- The paper introduces a dual-memory architecture that integrates non-parametric memory with parametric planning and execution modules.
- The paper employs an alternating RL strategy that disentangles planning from execution, enhancing tool use and multi-hop reasoning.
- The paper demonstrates significant accuracy gains across multimodal benchmarks, outperforming state-of-the-art memory systems by up to 9%.
Memory Intelligence Agent: A Dual-Memory Framework for Self-Evolving Deep Research Agents
Introduction and Motivation
The "Memory Intelligence Agent" (MIA) (2604.04503) addresses fundamental limitations in the integration of memory systems within Deep Research Agents (DRAs). DRAs—LLM-based autonomous agents augmented with tool-use—are increasingly critical for open-ended, complex reasoning tasks. While previous research has mainly deployed long-context memory systems to accumulate history for improved decision-making, these methods suffer from degradation due to attention dilution, contextual noise, growing computational/storage costs, and an over-reliance on knowledge-oriented memories rather than process-oriented ones. MIA introduces a three-component architecture—Manager, Planner, Executor—replacing monolithic memory with a synergistic combination of non-parametric and parametric stores, online RL-based optimization, and mechanisms for scalable, continual learning, including in unsupervised settings.
Architecture and Methodology
The MIA framework is instantiated as a Manager-Planner-Executor triad.
- Memory Manager: A non-parametric memory subsystem that compresses historical search trajectories (both successful and failed) into structured, succinct representations. It supports efficient retrieval with hybrid scoring (semantic similarity, value reward, frequency reward) and integrates a pre-trained LLM (e.g., Qwen3-32B) for memory management.
- Planner: A parametric agent (LLM, e.g., Qwen3-8B) that incorporates context from the Memory Manager to output chain-of-thought (CoT) guided search plans. The Planner evolves its parameters continuously during both training and test-time inference.
- Executor: An LLM or Multimodal Model (e.g., Qwen2.5-VL-7B) responsible for faithfully implementing the Planner's plan via stepwise tool use and environmental interaction.
MIA’s reasoning loop comprises retrieval from the Manager, collaborative planning and execution via an explicit planning-execution-reflection protocol, and post-hoc consolidation (compression) of experiences.
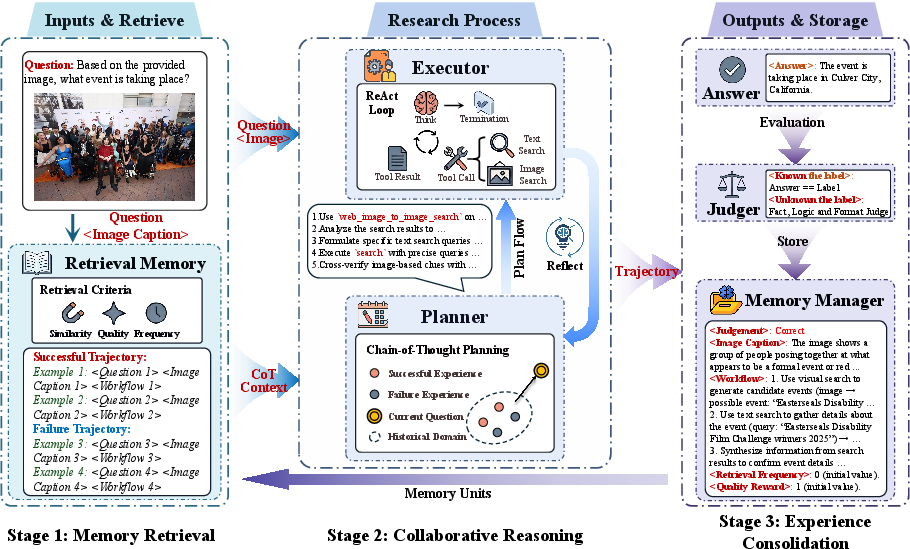
Figure 1: The MIA pipeline: context retrieval, Planner-Executor collaborative reasoning with dynamic feedback, and structured trajectory storage.

