- The paper demonstrates that advanced LLM adaptation methods measurably improve both cognitive plausibility and linguistic realism in math learner simulations.
- The fine-tuning approach leverages real student data, while multi-agent and DPO methods incorporate reflective critique to produce contextually appropriate responses.
- Educator feedback indicates that DPO achieves high authenticity and diverse reasoning, offering actionable insights for scalable teacher training simulations.
Developing Authentic Simulated Learners for Mathematics Teacher Education: Comparative Analysis of Fine-Tuning, Multi-Agent, and DPO Approaches
Introduction
The increasing integration of LLM-based simulations in Practice-Based Teacher Education (PBTE) addresses significant limitations of traditional training modalities by providing scalable, dynamic opportunities for teacher candidates to develop professional noticing of student mathematical thinking. However, prior LLM approaches relying on zero- or few-shot prompting inadequately mirror authentic student cognition and discourse, often resulting in verbose, overly sophisticated, or inconsistent simulations. This paper systematically evaluates three methods to enhance the authenticity and educational utility of simulated students: Fine-tuning on domain-specific learner data, Multi-agent architectures with reflective critique and self-correction loops, and Direct Preference Optimization (DPO) using synthetic preference pairs.

Figure 1: Prompt and interface for the simulated agent "Josh" targeting elementary fraction sense.
Comparative Methodological Overview
The study centers on a well-established mathematics diagnostic task—finding a fraction between 2/3 and 7/8—undertaken by pre-service teachers (PSTs) interacting with simulated fifth-grade student "Josh" in multi-turn chat-based settings. Across numerous authentic and inauthentic interaction instances, authenticity of LLM outputs is evaluated along two axes: Cognitive plausibility (consistency with the student profile, logical reasoning congruency, and typical solution pathways) and Linguistic realism (age-appropriate tone, avoidance of disciplinary jargon, and variability in surface features).
The three LLM adaptation strategies are as follows:
