MemEvolve: Meta-Evolution of Agent Memory Systems
Abstract: Self-evolving memory systems are unprecedentedly reshaping the evolutionary paradigm of LLM-based agents. Prior work has predominantly relied on manually engineered memory architectures to store trajectories, distill experience, and synthesize reusable tools, enabling agents to evolve on the fly within environment interactions. However, this paradigm is fundamentally constrained by the staticity of the memory system itself: while memory facilitates agent-level evolving, the underlying memory architecture cannot be meta-adapted to diverse task contexts. To address this gap, we propose MemEvolve, a meta-evolutionary framework that jointly evolves agents' experiential knowledge and their memory architecture, allowing agent systems not only to accumulate experience but also to progressively refine how they learn from it. To ground MemEvolve in prior research and foster openness in future self-evolving systems, we introduce EvolveLab, a unified self-evolving memory codebase that distills twelve representative memory systems into a modular design space (encode, store, retrieve, manage), providing both a standardized implementation substrate and a fair experimental arena. Extensive evaluations on four challenging agentic benchmarks demonstrate that MemEvolve achieves (I) substantial performance gains, improving frameworks such as SmolAgent and Flash-Searcher by up to $17.06\%$; and (II) strong cross-task and cross-LLM generalization, designing memory architectures that transfer effectively across diverse benchmarks and backbone models.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
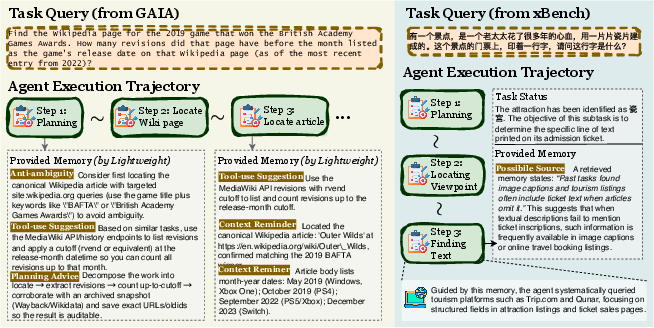
This paper introduces MemEvolve, a way to help AI “agents” not only learn from their past experiences but also get better at how they learn. Think of an AI agent like a very smart helper that reads, searches the web, plans steps, and solves problems using a LLM. Most agents already use “memory” to save helpful tips or past steps. But those memory systems are usually fixed. MemEvolve changes that: it lets the agent’s memory system itself adapt and improve over time, just like a student who upgrades their study habits, not just their knowledge.
Alongside the idea, the authors release EvolveLab, a standard, modular codebase that gathers 12 well-known memory designs into one place so researchers can compare, mix, and improve them fairly and easily.
Key questions the paper tries to answer
- Can an AI agent improve not just what it learns, but also how its memory is built and used?
- Is there a one-size-fits-all memory design for every task? If not, can the memory design evolve for different types of jobs (like web research vs. math problems)?
- Does evolving the memory design lead to better performance across different tasks, agent frameworks, and LLMs?
How it works, in simple terms
The authors break an agent’s memory into four simple parts. You can imagine them like a smart school notebook system:
- Encode: Turn raw experiences into useful notes. Example: summarize what happened or extract a lesson learned.
- Store: Put those notes somewhere. Example: a notebook, a graph, or a database.
- Retrieve: Find the right notes when needed. Example: search for the best example or tip to reuse right now.
- Manage: Clean up and improve the notebook over time. Example: organize, merge duplicates, or remove bad notes.
