reasoning traces that include textual descriptions of partially completed images..."
- Semantic partitioning: Supervising distinct, meaningful semantic states (e.g., objects/relations) rather than low-level pixel/noise states. "This advantage stems from our use of semantic partitioningâsupervising concrete visual states rather than the blurry latent noise used in prior work."
- Tool-augmented sketching: Using external tools or modules to aid visual reasoning or drafting during generation. "However, multimodal CoT~\cite{mcot,mcot-2} and tool-augmented sketching~\cite{sketchvisual,image-of-thought} decouple reasoning from generation..."
- Unified multimodal model: A single model that both understands visual content and generates images within one architecture. "Unified multimodal models aim to unify visual understanding and generation within a single framework, building on the strong perceptual abilities of modern multimodal LLMs."
- Unified multimodal sequencer: A unified model configured to emit interleaved text and image tokens in a single sequence. "We propose to train a unified multimodal sequencer, such as BAGEL~\cite{bagel}, to autoregressively generate interleaved multi-modal tokens."
- Vision-LLM (VLM): A model jointly trained on vision and language to perform multimodal understanding tasks. "We propose to construct a dual-stream process-critique data comprising error traces and alignment evaluation, to teach models to perform self-assessment from btoh textual and visual states, leveraging judges from a VLM operating on sampled trajectories."
- VQ-VAE: A vector-quantized variational autoencoder that converts images to discrete codes for sequence modeling. "Early autoregressive approach, e.g., Chameleon \cite{chameleon}, Emu3 \cite{emu3}, and Show-o \cite{showo}, rely on discrete visual tokenizers such as VQ-VAE \cite{vq-vae} to model images as token sequences..."
- WISE benchmark: A benchmark for evaluating text-to-image models on integration of world knowledge and structured reasoning. "WISE assesses a modelâs ability to integrate world knowledge and structured semantic reasoning into text-to-image generation."
- World knowledge reasoning: The capacity of a model to apply factual and commonsense knowledge during generation. "Evaluation of world knowledge reasoning WISE benchmark."
Collections
Sign up for free to add this paper to one or more collections.