Figure 2: The MIA memory evolution process: plan generation, environment rollout, optimal plan selection, and synchronous update of both memory types.
The framework employs a two-stage alternating Group Relative Policy Optimization (GRPO) RL scheme: the Executor is first trained to follow the Planner, then the Planner is optimized (while the Executor is frozen) to generate higher-quality, memory-guided plans and reflection strategies. This disentangles planning from execution and jointly aligns both agents' objectives. Test-time learning (TTL) continuously updates Planner parameters in situ, allowing adaptation without interrupting the inference pipeline.
A core innovation is the bidirectional transfer between non-parametric and parametric memories: historical trajectories retrieved from the Manager explicitly inform planning, while online trajectory compression internalizes new knowledge. TTL employs an online meta-memory mechanism to select optimal explorations, storing both positive/negative paradigms for future contrastive retrieval.
Unsupervised Self-Evolution and Judgment Framework
A notable contribution is MIA’s capacity for unsupervised continual self-evolution. Real-world tasks often lack explicit supervision or reward signals; commonplace LM-based judgment strategies suffer from hallucination and entangled evaluation criteria. MIA introduces an evaluation protocol mimicking the multi-perspective peer review process: three independent reviewers (Reasoning Logic, Source Credibility, Result Validity) and an Area Chair (meta-decider). The consensus grounds memory and RL updates even without gold answers.
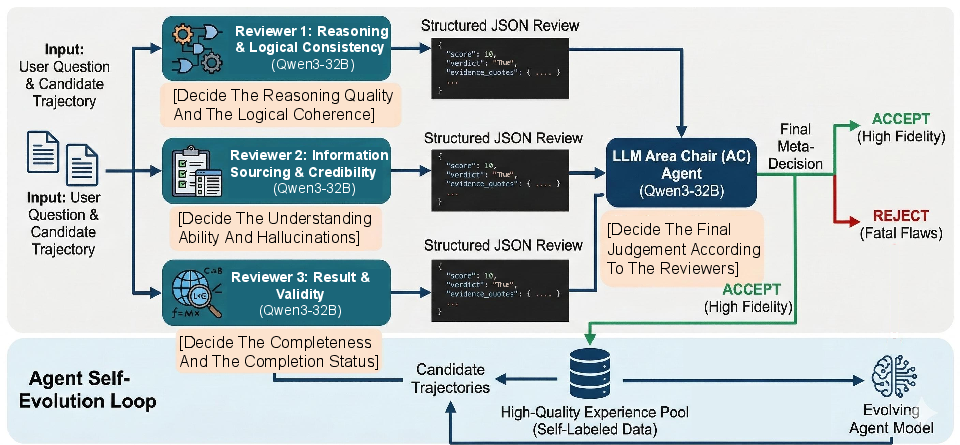
Figure 3: MIA’s unsupervised evaluation: multi-faceted, evidence-driven review and conflict resolution.
Empirical Evaluation
MIA is bench-marked across 11 multimodal and text-only datasets including FVQA, SimpleVQA, InfoSeek, MMSearch, LiveVQA, In-house datasets, HotpotQA, 2Wiki, SimpleQA, and GAIA. The primary evaluation metric is accuracy judged by Qwen3-32B.
Key empirical findings include:
- On multimodal benchmarks, MIA achieves up to 9% accuracy improvement on LiveVQA and 6% on HotpotQA when integrated with GPT-5.4, compared to its vanilla execution.
- With lightweight Executors like Qwen2.5-VL-7B, MIA yields a 31% average gain, outperforming the much larger Qwen2.5-VL-32B by 18%.
- MIA’s dual-memory and TTL-based optimization outperforms SOTA memory frameworks (e.g., Memento, ReasoningBank, ExpeL) by 5–8% across diverse scenarios.