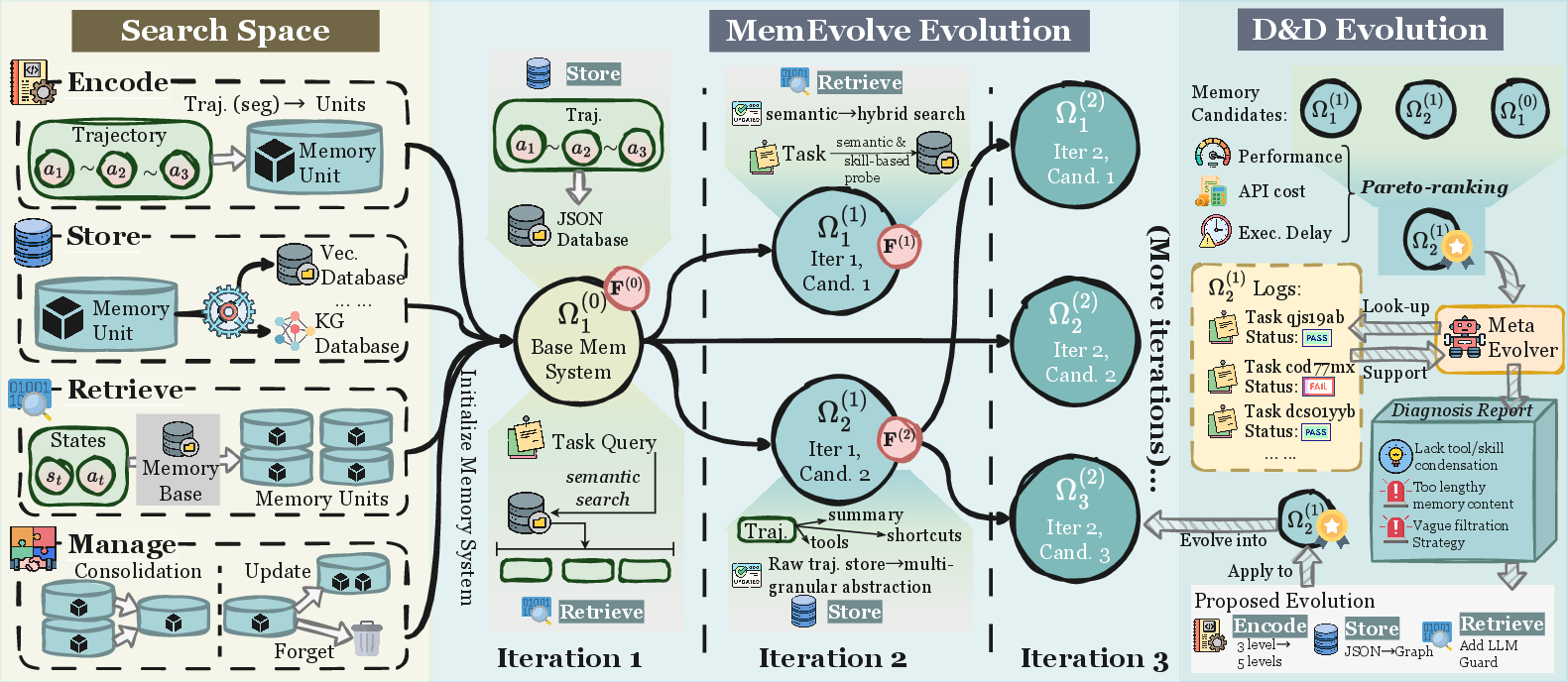
MemEvolve evolves both what’s inside the notebook and how the notebook system itself is designed. It runs in two loops:
- Inner loop (learning with one notebook): The agent does tasks using one specific memory design. It collects results like how often it succeeds, how long it took, and how many tokens it used. This is like doing homework with a particular study method and seeing how well you do.
- Outer loop (improving the notebook design): Based on those results, MemEvolve keeps the best memory designs and creates new ones by diagnosing what went wrong (for example, “retrieval failed to find the right tip”) and redesigning parts of the system (change how to encode, store, retrieve, or manage). This is like reviewing your study method after a test and trying smarter variations next time.
To make this practical, the authors:
- Provide EvolveLab, a modular codebase where many memory systems share the same four-part interface (Encode, Store, Retrieve, Manage).
- Re-implement 12 popular memory systems in this shared format so they’re easy to compare and combine.
- Use a “diagnose-and-design” step to create better memory designs over time, guided by actual task results.