- Fine-tuning: GPT-4.1 is adapted on a curated corpus comprising authentic student utterances from PST interactions, AI-tutoring transcripts (e.g., Khan Academy), and annotated classroom dialogue datasets.
- Multi-Agent Architecture: A hierarchical system where an Initial Responder generates candidate outputs, an Evaluator critiques those outputs using the authenticity framework, and a Refiner revises responses, iteratively enhancing plausibility and alignment.
- Direct Preference Optimization (DPO): Synthetic preference pairs are generated via reflexive agent critique and revision, with the LLM directly trained on these preferences using the DPO algorithm, bypassing explicit reward model construction.
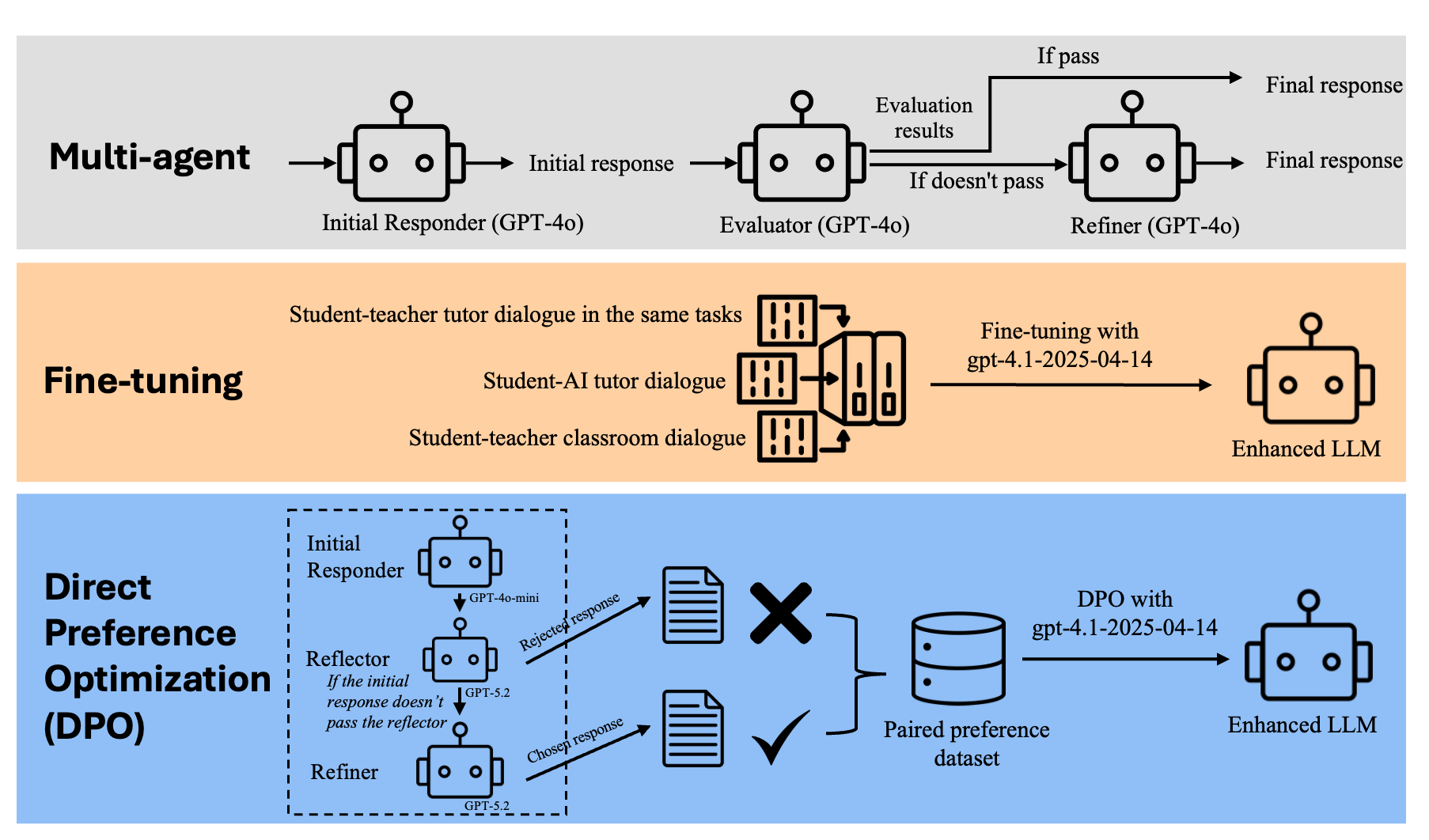
Figure 2: Overview of approaches showing LLM selection and feedback-driven refinement mechanisms.
Quantitative Outcomes on Authenticity
Rigorous double-coded evaluation with Generalized Linear Mixed Models (GLMM) and McNemar’s tests reveals that all three advanced methods substantially outperform few-shot prompting baselines in both cognitive and linguistic authenticity (Fine-tuning: p=.007/p<.001; Multi-Agent: p<.001/p=.003; DPO: p=.013/p<.001). DPO achieves the highest descriptive performance, consistently generating 100% authentic language and 88.7% authentic cognition on the test set. However, no statistically significant differences emerge between the advanced approaches in aggregate GLMM analyses, indicating convergent effectiveness across methods in the current simulation context.
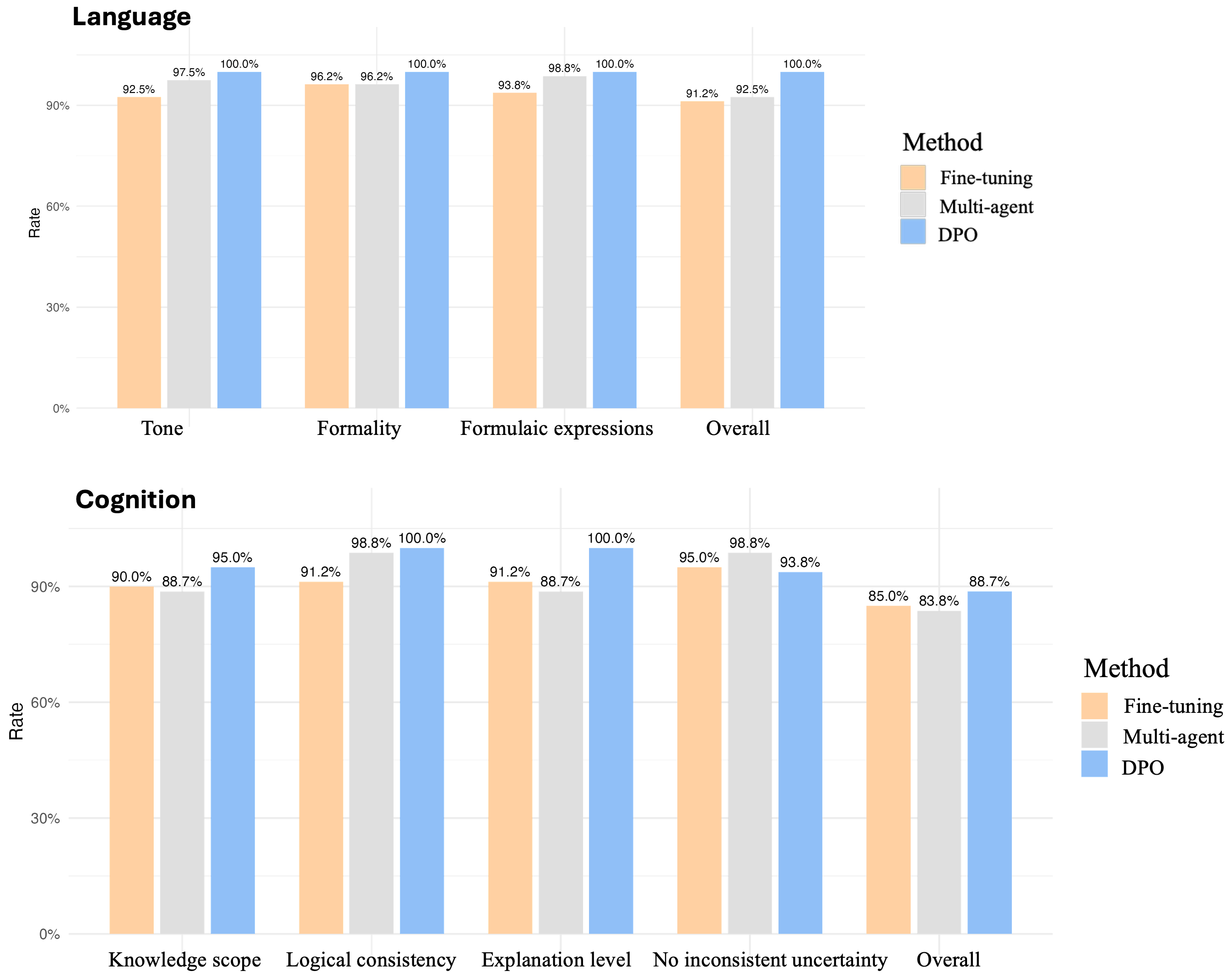
Figure 3: Performance of each approach across cognition and language authenticity dimensions.
Qualitative Analysis: Educator Perceptions and Pedagogical Implications
Structured interviews with teacher candidates and mathematics education researchers reveal nuanced affordances of each approach beyond aggregate authenticity scores:
Adaptive questioning emerges as a key instructional outcome: Fine-tuned agents promote more probing and open-ended scaffolding, whereas Multi-Agent/DPO agents facilitate deeper explanatory questioning (e.g., "why" and "how" prompts). All versions support PSTs’ reflection on the spectrum of authentic student responses and adaptive teacher noticing skills, but agent expressiveness must be balanced to avoid demotivation or cognitive overload.
