- The paper introduces A-MEM, advancing memory autonomy in LLM agents through a dynamic, Zettelkasten-inspired system.
- It details methodologies like note construction, link generation, and memory evolution to enhance multi-hop reasoning and context-aware retrieval.
- Empirical results demonstrate doubled performance in complex reasoning tasks and reduced token costs compared to baseline memory systems.
A-MEM: Agentic Memory for LLM Agents
Introduction
The paper "A-Mem: Agentic Memory for LLM Agents" introduces an innovative memory system designed to enhance the autonomy and adaptability of LLM agents. Current memory systems used with LLMs provide basic storage and retrieval functionalities but lack sophisticated organization and adaptability. The proposed A-Mem system leverages the principles of the Zettelkasten method to create dynamic, interconnected knowledge networks, allowing LLM agents to autonomously manage memory and ensure effective long-term interaction with their environment.
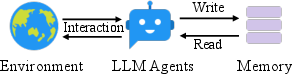
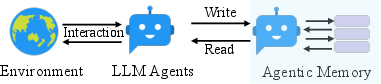
Figure 1: Traditional memory systems require predefined memory access patterns specified in the workflow, limiting their adaptability to diverse scenarios. Contrastly, A-Mem enhances the flexibility of LLM agents by enabling dynamic memory operations.
Methodology
Note Construction
The A-Mem system constructs memory notes by capturing both explicit interaction content and LLM-generated contextual understanding. Each memory note includes attributes like keywords, tags, and contextual descriptions generated through a templated LLM prompt (Figure 2). This allows the system to autonomously extract implicit knowledge and generate dense vector representations for similarity matching, enabling nuanced organization and retrieval.
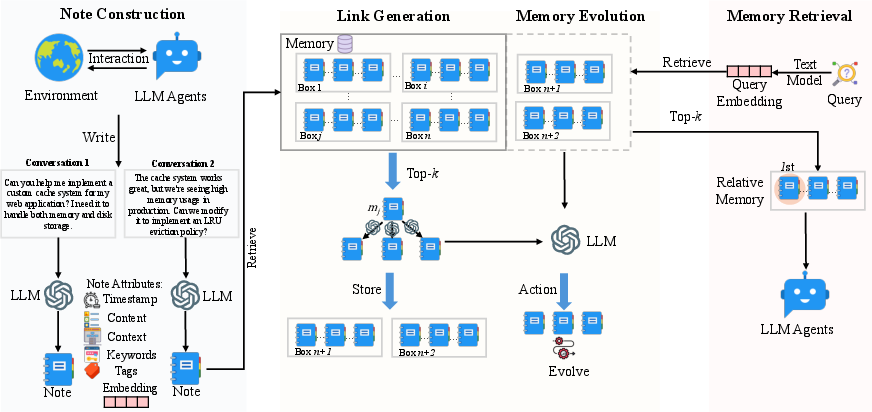
Figure 2: The A-Mem architecture comprises three integral parts: note construction, link generation, and memory retrieval.
Link Generation
A-Mem employs an autonomous link generation mechanism that identifies meaningful connections between memories based on semantic similarities. This is achieved through cosine similarity calculations and LLM-driven analyses, which allow for the identification of subtle patterns and conceptual links beyond basic similarity metrics. The process ensures scalability by filtering connections through embedding-based retrieval.
Memory Evolution
Upon adding new memories, A-Mem triggers updates to the contextual descriptions and attributes of existing memories, enabling the evolution of the memory network over time. This allows for the dynamic refinement of knowledge structures, resulting in a more sophisticated organizational framework that mimics human learning processes.
Empirical Evaluation
The proposed system was evaluated using a long-term conversational dataset, LoCoMo, and demonstrated significant improvements over existing state-of-the-art baselines across various metrics including F1 score and BLEU-1. A-Mem's architecture enables superior multi-hop reasoning and context-aware memory retrieval, evidenced by doubled performance scores in complex reasoning tasks when compared to traditional systems.