What they found and why it matters
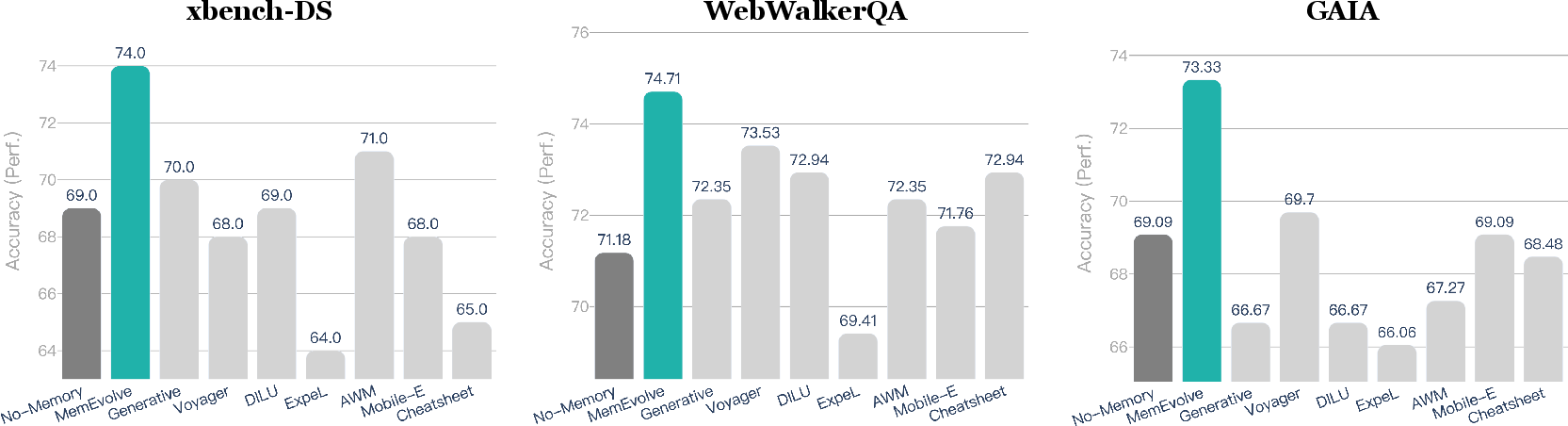
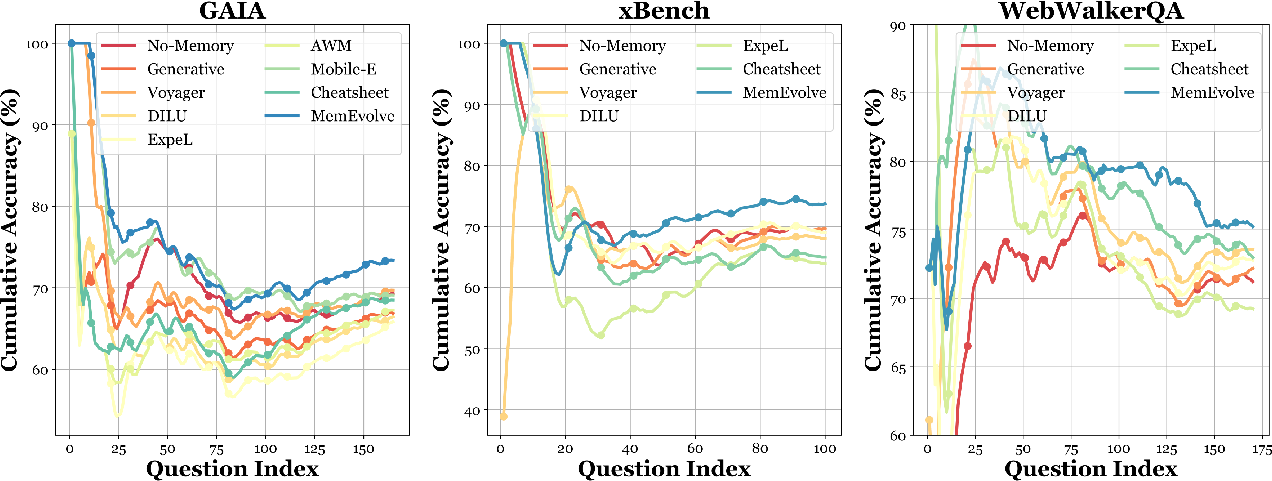
The authors test MemEvolve on four challenging benchmarks (think of them as standardized test sets):
- TaskCraft
- WebWalkerQA (web browsing questions)
- xBench-DeepSearch (hard research-style queries)
- GAIA (a general, multi-step problem-solving benchmark)
They plug MemEvolve into different agent frameworks (like SmolAgent and Flash-Searcher) and run it with different LLMs (such as GPT-5-Mini, Kimi K2, and DeepSeek V3.2). Here are the big takeaways:
- It boosts performance: MemEvolve improves agent results by up to about 17% in some settings. That means the agent gets more answers right or completes more tasks successfully.