Discussion
The findings demonstrate that Fine-tuning, Multi-Agent, and DPO pipelines each remediate the core authenticity limitations of prompt-only LLM student simulations. Each mechanism entails intrinsic trade-offs: Fine-tuning capitalizes on real classroom data but is limited in adaptivity when data are scarce; Multi-Agent systems excel in generating explicit reasoning but suffer from greater latency and verbosity; DPO generalizes well with limited paired preferences and aligns closely with desired student behaviors when carefully scaffolded. The study underscores the necessity of selecting and adapting techniques based on the target pedagogical context and the specific goals of simulation-based teacher training.
Notably, DPO and reflexive Multi-Agent feedback present a scalable frontier for educational LLM simulation, especially in domains where reliable annotated student data are limited. However, handling nuanced uncertainty expression and reasoning trajectories remains an open challenge, as does scaling simulation complexity to multi-student classroom settings.
Conclusion
This study provides robust evidence that advanced LLM adaptation methods—Fine-tuning, Multi-Agent collaboration, and Direct Preference Optimization—can each significantly improve the authenticity and pedagogical usefulness of simulated learners in mathematics teacher education. DPO approaches are favored in head-to-head educator comparisons, but all evaluated methods offer distinct advantages and implementation trade-offs. Future research should pursue integration with knowledge tracing mechanisms to ameliorate uncertainty misalignment, expand to collaborative multi-agent simulation of diverse classrooms, and iteratively ground agent preferences in expanded human-annotated datasets. As LLM-based teacher education tools mature, careful framework design to balance authenticity, instructional feedback, and operational efficiency will be essential for maximizing impact on professional noticing and classroom responsiveness.
Reference: See "Developing Authentic Simulated Learners for Mathematics Teacher Learning: Insights from Three Approaches with LLMs" (2604.04361).