- Contextual memory methods (e.g., RAG, Mem0) often degrade performance compared to no-memory setups, confirming that naive long-context construction is sub-optimal for agentic deep research tasks.
- Generalization holds for both open-source and closed-source Executors (GPT-5.4, Gemini-3-Flash, Claude-Sonnet-4.6), where gains on less capable models are especially pronounced.
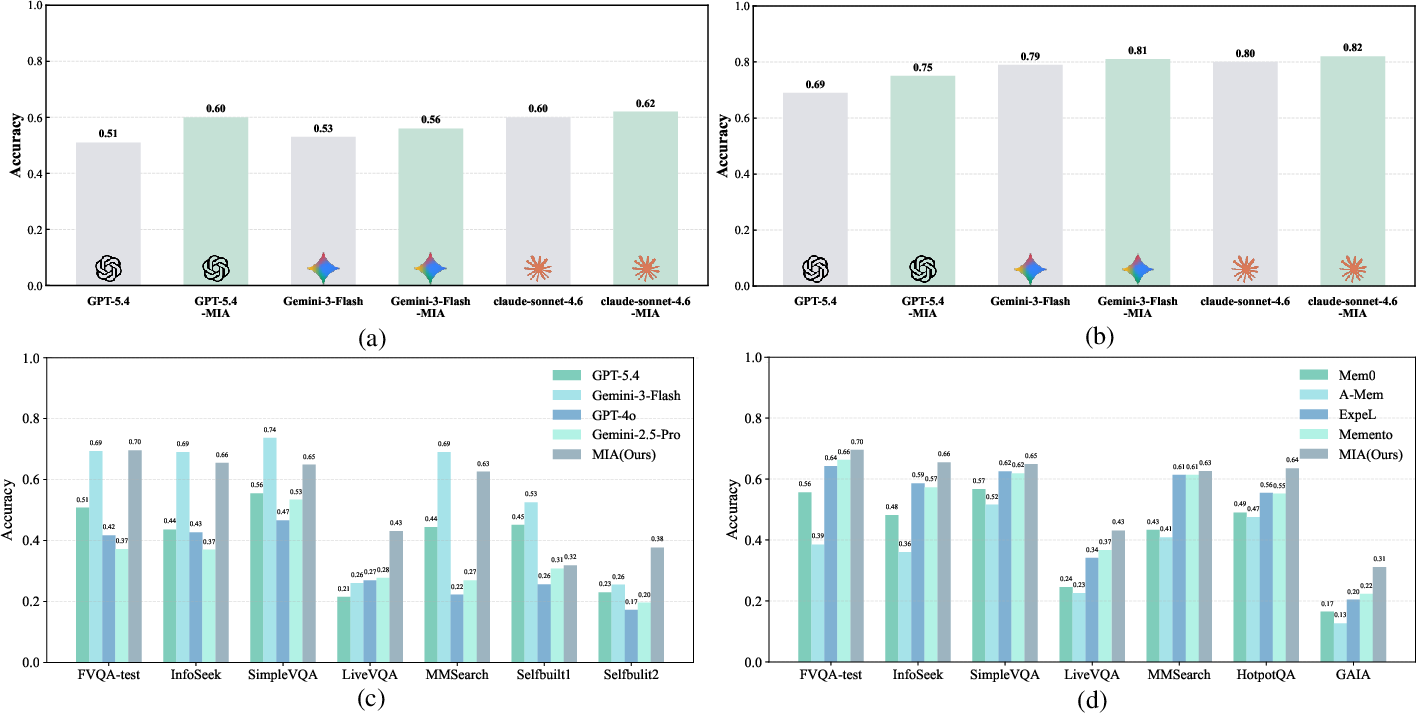
Figure 4: MIA boosts accuracy over baseline LLMs (a,b), outperforms models with more parameters (c), and surpasses SOTA memory frameworks (d) across various datasets.