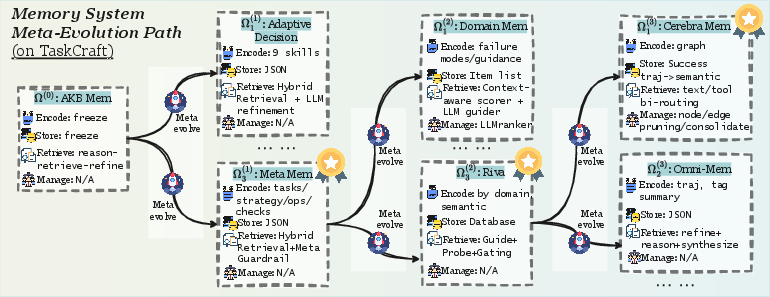
- It generalizes across tasks: A memory design evolved on one benchmark (TaskCraft) still helps on different benchmarks (like WebWalkerQA and xBench-DeepSearch), without re-tuning.
- It generalizes across models and frameworks: Memory designs evolved with one LLM or agent framework transfer to others and still give consistent gains.
- It’s cost-aware: The improvements come with similar API costs and reasonable runtime. In other words, you don’t need to spend a lot more to get these benefits.
- It outperforms many human-designed memories: Several existing memory systems help sometimes and hurt other times. MemEvolve tends to give steadier, more reliable gains because it adapts the memory to the task rather than sticking to a one-size-fits-all design.
Why this matters: If agents can evolve how they learn, they can adapt to new types of problems more easily and perform better in the real world, where tasks and contexts change a lot.
What this could mean going forward
- Smarter, more adaptive AI helpers: Agents won’t just get better at tasks; they’ll get better at choosing the right way to learn from experience, similar to top students who switch strategies depending on the subject.
- Less manual tuning: Instead of engineers hand-designing a memory pipeline for each task, MemEvolve can discover good designs automatically.
- A common foundation for research: EvolveLab provides a shared, modular playground so the community can build, compare, and evolve memory systems more fairly and quickly.
- Broader, safer deployment: More robust, adaptable memory systems can make AI agents more reliable across different jobs—research, planning, coding, and beyond.
In short, this paper shows that the best AI agents won’t just remember more—they’ll remember smarter, by continuously improving the way their memories work.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research.
- Formal guarantees and theory: No analysis of stability, convergence, or sample complexity for the dual-evolution process; unclear how survivor budget K=1 and short outer-loop horizon (Kmax=3) affect convergence, exploration–exploitation, and long-term optimality.
- Meta-evolution operator transparency: Insufficient detail on how the diagnose-and-design operator generates architectural variants (e.g., specific mutation/recombination rules over Encode/Store/Retrieve/Manage, prompt templates, constraints, randomness), hindering reproducibility and independent verification.
- Causal diagnosis rigor: Lacks methods to attribute failures to specific memory components versus agent policy/planning (e.g., randomized controlled perturbations, counterfactual replays, component-level fault localization).
- Component-wise ablations: No systematic ablation isolating the impact of each module (Encode, Store, Retrieve, Manage) on performance, cost, and latency; absence of interaction analyses among modules.
- Compute and energy accounting: Outer-loop search overhead (tokens, wall-clock hours, GPU/CPU usage, energy) is not reported; practical feasibility and cost–performance trade-offs of meta-evolution at scale remain unknown.
- Inner-loop reset assumption: Memory is re-initialized to empty each iteration; the effect on knowledge retention, exploration bias, and fairness (vs. warm-start carryover) is not studied.
- Multi-objective selection details: Pareto ranking is described but lacks sensitivity analyses (e.g., crowding distance, tie-breaking policies) and robustness to metric noise; alternative multi-objective strategies remain unexplored.
- Memory quality metrics: Evaluation relies on pass@k and aggregate cost/latency; missing memory-centric measures (retrieval precision/recall, coverage, abstraction quality, redundancy, drift, forgetting efficacy, provenance accuracy).
- Robustness to noise/poisoning: No experiments on adversarial or noisy experiences, memory corruption, or retrieval poisoning; absence of trust scoring, anomaly detection, and resilience mechanisms.
- Safety, privacy, and compliance: Unaddressed risks of storing sensitive data, copyright-protected content, or biased artifacts; no privacy-preserving memory management, auditability, or governance policies.
- Generalization scope: Claims of cross-task/LLM/framework transfer are confined to a single task regime (web/deep research); no evaluation on embodied control, code generation, mathematical reasoning, multimodal tasks, or multilingual settings.
- Statistical rigor: No confidence intervals, variance across seeds, or significance tests; hard to assess the reliability of reported gains and whether improvements persist across runs.
- Sensitivity to backbone models: Limited analysis of how evolved memories depend on LLM capability; no stratified studies across small vs. large models or open-source vs. proprietary backbones.