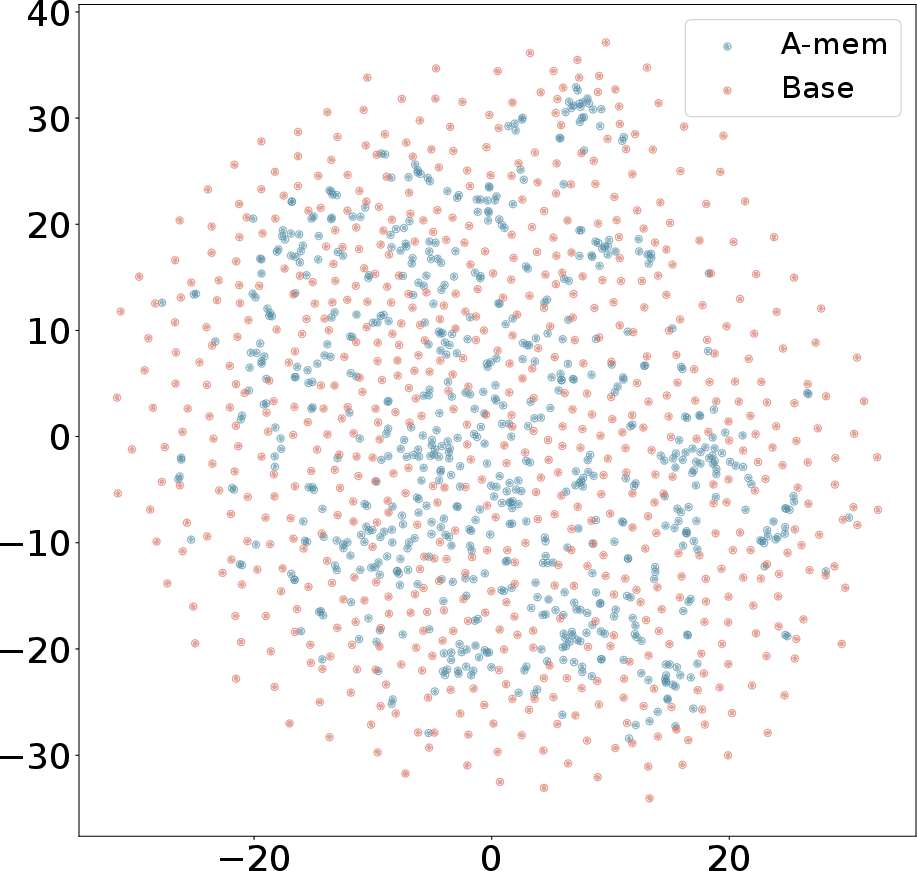
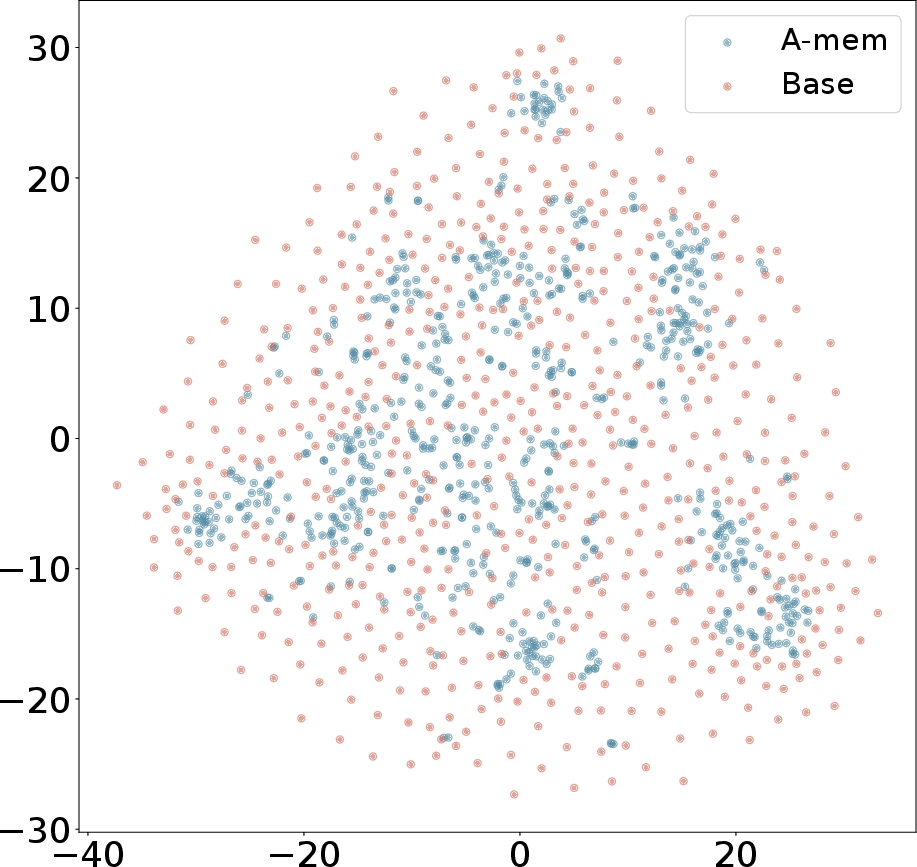
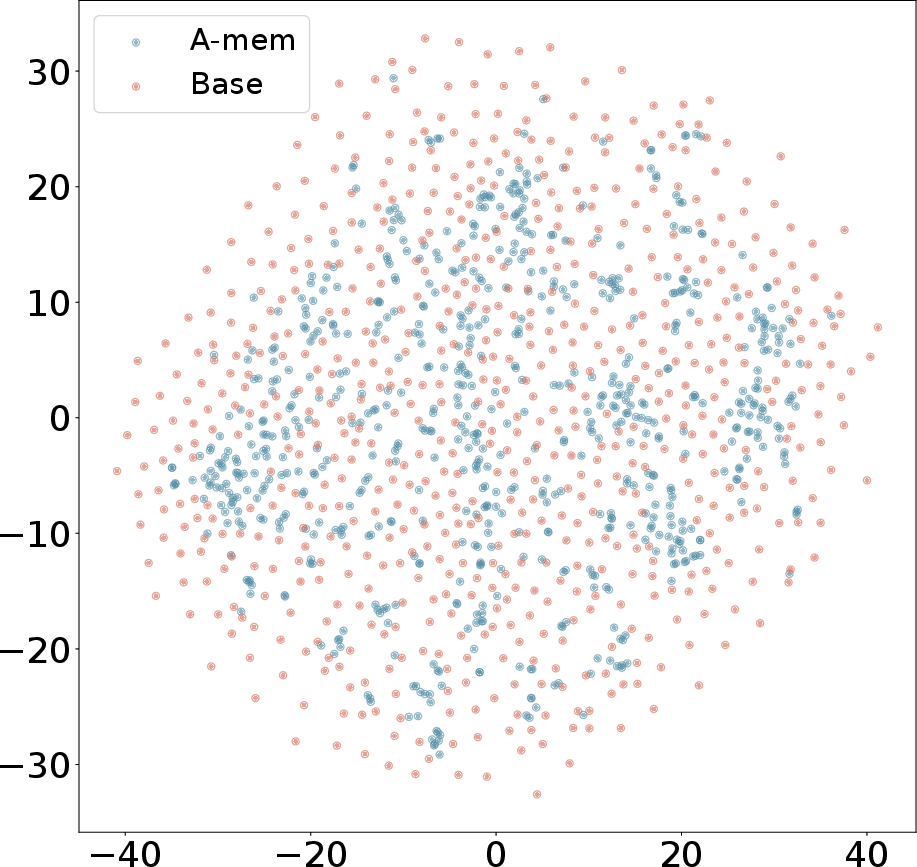
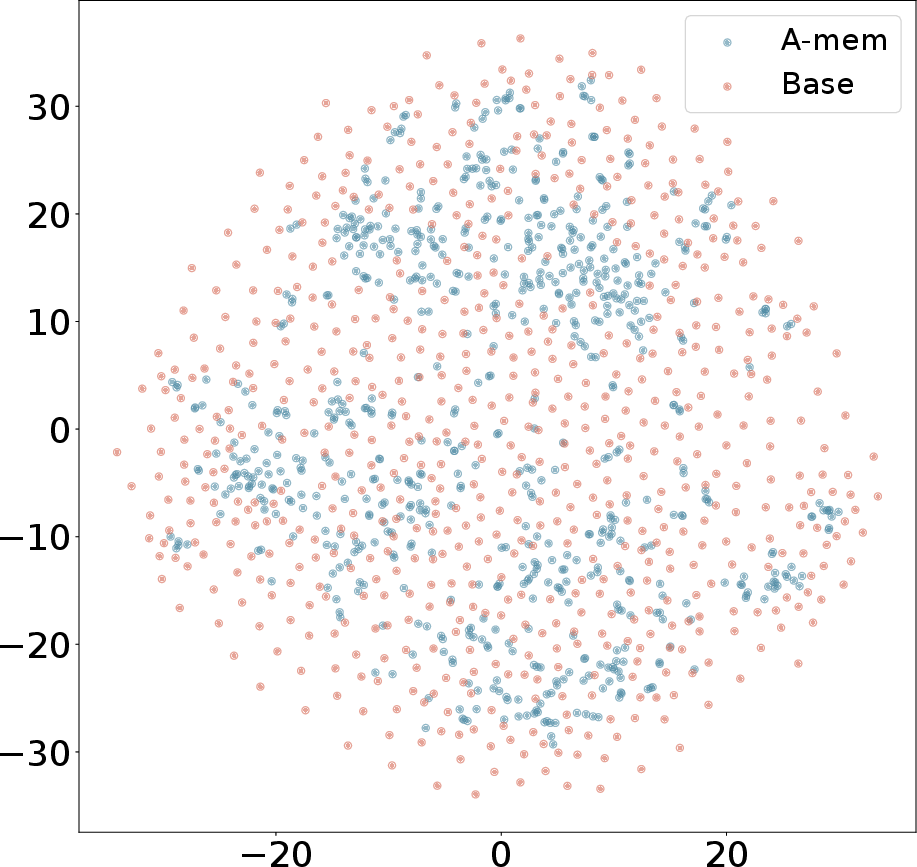
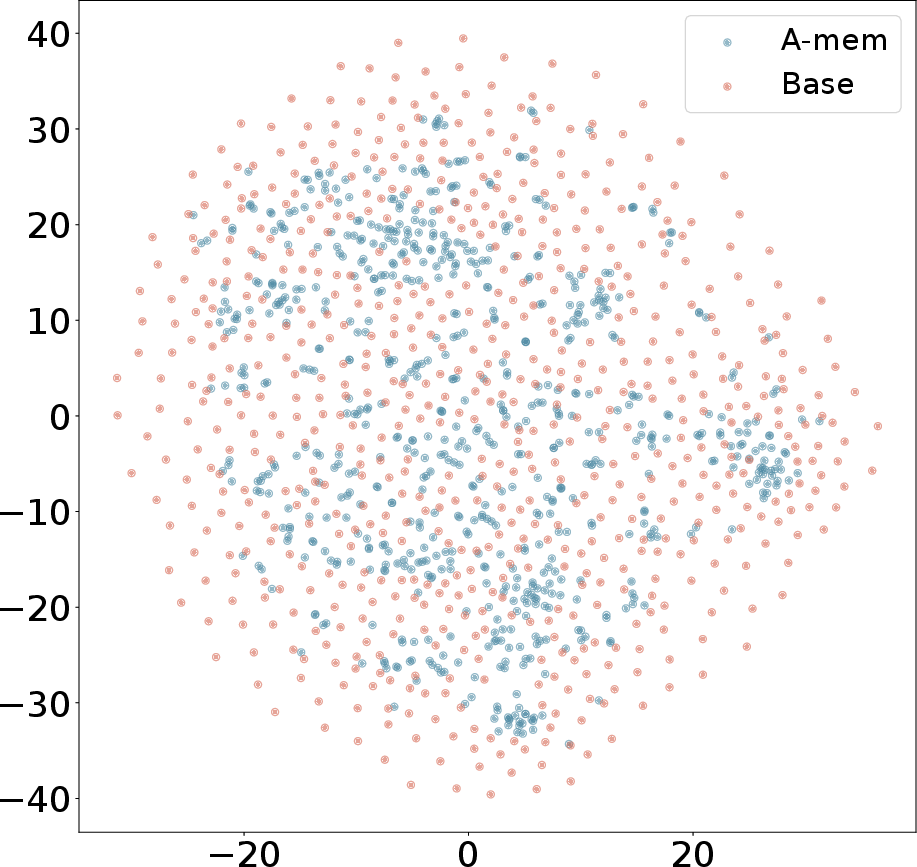
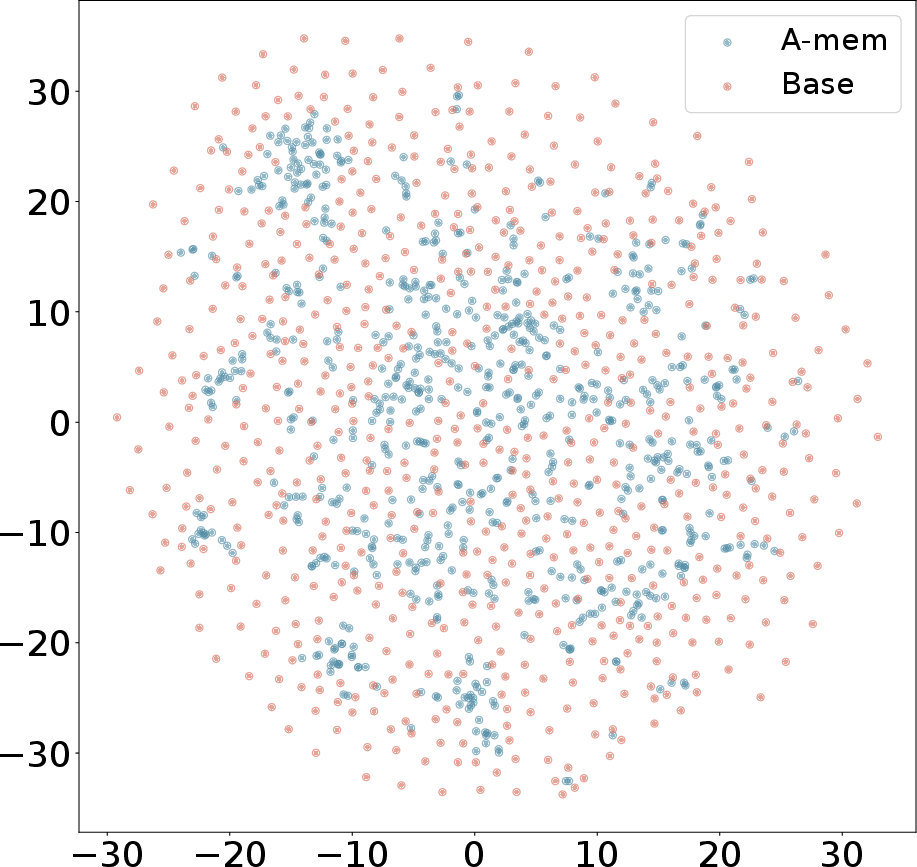
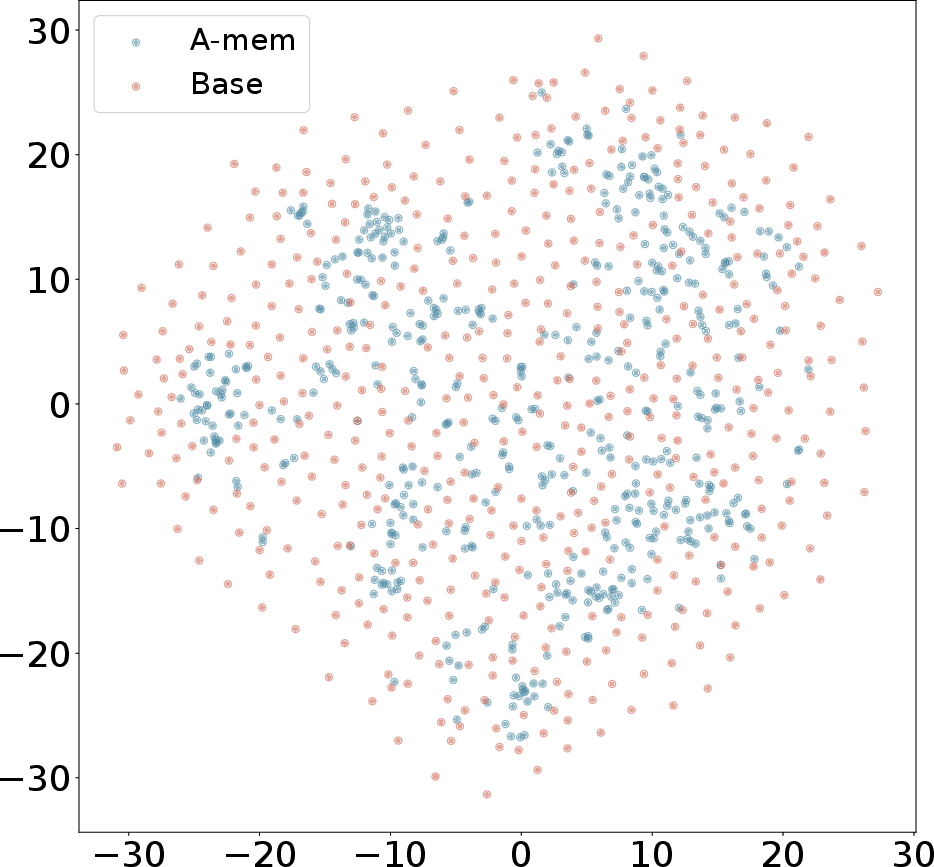
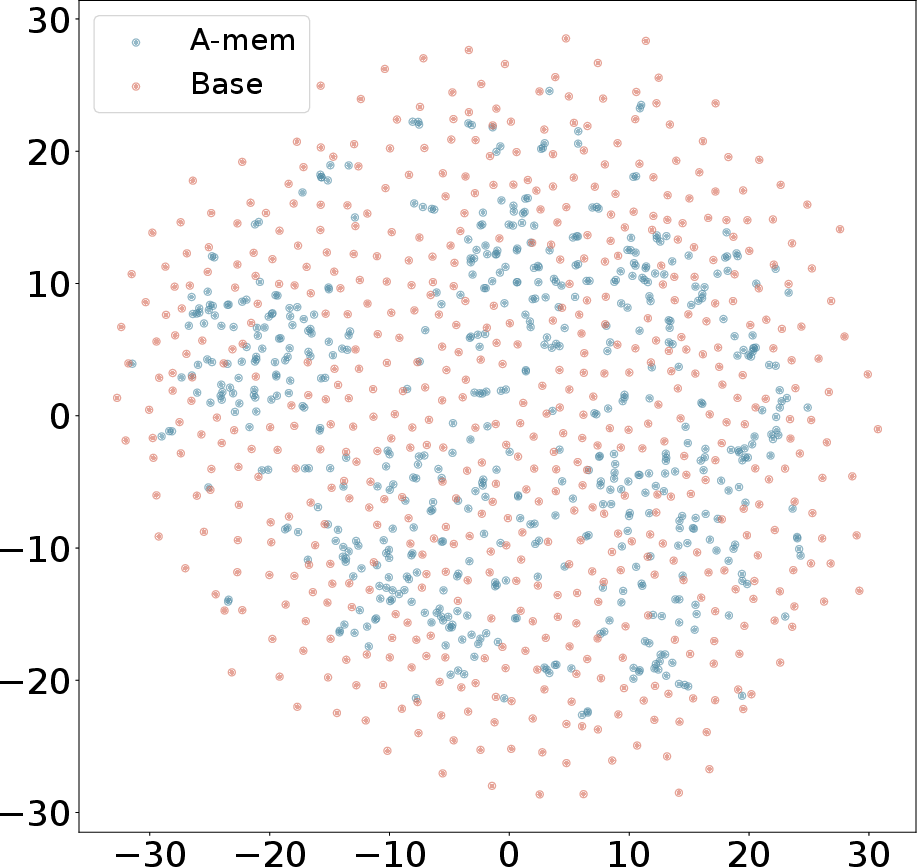
Figure 3: T-SNE Visualization of Memory Embeddings Showing More Organized Distribution with A-Mem (blue) Compared to Base Memory (red) Across Different Dialogues.
A-Mem achieves remarkable computational efficiencies, requiring substantially fewer tokens per memory operation compared to baseline methods. This efficiency translates to reduced operational costs, making large-scale deployments economically feasible. Despite multiple LLM calls during memory processing, A-Mem maintains cost-effective resource utilization while consistently outperforming baseline approaches across various foundation models.
Scaling and Limitations
The system's scalability was validated by experiments showing minimal increases in retrieval time despite scaling to large memory sizes. However, it is acknowledged that the quality of memory organization may depend on the LLM's capabilities, and future work may explore extensions to handle multimodal information.
Conclusion
The A-Mem system significantly enhances the ability of LLM agents to leverage long-term knowledge through autonomous, dynamic memory structuring. Its novel approach to memory management and evolution paves the way for more adaptive and context-driven applications in diverse real-world scenarios. Future research prospects include advancing multimodal integration and further optimizing the system for broader applications.