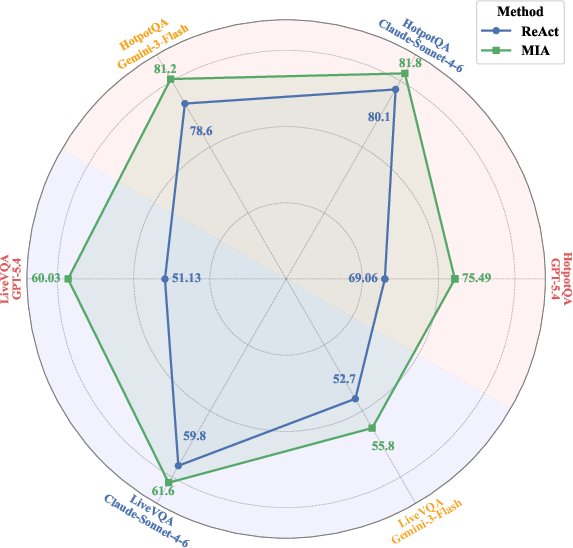
Figure 5: MIA enhancement (green) yields consistent accuracy improvements over ReAct-only (blue) across SOTA closed-source Executors.
Tool usage analysis demonstrates that models without effective memory rely on few tool calls and plateau at low accuracy. Explicit planning and memory-augmented architectures allow for more targeted tool use and higher execution success.
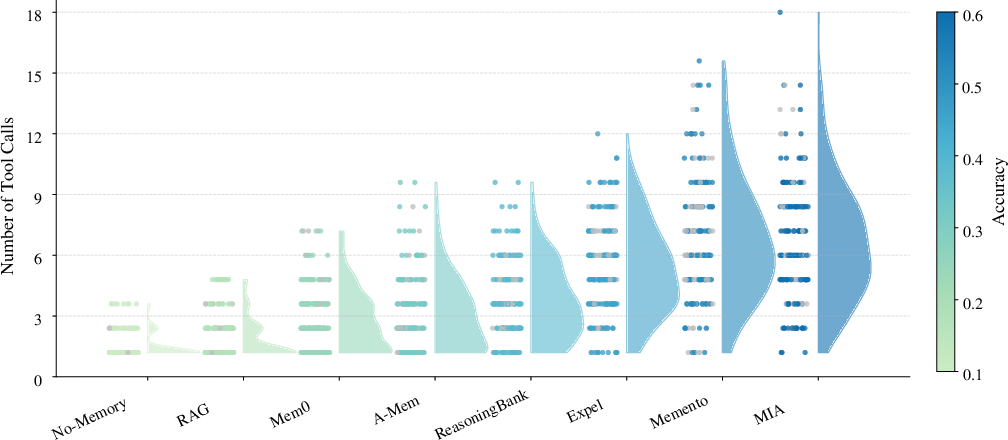
Figure 6: MIA's explicit memory and planning enable greater tool call diversity and success, as evidenced by the distribution of task completions.
Ablation and Training Dynamics
Ablations show significant gains only accrue when memory is used to guide the Planner (rather than the Executor directly), and reflection mechanisms further improve complex, multi-hop reasoning. Alternating RL training of the Planner provides an additional boost, and TTL delivers the highest single improvement. Fully assembled, MIA outperforms its base variant by 9–12 points in average accuracy.
Training analysis finds that Executor rewards are stable and rise rapidly, while Planner rewards are noisier but trend upward, reflecting the indirect credit assignment in the collaborative loop. TTL enables speedy adaptation to domain/data shifts, manifesting in changes in response length and output style tuned to new benchmarks.