- Design space coverage: Although 12 systems are re-implemented, coverage of important modalities (e.g., temporal knowledge graphs, program repositories, differentiable memory, hybrid retrieval pipelines) is unclear; extensions and gaps in the taxonomy need mapping.
- Manage (forgetting/consolidation) policies: No comparative evaluation of different manage strategies; criteria and triggers for consolidation/forgetting, and their impact on stability and performance, are not quantified.
- Scaling with memory size: Retrieval speed, indexing strategies, and latency under large-scale memory growth remain untested; no memory growth curves or capacity–performance studies.
- Distributed/multi-agent memory sharing: Concurrency control, conflict resolution, provenance tracking, and coordination across many agents are not addressed; minimal evaluation beyond small multi-agent setups.
- Non-stationarity and concept drift: No mechanisms for detecting drift or scheduling re-evolution in streaming/online settings; the trade-off between adaptability and catastrophic forgetting is not explored.
- Conditional memory selection: The framework discovers a single global architecture per run; no task-level routing/gating to select among multiple specialized memories or ensembles at inference time.
- Tool ecosystem integration: While APIs/MCPs are mentioned, empirical evaluations on tool synthesis, function libraries, or code-level memories are missing; integration strategies and efficacy remain open.
- Data reuse and overfitting: The reuse of 20 tasks per iteration may bias outer-loop fitness; ablations with strictly held-out validation sets and stronger OOD tests are needed.
- Evaluation methodology: Details of LLM-as-a-Judge (prompting, calibration, tie-breaking, consistency checks) are not provided; potential judge biases and replicability are unaddressed.
- Co-evolution of policy and memory: The agent policy is fixed; potential benefits/risks of co-evolving planning/policies with memory architectures (and avoiding co-adaptation pitfalls) are unexplored.
- Human-in-the-loop design: No experiments on mixed-initiative meta-evolution (expert constraints, priors, veto rules); opportunities for incorporating domain knowledge are left open.
- Real-world deployment constraints: Absent discussion of operational issues (update cadence, storage/compliance, network latencies, cost budgets, failure recovery) for production-grade systems.
- Reproducibility concerns: Heavy reliance on proprietary or future models (e.g., GPT-5-mini) may limit replication; release of full prompts, seeds, candidate configurations, and diagnostic artifacts is necessary.
- Benchmark diversity and difficulty: The selected benchmarks emphasize web/deep research; broader datasets with controlled difficulty gradients and noise levels would better characterize robustness and adaptability.
- Fitness signal granularity: Aggregation operator S collapses trajectory-level feedback; the potential benefits of finer-grained, stage- or step-level fitness signals for more precise architectural evolution remain untested.
- Safety of meta-evolution process: The outer-loop may amplify harmful heuristics (e.g., shortcut learning); safeguards, constraint enforcement, and red-teaming of evolved architectures are not discussed.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging MemEvolve’s modular memory design (Encode/Store/Retrieve/Manage), its diagnose-and-design meta-evolution loop, and the EvolveLab codebase that standardizes 12 representative memory systems and benchmarks.
- Sector: Software/Knowledge Work (Research assistants, deep web search)
- What: Memory-Tuned Research Agents that automatically evolve memory architectures for web browsing, literature reviews, competitor analysis, and due diligence.
- Why now: Demonstrated pass@k gains on GAIA, xBench, WebWalkerQA; cross-LLM and cross-framework portability; cost and latency budgets incorporated into Pareto selection.
- Tools/Workflows: “Memory Tuning Sprint” (1–2 weeks) on representative task sets; deploy evolved memory architecture into SmolAgent/Flash-Searcher or internal agents; nightly “MemoryOps” re-tuning using diagnose-and-design defect profiles.
- Assumptions/Dependencies: Access to web tools/APIs; curated tasks for outer-loop evolution; budget for running evolution batches; compliance with web scraping and data retention policies.
- Sector: Customer Support and CX
- What: Ticket-Triage and Resolution Assistants whose memory adapts by product line, issue type, and channel (email/chat/phone), improving retrieval of past fixes, macros, and troubleshooting flows.
- Why now: Modular Store/Retrieve components work with vector DBs/hybrid KBs; Management policies (consolidation/forgetting) control cost and bloat.
- Tools/Workflows: Integrations with CRM/Helpdesk (e.g., Zendesk, Salesforce Service Cloud); defect-driven updates to retrieval filters and summarization encoders based on failure cases.
- Assumptions/Dependencies: PII handling and audit trails; change management approval; reliable labeling of “resolved” outcomes as feedback signals.
- Sector: Software Engineering
- What: Code and DevOps Agents that evolve reusable fix patterns, test triage playbooks, and repo-specific tool libraries; adaptive retrieval for large mono-repos and multi-service environments.
- Why now: EvolveLab includes tool/library style memories (APIs, workflows) and pruning; cross-framework portability enables plug-in to existing LangChain/LlamaIndex pipelines.
- Tools/Workflows: CI “Memory Gates” that re-run evolution on flaky tests/incident retros; manage modules enforce retention windows and deduplication to keep memory lean.
- Assumptions/Dependencies: Access to repos/build logs; sandboxed environments; rights to store code snippets as memory artifacts.
- Sector: Marketing, Legal, Consulting
- What: Document Research Agents that learn domain- and client-specific memory abstractions (templates, checklists, argument schemas) for repeated deliverables.
- Why now: Encode/Manage supports abstraction and consolidation; demonstrated transfer across related task regimes without dataset-specific tuning.
- Tools/Workflows: Template mining and schema retrieval; memory variants per client vertical selected via Pareto-ranked profiles.
- Assumptions/Dependencies: Document ingestion permissions; confidentiality controls; representative prior engagements to seed evolution.
- Sector: Academia and R&D
- What: Reproducible Memory Benchmarking and Comparative Studies using EvolveLab; controlled A/B testing of Encode/Store/Retrieve/Manage variants and their trade-offs.
- Why now: Unified codebase, standardized evaluation (including LLM-as-a-Judge), and cross-benchmark reporting ready to use.
- Tools/Workflows: Curriculum-like evaluation protocols; public “Memory Architecture Registry” for sharing genotypes and reproducibility artifacts.
- Assumptions/Dependencies: Compute budget for outer-loop; careful judge prompts to reduce evaluation bias; citation and licensing compliance.
- Sector: Enterprise MLOps/AI Platform
- What: MemoryOps Dashboards for observability and governance of agent memory: cost/latency/performance Pareto fronts, defect profiles, and versioned rollbacks.
- Why now: The framework surfaces token cost and delay as first-class metrics; diagnose-and-design produces actionable failure signatures (retrieval misses, ineffective abstractions).
- Tools/Workflows: Feature-flag rollouts of evolved memories; budget-aware auto-scaling; audit logs for architecture changes.
- Assumptions/Dependencies: Centralized telemetry; role-based access control; compatibility with vector DBs/knowledge graphs.
- Sector: Education and Training
- What: Adaptive Study Assistants that switch memory strategies by subject (e.g., schemas for math, exemplars for literature), improving few-shot help and planning.
- Why now: The paper’s “adaptive learner” analogy maps directly to subject-specific memory modules; plug-and-play in lightweight agents.
- Tools/Workflows: Course-specific memory evolution on sample problem sets; controlled forgetting to avoid outdated curriculum.
- Assumptions/Dependencies: Non-sensitive student data; dataset splits to avoid leakage; human-in-the-loop validation.
- Sector: Finance/Analyst Work
- What: Financial Research Agents that optimize memory for SEC filings, earnings calls, and macro reports, improving cross-document reasoning and reusability of heuristics.
- Why now: Proven transfer across related information-seeking benchmarks; modular retrieval filters and consolidation for long-horizon tasks.
- Tools/Workflows: Periodic re-evolution around earnings seasons; sector-specific memory variants (e.g., TMT, Healthcare).
- Assumptions/Dependencies: Licensing for data sources; compliance review workflows; risk controls for hallucination.
- Daily Life/Prosumer
- What: Personal Knowledge Management Assistants that adapt memory structures for projects (travel, finances, home), balancing forgetting and consolidation to control clutter and cost.
- Why now: JSON/graph stores and hybrid search supported; management policies (pruning/deduplication) are ready-to-use.
- Tools/Workflows: Weekly “memory clean-up” runs; scenario-specific retrieval prompts (planning vs. execution).
- Assumptions/Dependencies: Privacy-preserving local or encrypted storage; clear consent for data retention.
Long-Term Applications
These require further research, scaling, compliance reviews, or new integrations beyond the paper’s scope, even though the core ideas are applicable.
- Sector: Healthcare (Clinical Workflows and Decision Support)
- What: Adaptive Clinical Assistants that evolve memory by specialty (radiology, cardiology) and setting (inpatient vs. outpatient), optimizing retrieval of guidelines and prior cases.
- Why later: Needs clinical validation, safety monitoring, EHR integration, and rigorous privacy/consent controls.