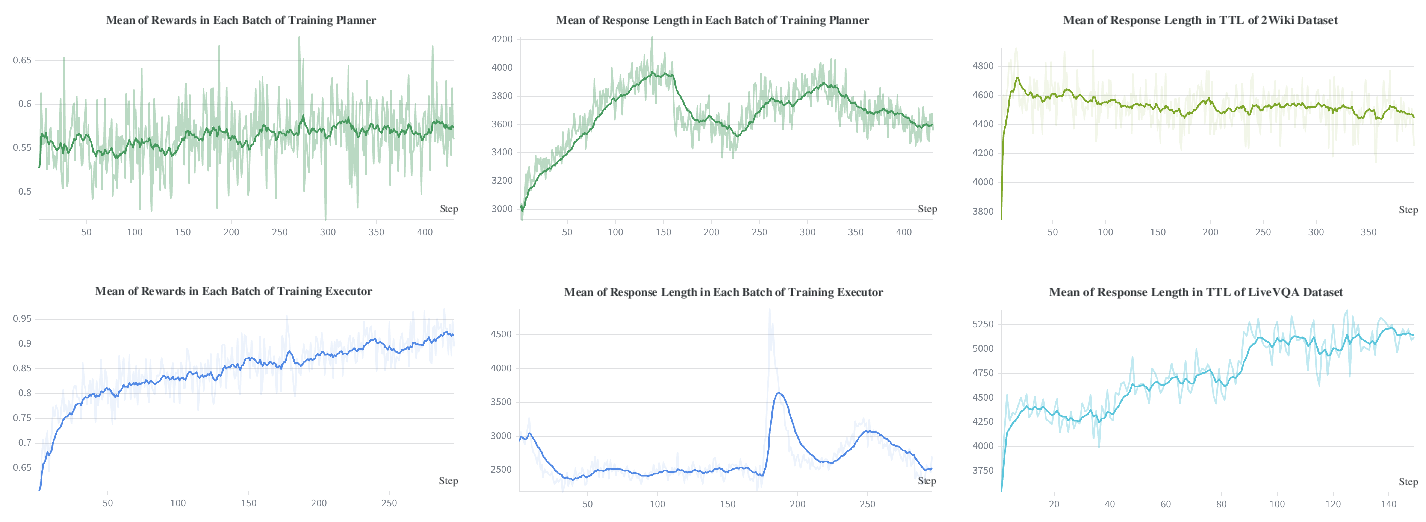
Figure 7: RL reward (left) and response length (middle/right) curves showing convergence and adaptation of Planner and Executor across training and TTL.
Theoretical and Practical Implications
MIA operationalizes a scalable mechanism for process-oriented, modular memory evolution in DRAs. This is technically significant because it:
- Separates episodic history from parametric policy, mitigating memory bloat and retrieval inefficiency.
- Achieves superior planning/execution co-adaptation via alternating RL and online test-time self-improvement.
- Enables data-efficient, supervision-light continual evolution, critical for real-world OOD deployment and open-world research.
- Demonstrates architecture-agnosticity: memory-induced performance generalizes to both small/large, open/closed Executor models.
These results suggest that future DRAs should eschew monolithic context accumulation for hybrid dual-memory systems tightly coupled with online learning. Further, explicit multi-facet judgment should replace black-box end-to-end performance estimates, especially when ground-truth is unavailable.
Future Directions
Potential advances include:
- Extending MIA’s architecture to support more complex hierarchical planning/execution, dynamic multi-agent cooperation, or richer tool adaptation.
- Leveraging memory evolution for genuinely lifelong or curriculum-based learning in changing, real-time environments.
- Applying the evidence-based judgment framework more generally for transparent, interpretable agent decision auditing.
Conclusion
MIA (2604.04503) presents a highly effective dual-memory agentic framework for deep research tasks, achieving state-of-the-art accuracy, sample efficiency, and continual adaptation. Its architecture and methodology set new design principles for agent memory in autonomous systems: explicit separation of experience, ongoing parametric adaptation, and robust unsupervised self-evolution. These contributions offer a blueprint for next-generation DRAs capable of real-world, open-ended reasoning, with broad implications for agent design in memory- and reasoning-intensive AI.