- Tools/Workflows: Governed forgetting aligned with retention policies; bias and safety audits on memory modifications.
- Assumptions/Dependencies: HIPAA/GDPR compliance; model and memory validation on real-world clinical outcomes.
- Sector: Robotics/Embodied AI
- What: Embodied Agents whose memory architectures co-evolve for physical tasks (manipulation, navigation), unifying perception, tool-use, and temporal memory.
- Why later: Paper cautions limited transfer to embodied settings; requires alignment with action spaces, sensors, and safety constraints.
- Tools/Workflows: Sim-to-real curricula; memory-safe fallback policies; formal verification of retrieval and forgetting.
- Assumptions/Dependencies: High-fidelity simulators; real-time constraints; safety certification.
- Sector: Regulatory Technology and AI Governance
- What: Auditable Memory-Evolution Pipelines codifying performance–cost–latency trade-offs and retention/forgetting policies; conformance test suites for adaptive agents.
- Why later: Emerging standards and oversight mechanisms are still evolving; requires cross-industry consensus on metrics and reporting.
- Tools/Workflows: Standardized “memory change logs,” certification checklists, and red-team protocols for meta-evolving systems.
- Assumptions/Dependencies: Adoption by regulators/standards bodies; interoperable telemetry.
- Sector: Enterprise Knowledge Management at Scale
- What: Organization-Wide Memory Architectures that self-adapt across functions (sales, ops, legal), with federated memory evolution respecting data silos and privacy.
- Why later: Needs robust multi-tenant isolation, federated optimization, and cross-team policy enforcement.
- Tools/Workflows: Federated diagnose-and-design; cross-domain genotype marketplaces; policy-aware retrieval filters.
- Assumptions/Dependencies: Data residency rules; identity and access management integration; federation across tool stacks.
- Sector: Scientific Discovery Platforms
- What: Lab-Cycle Agents that evolve memory for experiment planning, tooling protocols, and literature synthesis across disciplines (chemistry, biology, materials).
- Why later: Requires toolchain integrations (ELN/LIMS), provenance tracking, and ground-truth evaluation of scientific hypotheses.
- Tools/Workflows: Protocol abstraction encoders; experiment result consolidation; safety and reproducibility guards.
- Assumptions/Dependencies: Instrument APIs; rigorous domain-specific benchmarks; human oversight loops.
- Sector: Cost-Optimized Cross-LLM Portability
- What: Evolve-on-Cheap, Deploy-on-Preferred workflows that systematically evolve memory with low-cost LLMs and port to premium or local models at scale.
- Why later: Needs robust portability studies across more model families and tasks; tooling for automatic compatibility checks.
- Tools/Workflows: Memory genotype export/import standards; portability scorers; budget-aware schedulers.
- Assumptions/Dependencies: Stable APIs across LLM vendors; performance preservation under model swaps.
- Sector: Standards and Interoperability
- What: An “ONNX for Memory” standard exposing Encode/Store/Retrieve/Manage interfaces and metadata for agent ecosystems and marketplaces.
- Why later: Requires coordination across vendors and open-source communities; governance of safety and license metadata.
- Tools/Workflows: Memory artifact registries; schema validators; compatibility matrices.
- Assumptions/Dependencies: Broad adoption; clear IP and licensing frameworks.
- Sector: Safety-Critical Operations (Energy, Transportation)
- What: Safety-Assured Agents whose memory evolution is constrained by formal rules and certified forgetting to prevent stale or unsafe procedures.
- Why later: Demands formal verification, incident post-mortem integration, and regulatory certification.
- Tools/Workflows: Rule-constrained design operators; safety case generation; real-time monitoring for drift.
- Assumptions/Dependencies: Access to incident data; domain-specific safety standards; deterministic execution pathways.
Common Assumptions and Dependencies Across Applications
- Representative task logs or datasets are needed to drive the outer-loop evolution; poor coverage risks overfitting or missed edge cases.
- LLM capability remains a performance ceiling; while cross-model generalization is shown, weaker models may limit gains.
- Infrastructure for memory backends (vector DBs, graphs, hybrid stores) and observability is required; costs arise from token usage and evaluation runs.
- Privacy, compliance, and security are critical when storing trajectories; governed forgetting and auditability are essential.
- LLM-as-a-Judge introduces evaluation bias; supplement with deterministic metrics and human review where feasible.
- Transferability is strongest within similar task regimes; significant domain shifts (e.g., to embodied robotics) require adaptation and validation.
By operationalizing MemEvolve as a MemoryOps practice—combining evolution sprints, diagnose-and-design debugging, and governed deployment—organizations can realize immediate performance gains in agent systems while building a pathway to safe, scalable, and standards-aligned long-term adoption.
Glossary
- Agentic: Pertaining to agent-driven or agent-oriented tasks, systems, or behaviors. "Extensive evaluations on four challenging agentic benchmarks demonstrate that achieves (I) substantial performance gains"
- Aggregation operator: A function that summarizes multiple per-trajectory feedback vectors into a single performance summary. "An aggregation operator summarizes the inner-loop outcomes for each candidate as"
- Architectural selection: The process of choosing the top-performing memory architectures to serve as parents for the next evolution step. "1mm{Architectural Selection}"
- Bilevel optimization: An optimization scheme with nested loops, where an inner loop adapts experience and an outer loop meta-optimizes the architecture. "Conceptually, operates as a bilevel optimization process: the inner loop performs a first-order evolution, where the agent... The outer loop drives a second-order evolution"
- Contrastive comparison: A retrieval strategy that selects relevant memory by contrasting candidate items. "Contrastive Comparison"
- Deduplication: A management operation that removes duplicate entries from a memory repository to maintain quality and efficiency. "Deduplication"
- Dual-evolution process: A procedure that simultaneously evolves an agent’s memory base and the memory architectures themselves. "we propose a dual-evolution process that jointly evolves (i) the agentâs memory base and (ii) the underlying memory architectures"
- Episodic consolidation: A memory management technique that integrates episodic experiences into more stable, long-term structures. "Episodic Consolidation"
- Few-shot prompting: A prompting method that supplies a small number of examples to guide model behavior. "Initial designs centered on raw trajectory storage and few-shot prompting"
- Function matching: A retrieval mechanism that selects tools or APIs by matching their function signatures or capabilities. "Function Matching"
- Genotype: A compact representation of an architecture’s modular components used as the unit of evolution. "forming a ``genotype'' that facilitates the meta-evolutionary process of ."
- Inner loop: The experience evolution phase where the agent updates memory by interacting with tasks under a fixed architecture. "Inner Loop (Experience Evolution)."
- Knowledge graph: A graph-structured repository of entities and relations used for storage and retrieval in memory systems. "e.g., knowledge graphs, skill libraries, vector databases"
- LLM-as-a-Judge: An evaluation protocol where a LLM serves as the scoring or judging mechanism. "including exact string matching and flexible LLM-as-a-Judge."
- MCPs: Standardized tool interface protocols that integrate external capabilities into agent systems. "MCPs~\citep{qiu2025alita,qiu2025agentdistilltrainingfreeagentdistillation,zhang2025agentorchestraorchestratinghierarchicalmultiagent}"
- Meta-evolutionary framework: A framework that evolves both experiential knowledge and the underlying memory architecture over time. "We propose , a meta-evolutionary framework that jointly evolves both agents' experiential knowledge and their underlying memory architecture"
- Meta-learning: Learning to improve the learning strategy or architecture itself based on performance feedback. "The outer loop drives a second-order evolution, meta-learning a more effective memory architecture to accelerate future learning."
- Modular design space: A structured decomposition of memory systems into encode, store, retrieve, and manage modules. "a modular design space (encode, store, retrieve, manage)"
- Non-dominated sorting: A multi-objective ranking method that orders candidates by Pareto dominance. "Candidates are first ranked by non-dominated sorting over "
- Outer loop: The architectural evolution phase that selects, modifies, and recombines memory components based on performance. "Outer Loop (Architectural Evolution)."
- Pareto rank: The level assigned to a candidate based on its position in the non-dominated (Pareto) ordering. "yielding a Pareto rank ."
- Pass@k: An evaluation metric indicating success if any of k independent attempts produce a correct solution. "We report the pass@1â3 performance of"
- Semantic search: Retrieval based on embedding similarity or meaning rather than exact keyword matching. "Semantic Search"
- Skill pruning: The process of removing underperforming or redundant skills from a library to improve efficiency. "Skill Pruning"
- Survivor budget: The fixed number of top-ranked architectures retained for producing descendants in the next iteration. "where denotes a fixed survivor budget."
- Tool library: A curated repository of reusable tools or APIs that agents can invoke during tasks. "Tool Library"
- Vector database: A storage system that maintains embedding vectors and supports similarity-based retrieval. "Storage can be vector databases"
Collections
Sign up for free to add this paper to one or more collections.